KoPA: Making Large Language Models Perform Better in Knowledge Graph Completion
本来这个论文用来组会讲的,但是冲突了,没怎么讲,记录一下供以后学习。
创新点
按照我的理解简单概述一下这篇论文的创新点
- 提出使用大模型补全知识图谱,并且融合知识图谱的结构信息
- 提出一个新的模型KoPA模型,采用少量的参数进行模型的微调
- 采用类似于In-context learning的方式实现,structure-aware
常规的知识图谱补全方式
根据目前对一些模型的了解,我其实也没看多少篇基于大模型的知识图谱补全论文,截至到目前,比较系统的接触的是这篇论文。
常规的知识图谱补全方式,通过实体和关系预测确实的实体,如(head, relation, ?)or (?,relation, tail)。通常是采用一些方式结合实体和关系,来和所有的候选实体进行语义相似度进行计算,如ConvE:
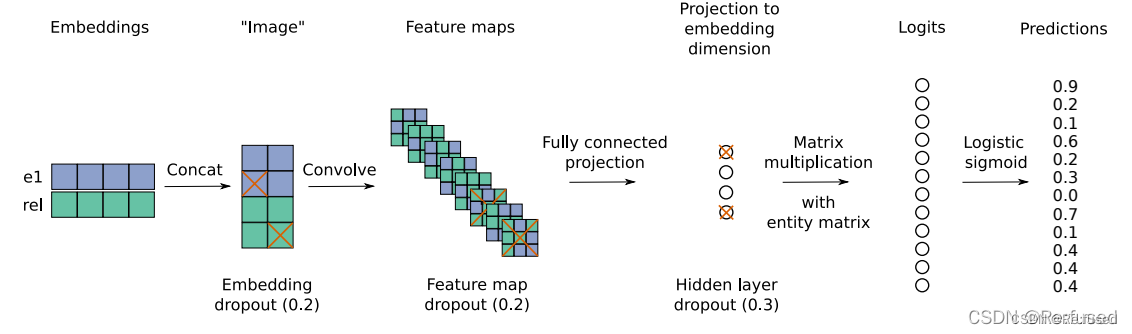
还有一些论文则是,将三元组同时作为输入进行整个三元组进行计算出一个得分,在评估的时候破坏三元组,计算整个三元组的得分, 如ConvKB:
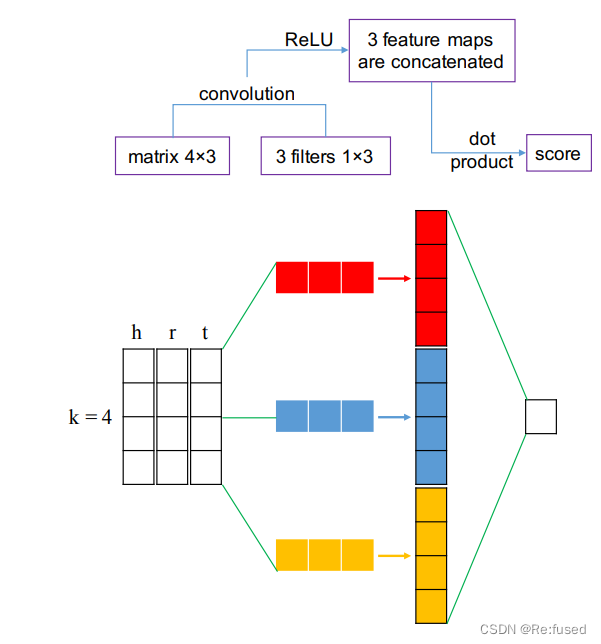
以上两种方式,算是一种比较传统的方式,进行排序,选择正确的三元组作为结果。通常采用MR, MRR, Hits@K,作为常规的评估指标。
大模型进行知识图谱补全
以我目前对大模型结合知识图谱补全的方式,我理解大模型没法像上述方式进行知识图谱补全(应该是有其他的方式,我没太仔细看)。这篇论文,我理解的是它的本质是把知识图谱补全问题转化为二分类的问题。如下图所示:
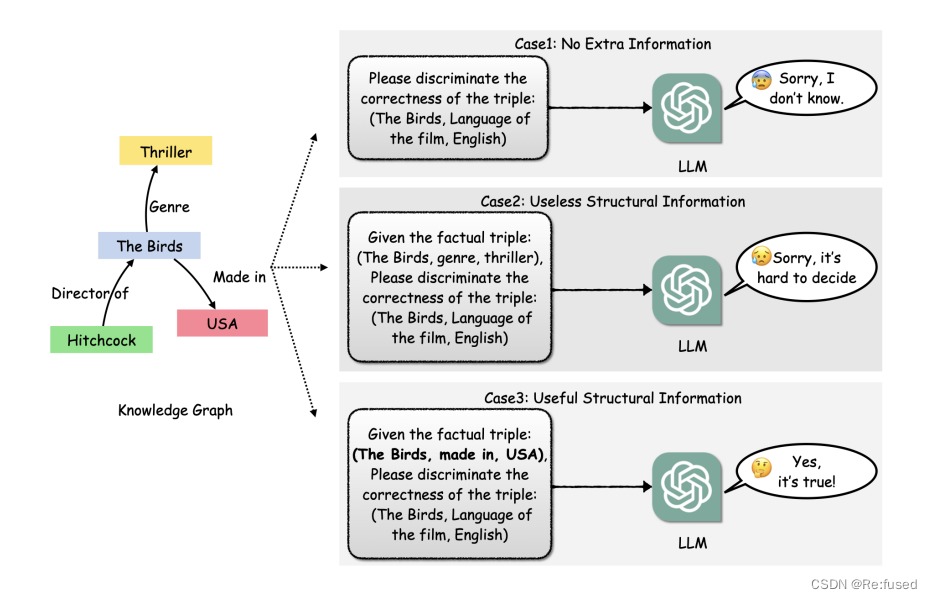
其实是给予一个三元组,判断这个三元组是否是正确的三元组,如果是正确的三元组,通过prompt回答一个Yes,否则是No.的形式,进行知识图谱补全,和常规的方式略有区别。
下面是截取的数据形式:
{
"instruction": "Given a triple from a knowledge graph. Each triple consists of a head entity, a relation, and a tail entity. Please determine the correctness of the triple and response True or False.",
"input": "\nThe input triple: \n( nucleic acid nucleoside or nucleotide, affects, mental or behavioral dysfunction )\n",
"output": "True",
"embedding_ids": [
31,
27,
89
]
},
{
"instruction": "Given a triple from a knowledge graph. Each triple consists of a head entity, a relation, and a tail entity. Please determine the correctness of the triple and response True or False.",
"input": "\nThe input triple: \n( nucleic acid nucleoside or nucleotide, affects, fully formed anatomical structure )\n",
"output": "False",
"embedding_ids": [
31,
27,
83
]
},
我粗略的理解,为了实现label平衡的状态,负样例需要针对正样例进行破坏即可,从而实现label实现样例比较均衡的状态。模型的评估指标也就是常规的二分类的评估指标。
模型讲解
常规的LLM没有充分利用知识图谱的结构信息,该论文则是结合文本信息和三元组信息进行微调,模型结构如下:
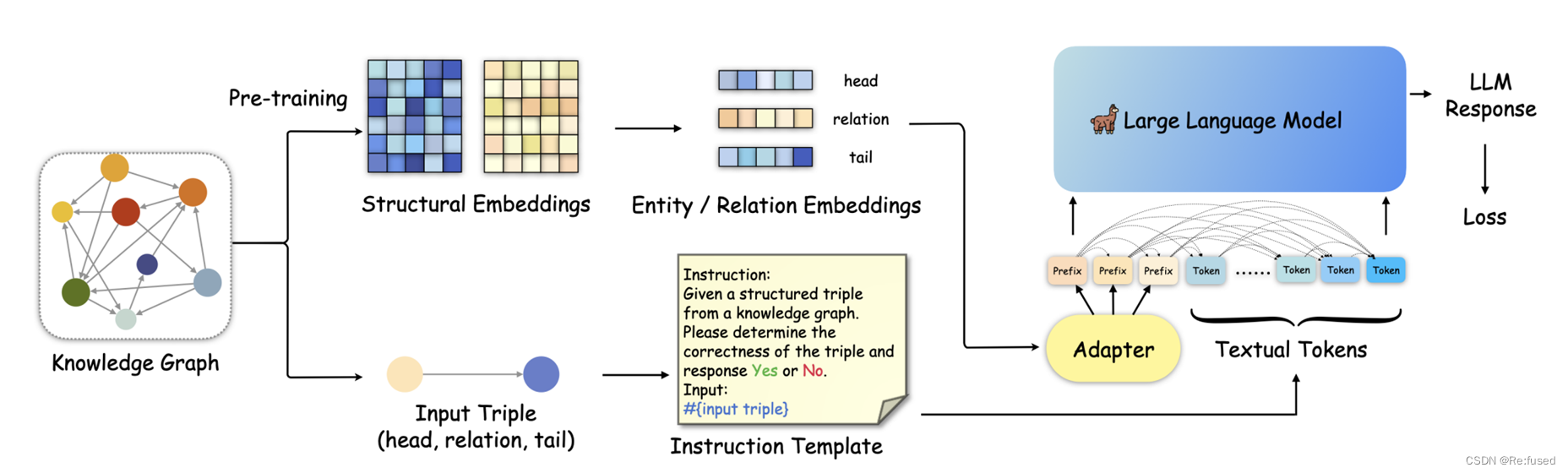
以上就是模型的输入,宏观上将输入包含两个部分,结构信息和文本信息。结构信息未为Adapter,进行微调类似于大模型的微调方式P-tuning。
- 结构信息
对于结构信息作为prefix或者Adapter,则是采用常规的KGC(知识图谱补全),如RotatE, TransE进行预训练参数,但是由于结构化嵌入的参数与大模型的输入不一致,则需要进行线性变换:其中 K \mathcal K K表示结构信息
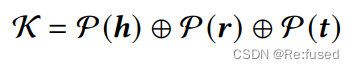
P \mathcal P P则是一个线性层,进行维度变换,在训练的过程中, h , r , t \mathcal h, r, t h,r,t 结构化参数进行冻结,只训练线性层参数。 - 文本信息
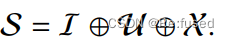
文本信息包含三个部分, I , U , X \mathcal I, \mathcal U, \mathcal X I,U,X分别表示Instruction文本信息;可选的文本信息;以及三元组的描述信息,其描述如下,就是实体和关系的描述信息进行简单的拼接的方式。
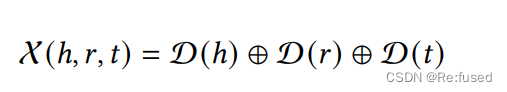
其中 U \mathcal U U可选信息,在使用的时候也是ICL信息,在这里称作structure-aware。本质上就是利用头实体和尾实体相邻的三元组,作为样例。三元组的形式,我理解应该也是实体描述的形式,然后告诉这个三元组的结果。类似一下形式:

- 可调参数
对于该可调的参数,主要是两个方面,结构信息的维度变化参数;对于大模型,并没有采用全量参数微调,而是采用一种Lora微调的方式,主要的可学习参数在Lora的两个线性举证方面
实验结果
数据集统计:
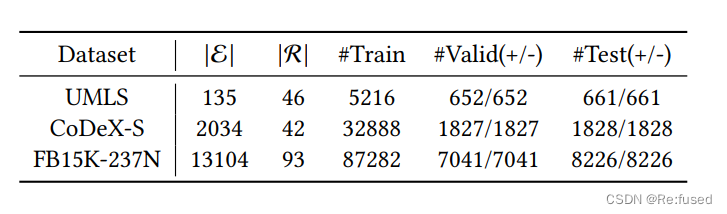
其实就是一个正例子,一个负例子
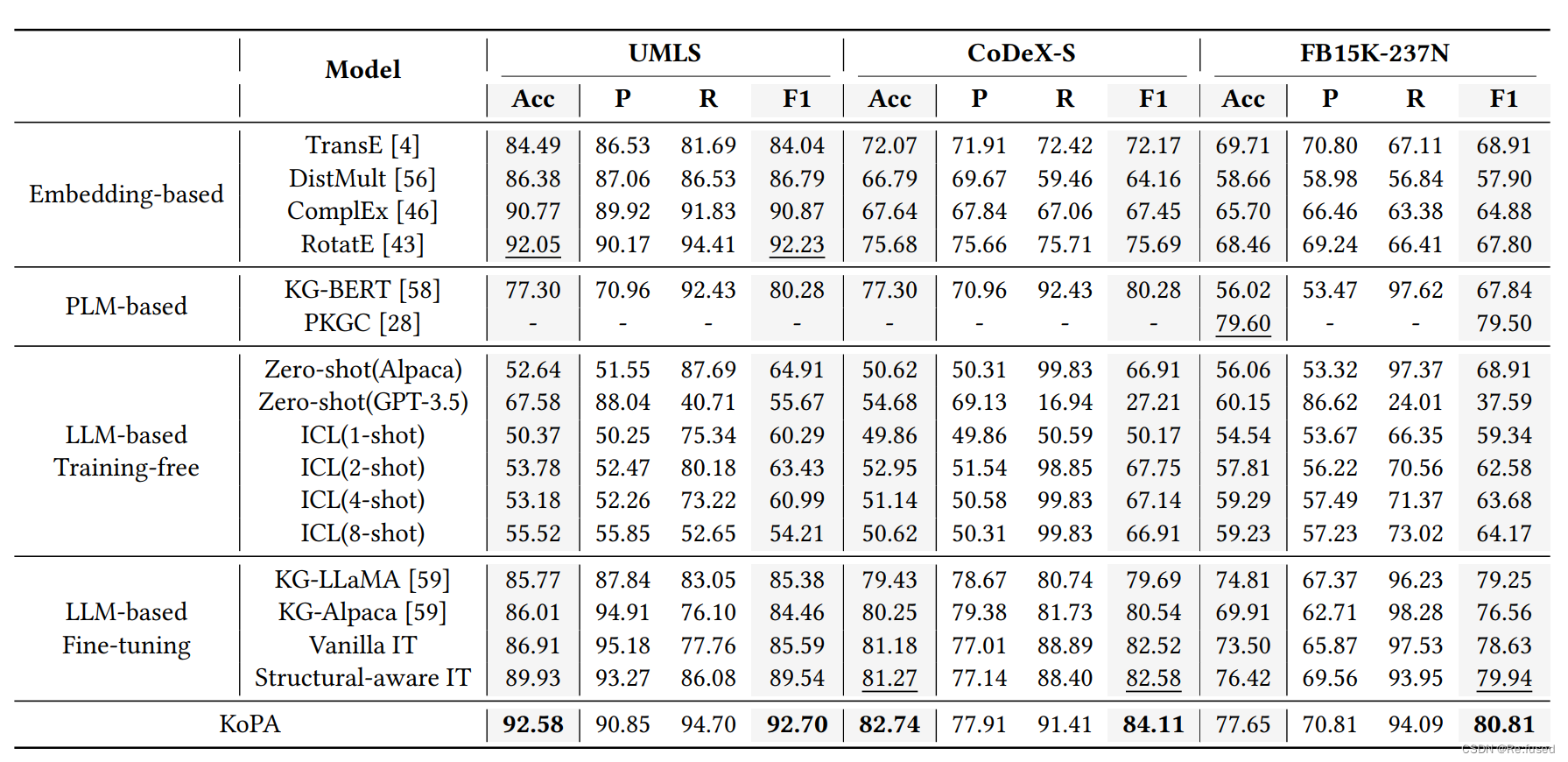
对于常规的方式则是设置一个得分的阈值进行二分类。
消融实验
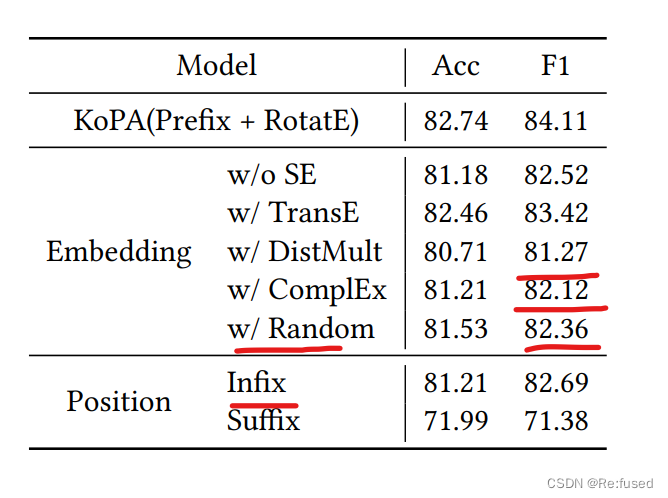
消融实现则是探究,常规的KGC方式进行预训练的影响, random则是探索采用随机的嵌入方式的影响。
结论
本论文实现了,大模型和知识图谱结构信息结合的论文,只训练很少的参数。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【开题报告】基于 SSM 的学生宿舍报备报修系统设计与实现
- 考公还是互联网?
- 零基础教学文档之:docker
- 华为HCIA课堂笔记第六章 OSPF基础
- 迭代器与生成器
- 设计师们必备的神秘利器!这款设计工具不容忽视!
- 编程笔记 html5&css&js 013 网页布局框架
- 智能电气柜环境监测系统
- 2024年1月11日 主题:非枪人生
- springboot(ssm火锅店管理系统 火锅在线点餐系统 Java系统