FaceNet: 人脸识别和聚类的统一嵌入
1.FaceNet 的系统
????????FaceNet直接学习从面部图像到紧凑欧几里得空间的映射,其中距离直接对应于面部相似度的度量。一旦生成了这个空间,就可以以 FaceNet 嵌入作为特征向量轻松实现人脸识别、验证和聚类等任务。FaceNet是一个统一的系统,用于人脸验证(这是同一个人)、识别(这个人是谁)和聚类(在这些人脸中找到共同的人)。
????????FaceNet基于使用深度卷积网络学习每个图像的欧几里德嵌入。 人脸验证涉及对两个嵌入之间的距离进行阈值化;识别变成k-NN分类问题;聚类可以使用 k 均值或凝聚聚类。三元组由两个匹配的面部缩略图和一个不匹配的面部缩略图组成,损失旨在通过距离余量将正对与负对分开。

2.模型结构
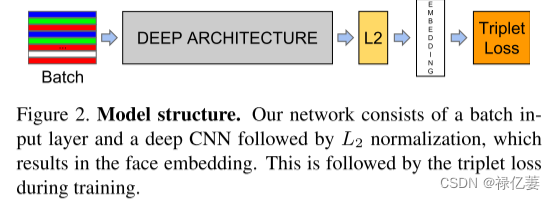
????????网络由批量输入层和深度 CNN 组成,后跟 L2 归一化,从而产生人脸嵌入,然后是训练期间的三元组损失。FaceNet 使用深度卷积网络。讨论了两种不同的核心架构:Zeiler&Fergus型网络和最近的 Inception型网络,整个系统是端到端学习。采用了三元组损失,它直接反映了我们想要在人脸验证、识别和聚类中实现的目标,努力图像 x 嵌入到特征空间 Rd 中,使得所有具有相同身份的人脸之间的平方距离很小。
3.损失函数

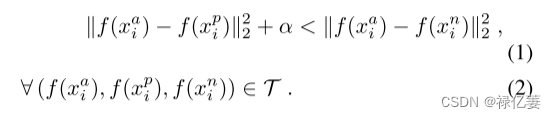

????????同一个人的脸部距离较小,而不同人的脸部距离较大。其中, α 是正负对之间强制执行的边距, T 是训练集中所有可能的三元组的集合,基数为 N。
4.两种架构

????????Zeiler&Fergus架构的标准卷积层之间添加 1×1×d 卷积层,并产生 22 层深的模型。它总共有 1.4 亿个参数,每张图像需要大约 16 亿次 FLOPS。
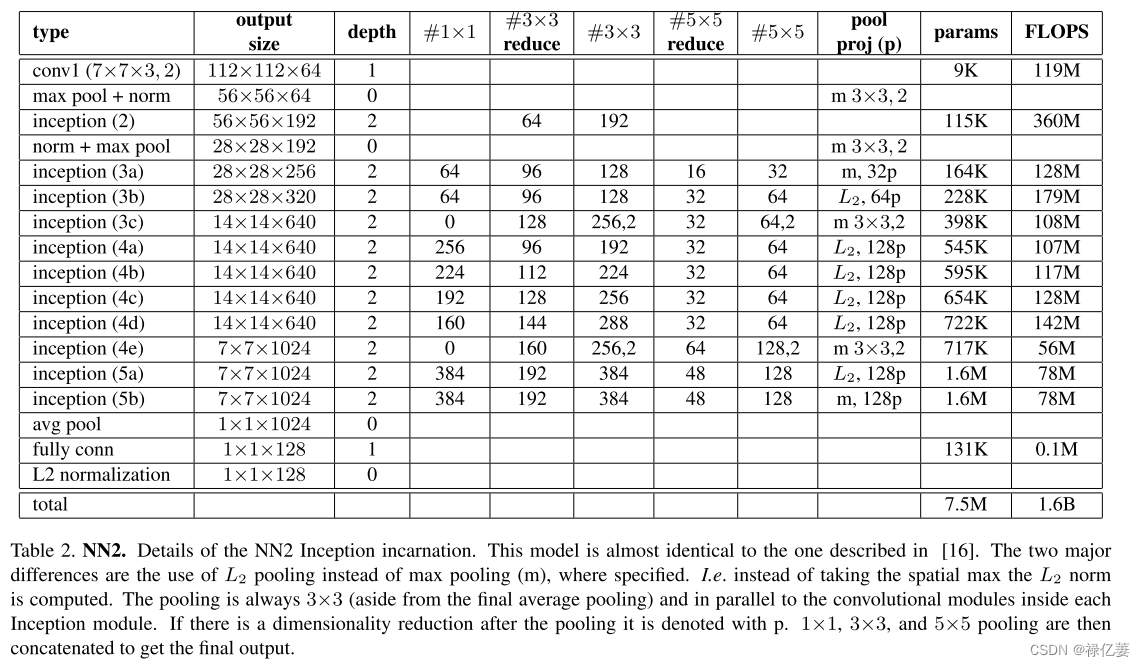
????????基于 GoogLeNet 风格的 Inception 模型,Inception 化身的详细信息。该模型与使用 L2 池化,计算 L2 范数。池化始终为 3×3(除了最终的平均池化),并且与每个 Inception 模块内的卷积模块并行。 p 表示池化后存在降维,然后连接 1×1、3×3 和 5×5 池化以获得最终输出。
5.实验????????????????
LFW数据集:
模型以两种模式进行评估:
? ? ? ? (1)LFW 提供的缩略图的固定中心裁剪。
? ? ? ? (2)专有的人脸检测器在提供的 LFW 缩略图上运行;如果无法对齐脸部(这发生在两个图像上),则使用 LFW 对齐。
????????使用(1)中描述的固定中心裁剪时,实现了 98.87%±0.15 的分类精度,当使用额外的面部对齐(2)时,实现了破纪录的 99.63%±0.09 平均值标准误差。
YouTube Faces DB数据集:
????????使用FaceNet检测器在每个视频中检测到的前一百帧的所有对的平均相似度,这使得分类准确度达到 95.12%±0.39,使用前 1000 帧的结果为 95.18%。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Vue3 多语言
- 光伏、储能一体化监控及运维解决方案——安科瑞 顾烊宇
- 国内CRM系统哪个品牌比较好?
- 【Py/Java/C++三种语言OD2023C卷真题】20天拿下华为OD笔试之【DP】2023C-分月饼【欧弟算法】全网注释最详细分类最全的华为OD真题题解
- Element Plus 的 el-table 组件合并不规律的行
- 免费的ChatGPT分享
- 游泳时用什么耳机听歌好? 口碑最好的游泳耳机分享
- WebStorm不识别‘@‘路径别名解决方法
- Redis集群优化
- windows屏幕录制技巧,必须知道的实用功能