Text2SQL学习整理(二) WikiSQL数据集介绍
导语
上篇博客中,我们已经了解到Text2SQL任务的基本定义,本篇博客将对近年来该领域第一个大型数据集WikiSQL做简要介绍。
WikiSQL数据集概述
基本统计特性
WikiSQL数据集是一个多数据库、单表、单轮查询的Text-to-SQL数据集。它是Salesforce在2017年提出的大型标注NL2SQL数据集,也是目前规模最大的NL2SQL数据集。它包含了 24,241张表,80,645条自然语言问句及相应的SQL语句。
其问句形式分布统计如下:
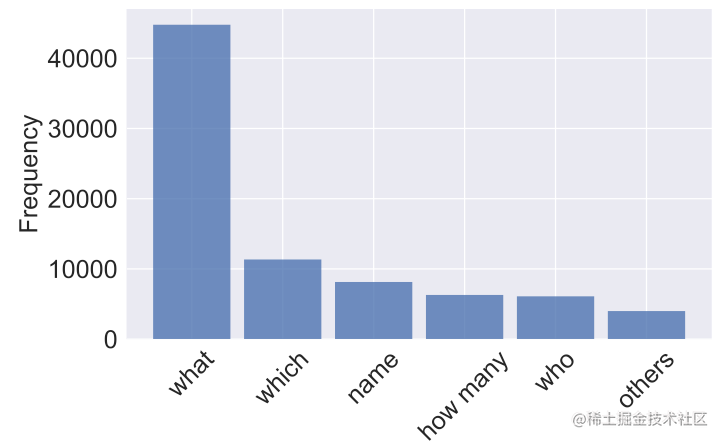
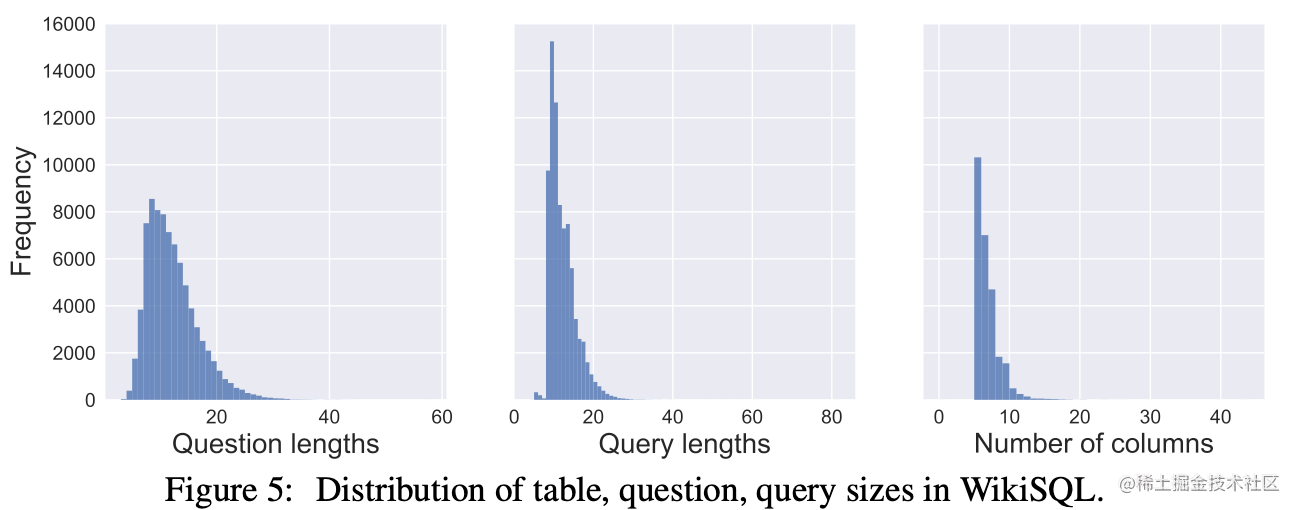
相应的Question、Query(即Question对应的SQL语句)以及每一个SQL数据库表中的column数目的分布如下图所示:
特点
WikiSQL与其他的数据集对比如下图。可以看到,WIkiSQL是规模最大、schema覆盖最丰富的数据集。
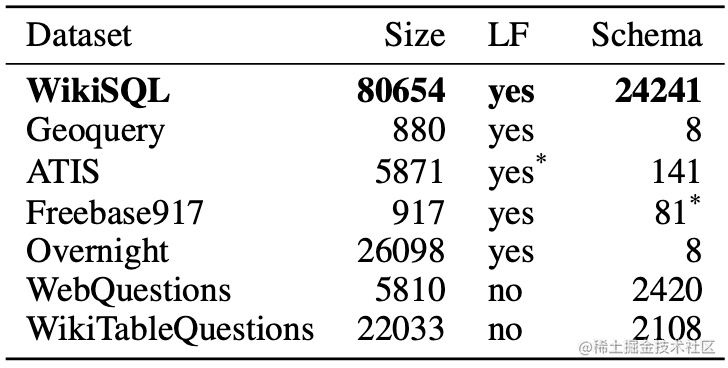
WikiSQL每个数据库都只有一个table,因而无需考虑主键、外键的问题。同时,其预测的SQL语句形式比较简单,基本为一个SQL主句加上0-3个WHERE子句条件限制构成。

评价指标
主要评价指标有两个:
- 逻辑形式准确率( A c c L F Acc_{LF} AccLF?,即生成的SQL语句和Ground truth完全相同的比例)
- 执行准确率( A c c E X Acc_{EX} AccEX?,即生成的SQL语句执行结果与Ground truth执行结果完全相同的比例)
相关研究
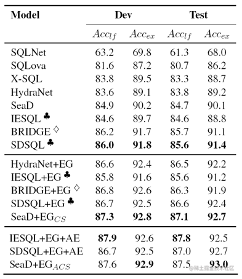
目前该数据集的Leaderboard如下:
主要研究论文如下:

接下来,本文将简要介绍WikiSQL作者在该数据集上提出的baseline方法,Seq2SQL。
Seq2sql: Generating structured queries from natural language using reinforcement learning
这篇论文首先提出了WikiSQL数据集,然后利用改进的Pointer Network(这是一种改进的Seq2seq模型,后续我会再详细写一篇博客说明) + RL在上面达到了最好的结果。

Seq2SQL由三部分组成:
- Aggregation classifier(用于判断使用哪个聚合函数)
- SELECT column(用于判断输出的是哪一个column)
- WHERE clause(a pointer decoder)(用于输出WHERE子句)
模型采用序列化输入,其编码格式如下:
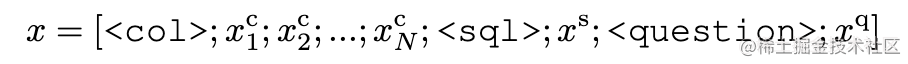
序列化输入 x x x被送入一个两层的Bi-LSTM以获取隐层表示。之后,该表示分别送入以上三个模块获得该模块的输出。
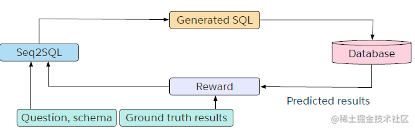
模型的整体架构如上图所示。在预测WHERE子句时,除了使用基本的Pointer Network之外,作者还引入了强化学习,以鼓励模型预测出更多的同义SQL语句。

由于正确的SQL语句不只是一种表达形式,因而作者提出使用RL来促使模型生成正确的SQL语句,其中WHERE子句的各个条件不一定与Ground Truth中的顺序相同。
最终,作者提出的模型和之前的一些baseline对比结果如下:
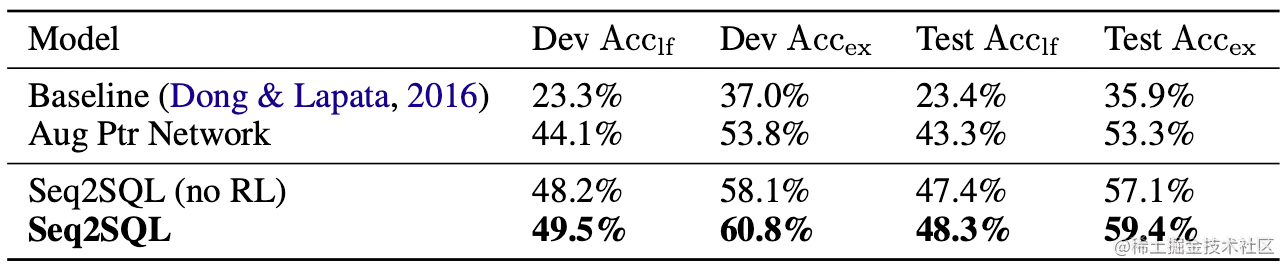
可以看到,强化学习的引入对最终表现的提升实际上并没有那么好,因而在WikiSQL以及后续Text2SQL任务的研究中,也很少看到强化学习的踪影。
WikiSQL的引入使得该领域研究热情点燃,尽管这篇论文被当年的ICLR所拒稿,但后续仍有不少研究follow了这一数据集,后面的文章中将为大家介绍几个该数据集上的主要研究方法。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- PLC龙门刨床横梁运动控制程序示例
- 面试官:说说flexbox(弹性盒flex布局),以及适用场景?
- B端产品经理学习-如何进行埋点
- 单细胞转录组学对代谢功能障碍相关脂肪变性肝病的类器官模型进行分析
- 华为OD机试真题-分披萨-2023年OD统一考试(C卷)
- 【python学习】-用matplotlib实现将二维数据绘制为三维图形(三维多线图)并实战(三维散点图)
- 学习vue3(一)
- 关于“Python”的核心知识点整理大全24
- 【复现】(day)全程云OA SQL注入漏洞_09
- 网络安全专家必备的20个操作系统