《手把手教你》系列练习篇之5-python+ selenium自动化测试(详细教程)
1.简介
相信各位小伙伴或者同学们通过前面已经介绍了的Python+Selenium基础篇,通过前面几篇文章的介绍和练习,Selenium+Python的webUI自动化测试算是 一只脚已经迈入这个门槛了要想第二只脚也迈进来。那么就要继续跟随宏哥的脚步继续前行。接下来,宏哥
计划写第二个系列:练习篇,通过一些练习,了解和掌握一些Selenium常用的接口或者方法。同时也可以把各位小伙伴或者童鞋们的基础夯实一下、巩固一下。这样有助于小伙伴或者同学们更快的将自己在门外的第二只脚迈进来,加入自动化测试的队伍中。
本文通过练习三个知识点:正则提取关键字、ID和tag name定位web页面元素。
2. 练习场景:
例如:在某一个网页上有些字段或者关键字等信息是我们感兴趣的,我们希望将其摘取出来,进行其他操作。但是这些字段可能在一个网页的不同地方。例如,我们需要在关于百度页面-联系我们,摘取全部的邮箱。
3. 思路拆分:
1. 首先,需要得到当前页面的source内容,就像,打开一个页面,右键-查看页面源代码。
2. 找出规律,通过正则表达式去摘取匹配的字段,存储到一个字典或者列表。
3. 循环打印字典或列表中内容,Python中用 for 语句实现。
4.技术角度实现相关方法:
1. 查看页面的源代码,在Selenium中有driver.page_source 这个方法得到
2. Python中利用正则,需要导入re模块
3. 将字段通过下列代码打印出来
for email in emails :
print email
4.1 代码实现
想法技术角度方法都找到,我们新建一个extract_email.py 文件,输入如下代码:
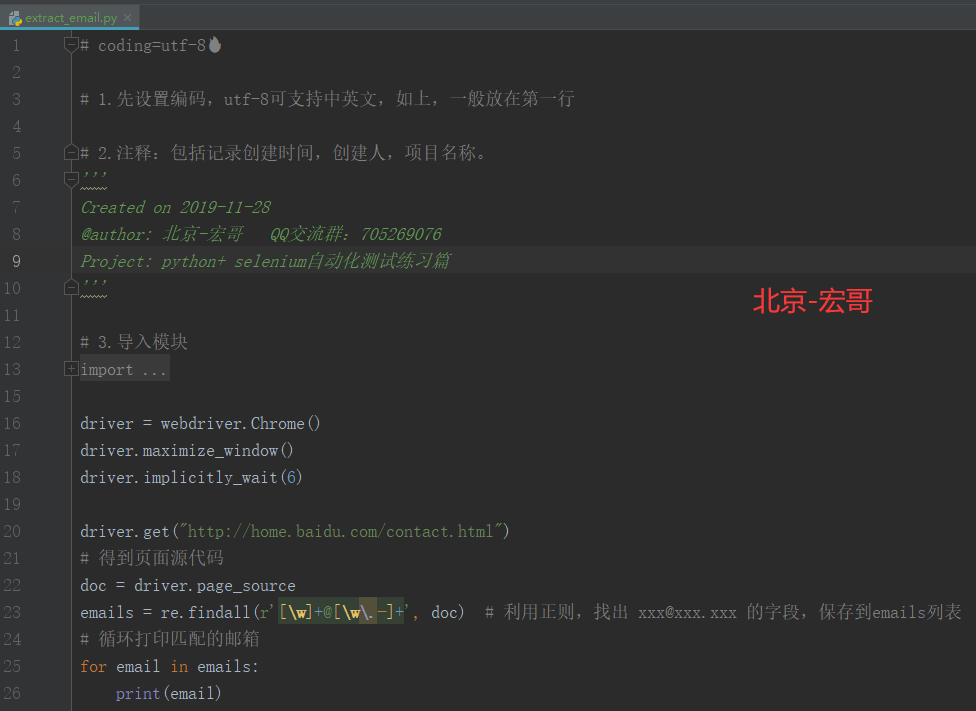
4.2 参考代码:
# coding=utf-8🔥
# 1.先设置编码,utf-8可支持中英文,如上,一般放在第一行
# 2.注释:包括记录创建时间,创建人,项目名称。
'''
Created on 2019-11-28
@author: 北京-宏哥 QQ交流群:705269076
Project: python+ selenium自动化测试练习篇
'''
# 3.导入模块
from selenium import webdriver
import re
driver = webdriver.Chrome()
driver.maximize_window()
driver.implicitly_wait(6)
driver.get("http://home.baidu.com/contact.html")
# 得到页面源代码
doc = driver.page_source
emails = re.findall(r'[\w]+@[\w\.-]+', doc) # 利用正则,找出 xxx@xxx.xxx 的字段,保存到emails列表
# 循环打印匹配的邮箱
for email in emails:
print(email)
4.3 解释说明:
在python正则表达式语法中,Python中字符串前面加上 r 表示原生字符串,用\w表示匹配字母数字及下划线。re模块下findall方法返回的是一个匹配子字符串的列表。
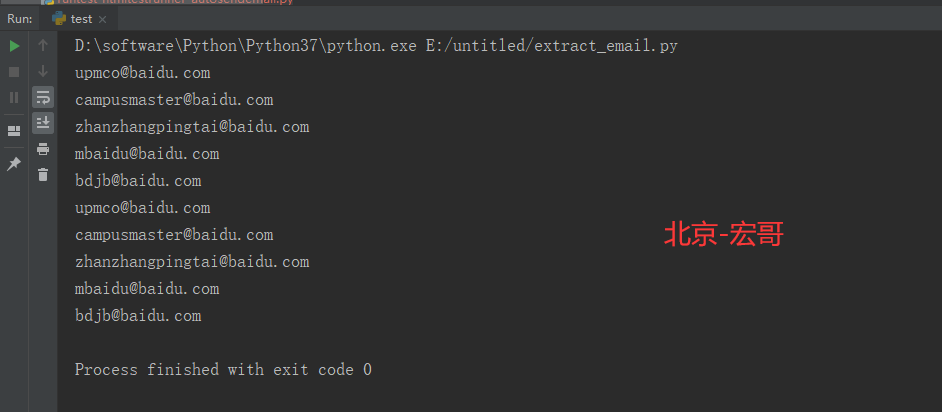
4.4 运行结果:
运行代码后,控制台打印如下图的结果
5.利用ID定位元素
在上边,我们介绍了如何摘取页面字段,通过正则进行匹配符合要求的字段。如果感觉有点困难,不能立马理解,没有关系。把字符串摘取放到第一篇,是因为自动化测试脚本,经常要利用字符串操作,字符串切割,查找,匹配等手段,得到新的字符串或字符串数组,然后根据新得到的字符串进行判断用例是否通过。
? ? ? 下面介绍如何通过元素节点信息ID来定位该元素,使用id来定位元素虽然效率要高于XPath,但是实际测试测项目,能直接通过id定位的元素还是比较少,以下来举例百度首页搜索输入框的id定位。
5.1 代码实现
我们新建一个test_baidu_id.py文件,输入如下代码:
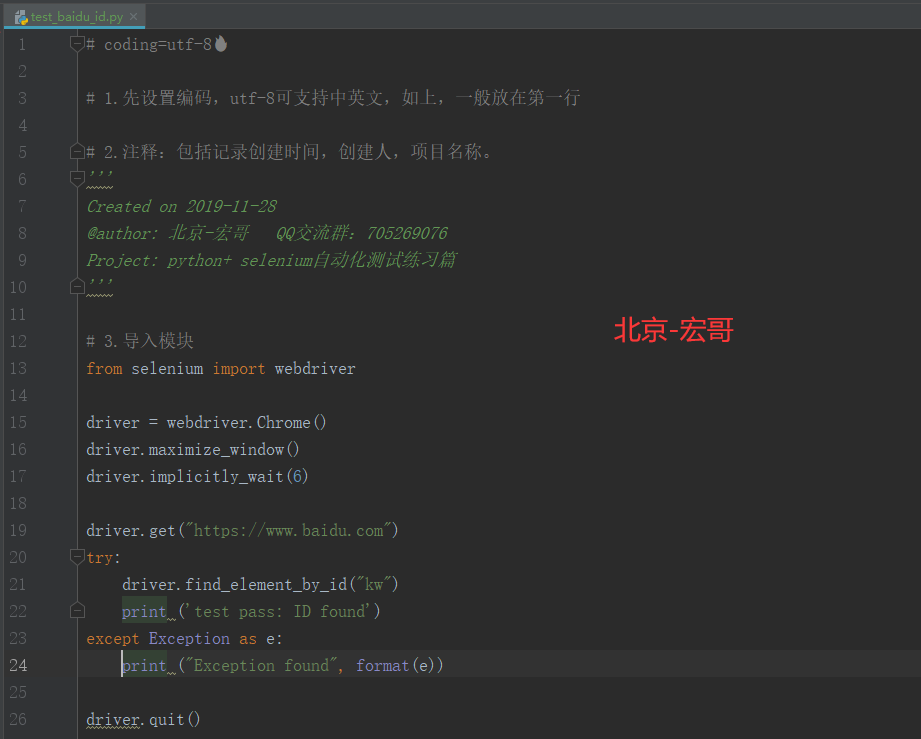
5.2 参考代码
# coding=utf-8🔥
# 1.先设置编码,utf-8可支持中英文,如上,一般放在第一行
# 2.注释:包括记录创建时间,创建人,项目名称。
'''
Created on 2019-11-28
@author: 北京-宏哥 QQ交流群:705269076
Project: python+ selenium自动化测试练习篇
'''
# 3.导入模块
from selenium import webdriver
driver = webdriver.Chrome()
driver.maximize_window()
driver.implicitly_wait(6)
driver.get("https://www.baidu.com")
try:
driver.find_element_by_id("kw")
print ('test pass: ID found')
except Exception as e:
print ("Exception found", format(e))
driver.quit()
这里,我们通过try except语句块来进行测试断言,这个在实际自动化测试脚本开发中,经常要用到处理异常。本文,我们学习了可以利用find_element_by_id()方法来定位网页元素对象。
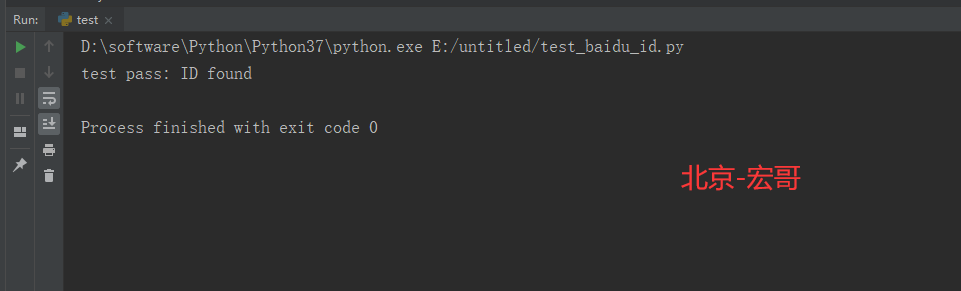
5.3 运行结果:
运行代码后,控制台打印如下图的结果
6. 利用tag name定位元素
?? 前边介绍了如何通过元素的id值来定位web元素,本文介绍如何通过tag name来定位元素。个人认为,通过tag name来定位还是有很大缺陷,定位不够精确。主要是tag name有很多重复的,造成了选择tag name来定位页面元素不准确,所以使用这个方法定位web元素的机会很少。
????? 什么是tag name? 还是以百度首页搜索输入框,在火狐浏览器,右键,通过firepath,检查元素,看下图:
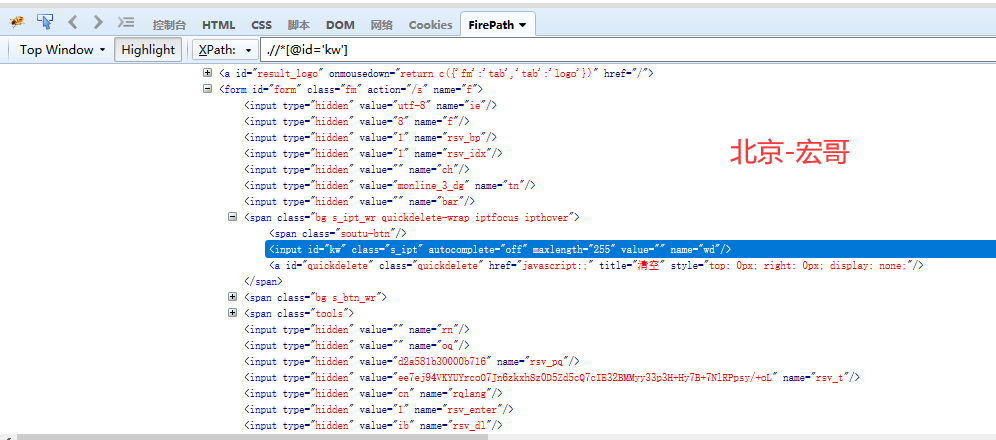
????? 上面图片中红色圈选区域的标签名称都是tag name;实际上我们目标元素是输入框,应该是input这个tag name,在图中蓝色高亮区域。但是如果只是通过input这个tag name来定位,发现上面有很多input的选项。所以我们扩大节点的参照选择,我们选择上面这个
form来作为我们tag name。
6.1 代码实现
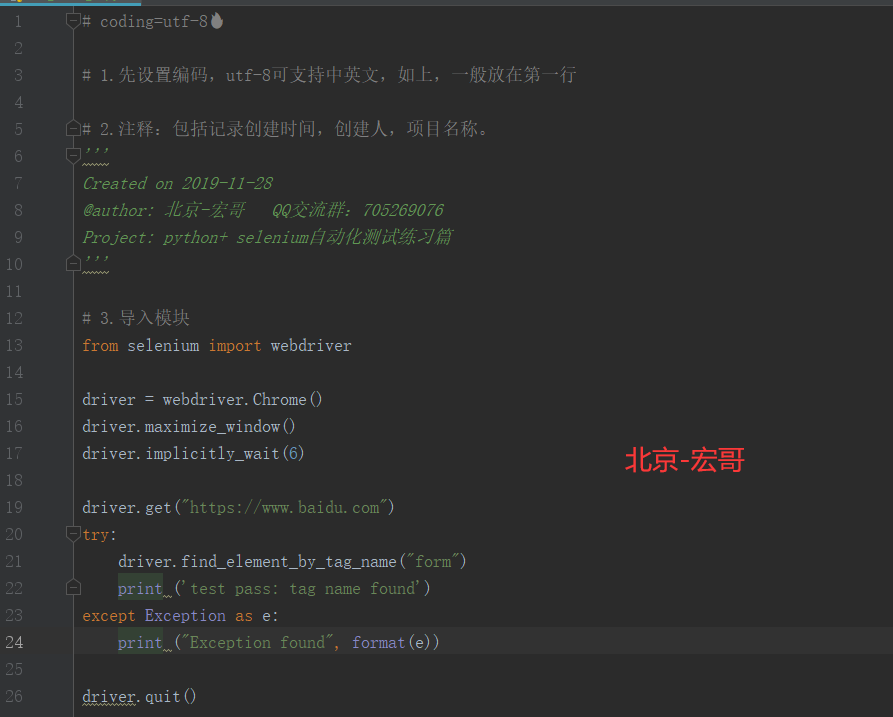
看看如何写定位form这个元素的脚本:
6.2 参考代码
# coding=utf-8🔥
# 1.先设置编码,utf-8可支持中英文,如上,一般放在第一行
# 2.注释:包括记录创建时间,创建人,项目名称。
'''
Created on 2019-11-28
@author: 北京-宏哥 QQ交流群:705269076
Project: python+ selenium自动化测试练习篇
'''
# 3.导入模块
from selenium import webdriver
driver = webdriver.Chrome()
driver.maximize_window()
driver.implicitly_wait(6)
driver.get("https://www.baidu.com")
try:
driver.find_element_by_tag_name("form")
print ('test pass: tag name found')
except Exception as e:
print ("Exception found", format(e))
driver.quit()
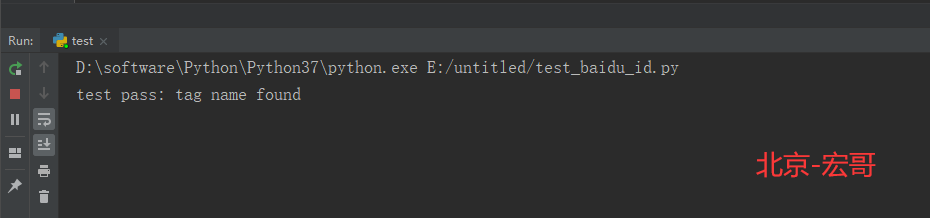
6.3 运行结果:
运行代码后,控制台打印如下图的结果
7. 小结
总结:本文介绍了webdriver 八大定位元素方法中的driver.find_element_by_tag_name("form") # form是tag name从实际项目中自动化脚本开发来看,使用这个方法定位元素的机会比较少,知道有这么一种方法就好了。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- vsCode编辑器中wxml微信小程序代码没有高亮
- tsmc12 OD.L.5 DRC
- Windows连接Ubuntu桌面
- 市场复盘总结 20240118
- 【flink番外篇】9、Flink Table API 支持的操作示例(2)- 通过Table API 和 SQL 创建视图
- UOS python+pyqt5实现COM和LPT回路测试
- 17/100全排列 18/100电话号码的字母组合 19/100四数之和
- Centos 7.9安装Oracle19c步骤亲测可用有视频
- 力扣hot100 寻找重复数 二分 抽屉原理
- YOLOv7优化:独家创新(Partial_C_Detect)检测头结构创新,实现涨点 | 检测头新颖创新系列