超越5大最先进的文本到视频系统!MagicVideo-V2:多阶段高保真视频生成框架(字节)

本项工作介绍了MagicVideo-V2,将文本到图像模型、视频运动生成器、参考图像embedding模块和帧内插模块集成到端到端的视频生成流程中。由于这些架构设计的好处,MagicVideo-V2能够生成具有极高保真度和流畅度的美观高分辨率视频。通过大规模用户评估,它在性能上表现优越,超过了领先的文本到视频系统,如Runway、Pika-1.0、Morph、Moon Valley和Stable Video Diffusion模型。
github链接:https://magicvideov2.github.io/
引言
文本到视频(T2V)模型的大量涌现标志着领域的重大进步,这得益于最近传播的基于扩散的模型。这项工作提出了MagicVideo-V2,这是一个新颖的多阶段T2V框架,将文本到图像(T2I)、图像到视频(I2V)、视频到视频(V2V)和视频帧插值(VFI)模块集成到端到端视频生成流程中。 T2I 模块通过从文本提示生成一个初始图像,捕捉输入的美学要素,为视频生成奠定基础。然后 I2V 模块以图像为输入,输出生成视频的低分辨率关键帧。随后的 V2V 模块增加了关键帧的分辨率并增强了其细节。最后,帧插值模块在视频中添加平滑的运动。
MagicVideo-V2
MagicVideo-V2 是一个多阶段端到端视频生成流程,能够从文本描述生成高美学水平的视频。它包括以下关键模块:
-
「Text-to-Image 模型」,从给定的文本提示生成具有高保真度的美学图像。
-
「Image-to-Video 模型」,使用文本提示和生成的图像作为条件生成关键帧。
-
「Video to Video 模型」,对关键帧进行细化和超分辨率处理,生成高分辨率视频。
-
「Video Frame Interpolation 模型」,在关键帧之间插入帧以平滑视频运动,最终生成高分辨率、流畅、高度美学的视频。
下面的小节将详细解释每个模块。

Text-to-Image 模块
T2I 模块以用户提供的文本提示为输入,并生成一张 1024 × 1024 的图像作为视频生成的参考图像。参考图像有助于描述视频内容和美学风格。MagicVideo-V2 兼容不同的 T2I 模型。具体而言,在 MagicVideo-V2 中使用了一个内部开发的基于扩散的 T2I 模型,该模型能够输出高美学的图像。
Image-to-Video 模块
I2V 模块基于高美学的 SD1.5模型,该模型利用人类反馈来提高在视觉质量和内容一致性方面的能力。I2V 模块通过受[10]启发的运动模块对高美学的 SD1.5 进行了扩展,两者都在内部数据集上进行了训练。 I2V 模块还增加了一个参考图像embedding模块,用于利用参考图像。具体而言,采用外观编码器来提取参考图像embedding ,并通过交叉注意力机制将其注入到 I2V 模块中。通过这种方式,图像提示可以有效地与文本提示解耦,并提供更强的图像调节。此外,采用了潜在噪声先验策略,以在起始噪声潜变量中提供布局条件。帧是从标准高斯噪声初始化的,其均值从零移向参考图像潜变量的值。通过适当的噪声先验技巧,可以部分保留图像布局,并改善帧之间的时间一致性。为了进一步增强布局和空间调节,部署了一个 ControlNet 模块,直接从参考图像中提取 RGB 信息,并将其应用于所有帧。这些技术使帧与参考图像很好地对齐,同时允许模型生成清晰的运动。
采用图像-视频联合训练策略来训练 I2V 模块,其中将图像视为单帧视频。联合训练的动机在于利用内部高质量和美学的图像数据集,以提高生成视频的帧质量。图像数据集部分还可以弥补视频数据集在多样性和数量上的不足。
Video to Video模块
V2V 模块的设计与 I2V 模块类似。它与 I2V 模块共享相同的主干和空间层。它的运动模块是使用高分辨率视频子集进行单独微调以进行视频超分辨率的。图像外观编码器和 ControlNet 模块也在这里使用。这是至关重要的,因为生成的视频帧具有更高的分辨率。利用参考图像的信息有助于通过减少结构错误和故障率来引导视频扩散步骤。此外,它还可以增强更高分辨率生成的细节。
视频帧插值(VFI)
VFI 模块使用一个内部训练的基于 GAN 的 VFI 模型。它采用了增强型可变分离卷积(EDSC)头 ,与基于 VQ-GAN 的架构配对,类似于 [8] 所进行的研究中使用的自动编码器模型。为了进一步提高其稳定性和流畅性,使用了[13]中提出的预训练轻量级插值模型。
实验
人工评估
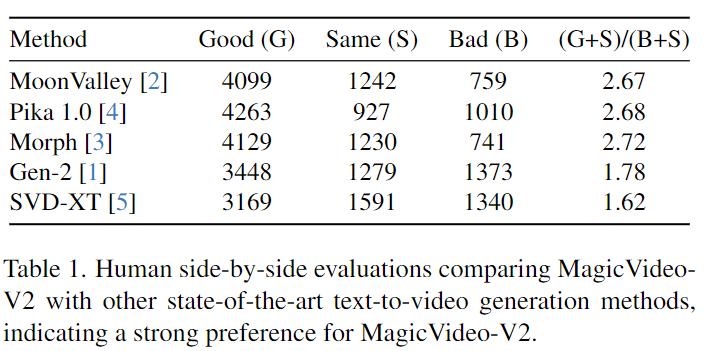
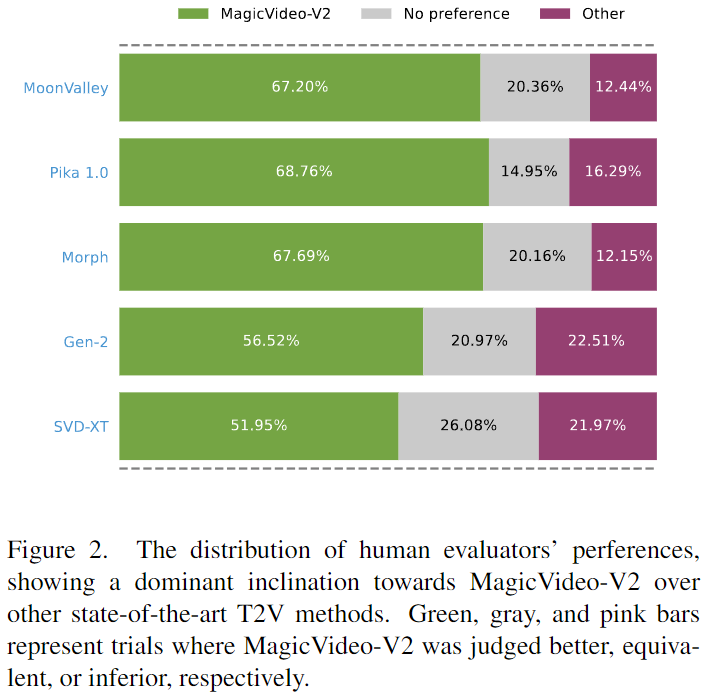
为了评估 MagicVideo-V2,邀请人工评估员进行与当代最先进的 T2V 系统的比较分析。61 名评估员小组对 MagicVideo-V2 和另一种 T2V 方法之间的 500 次并行比较进行了评分。每个选民在每一轮比较中基于相同的文本提示,被呈现一对随机视频,其中包括我们的一个与竞争对手的一个。他们被提供了三个评估选项 - 好、相同或差 - 分别表示对 MagicVideo-V2 的偏好、无偏好或对竞争 T2V 方法的偏好。评估员被要求根据他们在三个标准上的总体偏好投票:
1)哪个视频具有更高的帧质量和整体视觉吸引力。
2)哪个视频在时间上更一致,具有更好的运动范围和运动有效性。
3)哪个视频具有更少的结构错误或不良情况。
这些试验的统计数据可以在下表 1 中找到,其偏好比例显示在下图 2 中。结果清楚地表明 MagicVideo-V2 更受青睐,从人类视觉感知的角度证明了其卓越的性能。
定性示例
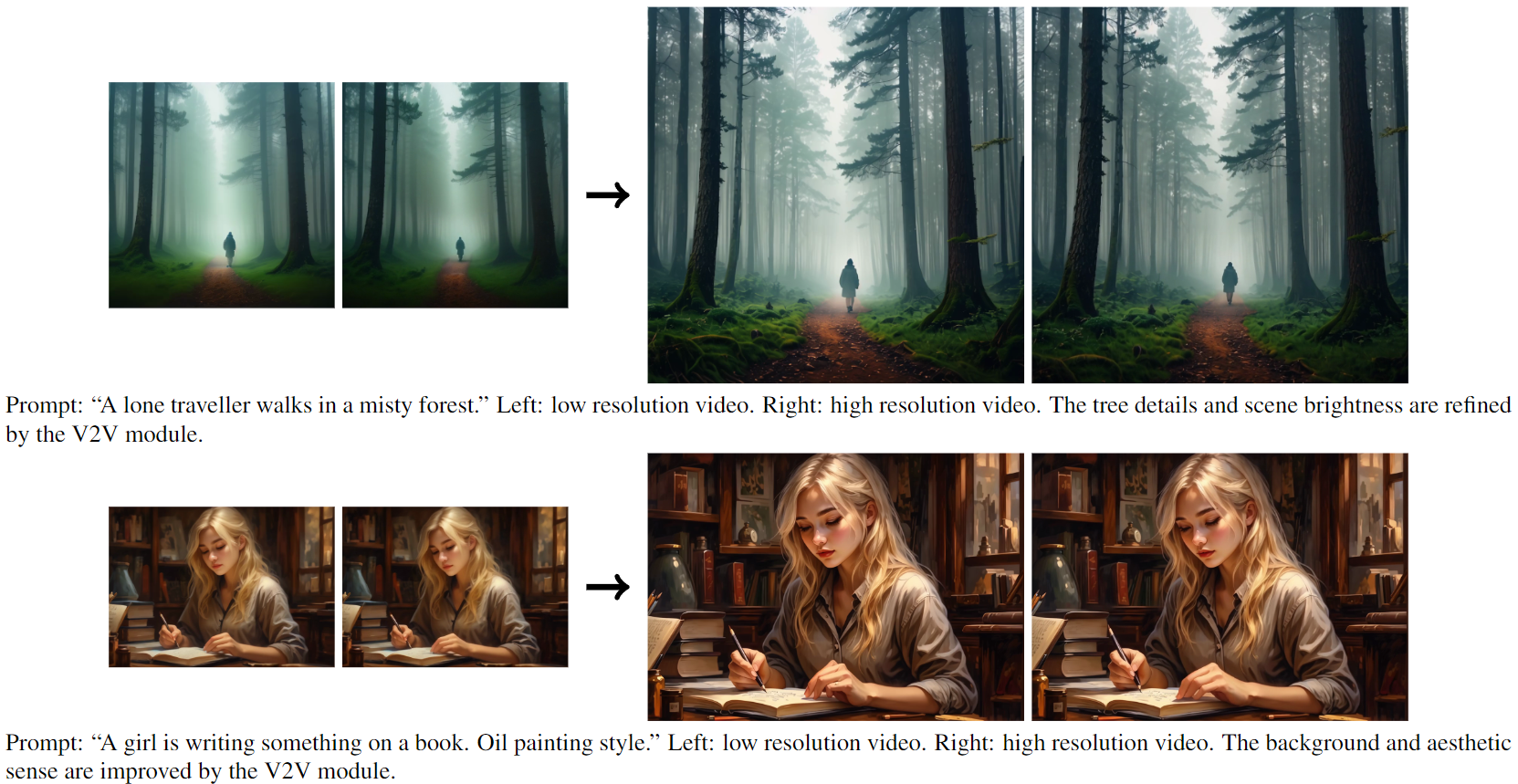
在下图3中呈现了 MagicVideo-V2 的精选定性示例。为了更好的观看体验,邀请读者在我们的项目网站上观看附带的视频。如前所述,MagicVideo-V2 的 I2V 和 V2V 模块擅长矫正和改进 T2I 模块的缺陷,生成流畅而富有审美的视频。

下图4中展示了一些例子。


结论
MagicVideo-V2 提出了一种新的文本到视频生成流程。综合评估得到了人类裁判的支持,证实了 MagicVideo-V2 超越了现有技术方法。MagicVideo-V2 的模块化设计,整合了文本到图像、图像到视频、视频到视频和视频帧插值,为生成流畅且高审美的视频提供了一种新的策略。
参考文献
[1] MagicVideo-V2: Multi-Stage High-Aesthetic Video Generation
?多精彩内容,请关注公众号:AI生成未来

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 随机数的实现——rand函数、srand函数和time函数
- AI 和 XR:将扩展现实体验带给千家万户
- RT-Thread 线程管理
- Golang 中高级工程师学习笔记
- leetcode670-最大交换
- 浅谈企业定岗定编工作中的几点误区
- 怎样提取视频号里的视频,视频下载小助手工具可下载吗?
- 【Qt-QFile-QDir】
- 什么是跨境电商独立站?
- 【MATLAB源码-第104期】基于matlab的MPSK和MQAM调制解调方式仿真,输出误码率曲线。