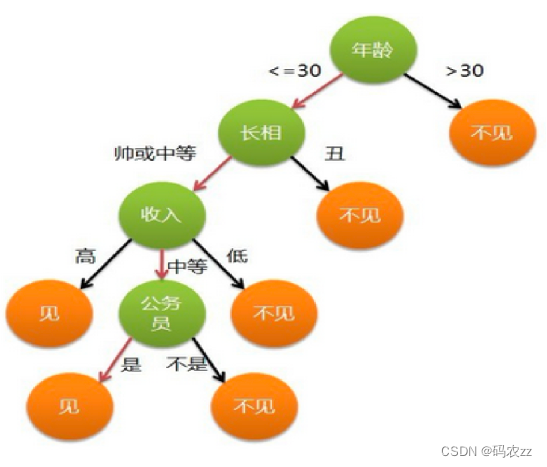
决策树的分类
概念
决策树是一种树形结构
树中每个内部节点表示一个特征上的判断,每个分支代表一个判断结果的输出,每个叶子节点代表一种分类结果
决策树的建立过程
1.特征选择:选取有较强分类能力的特征。
2.决策树生成:根据选择的特征生成决策树。
3. 决策树也易过拟合,采用剪枝的方法缓解过拟合
决策树的分类
ID3 决策树
如何挑选出区分度最强的特征:
????????遍历所有特征, 尝试进行分类, 计算所有特征的信息增益
????????选择信息增益最大的特征作为当前轮选出来的特征
信息熵/信息增益
????????在信息论中代表随机变量不确定度的度量

????????????????其中 P(xi) 表示数据中类别出现的概率,H(x) 表示信息的信息熵值
????????信息增益 = 信息熵 - 条件熵
????????????????条件熵 = ∑ 当前类别特征取值在所有样本中的比例 * 当前类别特征取值的信息熵
ID3 决策树生长停止的条件
????????所有的叶子结点信息熵为0
????????所有的特征都用完了
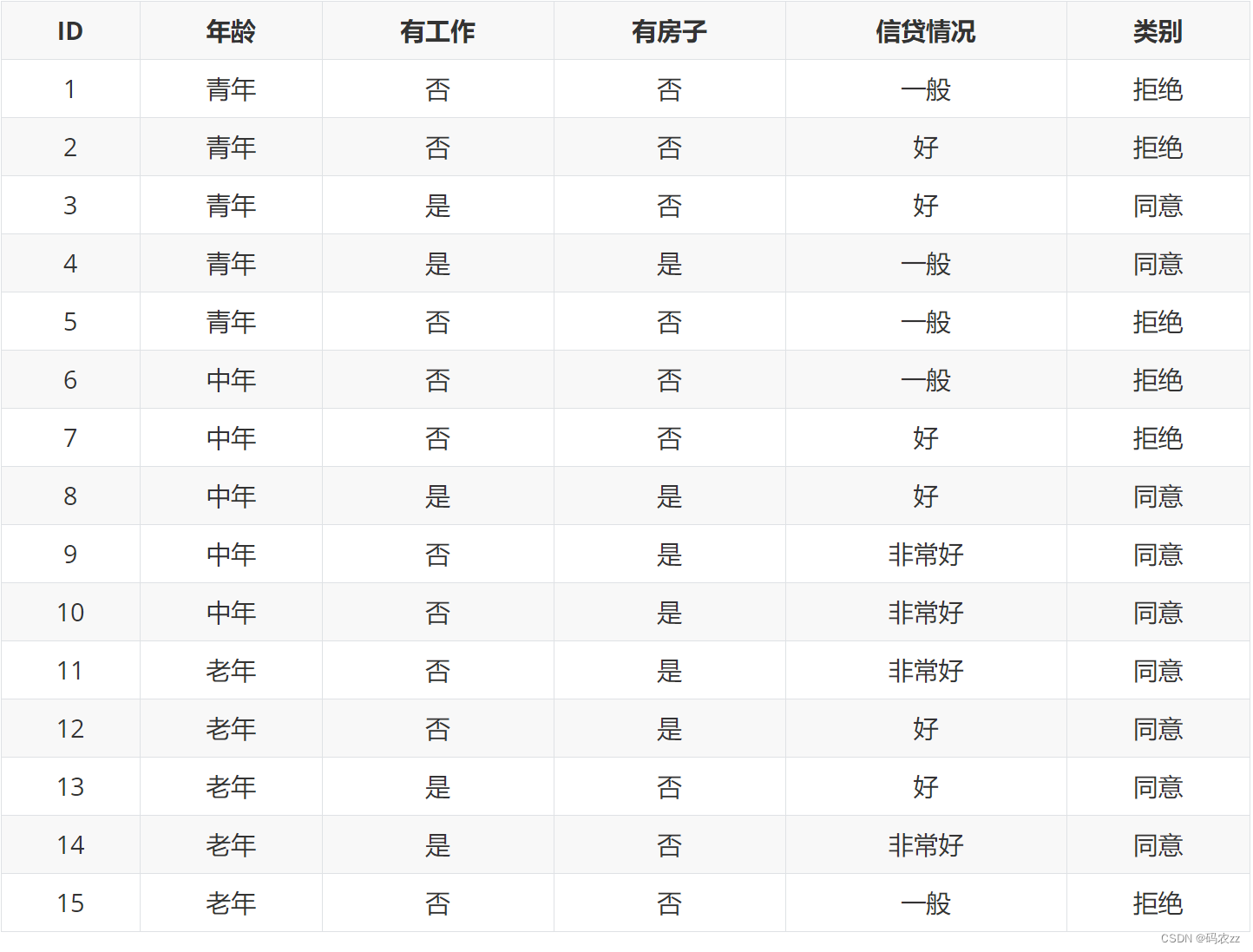
案例
下面以常用的贷款申请样本数据表为样本集,通过数学计算来介绍信息增益计算过程。
Step1 计算经验熵
类别一共是两个拒绝/同意,数量分别是6和9,根据熵定义可得:
![]()
Step2 各特征的条件熵
将各特征分别记为 $A_1,A_2,A_3,A_4$ ,分别代表年龄、有无工作、有无房子和信贷情况,那么

?Step3 计算增益

根据计算所得的信息增益,选取最大的$A_3$ 作为根节点的特征。它将训练集 $D$ 划分为两个子集$D_1$(取值为“是”)和$D_2$(取值为“否”)。由于$D_1$只有同一类的样本点,所以成为一个叶节点,节点标记为“是”。
对于$D_2$需从特征$A_1,A_2,A_4$中选择新的特征。计算各个特征的信息增益

?选择信息增益最大的特征$A_2$作为节点的特征。由于$A_2$有两个可能取值,一个是“是”的子节点,有三个样本,且为同一类,所以是一个叶节点,类标记为“是”;另一个是“否”的子节点,包含6个样本,也属同一类,所以也是一个叶节点,类别标记为“否”。
最终构建的决策树如下:

ID3算法步骤
????????计算每个特征的信息增益
????????使用信息增益最大的特征将数据集 S 拆分为子集
????????使用该特征(信息增益最大的特征)作为决策树的一个节点
????????使用剩余特征对子集重复上述(1,2,3)过程
?C 4.5 决策树
ID3 决策树的缺陷:
????????倾向于选择类别取值比较多的特征, (ID3 计算信息增益带来的缺陷)
C4.5 做特征选择的时候, 计算的是信息增益率, 而不是信息增益
????????信息增益率 = 信息增益/ 特征自己的信息熵
????????相当于对信息增益进行修正,增加一个惩罚系数
Cart树
Cart模型是一种决策树模型,它即可以用于分类,也可以用于回归。
Cart回归树使用平方误差最小化策略
Cart分类生成树采用的基尼指数最小化策略。
Cart分类生成树
基尼值Gini(D):从数据集D中随机抽取两个样本,其类别标记不一致的概率。故,Gini(D)值越小,数据集D的纯度越高。
基尼指数Gini_index(D):选择使划分后基尼系数最小的属性作为最优化分属性。

?注意:
信息增益(ID3)、信息增益率值越大(C4.5),则说明优先选择该特征。 基尼指数值越小
(cart),则说明优先选择该特征。
Cart回归决策树
CART 回归树和 CART 分类树的不同之处在于:?
CART 分类树预测输出的是一个离散值,CART 回归树预测输出的是一个连续值 CART 分类树使
用基尼指数作为划分、构建树的依据,CART 回归树使用平方损失 分类树使用叶子节点多数类别
作为预测类别,回归树则采用叶子节点里均值作为预测输出
CART 回归树的平方损失
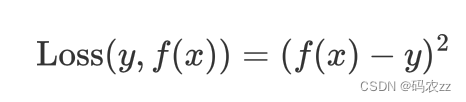
?决策枝剪枝
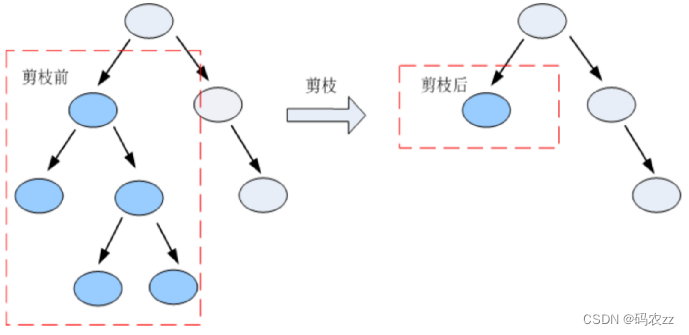
为什么要剪枝:
????????决策树剪枝是一种防止决策树过拟合的一种正则化方法;提高其泛化能力
????????把子树的节点全部删掉,使用用叶子节点来替换
剪枝的方式
预剪枝:指在决策树生成过程中,对每个节点在划分前先进行估计,若当前节点的划分不能带来决
策树泛化性能提升,则停止划分并将当前节点标记为叶节点;
? ? ? ? 优点: 预剪枝使决策树的很多分支没有展开,不单降低了过拟合风险,还显著减少了决策树的
????????????????训练、测试时间开销
? ? ? ? 缺点: 有些分支的当前划分虽不能提升泛化性能,但后续划分却有可能导致性能的显著提高;?
???????????????? 预剪枝决策树也带来了欠拟合的风险
后剪枝:是先从训练集生成一棵完整的决策树,然后自底向上地对非叶节点进行考察,若将该节点
对应的子树替换为叶节点能带来决策树泛化性能提升,则将该子树替换为叶节点。
????????优点: 比预剪枝保留了更多的分支。一般情况下,后剪枝决策树的欠拟合风险很小,泛化性能
????????????????往往优于预剪枝
? ? ? ? 缺点: 后剪枝先生成,后剪枝。自底向上地对树中所有非叶子节点进行逐一考察,训练时间开
????????????????销比未剪枝的决策树和预剪枝的决策树都要大得多。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Ansible自动化运维以及模块使用
- matlab中如何将视频保存成图像
- OLED取模流程
- cpu温度监测工具 -- Turbo Boost Switcher Pro
- 克魔助手:方便查看iPhone应用实时日志和奔溃日志工具
- docker安装 mysql 8.0.32
- 机器学习 | Python实现基于GRNN神经网络模型
- 【Web API系列】使用异步剪贴板API(async clipboard)的图像的编程复制和粘贴
- 【管理篇 / 恢复】? 08. 文件权限对macOS下用命令刷新固件的影响 ? FortiGate 防火墙
- Spring常见的造成数据库连接泄露的写法