ViTDet论文笔记
arxiv:https://arxiv.org/abs/2203.16527
GitHub:https://github.com/ViTAE-Transformer/ViTDet
摘要
本文提出使用plain,non-hierarchical视觉transformer作为目标检测的主干网络。通过这种设计可以使得ViT结构模型不需要再重新设计一个分层ViT进行预训练然后微调进行目标检测。在微调阶段通过微小调整,plain主干的检测器可以取得不错的效果。此外,作者观察到:
- 基于单尺度的特征图构建简单特征金字塔结构是非常有效的;
- 利用窗口注意力(无需移位)并配合少量的跨窗口传播块,能够在减少计算量的同时,仍然有效地捕获图像的全局信息;
作者提出了ViTDet检测模型,该模型使用基于Masked Autoencoders (MAE)预训练的普通ViT作为其骨干网络,尽管之前的SOTA方法都是基于分层的骨干网络,但是ViTDet仍然可以与它们竞争。在使用仅有ImageNet-1K预训练的模型进行测试时,ViTDet在COCO上能达到61.3%的mAP,表明了ViTDet具有很高的物体检测能力。
前提知识
过去一年以来,视觉Transformer被证明是一种强大的用于视觉识别的骨干网络。与典型的卷积神经网路(ConvNets)不同,原始的ViT是一种简单,非分层的架构,在整个过程保持单一尺度的特征映射。然而,这种“极简主义”的追求在应用到目标检测任务遇到挑战。例如,如何在下游任务中处理多尺度预测,而上游预训练使用的是简单的骨干网络?因为简单的ViT骨干网络可能无法有效地捕获不同尺度的物体特征,在应用到下游任务中通常需要重新设计网络。
对于高分辨率的检测任务,简单的视觉Transformer是否效率过低?一个解决方案是放弃简单ViT的设计,重新引入分层设计到骨干网络。例如,Swin Transformer和其他相关工作,可以继承基于卷积神经网络检测器的设计,并已经取得较好的结果。
本文提出了另外一个方向:使用简单,非分层作为目标检测任务的骨干网络。这是的预训练设计与微调需求解耦,保持上游任务与下游任务的独立性。“较少归纳偏差”指的是ViT模型相对于传统卷积网络没有对输入数据的特定结构做过多的假设,而是通过自注意力机制自动学习数据的内在关系。这种设计理念有可能帮助模型学习更通用、更鲁棒的特征,有利于模型在各种任务和数据集上的泛化性能。
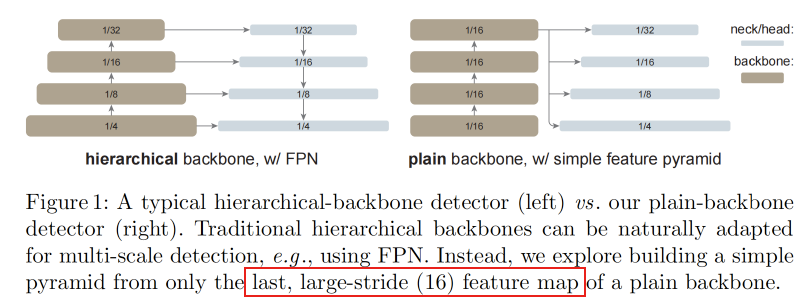
本文提出的方案不是要开发新的组件,而是进行最小的适配。具体来说,只从简单的ViT骨干网络的最后一个特征图上构建一个简单的特征金字塔。这放弃了FPN设计,并取消了分层骨干网络的要求。为了有效地从高分辨率图像中提取特征,检测器使用简单的非重叠窗口注意力。少量的跨窗口块,可以是全局注意力或者卷积,用来传播信息。这些适配只在微调阶段进行,并不改变预训练。
ViTDet在COCO数据集上,仅仅使用ImageNet-1K预训练的MAE作为骨干网络,实现了61.3%的mAP。本文提出的方法保持了将目标检测特定任务与任务无关的预训练进行解耦的理念,保持了模型设计的间接性和通用性,可以灵活地适应不同的任务和数据集。
网络结构
作者阐述了他们的研究目标,即去除骨干网络的层次性约束,以便探索简单骨干网络的物体检测。为了达到这个目标,他们只在微调阶段对简单骨干网络进行最小的修改,以适应物体检测任务。在这些调整之后,原则上可以应用任何检测器头部,他们选择使用Mask R-CNN及其扩展。他们的目标并不是开发新的组件,而是关注在他们的探索中可以得出什么新的见解。
简单特征金字塔
由于骨干网络是非分层的,那么FPN的输入无法满足,因为骨干网络中的所有特征图都是同一分辨率的。在这种情况下,作者只使用来自骨干网络的最后一个特征图,并应用一组卷积或反卷积,以生成多尺度特征图。具体而言,原始ViT的特征图缩放因子为
1
16
\frac{1}{16}
161?,使用卷积,步长分别为{
2
,
1
,
1
2
,
1
4
2,1,\frac{1}{2},\frac{1}{4}
2,1,21?,41?},得到特征图的缩放因子分别为{
1
32
,
1
16
,
1
8
,
1
4
\frac{1}{32},\frac{1}{16},\frac{1}{8},\frac{1}{4}
321?,161?,81?,41?},这种方案称为“简单特征金字塔”。
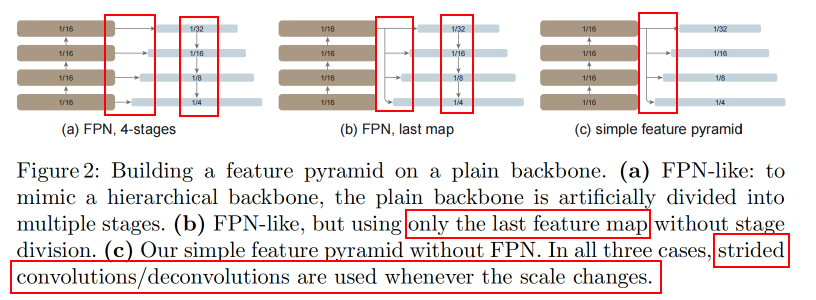
如上图所示,作者比较了两种建立在简单ViT上的FPN变体。第一种变体中,骨干网络被人为地划分成多个阶段,以模仿分层骨干的阶段,同时应用横向和自上而下的连接。第二种变体和第一种类似。作者在后续的实验中证明这些FPN变体是不必要的。
骨干网络调整
在预训练阶段模型进行全局自注意力运算,以学习全局的特征和上下文信息。然后,在微调阶段,模型将使用更高分辨率的输入,以提取更细粒度的特征和信息,以此改善在物体检测任务上的性能。
在微调过程中,给定一个高分辨率的特征图,将其划分为规则的、非重叠的窗口,每个窗口内部都计算自注意力,这在原始的Transformer中被称为“受限”的自注意力。
与Swin采用shift window不同,作者为了允许信息传递,使用了一下可以跨窗口的blocks。将整个骨干网络划分为4个阶段,在每个阶段的最后block上应用信息传播策略。有如下两种策略:
- 全局传播:在每个stage的最后一个block中执行全局自注意力。由于全局block的数量较少,内存和计算成本是可控的。这个和MViTv2中使用混合窗口注意力方法与FPN连接一样。
- 卷积传播:作为一种替代方案,在每个stage后面额外添加一个卷积block。一个卷积block就是一个残差block,有一个或多个卷积核一个恒等变换组成。这个块中的最后一层初始化为零,这样这个块的初始状态就是恒等的。将一个block初始化为恒等的允许我门将其插入到预训练的骨干网络的任何位置,而不会破坏骨干网络的初始状态。
本文提出的骨干网络适应性方法简单,并且使得检测微调与全局自注意力预训练兼容,没有必要重新设计预训练的架构。
对象检测器包含一些任务无关的组件,如骨干网络,以及一些任务特定的组件,如RoI head。这种模型分解允许任务无关的组件使用非检测数据进行预训练,这可能会带来优势,因为检测训练数据相对稀缺。
因此,追求一个引入较少归纳偏差的骨干网络变得合理,因为骨干网络可以有效地使用大规模数据或自我监督进行训练。相比之下,检测任务特定的组件可用的数据相对较少,可能仍会受益于额外的归纳偏见。虽然寻求具有较少归纳骗的检测头是一个活跃的研究领域,但是像DETR这种方法训练起来具有挑战性。(在设计和训练视觉任务模型时,考虑和管理归纳偏差是非常重要的。骨干网络,由于可以用大规模数据进行训练,可以尽可能减少引入归纳偏差,以提高模型的泛化能力。然后,任务特定的组件,如检测头,由于训练数据较少,可能仍需要一些归纳偏差来引导模型的学习,提高模型的性能。)
为了验证这种方法的可行性,作者选择使用标准的检测组件(如Mask R-CNN及其扩展)来实现他们的方法,即使这些组件可能引入一定的归纳偏见。他们也认识到,进一步减少检测头部的归纳偏见是一个值得探索的未来研究方向,并希望他们的工作可以为这个方向提供一些基础。
实现
使用原始的ViT-B、ViT-L、ViT-H 作为预训练的骨干网络。我们将patch大小设置为16,因此特征图的比例是1/16,即stride=16。检测器头部遵循Mask R-CNN 或Cascade Mask R-CNN ,具体的结构细节在附录中描述。输入图像是1024×1024,在训练过程中进行大规模的jittering。由于这种强烈的正则化,作者在COCO上微调最多100个周期。使用AdamW优化器并使用基线版本来搜索最优的超参数。更多的细节在附录中。
实验结果
与分级骨干网络比较
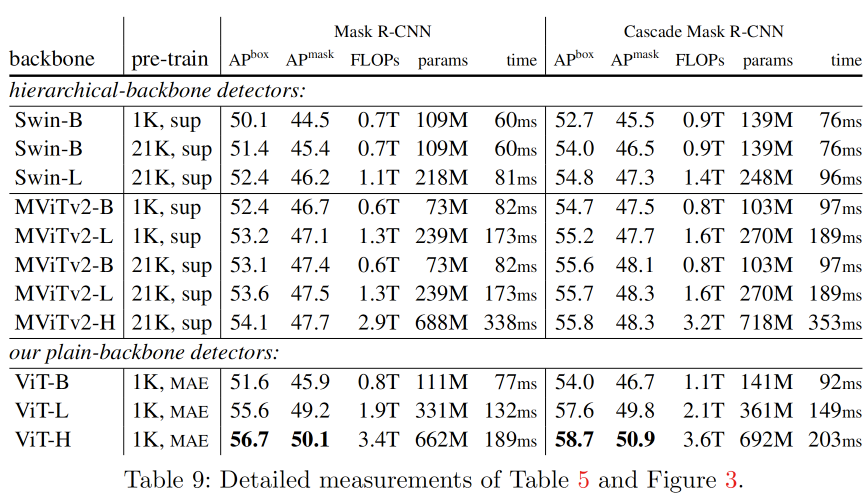
为了尽可能公平地比较骨干网络,将Swin和MViTv2同样作为ViTDet的骨干网络进行比较。对ViT、Swin和MViTv2使用相同的Mask RCNN和Cascade RCNN进行实现。对Swin/MViTv2的分层骨干网络使用FPN。为每个骨干网络单独搜索最优的超参数(见附录)。本文的Swin结果优于原论文中的对应结果;MViTv2结果优于或者与[34]中报告的结果相当。
按照原始论文[42,34],Swin和MViTv2都使用相对位置偏差[46]。为了更公平的比较,作者在这里也按照[34]采用相对位置偏差,但只在微调中使用,不影响预训练。这个添加提高了约1点的AP。注意,在第4.1节中的消融实验是没有相对位置偏差的。
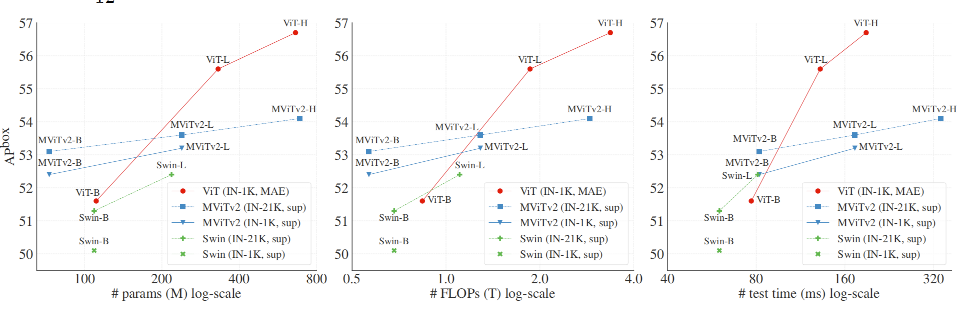
下图中展示了对比结果,涉及到两个因素:骨干网络和预训练策略。ViTDet采用简单骨干网络,结合MAE预训练,具有更好的效果。当模型较大时,本文的方法优于Swin/MViTv2的分层对应模型,包括那些使用IN-21K有监督预训练的模型。使用ViT-H的结果比使用MViTv2-H的结果好2.6个百分点。此外,简单的ViT在实际运行时间性能上更好(图3右侧,参见ViT-H vs. MViTv2-H),因为更简单的块对硬件更友好。
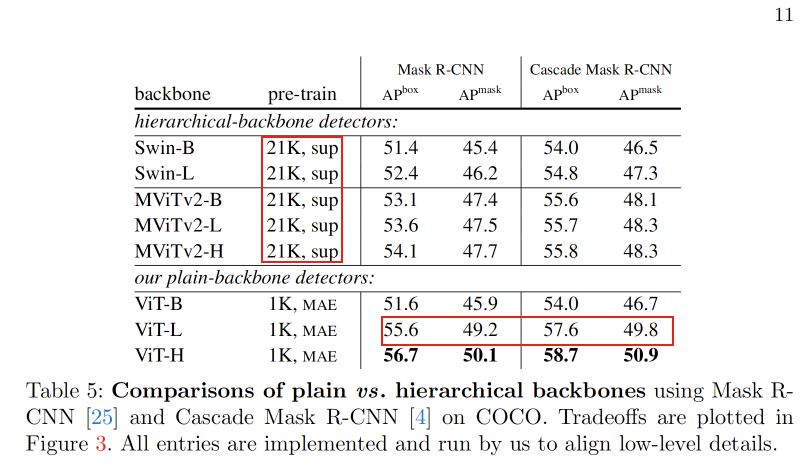
本文对MAE训练方法对分层骨干网络的影响也做了相应的研究,将MAE和MViTv2结合,发现使用使用IN-1K上的MAE预训练的MViTv2-L比使用IN-21K有监督预训练的结果好1.3个百分点(54.9 vs. 53.6 APbox)。而plain骨干网络的这个差距为4% ,这表明plain骨干网络可能会比分级骨干网络更多地从MAE预训练中受益,通过MAE的自监督训练可以弥补关于尺度的归纳偏差。
同样,分级骨干网络中涉及到的增强自注意力模块设计,如Swin中的移动窗口注意力和MViT v1/v2中的池化注意力,如果将这些模块应用到plain骨干网络中,可能会提高准确率和效率。
与之前的检测器比较
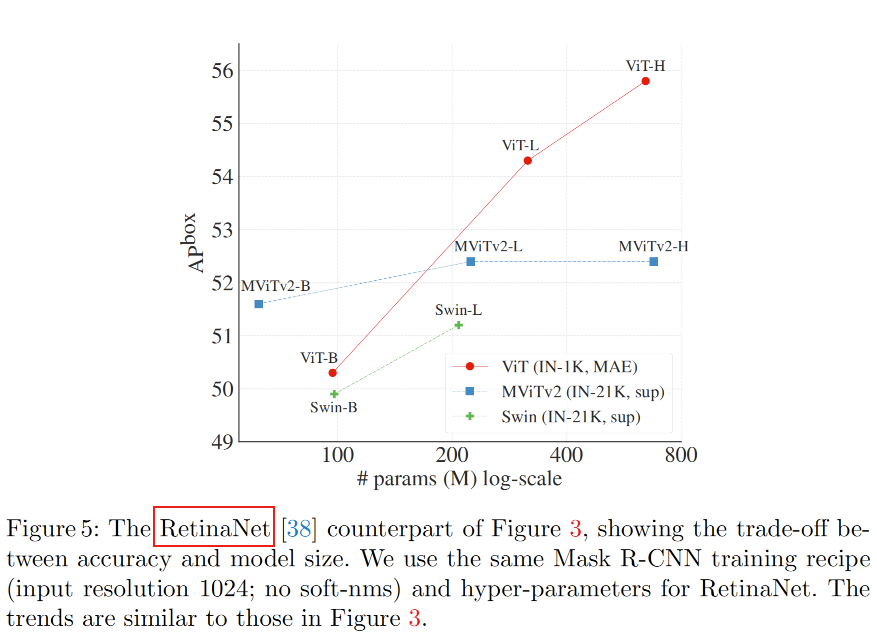
下图比较了不同检测器在COCO数据上的效果。为了更公平的比较,ViTDet和其他检测一样做了两个改变:使用soft-nms和增大输入(从1024到1280)。此外,和上一节一样这里使用相对位置偏差。到目前为止,SOTA检测器都是基于分层骨干网络,在这里首次展示了一个plain骨干网络检测器可以在COCO上获得更好的结果。
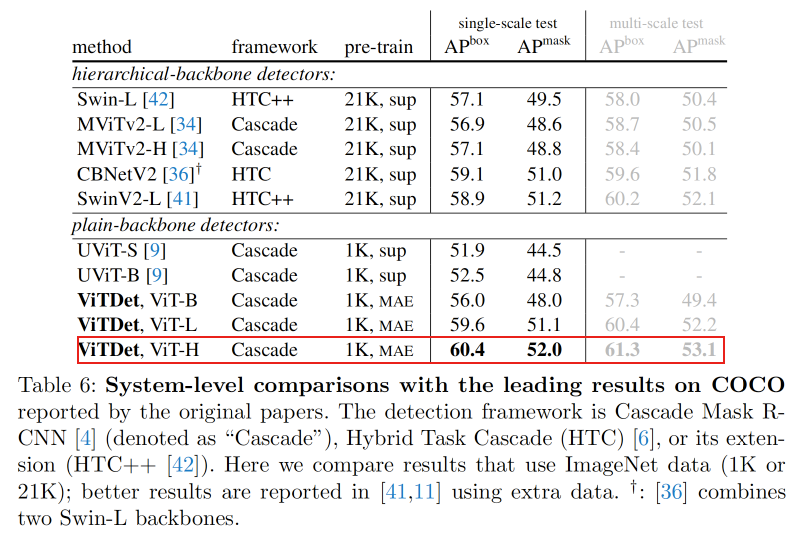
COCO数据集实验细节:
- 输入大小为1024??1024;
- 大尺度jitter,缩放因子范围为[0.1, 2.0]:这个技巧用于增强数据通过在一定范围内缩放图像,可以帮助模型训练对于输入数据的尺度变换更加鲁棒;
- 优化器AdamW, β 1 , β 2 = 0.9 , 0.999 \beta_1, \beta_2=0.9, 0.999 β1?,β2?=0.9,0.999;
- 逐步学习率衰减:在训练过程中逐渐减少学习率,以帮助模型更有效地收敛;
- warmup:在训练的前250次迭代中,学习率逐渐增加;
- 批处理大小为64,分布在64个GPU上,也即每个GPU每次迭代处理1张图像;
针对不同模型大小(B,L,H)和类型(ViT,Swin, MViTv2)的超参数进行调优,具体如下表所示。
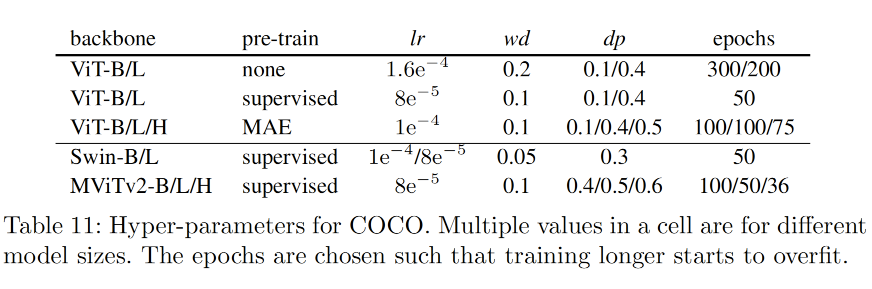
对于MAE预训练的ViT- B/L/H模型,使用0.7/0.8/0.9的逐层学习率衰减,可以获得高达0.3%AP的小幅度增益。
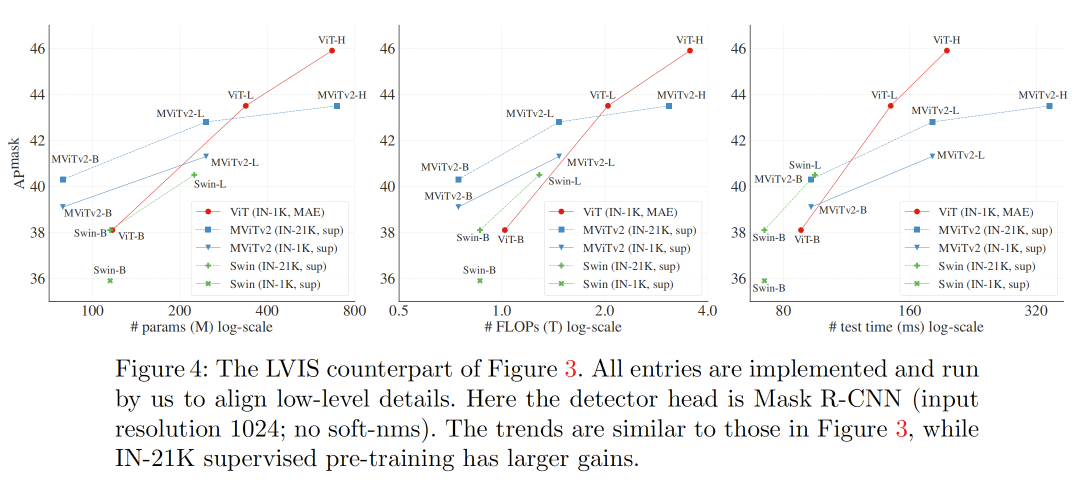
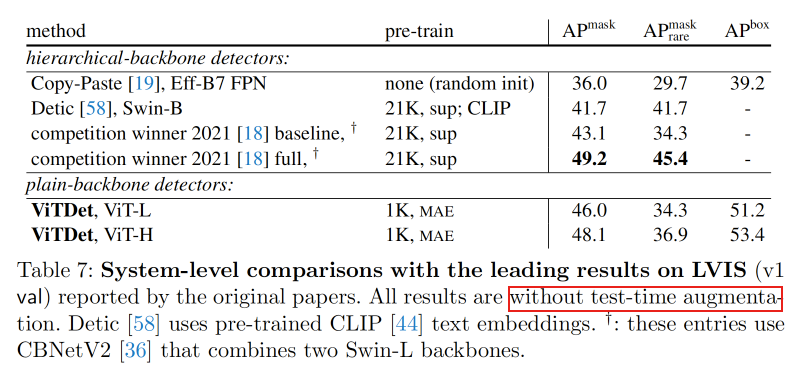
进一步在LVIS数据集[23]上比较结果。VIS包含约200万个高质量的实例分割注释,这些注释涵盖有自然、长尾物体分布的1203个类别。与COCO不同,类别分布严重不平衡,许多类别的训练样本非常少(例如,<10)。
遵循与COCO系统级别比较相同的模型和训练细节,并增加了两种常见的LVIS实践:使用来自[59]的联合损失,并使用重复因子采样[23]来采样图像。我们在v1训练集上进行了100个周期的微调。下图展示了v1 验证集上的结果。本文的检测与所有使用分层骨干网络的SOTA结果相比具有竞争性的性能。
消融实验
本文在COCO数据集上进行消融实验,模型在train2017数据上进行训练,在val2017上进行评估。评价指标分别为 A P b o x AP^{box} APbox和 A P m a s k AP^{mask} APmask。默认使用简单特征金字塔和全局传播,利用没有标签的IN-1K上预训练的MAE来初始化骨干网络。
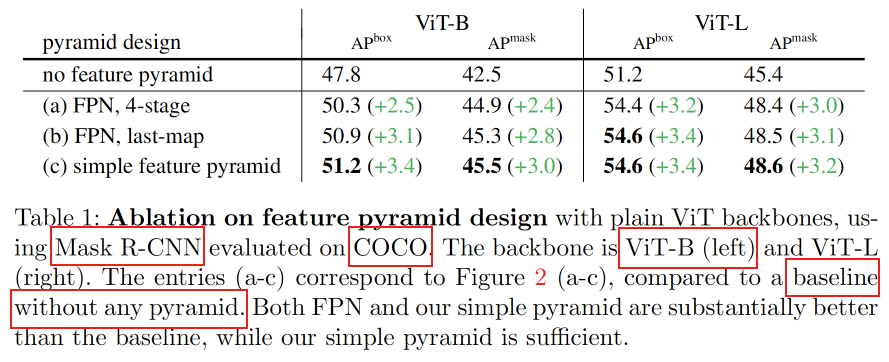
简单特征金字塔的有效性
使用单尺度的特征图后接RPN和RoI head作为baseline,这个和原始的Faster R- CNN类似。后续3种FPN变体效果都好于这个baseline,最高有3.4%的增幅。本文揭示了在进行多尺度检测时,金字塔型特征图的作用比自顶向下/横向连接更为关键。
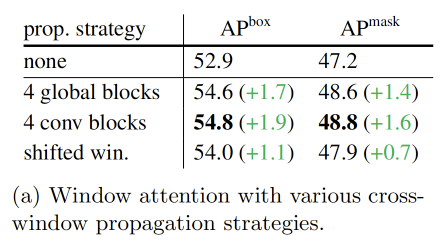
窗口注意力结合少量跨窗口模块有效
下图是对骨干网络的调整进行对比,“none”表示简单实用窗口注意力没有跨窗口传播的blocks作为baseline。后续的各种传播方式都表现出不错的增益。
下表比较了卷积传播中不同类型的残差块。研究了基本(两个3??3卷积),bottleneck(1??1->3x3->1x1),以及一个3??3卷积的初级block。它们都比基线有所提高。
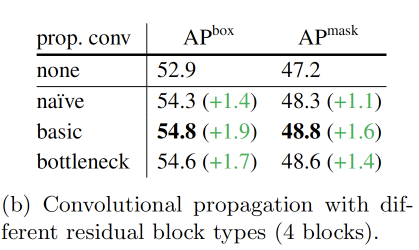
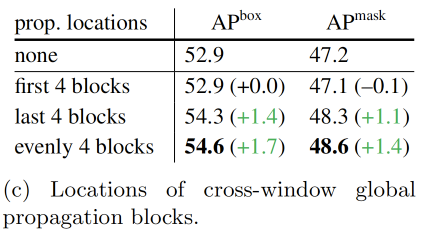
下表中研究了跨窗口传播block应该位于骨干网络的何处。默认情况下,4个全局传播block均匀地放置。此外,比较了将它们放置在前4个或后4个block的情况。可以发现在最后4个block中进行传播几乎与均匀放置一样好,这是因为在后面的block中,ViT的注意力距离更长,而在前面的block中更为局部化。
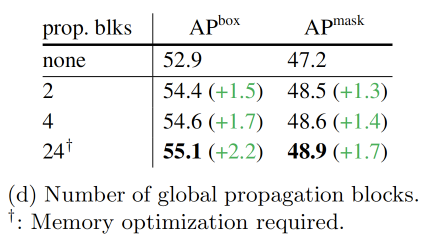
下表中比较了使用全局传播block的数量。即便只使用2个块也可以达到较好的准确度,并明显优于基线。此外,还研究了将ViT- L中所有24个block都是用全局注意力,比默认的4块提高了0.5个百分点。
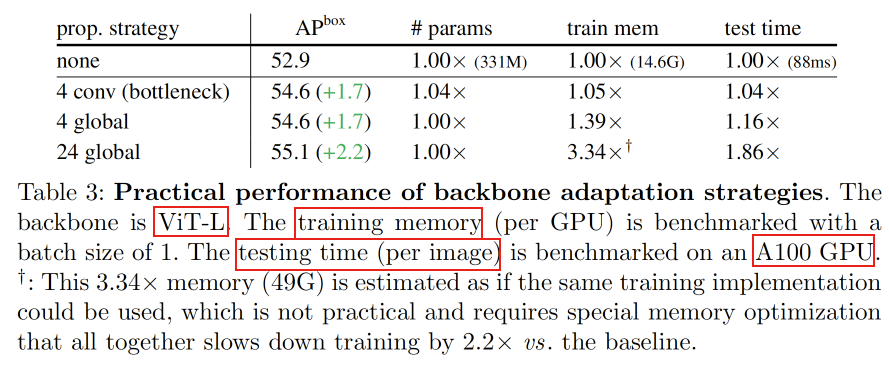
使用4个传播块提供一个良好的折中,卷积传播最为使用,仅增加小于等于5%的内存和时间消耗,以及4%的参数增加作为代价。使用4个块的全局传播也是可行的,不会增加模型大小。
MAE预训练增益
下表比较了骨干网络的预训练策略,在IN-1K和IN-21K上进行监督预训练差于从头开始训练,而采用MAE进行预训练,ViT-B和ViT-L的增幅分别为3.1和4.6.原始的ViT(Visual Transformer),由于归纳偏差较少,可能需要更高的容量来学习平移和尺度等变特征,而高容量模型更容易过拟合。MAE(Masked Autoencoder)预训练可以帮助缓解这个问题。


结论和思考
本文采用plain ViT作为检测器的骨干网络,保持了通用骨干网络和下游任务特定设计的独立性。微调阶段,通过极少的调整,可以将预训练的ViT应用到下游的检测任务中,并取得与分级骨干网络相比具有竞争性的结果。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 关于HTTP请求Header中的referer
- 智慧用电,同为云(TOWE Cloud)平台为机房供配电提供数字化赋能
- TIDB: 元数据查询语句
- 山西电力市场日前价格预测【2024-01-03】
- Live800:倾听和理解客户的声音:改进服务的动力
- 告别 2023,迎接 2024
- WPF 实现Popup不在最上层显示、随窗口移动
- Java王者火柴人
- 回味2023
- STM32入门教程-2023版【3-2】使用库函数点亮GPIO灯