Springboot整合Elastic-job
一 概述
??Elastic-Job 最开始只有一个 elastic-job-core 的项目,定位轻量级、无中心化,最核心的服务就是支持弹性扩容和数据分片!从 2.X 版本以后,主要分为 Elastic-Job-Lite 和 Elastic-Job-Cloud 两个子项目。esjbo官网地址
- Elastic-Job-Lite 定位为轻量级 无 中 心 化 解 决 方 案 , 使 用jar 包 的 形 式 提 供 分 布 式 任 务 的 协 调 服 务 。
- Elastic-Job-Cloud 使用 Mesos + Docker 的解决方案,额外提供资源治理、应用分发以及进程隔离等服务(跟 Lite 的区别只是部署方式不同,他们使用相同的 API,只要开发一次)。
今天我们主要介绍的是Elastic-Job-Lite,最主要的功能特性如下:
- 分布式调度协调
- 弹性扩容缩容
- 失效转移
- 错过执行作业重触发
- 作业分片一致性,保证同一分片在分布式环境中仅一个执行实例
- 自诊断并修复分布式不稳定造成的问
- 支持并行调度
- 支持作业生命周期操作
- 丰富的作业类型
- Spring整合以及命名空间提供
- 运维平台
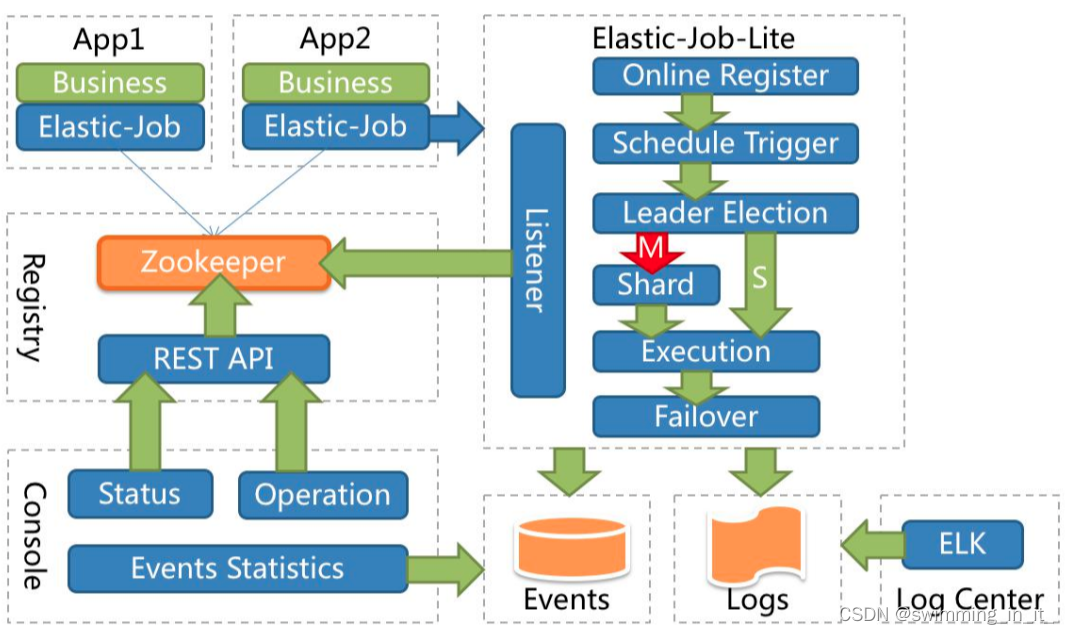
??应用在各自的节点执行任务,通过 zookeeper 注册中心协调。节点注册、节点选举、任务分片、监听都在 E-Job 的代码中完成。下图是官网提供得架构图。
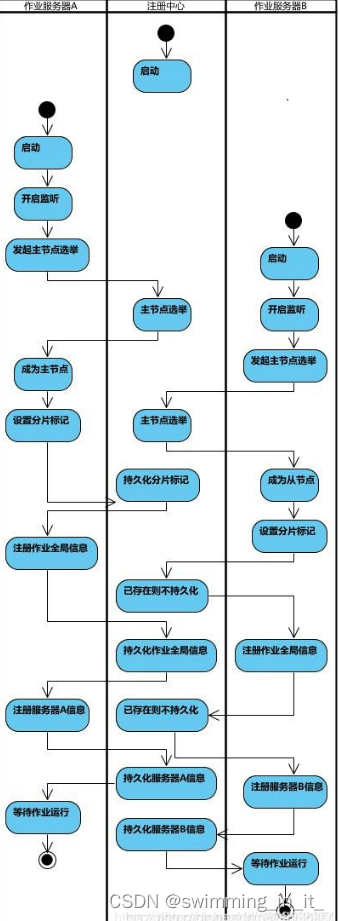
作业启动流程图:
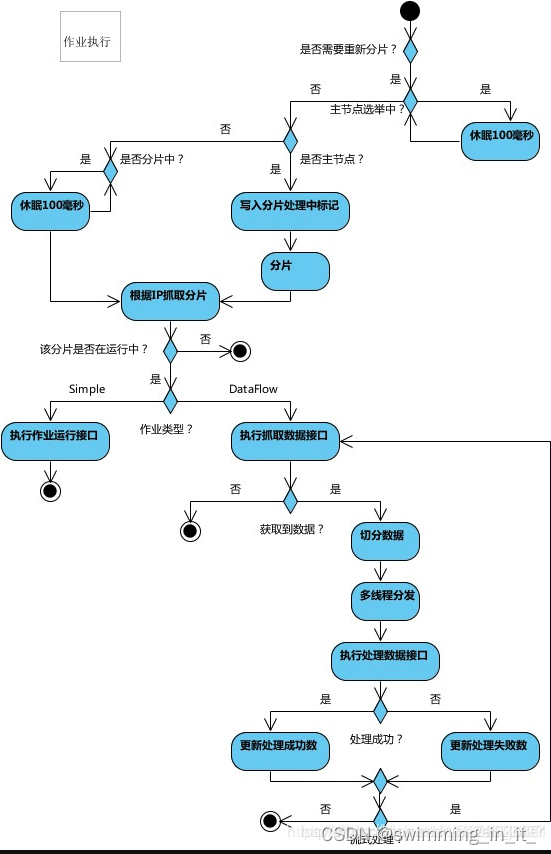
作业执行流程图:
1.1 基本概念
1.1.1 分片概念
? 任务的分布式执行,需要将一个任务拆分为多个独立的任务项,然后由分布式的服务器分别执行某一个或几个分片项。
例如:有一个遍历数据库某张表的作业,现有2台服务器。为了快速的执行作业,那么每台服务器应执行作业的50%。 为满足此需求,可将作业分成2片,每台服务器执行1片。作业遍历数据的逻辑应为:服务器A遍历ID以奇数结尾的数据;服务器B遍历ID以偶数结尾的数据。 如果分成10片,则作业遍历数据的逻辑应为:每片分到的分片项应为ID%10,而服务器A被分配到分片项0,1,2,3,4;服务器B被分配到分片项5,6,7,8,9,直接的结果就是服务器A遍历ID以0-4结尾的数据;服务器B遍历ID以5-9结尾的数据。
1.1.2 分片策略
shardingTotalCount:作业分片总数。jobShardingStrategyClass:作业分片策略实现类全路径。shardingItemParameters:分片序列号和个性化参数对照表。分片序列号和参数用等号分隔, 多个键值对用逗号分隔。分片序列号从0开始, 不可大于或等于作业分片总数。分片的维度通常有状态(state)、类型(accountType)、id分区等,需要按照业务合适选取。
elasticJob提供了如下三种分片策略,
- AverageAllocationJobShardingStrategy :(默认的分片策略) 基于平均分配算法的分片策略。
如果有3台服务器, 分成9片, 则每台服务器分到的分片是: 1=[0,1,2], 2=[3,4,5], 3=[6,7,8].
如果有3台服务器, 分成8片, 则每台服务器分到的分片是: 1=[0,1,6], 2=[2,3,7], 3=[4,5].
如果有3台服务器, 分成10片, 则每台服务器分到的分片是: 1=[0,1,2,9], 2=[3,4,5], 3=[6,7,8]
- OdevitySortByNameJobShardingStrategy:根据作业名的哈希值奇偶数决定IP升降序算法的分片策略。
作业名的哈希值为奇数则IP升序.
作业名的哈希值为偶数则IP降序.
用于不同的作业平均分配负载至不同的服务器.
eg:
如果有3台服务器, 分成2片, 作业名称的哈希值为奇数, 则每台服务器分到的分片是: 1=[0], 2=[1], 3=[].
如果有3台服务器, 分成2片, 作业名称的哈希值为偶数, 则每台服务器分到的分片是: 3=[0], 2=[1], 1=[].
- RotateServerByNameJobShardingStrategy:根据作业名的哈希值对服务器列表进行轮转的分片策略。
1.1.3 分片项与业务处理解耦
Elastic-Job并不直接提供数据处理的功能,框架只会将分片项分配至各个运行中的作业服务器,开发者需要自行处理分片项与真实数据的对应关系。
1.1.4 个性化参数
个性化参数即shardingItemParameter,可以和分片项匹配对应关系,用于将分片项的数字转换为更加可读的业务代码。
? 例如:按照地区水平拆分数据库,数据库A是北京的数据;数据库B是上海的数据;数据库C是广州的数据。 如果仅按照分片项配置,开发者需要了解0表示北京;1表示上海;2表示广州。 合理使用个性化参数可以让代码更可读,如果配置为0=北京,1=上海,2=广州,那么代码中直接使用北京,上海,广州的枚举值即可完成分片项和业务逻辑的对应关系。
1.1.5 任务类型
- Simple类型作业:意为简单实现,未经任何封装的类型。需实现SimpleJob接口。该接口仅提供单一方法用于覆盖,此方法将定时执行。与Quartz原生接口相似,但提供了弹性扩缩容和分片等功能。
- Dataflow类型:用于处理数据流,需实现DataflowJob接口。该接口提供2个方法可供覆盖,分别用于抓取(fetchData)和处理(processData)数据
- Script类型:作业意为脚本类型作业,支持shell,python,perl等所有类型脚本。只需通过控制台或代码配置scriptCommandLine即可,无需编码。执行脚本路径可包含参数,参数传递完毕后,作业框架会自动追加最后一个参数为作业运行时信息。
1.2 核心概念
1.2.1 分布式调度
Elastic-Job-Lite并无作业调度中心节点,而是基于部署作业框架的程序在到达相应时间点时各自触发调度。注册中心仅用于作业注册和监控信息存储。而主作业节点仅用于处理分片和清理等功能。
1.2.2 作业高可用
Elastic-Job-Lite提供最安全的方式执行作业。将分片总数设置为1,并使用多于1台的服务器执行作业,作业将会以1主n从的方式执行。
? 一旦执行作业的服务器崩溃,等待执行的服务器将会在下次作业启动时替补执行。开启失效转移功能效果更好,可以保证在本次作业执行时崩溃,备机立即启动替补执行。
1.2.3 最大限度利用资源
Elastic-Job-Lite也提供最灵活的方式,最大限度的提高执行作业的吞吐量。将分片项设置为大于服务器的数量,最好是大于服务器倍数的数量,作业将会合理的利用分布式资源,动态的分配分片项。
二 应用安装
2.1 zookeeper 安装
elastic-job-lite,是直接依赖 zookeeper 的,因此在开发之前我们需要先准备好对应的 zookeeper 环境,关于 zookeeper 的安装过程,就不多说了,非常简单,网上都有教程!
2.2 elastic-job-lite-console 安装
elastic-job-lite-console,主要是一个任务作业可视化界面管理系统。
可以单独部署,与平台不关,主要是通过配置注册中心和数据源来抓取数据。
获取的方式也很简单,直接访问https://github.com/apache/shardingsphere-elasticjob地址,然后切换到2.1.5的版本号,然后执行mvn clean install进行打包,获取对应的安装包将其解压,进行bin文件夹启动服务即可!
如果你的网速像蜗牛一样的慢,还有一个办法就是从这个地址https://gitee.com/elasticjob/elastic-job获取对应的源码!
启动服务后,在浏览器访问http://127.0.0.1:8899,输入账户、密码(都是root)即可进入控制台页面,类似如下界面!
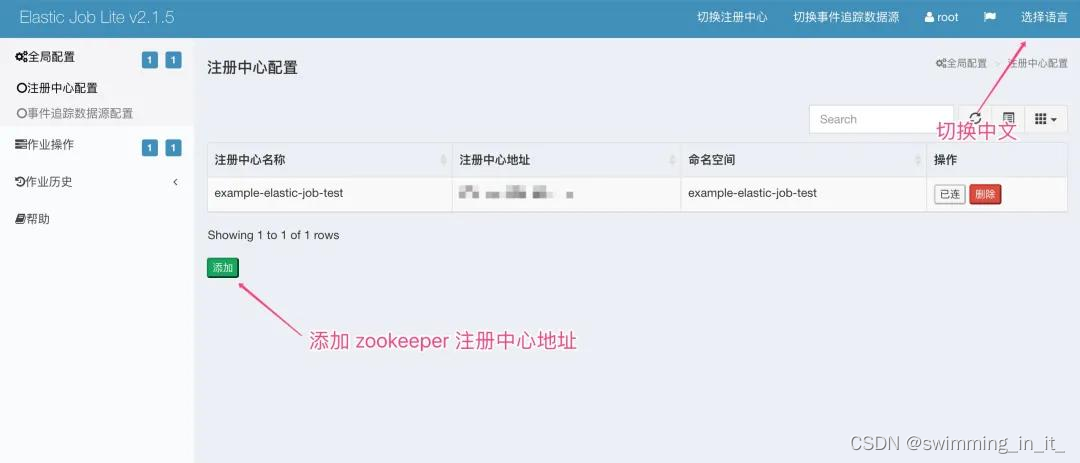
进入之后,将上文所在的 zookeeper 注册中心进行配置,包括数据库 mysql 的数据源也可以配置一下!
2.3 创建工程(自集成方式)
2.3.1 引入依赖和配置
本文采用springboot来搭建工程为例,创建工程并添加elastic-job-lite依赖!
<!-- 使用springframework自定义命名空间时引入 -->
<dependency>
<groupId>com.dangdang</groupId>
<artifactId>elastic-job-lite-spring</artifactId>
<version>2.1.5</version>
</dependency>
<!-- elastic-job-lite 默认依赖如下的模块,否则ZookeeperRegistryCenter无法注册 -->
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>2.10.0</version>
</dependency>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-framework</artifactId>
<version>2.10.0</version>
</dependency>
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>18.0</version>
</dependency>
在配置文件application.properties中提前配置好 zookeeper 注册中心相关信息!
#zookeeper config
zookeeper.serverList=127.0.0.1:2181
zookeeper.namespace=example-elastic-job-test
2.3.2 新建 ZookeeperConfig 配置类
@Configuration
@ConditionalOnExpression("'${zookeeper.serverList}'.length() > 0")
public class ZookeeperConfig {
/**
* zookeeper 配置
* @return
*/
@Bean(initMethod = "init")
public ZookeeperRegistryCenter zookeeperRegistryCenter(@Value("${zookeeper.serverList}") String serverList,
@Value("${zookeeper.namespace}") String namespace){
return new ZookeeperRegistryCenter(new ZookeeperConfiguration(serverList,namespace));
}
}
2.3.4 新建Simple任务处理类
- 编写一个SimpleJob接口的实现类MySimpleJob,当前工作主要是打印一条日志。
@Slf4j
public class MySimpleJob implements SimpleJob {
@Override
public void execute(ShardingContext shardingContext) {
log.info(String.format("Thread ID: %s, 作业分片总数: %s, " +
"当前分片项: %s.当前参数: %s," +
"作业名称: %s.作业自定义参数: %s"
,
Thread.currentThread().getId(),
shardingContext.getShardingTotalCount(),
shardingContext.getShardingItem(),
shardingContext.getShardingParameter(),
shardingContext.getJobName(),
shardingContext.getJobParameter()
));
}
}
- 创建一个MyElasticJobListener任务监听器,用于监听MySimpleJob的任务执行情况。
@Slf4j
public class MyElasticJobListener implements ElasticJobListener {
private long beginTime = 0;
@Override
public void beforeJobExecuted(ShardingContexts shardingContexts) {
beginTime = System.currentTimeMillis();
log.info("===>{} MyElasticJobListener BEGIN TIME: {} <===",shardingContexts.getJobName(), DateFormatUtils.format(new Date(), "yyyy-MM-dd HH:mm:ss"));
}
@Override
public void afterJobExecuted(ShardingContexts shardingContexts) {
long endTime = System.currentTimeMillis();
log.info("===>{} MyElasticJobListener END TIME: {},TOTAL CAST: {} <===",shardingContexts.getJobName(), DateFormatUtils.format(new Date(), "yyyy-MM-dd HH:mm:ss"), endTime - beginTime);
}
}
- 创建一个MySimpleJobConfig类,将MySimpleJob其注入到zookeeper。
@Configuration
public class MySimpleJobConfig {
/**
* 任务名称
*/
@Value("${simpleJob.mySimpleJob.name}")
private String mySimpleJobName;
/**
* cron表达式
*/
@Value("${simpleJob.mySimpleJob.cron}")
private String mySimpleJobCron;
/**
* 作业分片总数
*/
@Value("${simpleJob.mySimpleJob.shardingTotalCount}")
private int mySimpleJobShardingTotalCount;
/**
* 作业分片参数
*/
@Value("${simpleJob.mySimpleJob.shardingItemParameters}")
private String mySimpleJobShardingItemParameters;
/**
* 自定义参数
*/
@Value("${simpleJob.mySimpleJob.jobParameters}")
private String mySimpleJobParameters;
@Autowired
private ZookeeperRegistryCenter registryCenter;
@Bean
public MySimpleJob mySimpleJob() {
return new MySimpleJob();
}
@Bean(initMethod = "init")
public JobScheduler simpleJobScheduler(final MySimpleJob mySimpleJob) {
//配置任务监听器
MyElasticJobListener elasticJobListener = new MyElasticJobListener();
return new SpringJobScheduler(mySimpleJob, registryCenter, getLiteJobConfiguration(), elasticJobListener);
}
private LiteJobConfiguration getLiteJobConfiguration() {
// 定义作业核心配置
JobCoreConfiguration simpleCoreConfig = JobCoreConfiguration.newBuilder(mySimpleJobName, mySimpleJobCron, mySimpleJobShardingTotalCount).
shardingItemParameters(mySimpleJobShardingItemParameters).jobParameter(mySimpleJobParameters).build();
// 定义SIMPLE类型配置
SimpleJobConfiguration simpleJobConfig = new SimpleJobConfiguration(simpleCoreConfig, MySimpleJob.class.getCanonicalName());
// 定义Lite作业根配置
LiteJobConfiguration simpleJobRootConfig = LiteJobConfiguration.newBuilder(simpleJobConfig).overwrite(true).build();
return simpleJobRootConfig;
}
}
- 在配置文件application.properties中配置好对应的mySimpleJob参数!
#elastic job
#simpleJob类型的job
simpleJob.mySimpleJob.name=mySimpleJob
simpleJob.mySimpleJob.cron=0/15 * * * * ?
simpleJob.mySimpleJob.shardingTotalCount=3
simpleJob.mySimpleJob.shardingItemParameters=0=a,1=b,2=c
simpleJob.mySimpleJob.jobParameters=helloWorld
5.运行程序,查看效果
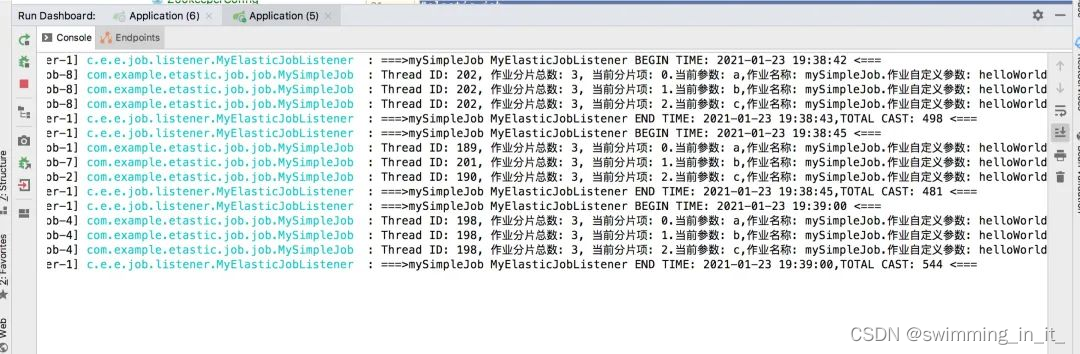
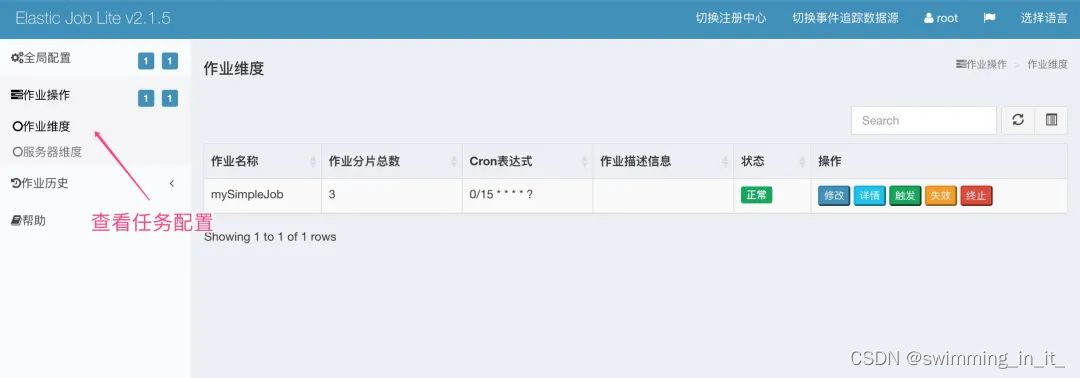
在上图demo中,配置的分片数为3,这个时候会有3个线程进行同时执行任务,因为都是在一台机器上执行的,这个任务被执行来3次,下面修改一下端口配置,创建三个相同的服务实例,在看看效果如下:
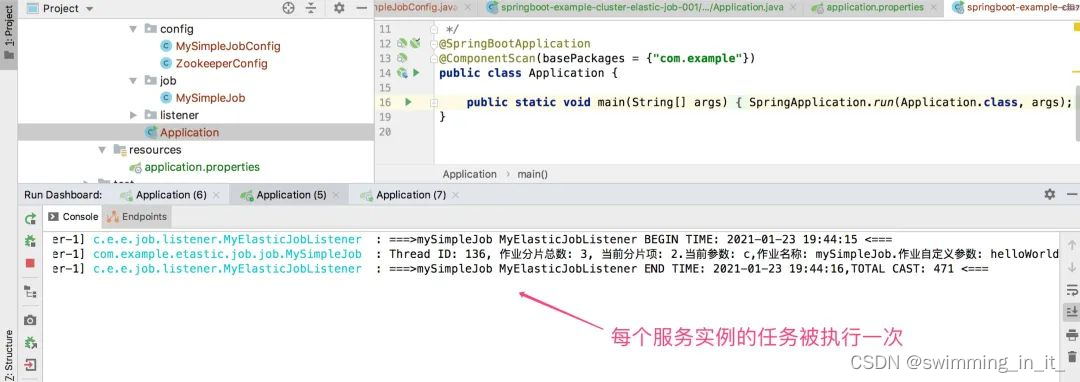
2.3.5 新建DataFlowJob类型作业
- 创建一个DataflowJob类型的实现类MyDataFlowJob。
@Slf4j
public class MyDataFlowJob implements DataflowJob<String> {
private boolean flag = false;
@Override
public List<String> fetchData(ShardingContext shardingContext) {
log.info("开始获取数据");
if (flag) {
return null;
}
return Arrays.asList("qingshan", "jack", "seven");
}
@Override
public void processData(ShardingContext shardingContext, List<String> data) {
for (String val : data) {
// 处理完数据要移除掉,不然就会一直跑,处理可以在上面的方法里执行。这里采用 flag
log.info("开始处理数据:" + val);
}
flag = true;
}
}
- 接着创建MyDataFlowJob的配置类,将其注入到zookeeper注册中心。
Configuration
public class MyDataFlowJobConfig {
/**
* 任务名称
*/
@Value("${dataflowJob.myDataflowJob.name}")
private String jobName;
/**
* cron表达式
*/
@Value("${dataflowJob.myDataflowJob.cron}")
private String jobCron;
/**
* 作业分片总数
*/
@Value("${dataflowJob.myDataflowJob.shardingTotalCount}")
private int jobShardingTotalCount;
/**
* 作业分片参数
*/
@Value("${dataflowJob.myDataflowJob.shardingItemParameters}")
private String jobShardingItemParameters;
/**
* 自定义参数
*/
@Value("${dataflowJob.myDataflowJob.jobParameters}")
private String jobParameters;
@Autowired
private ZookeeperRegistryCenter registryCenter;
@Bean
public MyDataFlowJob myDataFlowJob() {
return new MyDataFlowJob();
}
@Bean(initMethod = "init")
public JobScheduler dataFlowJobScheduler(final MyDataFlowJob myDataFlowJob) {
MyElasticJobListener elasticJobListener = new MyElasticJobListener();
return new SpringJobScheduler(myDataFlowJob, registryCenter, getLiteJobConfiguration(), elasticJobListener);
}
private LiteJobConfiguration getLiteJobConfiguration() {
// 定义作业核心配置
JobCoreConfiguration dataflowCoreConfig = JobCoreConfiguration.newBuilder(jobName, jobCron, jobShardingTotalCount).
shardingItemParameters(jobShardingItemParameters).jobParameter(jobParameters).build();
// 定义DATAFLOW类型配置
DataflowJobConfiguration dataflowJobConfig = new DataflowJobConfiguration(dataflowCoreConfig, MyDataFlowJob.class.getCanonicalName(), false);
// 定义Lite作业根配置
LiteJobConfiguration dataflowJobRootConfig = LiteJobConfiguration.newBuilder(dataflowJobConfig).overwrite(true).build();
return dataflowJobRootConfig;
}
}
- 最后,在配置文件application.properties中配置好对应的myDataflowJob参数!
#dataflow类型的job
dataflowJob.myDataflowJob.name=myDataflowJob
dataflowJob.myDataflowJob.cron=0/15 * * * * ?
dataflowJob.myDataflowJob.shardingTotalCount=1
dataflowJob.myDataflowJob.shardingItemParameters=0=a,1=b,2=c
dataflowJob.myDataflowJob.jobParameters=myDataflowJobParamter
- 运行程序,查看效果
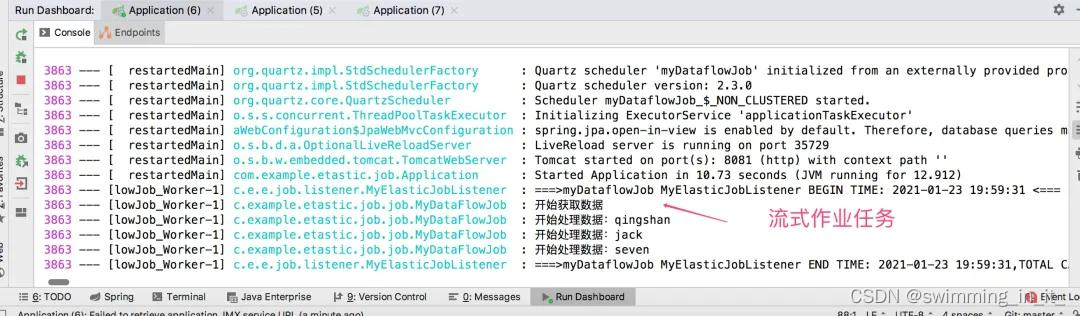
需要注意的地方是,如果配置的是流式处理类型,它会不停的拉取数据、处理数据,在拉取的时候,如果返回为空,就不会处理数据!如果配置的是非流式处理类型,和上面介绍的simpleJob类型,处理一样!
2.3.6 新建ScriptJob类型作业
- ScriptJob 类型的任务配置:主要是用于定时执行某个脚本,一般用的比较少!因为目标是脚本,没有执行的任务,所以无需编写任务作业类型!只需要编写一个ScriptJob类型的配置类即可,命令是echo 'Hello World !内容!
@Configuration
public class MyScriptJobConfig {
/**
* 任务名称
*/
@Value("${scriptJob.myScriptJob.name}")
private String jobName;
/**
* cron表达式
*/
@Value("${scriptJob.myScriptJob.cron}")
private String jobCron;
/**
* 作业分片总数
*/
@Value("${scriptJob.myScriptJob.shardingTotalCount}")
private int jobShardingTotalCount;
/**
* 作业分片参数
*/
@Value("${scriptJob.myScriptJob.shardingItemParameters}")
private String jobShardingItemParameters;
/**
* 自定义参数
*/
@Value("${scriptJob.myScriptJob.jobParameters}")
private String jobParameters;
@Autowired
private ZookeeperRegistryCenter registryCenter;
@Bean(initMethod = "init")
public JobScheduler scriptJobScheduler() {
MyElasticJobListener elasticJobListener = new MyElasticJobListener();
return new JobScheduler(registryCenter, getLiteJobConfiguration(), elasticJobListener);
}
private LiteJobConfiguration getLiteJobConfiguration() {
// 定义作业核心配置
JobCoreConfiguration scriptCoreConfig = JobCoreConfiguration.newBuilder(jobName, jobCron, jobShardingTotalCount).
shardingItemParameters(jobShardingItemParameters).jobParameter(jobParameters).build();
// 定义SCRIPT类型配置
ScriptJobConfiguration scriptJobConfig = new ScriptJobConfiguration(scriptCoreConfig, "echo 'Hello World !'");
// 定义Lite作业根配置
LiteJobConfiguration scriptJobRootConfig = LiteJobConfiguration.newBuilder(scriptJobConfig).overwrite(true).build();
return scriptJobRootConfig;
}
}
- 在配置文件application.properties中配置好对应的myScriptJob参数!
#script类型的job
scriptJob.myScriptJob.name=myScriptJob
scriptJob.myScriptJob.cron=0/15 * * * * ?
scriptJob.myScriptJob.shardingTotalCount=3
scriptJob.myScriptJob.shardingItemParameters=0=a,1=b,2=c
scriptJob.myScriptJob.jobParameters=myScriptJobParamter
- 运行程序,看看效果
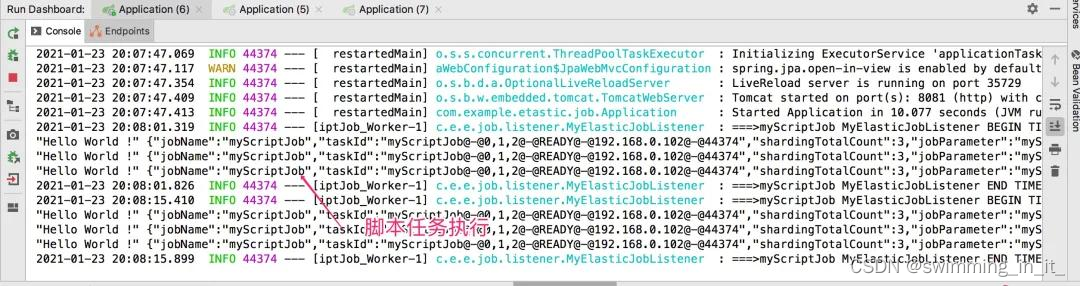
2.3.7 任务状态持久化
可能有的人会发出疑问,elastic-job是如何存储数据的,用ZooInspector客户端链接zookeeper注册中心,你发现对应的任务配置被存储到相应的树根上!而具体作业任务执行轨迹和状态结果是不会存储到zookeeper,需要我们在项目中通过数据源方式进行持久化!
将任务状态持久化到数据库配置过程也很简单,只需要在对应的配置类上注入数据源即可,以MySimpleJobConfig为例,代码如下:
@Configuration
public class MySimpleJobConfig {
/**
* 任务名称
*/
@Value("${simpleJob.mySimpleJob.name}")
private String mySimpleJobName;
/**
* cron表达式
*/
@Value("${simpleJob.mySimpleJob.cron}")
private String mySimpleJobCron;
/**
* 作业分片总数
*/
@Value("${simpleJob.mySimpleJob.shardingTotalCount}")
private int mySimpleJobShardingTotalCount;
/**
* 作业分片参数
*/
@Value("${simpleJob.mySimpleJob.shardingItemParameters}")
private String mySimpleJobShardingItemParameters;
/**
* 自定义参数
*/
@Value("${simpleJob.mySimpleJob.jobParameters}")
private String mySimpleJobParameters;
@Autowired
private ZookeeperRegistryCenter registryCenter;
@Autowired
private DataSource dataSource;;
@Bean
public MySimpleJob stockJob() {
return new MySimpleJob();
}
@Bean(initMethod = "init")
public JobScheduler simpleJobScheduler(final MySimpleJob mySimpleJob) {
//添加事件数据源配置
JobEventConfiguration jobEventConfig = new JobEventRdbConfiguration(dataSource);
MyElasticJobListener elasticJobListener = new MyElasticJobListener();
return new SpringJobScheduler(mySimpleJob, registryCenter, getLiteJobConfiguration(), jobEventConfig, elasticJobListener);
}
private LiteJobConfiguration getLiteJobConfiguration() {
// 定义作业核心配置
JobCoreConfiguration simpleCoreConfig = JobCoreConfiguration.newBuilder(mySimpleJobName, mySimpleJobCron, mySimpleJobShardingTotalCount).
shardingItemParameters(mySimpleJobShardingItemParameters).jobParameter(mySimpleJobParameters).build();
// 定义SIMPLE类型配置
SimpleJobConfiguration simpleJobConfig = new SimpleJobConfiguration(simpleCoreConfig, MySimpleJob.class.getCanonicalName());
// 定义Lite作业根配置
LiteJobConfiguration simpleJobRootConfig = LiteJobConfiguration.newBuilder(simpleJobConfig).overwrite(true).build();
return simpleJobRootConfig;
}
}
同时,需要在配置文件application.properties中配置好对应的datasource参数!
spring.datasource.url=jdbc:mysql://127.0.0.1:3306/example-elastic-job-test
spring.datasource.username=root
spring.datasource.password=root
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
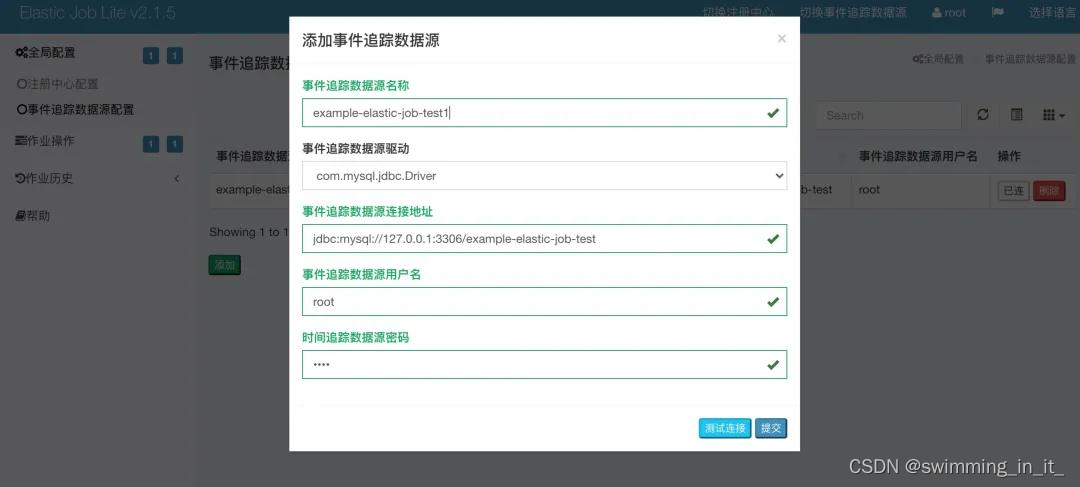
运行程序,然后在elastic-job-lite-console控制台配置对应的数据源!
注意:该功能Mysql数据库的话只支持5.7,其他版本则无法连接
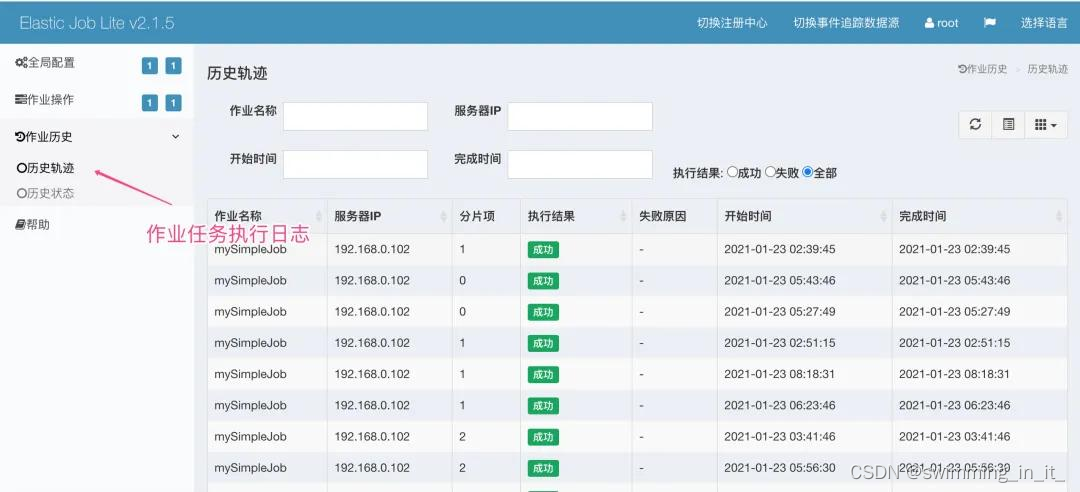
最后,点击【作业轨迹】即可查看对应作业执行情况!

2.4 创建工程(start集成方式)
具体 参考(推荐):https://blog.csdn.net/baidu_21349635/article/details/106317774
三 常见问题集锦
参考文献:
https://blog.csdn.net/qq_34350584/article/details/119754657
https://blog.csdn.net/lvlei19911108/article/details/118633115
https://blog.csdn.net/cicada_smile/article/details/104810958
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- react项目运行卡在编译:您当前运行的TypeScript版本不受@TypeScript eslint/TypeScript estree的官方支持
- 精品Nodejs实现的旅游景点的设计与实现
- 解决docker容器内无法连接宿主redis
- go切片参数传递用值还是指针
- MongoDB ReplicaSet 部署
- 【Python可视化系列】一文教会你绘制美观的热力图(理论+源码)
- canvas+fabric实现自定义封面
- 市场上的卖出和买入订单如何形成?fpmarkets澳福简单聊聊
- UDP Ping程序实现--第1关:Ping服务端创建UDP套接字
- 【FPGA】分享一些FPGA视频图像处理相关的书籍