YOLOv5:将模型预测结果保存为Labelme格式的Json文件
发布时间:2023年12月21日

前言
- 由于本人水平有限,难免出现错漏,敬请批评改正。
- 更多精彩内容,可点击进入Python日常小操作专栏、OpenCV-Python小应用专栏、YOLO系列专栏、自然语言处理专栏或我的个人主页查看
- 基于DETR的人脸伪装检测
- YOLOv7训练自己的数据集(口罩检测)
- YOLOv8训练自己的数据集(足球检测)
- YOLOv5:TensorRT加速YOLOv5模型推理
- YOLOv5:IoU、GIoU、DIoU、CIoU、EIoU
- 玩转Jetson Nano(五):TensorRT加速YOLOv5目标检测
- YOLOv5:添加SE、CBAM、CoordAtt、ECA注意力机制
- YOLOv5:yolov5s.yaml配置文件解读、增加小目标检测层
- Python将COCO格式实例分割数据集转换为YOLO格式实例分割数据集
- YOLOv5:使用7.0版本训练自己的实例分割模型(车辆、行人、路标、车道线等实例分割)
- 使用Kaggle GPU资源免费体验Stable Diffusion开源项目
前提条件
- 熟悉Python
相关介绍
- Python是一种跨平台的计算机程序设计语言。是一个高层次的结合了解释性、编译性、互动性和面向对象的脚本语言。最初被设计用于编写自动化脚本(shell),随着版本的不断更新和语言新功能的添加,越多被用于独立的、大型项目的开发。
- PyTorch 是一个深度学习框架,封装好了很多网络和深度学习相关的工具方便我们调用,而不用我们一个个去单独写了。它分为 CPU 和 GPU 版本,其他框架还有 TensorFlow、Caffe 等。PyTorch 是由 Facebook 人工智能研究院(FAIR)基于 Torch 推出的,它是一个基于 Python 的可续计算包,提供两个高级功能:1、具有强大的 GPU 加速的张量计算(如 NumPy);2、构建深度神经网络时的自动微分机制。
- YOLOv5是一种单阶段目标检测算法,该算法在YOLOv4的基础上添加了一些新的改进思路,使其速度与精度都得到了极大的性能提升。它是一个在COCO数据集上预训练的物体检测架构和模型系列,代表了Ultralytics对未来视觉AI方法的开源研究,其中包含了经过数千小时的研究和开发而形成的经验教训和最佳实践。
- Labelme是一款图像标注工具,由麻省理工(MIT)的计算机科学和人工智能实验室(CSAIL)研发。它是用Python和PyQT编写的,开源且免费。Labelme支持Windows、Linux和Mac等操作系统。
- 这款工具提供了直观的图形界面,允许用户在图像上标注多种类型的目标,例如矩形框、多边形、线条等,甚至包括更复杂的形状。标注结果以JSON格式保存,便于后续处理和分析。这些标注信息可以用于目标检测、图像分割、图像分类等任务。
- 总的来说,Labelme是一款强大且易用的图像标注工具,可以满足不同的图像处理需求。
- Labelme标注json文件是一种用于存储标注信息的文件格式,它包含了以下几个主要的字段:
version: Labelme的版本号,例如"4.5.6"。flags: 一些全局的标志,例如是否是分割任务,是否有多边形,等等。shapes: 一个列表,每个元素是一个字典,表示一个标注对象。每个字典包含了以下几个字段:
label: 标注对象的类别名称,例如"dog"。points: 一个列表,每个元素是一个坐标对,表示标注对象的边界点,例如[[10, 20], [30, 40]]。group_id: 标注对象的分组编号,用于表示属于同一组的对象,例如1。shape_type: 标注对象的形状类型,例如"polygon",“rectangle”,“circle”,等等。flags: 一些针对该标注对象的标志,例如是否是难例,是否被遮挡,等等。lineColor: 标注对象的边界线颜色,例如[0, 255, 0, 128]。fillColor: 标注对象的填充颜色,例如[255, 0, 0, 128]。imagePath: 图像文件的相对路径,例如"img_001.jpg"。imageData: 图像文件的二进制数据,经过base64编码后的字符串,例如"iVBORw0KGgoAAAANSUhEUgAA…"。imageHeight: 图像的高度,例如600。imageWidth: 图像的宽度,例如800。
以下是一个Labelme标注json文件的示例:
{
"version": "4.5.6",
"flags": {},
"shapes": [
{
"label": "dog",
"points": [
[
121.0,
233.0
],
[
223.0,
232.0
],
[
246.0,
334.0
],
[
121.0,
337.0
]
],
"group_id": null,
"shape_type": "polygon",
"flags": {}
}
],
"lineColor": [
0,
255,
0,
128
],
"fillColor": [
255,
0,
0,
128
],
"imagePath": "img_001.jpg",
"imageData": "iVBORw0KGgoAAAANSUhEUgAA...",
"imageHeight": 600,
"imageWidth": 800
}
实验环境
- Python 3.x (面向对象的高级语言)
YOLOv5:将模型预测结果保存为Labelme格式的Json文件
- 背景:YOLOv5官方可以将预测结果保存为YOLO格式的txt文件,没有Labelme格式的Json文件,本文修改官方代码,“将模型预测结果保存为Labelme格式的Json文件”的功能添加进去。
- 目录结构示例
代码实现
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
"""
Run inference on images, videos, directories, streams, etc.
Usage - sources:
$ python path/to/detect.py --weights yolov5s.pt --source 0 # webcam
img.jpg # image
vid.mp4 # video
path/ # directory
path/*.jpg # glob
'https://youtu.be/Zgi9g1ksQHc' # YouTube
'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP stream
Usage - formats:
$ python path/to/detect.py --weights yolov5s.pt # PyTorch
yolov5s.torchscript # TorchScript
yolov5s.onnx # ONNX Runtime or OpenCV DNN with --dnn
yolov5s.xml # OpenVINO
yolov5s.engine # TensorRT
yolov5s.mlmodel # CoreML (MacOS-only)
yolov5s_saved_model # TensorFlow SavedModel
yolov5s.pb # TensorFlow GraphDef
yolov5s.tflite # TensorFlow Lite
yolov5s_edgetpu.tflite # TensorFlow Edge TPU
"""
import json
import argparse
import os
import sys
from pathlib import Path
import cv2
import torch
import torch.backends.cudnn as cudnn
FILE = Path(__file__).resolve()
ROOT = FILE.parents[0] # YOLOv5 root directory
if str(ROOT) not in sys.path:
sys.path.append(str(ROOT)) # add ROOT to PATH
ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative
from models.common import DetectMultiBackend
from utils.datasets import IMG_FORMATS, VID_FORMATS, LoadImages, LoadStreams
from utils.general import (LOGGER, check_file, check_img_size, check_imshow, check_requirements, colorstr,
increment_path, non_max_suppression, print_args, scale_coords, strip_optimizer, xyxy2xywh)
from utils.plots import Annotator, colors, save_one_box
from utils.torch_utils import select_device, time_sync
@torch.no_grad()
def run(weights=ROOT / 'yolov5s.pt', # model.pt path(s)
source=ROOT / 'data/images', # file/dir/URL/glob, 0 for webcam
data=ROOT / 'data/coco128.yaml', # dataset.yaml path
imgsz=(640, 640), # inference size (height, width)
conf_thres=0.25, # confidence threshold
iou_thres=0.45, # NMS IOU threshold
max_det=1000, # maximum detections per image
device='', # cuda device, i.e. 0 or 0,1,2,3 or cpu
view_img=False, # show results
save_txt=False, # save results to *.txt
save_conf=False, # save confidences in --save-txt labels
save_crop=False, # save cropped prediction boxes
nosave=False, # do not save images/videos
classes=None, # filter by class: --class 0, or --class 0 2 3
agnostic_nms=False, # class-agnostic NMS
augment=False, # augmented inference
visualize=False, # visualize features
update=False, # update all models
project=ROOT / 'runs/detect', # save results to project/name
name='exp', # save results to project/name
exist_ok=False, # existing project/name ok, do not increment
line_thickness=3, # bounding box thickness (pixels)
hide_labels=False, # hide labels
hide_conf=False, # hide confidences
half=False, # use FP16 half-precision inference
dnn=False, # use OpenCV DNN for ONNX inference
):
source = str(source)
save_img = not nosave and not source.endswith('.txt') # save inference images
is_file = Path(source).suffix[1:] in (IMG_FORMATS + VID_FORMATS)
is_url = source.lower().startswith(('rtsp://', 'rtmp://', 'http://', 'https://'))
webcam = source.isnumeric() or source.endswith('.txt') or (is_url and not is_file)
if is_url and is_file:
source = check_file(source) # download
# Directories
save_dir = increment_path(Path(project) / name, exist_ok=exist_ok) # increment run
# (save_dir / 'labels' if save_txt else save_dir).mkdir(parents=True, exist_ok=True) # make dir
# Load model
device = select_device(device)
model = DetectMultiBackend(weights, device=device, dnn=dnn, data=data)
stride, names, pt, jit, onnx, engine = model.stride, model.names, model.pt, model.jit, model.onnx, model.engine
imgsz = check_img_size(imgsz, s=stride) # check image size
# Half
half &= (pt or jit or onnx or engine) and device.type != 'cpu' # FP16 supported on limited backends with CUDA
if pt or jit:
model.model.half() if half else model.model.float()
# Dataloader
if webcam:
view_img = check_imshow()
cudnn.benchmark = True # set True to speed up constant image size inference
dataset = LoadStreams(source, img_size=imgsz, stride=stride, auto=pt)
bs = len(dataset) # batch_size
else:
dataset = LoadImages(source, img_size=imgsz, stride=stride, auto=pt)
bs = 1 # batch_size
vid_path, vid_writer = [None] * bs, [None] * bs
# Run inference
model.warmup(imgsz=(1 if pt else bs, 3, *imgsz), half=half) # warmup
dt, seen = [0.0, 0.0, 0.0], 0
for path, im, im0s, vid_cap, s in dataset:
t1 = time_sync()
im = torch.from_numpy(im).to(device)
im = im.half() if half else im.float() # uint8 to fp16/32
im /= 255 # 0 - 255 to 0.0 - 1.0
if len(im.shape) == 3:
im = im[None] # expand for batch dim
t2 = time_sync()
dt[0] += t2 - t1
# Inference
visualize = increment_path(save_dir / Path(path).stem, mkdir=True) if visualize else False
pred = model(im, augment=augment, visualize=visualize)
t3 = time_sync()
dt[1] += t3 - t2
# NMS
pred = non_max_suppression(pred, conf_thres, iou_thres, classes, agnostic_nms, max_det=max_det)
dt[2] += time_sync() - t3
# Second-stage classifier (optional)
# pred = utils.general.apply_classifier(pred, classifier_model, im, im0s)
# Process predictions
for i, det in enumerate(pred): # per image
seen += 1
if webcam: # batch_size >= 1
p, im0, frame = path[i], im0s[i].copy(), dataset.count
s += f'{i}: '
else:
p, im0, frame = path, im0s.copy(), getattr(dataset, 'frame', 0)
p = Path(p) # to Path
save_path = str(save_dir / p.name) # im.jpg
txt_path = str(save_dir / 'labels' / p.stem) + ('' if dataset.mode == 'image' else f'_{frame}') # im.txt
s += '%gx%g ' % im.shape[2:] # print string
gn = torch.tensor(im0.shape)[[1, 0, 1, 0]] # normalization gain whwh
imc = im0.copy() if save_crop else im0 # for save_crop
annotator = Annotator(im0, line_width=line_thickness, example=str(names))
if len(det):
# Rescale boxes from img_size to im0 size
det[:, :4] = scale_coords(im.shape[2:], det[:, :4], im0.shape).round()
# Print results
for c in det[:, -1].unique():
n = (det[:, -1] == c).sum() # detections per class
s += f"{n} {names[int(c)]}{'s' * (n > 1)}, " # add to string
################################### detect_to_labelme_json ######################
out_json_path = str(p)[:-4] + '.json'
image_name = os.path.split(p)[1]
print('out_json_path,image_name:',out_json_path,image_name)
labelme_json = {
'version': '4.5.7',
'flags': {},
'shapes': [],
'imagePath': image_name,
'imageData': None,
'imageHeight': im0s.shape[0],
'imageWidth': im0s.shape[1],
}
# Write results
for *xyxy, conf, cls in reversed(det):
# print("xyxy, conf, cls:",xyxy, conf, cls)
x1 = xyxy[0]
y1 = xyxy[1]
x2 = xyxy[2]
y2 = xyxy[3]
score = float(conf)
c = int(cls) # integer class
# label = None if hide_labels else (names[c] if hide_conf else f'{names[c]} {conf:.2f}')
# annotator.box_label(xyxy, label, color=colors(c, True))
shape = {
'label': str(names[c]),
'group_id': None,
'shape_type': 'rectangle',
'flags': {},
'score': score,
'points': [
[float(x1), float(y1)],
[float(x2), float(y2)]
]
}
labelme_json['shapes'].append(shape)
with open(out_json_path, 'w') as f:
json.dump(labelme_json, f)
##############################################################################
# Write results
for *xyxy, conf, cls in reversed(det):
if save_txt: # Write to file
xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # normalized xywh
line = (cls, *xywh, conf) if save_conf else (cls, *xywh) # label format
with open(txt_path + '.txt', 'a') as f:
f.write(('%g ' * len(line)).rstrip() % line + '\n')
if save_img or save_crop or view_img: # Add bbox to image
c = int(cls) # integer class
label = None if hide_labels else (names[c] if hide_conf else f'{names[c]} {conf:.2f}')
annotator.box_label(xyxy, label, color=colors(c, True))
if save_crop:
save_one_box(xyxy, imc, file=save_dir / 'crops' / names[c] / f'{p.stem}.jpg', BGR=True)
# Stream results
im0 = annotator.result()
if view_img:
cv2.imshow(str(p), im0)
cv2.waitKey(1) # 1 millisecond
# Save results (image with detections)
if save_img:
if dataset.mode == 'image':
cv2.imwrite(save_path, im0)
else: # 'video' or 'stream'
if vid_path[i] != save_path: # new video
vid_path[i] = save_path
if isinstance(vid_writer[i], cv2.VideoWriter):
vid_writer[i].release() # release previous video writer
if vid_cap: # video
fps = vid_cap.get(cv2.CAP_PROP_FPS)
w = int(vid_cap.get(cv2.CAP_PROP_FRAME_WIDTH))
h = int(vid_cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
else: # stream
fps, w, h = 30, im0.shape[1], im0.shape[0]
save_path = str(Path(save_path).with_suffix('.mp4')) # force *.mp4 suffix on results videos
vid_writer[i] = cv2.VideoWriter(save_path, cv2.VideoWriter_fourcc(*'mp4v'), fps, (w, h))
vid_writer[i].write(im0)
# Print time (inference-only)
LOGGER.info(f'{s}Done. ({t3 - t2:.3f}s)')
# Print results
t = tuple(x / seen * 1E3 for x in dt) # speeds per image
LOGGER.info(f'Speed: %.1fms pre-process, %.1fms inference, %.1fms NMS per image at shape {(1, 3, *imgsz)}' % t)
if save_txt or save_img:
s = f"\n{len(list(save_dir.glob('labels/*.txt')))} labels saved to {save_dir / 'labels'}" if save_txt else ''
LOGGER.info(f"Results saved to {colorstr('bold', save_dir)}{s}")
if update:
strip_optimizer(weights) # update model (to fix SourceChangeWarning)
def parse_opt():
parser = argparse.ArgumentParser()
parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'yolov5s.pt', help='model path(s)')
parser.add_argument('--source', type=str, default=ROOT / 'data/images', help='file/dir/URL/glob, 0 for webcam')
parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='(optional) dataset.yaml path')
parser.add_argument('--imgsz', '--img', '--img-size', nargs='+', type=int, default=[640], help='inference size h,w')
parser.add_argument('--conf-thres', type=float, default=0.25, help='confidence threshold')
parser.add_argument('--iou-thres', type=float, default=0.45, help='NMS IoU threshold')
parser.add_argument('--max-det', type=int, default=1000, help='maximum detections per image')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--view-img', action='store_true', help='show results')
parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')
parser.add_argument('--save-crop', action='store_true', help='save cropped prediction boxes')
parser.add_argument('--nosave', action='store_true', help='do not save images/videos')
parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --classes 0, or --classes 0 2 3')
parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')
parser.add_argument('--augment', action='store_true', help='augmented inference')
parser.add_argument('--visualize', action='store_true', help='visualize features')
parser.add_argument('--update', action='store_true', help='update all models')
parser.add_argument('--project', default=ROOT / 'runs/detect', help='save results to project/name')
parser.add_argument('--name', default='exp', help='save results to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--line-thickness', default=3, type=int, help='bounding box thickness (pixels)')
parser.add_argument('--hide-labels', default=False, action='store_true', help='hide labels')
parser.add_argument('--hide-conf', default=False, action='store_true', help='hide confidences')
parser.add_argument('--half', action='store_true', help='use FP16 half-precision inference')
parser.add_argument('--dnn', action='store_true', help='use OpenCV DNN for ONNX inference')
opt = parser.parse_args()
opt.imgsz *= 2 if len(opt.imgsz) == 1 else 1 # expand
print_args(FILE.stem, opt)
return opt
def main(opt):
check_requirements(exclude=('tensorboard', 'thop'))
run(**vars(opt))
if __name__ == "__main__":
opt = parse_opt()
main(opt)
进行预测



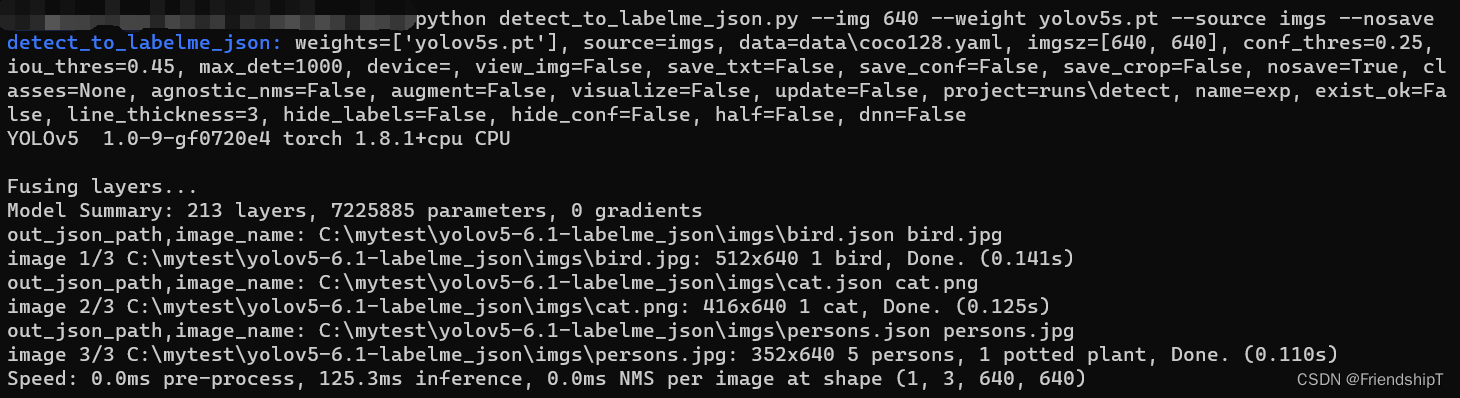
python detect_to_labelme_json.py --img 640 --weight yolov5s.pt --source imgs --nosave
输出结果




- 由于本人水平有限,难免出现错漏,敬请批评改正。
- 更多精彩内容,可点击进入Python日常小操作专栏、OpenCV-Python小应用专栏、YOLO系列专栏、自然语言处理专栏或我的个人主页查看
- 基于DETR的人脸伪装检测
- YOLOv7训练自己的数据集(口罩检测)
- YOLOv8训练自己的数据集(足球检测)
- YOLOv5:TensorRT加速YOLOv5模型推理
- YOLOv5:IoU、GIoU、DIoU、CIoU、EIoU
- 玩转Jetson Nano(五):TensorRT加速YOLOv5目标检测
- YOLOv5:添加SE、CBAM、CoordAtt、ECA注意力机制
- YOLOv5:yolov5s.yaml配置文件解读、增加小目标检测层
- Python将COCO格式实例分割数据集转换为YOLO格式实例分割数据集
- YOLOv5:使用7.0版本训练自己的实例分割模型(车辆、行人、路标、车道线等实例分割)
- 使用Kaggle GPU资源免费体验Stable Diffusion开源项目
文章来源:https://blog.csdn.net/FriendshipTang/article/details/135139278
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Zabbix监控
- TSINGSEE青犀边缘AI计算基于车辆结构化数据的车辆监控方案
- Linux——— grep命令详解(狠狠爱住)
- ubuntu 22.04 快速安装Odoo17.0详记
- 2024年【建筑电工(建筑特殊工种)】报名考试及建筑电工(建筑特殊工种)新版试题
- SpringBoot接口开发
- Python异常值的自动检测实战案例
- 【控制篇 / 策略】(7.4) ? 03. 地理地址对象在路由中的应用 ? FortiGate 防火墙
- 蒙特卡洛方法:Python实现
- 【计算机组成原理】---总线系统