Kafka-消费者-传递保证语义(Delivery guarantee semantic)
Kafka服务端并不会记录消费者的消费位置,而是由消费者自己决定如何保存如何记录其消费的offset。
在Kafka服务端中添加了一个名为“__consumer_offsets”的内部Topic,为了便于描述简称“Offsets Topic”。
Offsets Topic可以用来保存消费者提交的offset,当出现消费者上/下线时会触发Consumer Group进行Rebalance操作,对分区进行重新分配,待Rebalance操作完成后,消费者就可以读取Offsets Topic中记录的offset,并从此offset位置继续消费。
当然,使用Offsets Topic记录消费者的offset只是默认选项,开发人员可以根据业务需求将offset记录在别的存储中。
在消费者消费消息的过程中,提交offset的时机显得非常重要,因为它决定了消费者故障重启后的消费位置。
我们通过将enable.auto.commit选项设置为true可以起到自动提交offset的功能,auto.commit.interval.ms选项则设置了自动提交的时间间隔,这是最简单的提交offset方式。
每次在调用KafkaConsumer.poll方法时都会检测是否需要自动提交,并提交上次poll方法返回的最后一个消息的offset。
为了避免消息丢失,建议poll方法之前要处理完上次poll方法拉取的全部消息。
KafkaConsumer中还提供了两个手动提交offset的方法,分别是commitSync()方法和commitAsync()方法,它们都可以指定提交的offset值,区别在于前者是同步提交,后者是异步提交。提交offset的具体原理和实现稍后分析。
下面来介绍消息的传递保证(Delivery guarantee semantic)的相关内容,传递保证语义有以下三个级别。
- At most once:消息可能会丢,但绝不会重复传递。
- At least once:消息绝不会丢,但可能会重复传递。
- Exactly once:每条消息只会被传递一次。
在实践中很少出现对“At most once”的需求,而在很多场景中,“Exactly once”语义才是我们需要的,所以我们详述这种语义。
当然,如果通过Kafka传递的消息是幂等性的(即一条消息被反复消费多次并不会对计算结果产生影响),使用“At least once”语义也是没有问题的。
“Exactly once”语义由生产者和消费者两部分共同决定:首先,生产者要保证不会产生重复的消息;其次,消费者不能重复拉取相同的消息。
先来讨论生产者部分,当生产者向Kafka发送消息,且正常得到响应的时候,可以确保生产者不会产生重复的消息。
但是,如果生产者发送消息后,遇到网络问题,无法获取响应,生产者就无法判断该消息是否成功提交给了Kafka。
我们知道,当出现异常时,会进行消息重传,这就可能出现“At least one”语义。
为了实现“Exactly once”语义,这里提供两个可选方案:
- 每个分区只有一个生产者写入消息,当出现异常或超时的情况时,生产者就要查询此分区的最后一个消息,用来决定后续操作是消息重传还是继续发送。
- 为每个消息添加一个全局唯一主键,生产者不做其他特殊处理,按照之前分析方式进行重传,由消费者对消息进行去重,实现“Exactly once”语义。
如果业务数据产生消息可以找到合适的字段作为主键,或是有一个全局ID生成器,可以优先考虑选用第二种方案。
接下来讨论消费者部分。消费者处理消息与提交offset的顺序,在很大程度上决定了消息者是哪个语义。
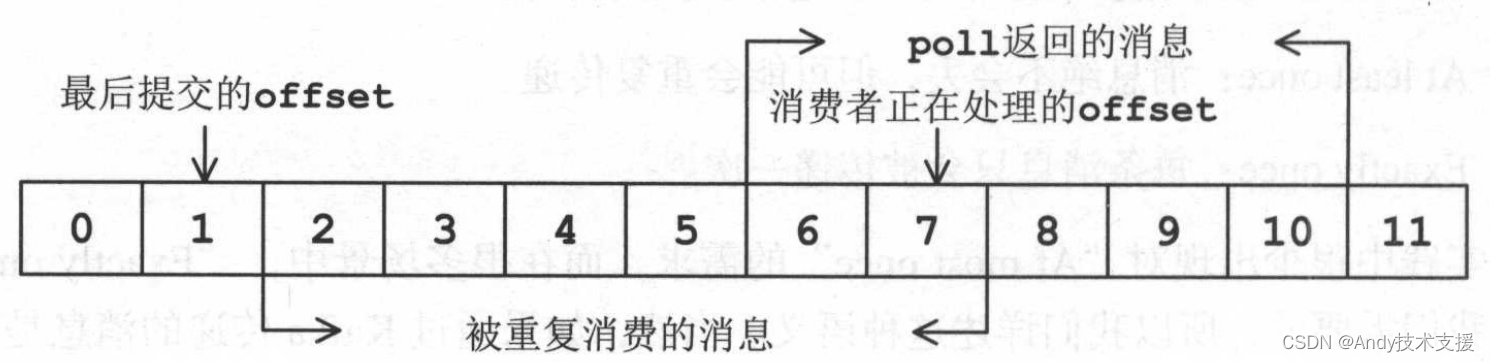

在图中展示了两种提交offset不当导致的消息被重复消费(“At least once”语义)以及丢失消息(“At most once”语义)的情况。
在图1的场景中,消费者拉取完消息后,业务逻辑先对消息进行处理,再提交offset。
这种模式下,如果消费者在处理完了消息之后,提交offset之前出现宕机,待消费者重新上线时,还会处理刚刚未提交的那部分消息(即2~7这部分消息),但这些消息已经被处理过了,这就对应于“At least once”语义。
在图2的场景中,消费者拉取消息后,先提交offset后再处理消息。
在提交offset之后,业务逻辑处理消息之前出现宕机,待消费者重新上线时,就无法读到刚刚已提交而未处理的这部分消息(即5~8这部分消息),这就对应于“At most once”语义。
这里仅仅是一个示例,还有很多原因会导致类似的结果,例如Consumer Group Rebalance等。
为了实现消费者的“Exactly once”语义,在这里提供一种方案,供读者参考:
消费者将关闭自动提交offset的功能且不再手动提交offset,这样就不使用Offsets Topic这个内部Topic记录其offset,而是由消费者自己保存offset。
这里利用事务的原子性来实现“Exactlyonce”语义,我们将offset和消息处理结果放在一个事务中,事务执行成功则认为此消息被消费,否则事务回滚需要重新消费。
当出现消费者宕机重启或Rebalance操作时,消费者可以从关系型数据库中找到对应的offset,然后调用KafkaConsumer.seek()方法手动设置消费位置,从此offset处开始继续消费。
到目前为止,消费者并不知道Consumer Group什么时候会发生Rebalance操作,哪个分区分配给了哪个消费者消费。我们可以通过向KafkaConsumer添加ConsumerRebalanceListener接口来解决这个问题。
ConsumerRebalanceListener有两个回调方法。
- onPartitionsRevoked方法:调用时机是Consumer停止拉取数据之后、Rebalance开始之前,我们可以在此方法中实现手动提交offset,这就避免了Rebalance导致的重复消费的情况。
- onPartitionsAssigned方法:调用时机是Rebalance完成之后、Consumer开始拉取数据之前,我们可以在此方法中调整或自定义offset的值。
通过ConsumerRebalanceListener接口和seek方法,我们就可以实现从关系型数据库获取offset并手动设置的功能了。
这个方案还有其他的变体,例如,使用assign方法为消费者手动分配TopicPartition,将提供事务保证的存储换成HDFS或其他No-SQL数据库,但是基本原理还是不变的。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 如何测试和挑选 2024 年最佳 Mac 数据恢复软件
- RTDETR 引入 超越自注意力:面向医学图像分割的可变形大卷积核注意力
- 外卖订餐系统(JSP+java+springmvc+mysql+MyBatis)
- Linux 软件安装方式汇总与详解
- yo!这里是Linux信号相关介绍
- uniapp中uview组件库的Search 搜索 的用法
- Pandas.DataFrame.select_dtypes() 根据数据类型筛选列 详解 含代码 含测试数据集 随Pandas版本持续更新
- Retrofit2 + Hilt + MVVM + 协程 + Paging3 + SmartRefreshLayout 整合 使用
- nginx+rsyslog+kafka+clickhouse+grafana 实现nginx 网关监控
- 策略模式+责任链模式配合Nacos实现参数校验链