【机器学习】Sklearn初步学习
发布时间:2024年01月19日
简介
更适合于完成传统的机器学习算法(除了深度学习之外的算法),不光在模型使用,所有预处理的操作也包含在其中。 对于API部分有相关文档当不确定相关模型需要的参数等时可以查看API文档;对于Examples部分,不仅可以学习相关代码还可以着重学习数据的可视化
Sklearn官网地址:
scikit-learn: machine learning in Python — scikit-learn 1.3.2 documentation
数据准备
import numpy as np
import os
# % matplotlib inline
import matplotlib
import matplotlib.pyplot as plt
plt.rcParams['axes.labelsize']=14
plt.rcParams['xtick.labelsize']=12
plt.rcParams['ytick.labelsize']=12
import warnings
warnings.filterwarnings('ignore')
np.random.seed(42)
from sklearn.datasets import fetch_openml
'''Mnist数据是图像数据 (28,28,1)的灰度图'''
mnist = fetch_openml("mnist_784", version=1)
# mnist
X,y=mnist["data"],mnist["target"]
print(X.shape)
###分割测试集与训练集
X_train,X_test,y_train,y_test=X[:60000],X[60000:],y[:60000],y[60000:]
##洗牌操作 不希望数据学到由于排序而获得的规律
import numpy as np
shuffle_index=np.random.permutation(60000)
X_train,y_train=X_train.to_numpy()[shuffle_index],y_train.to_numpy()[shuffle_index]
##将十分类问题转为简单的二分类问题
y_train_5=(y_train=="5")
y_test_5=(y_test=="5")
print(y_train_5[:20])
'''训练得到最基本的分类器'''
from sklearn.linear_model import SGDClassifier
sgd_clf=SGDClassifier(max_iter=5,random_state=42)
###代码运行时其中会设计一些随机的策略 每次随机的时候都是一致的
sgd_clf.fit(X_train,y_train_5)##输入训练数据的XY交叉验证
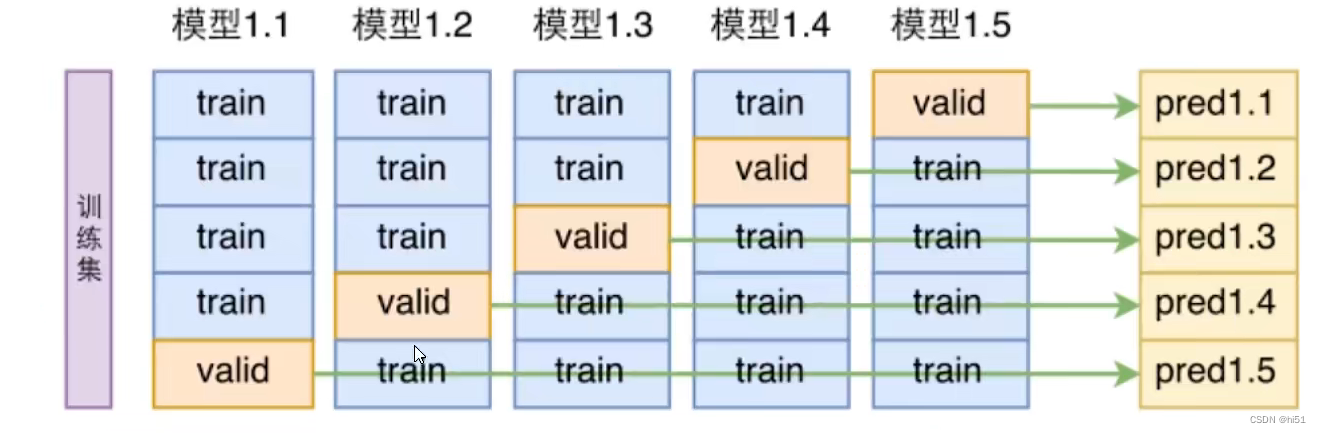
使用sklearn实现数据的交叉验证示例:
方式一:
from sklearn.model_selection import cross_val_score
score1=cross_val_score(sgd_clf,X_train,y_train_5,cv=3,scoring='accuracy')
'''cv=3 将数据平均分的份数
,scoring='accuracy' 进行评估使用的方法'''
print(score1)方式二:
'''使用克隆来对参数进行操作 使之参数一致'''
from sklearn.model_selection import StratifiedKFold
from sklearn.base import clone
skflods=StratifiedKFold(n_splits=3,random_state=42,shuffle=True)##将当前数据集分割为多少份
###所得到的每一份的训练集和验证集是不一样的 因而需要遍历每个进行训练
for train_index,test_index in skflods.split(X_train,y_train_5):
clone_clf=clone(sgd_clf)##克隆分类器的参数值
##设定当前一折的XY训练集与测试集 需要注意 全部都是在训练集上进行操作
X_train_folds=X_train[train_index]
y_train_folds=y_train_5[train_index]
X_test_folds=X_train[test_index]
y_test_folds=y_train_5[test_index]
clone_clf.fit(X_train_folds,y_train_folds)##训练当前这一折的模型
y_pred=clone_clf.predict(X_test_folds)##预测数据
n_correct=sum(y_pred==y_test_folds)##获得预测正确的数量
print(n_correct/len(y_pred))##准确率混淆矩阵
构建混淆矩阵是在得到预测值之后进行分析的 得到的将是2×2的矩阵
得到混淆矩阵示例:
from sklearn.model_selection import cross_val_predict
y_train_pred=cross_val_predict(sgd_clf,X_train,y_train_5,cv=3)##获得预测值
from sklearn.metrics import confusion_matrix
confusion_matrix1=confusion_matrix(y_train_5,y_train_pred)##传入y的正确值与预测值
print(confusion_matrix1)| 预测错误值 | 预测正确值 | |
| 实际错误值 | true negatives(TN) | false?positives(FP) |
| 实际正确值 | false negatives(FN) | true positives(TP) |
一个完美的分类器应该只要true positives和true negatives,即主对角线元素不为0,其余元素为0
精度:precision=TP/(TP+FP)
召回率:recall=TP/(TP+FN)
阈值越低recall值越高,但是精度会较低;随着阈值增大,recall值减少,精度逐渐增大
在sklearn的metrics中都有计算该指标的方法,示例如下:
###计算精度与召回率 调和平均数
from sklearn.metrics import precision_score,recall_score,f1_score
precision_score1=precision_score(y_train_5,y_train_pred)
recall_score1=recall_score(y_train_5,y_train_pred)
f1_score1=f1_score(y_train_5,y_train_pred)
print(precision_score1,recall_score1,f1_score1)一般机器学习使用调和平均值F1进行综合评分
ROC曲线
一般运用与分类问题
对于ROC曲线,虚线表示纯随机分类器的ROC曲线;一个好的分类器尽可能远离该线,越朝左上角越好。比较分类器的一种方法是测量曲线下面积(AUC)。完美分类器的ROC AUC等于1,而纯随机分类器的ROC AUC等于0.5。 通过ROC曲线可以较为综合的评估所建立模型的效果如何。
利用sklearn展示ROC曲线示例:
'''分类问题使用ROC曲线'''
from sklearn.metrics import roc_curve
fpr,tpr,thresholds=roc_curve(y_train_5,y_scores)
def plot_roc_curve(fpr,tpr,label=None):
plt.plot(fpr,tpr,linewidth=2,label=label)
plt.plot([0,1],[0,1],'k-')
plt.axis([0,1,0,1])
plt.xlabel('False Positive Rate',fontsize=16)
plt.ylabel('True Positive Rate',fontsize=16)
'''绘制ROC曲线'''
plt.figure(figsize=(8,6))
plot_roc_curve(fpr,tpr)
plt.show()
'''进行最终模型的评估'''
from sklearn.metrics import roc_auc_score
roc_auc_score1=roc_auc_score(y_train_5,y_scores)
print(roc_auc_score1)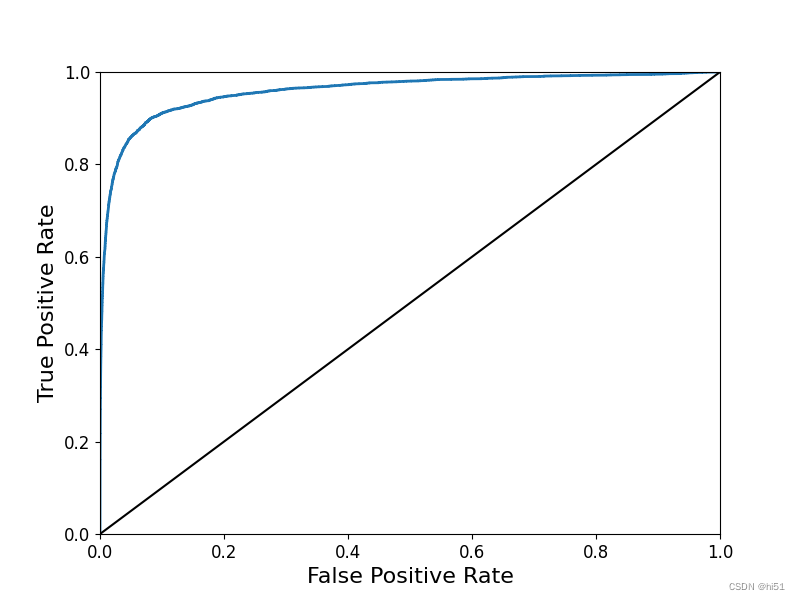
文章来源:https://blog.csdn.net/weixin_62100318/article/details/135629684
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- C++ 指向类的指针
- 7天玩转 Golang 标准库之 http/net
- 价差为0甚至有时可能会是负的,但Anzo Capital还有一点提醒
- Redis 常用的数据类型及用法
- 微信小程序中textarea表单组件字数实时更新方法
- 集成腾讯Bugly使用步骤以及字符串的上传(IOS手把手)
- 【数据库设计和SQL基础语法】--安全性和备份--数据库安全性的重要性
- 大端和小端传输字节序
- 基于小波变换DWT肌电信号去噪频域时域分析附Matlab代码
- Jmeter脚本录制:抓取IOS手机请求包