GroupMixFormer:Advancing Vision Transformers with Group-Mix Attention论文学习笔记
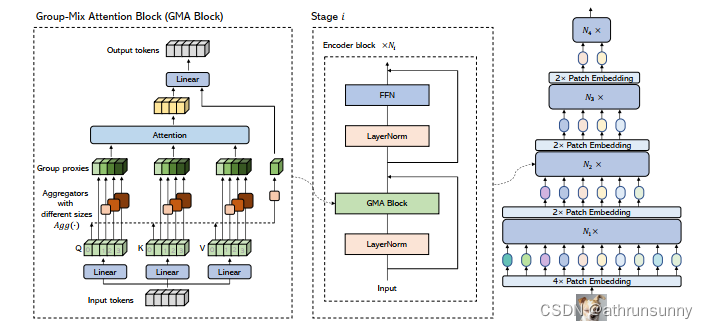
摘要:ViT?已被证明可以通过使用多头自注意力 (MHSA) 对远程依赖关系进行建模来增强视觉识别,这通常被表述为Query-Key-Value?计算。但是,从“Query”和“Key”生成的注意力图仅捕获单个粒度的token-to-token的相关性。在本文中,作者认为自注意力应该有一个更全面的机制来捕捉?tokens和groups(即多个相邻tokens)之间的相关性,以获得更高的表征能力。因此,作者提出Group-Mix Attention(GMA)作为传统自注意力的高级替代品,它可以同时捕获具有各种group规模的token-to-token, token-to-group, and group-to-group的相关性。为此,GMA 将 Query、Key 和 Value 统一拆分为多个段,并执行不同的分组聚合以生成分组代理(group proxies)。注意力图是根据tokens和group proxies的混合计算的,用于在 Value 中重新组合tokens和groups。
基于GMA,作者引入了一个强大的骨干,即GroupMixFormer,它在图像分类、目标检测和语义分割方面实现了最先进的性能,参数比现有模型少。例如,GroupMixFormer-L(具有70.3M参数和384输入)在没有外部数据的情况下在ImageNet-1K上达到86.2%的Top1准确率,而GroupMixFormer-B(具有45.8M参数)在ADE20K上达到51.2%的mIoU。
简单总结:本文通过将QKV统一划分为5段,pre-attention branche(四段)其中三段分别做核大小为3/5/7(即滑动窗大小)的深度可分离卷积来实现聚合器,将滑动窗周围的信息聚合在一个token中,其中一个不做聚合,以保持网络在建模单个token相关性方面的能力,最后一段被建模为非注意力分支,该段有聚合器但没有注意力,如图三所示。利用了组聚合器同时捕捉token-to-token、token-to-group和group-to-group的关联。
1. Introduction
????????多头自注意力 (MHSA) 是显著提高ViT性能的一个关键模块,它支持使用长程依赖建模 、全局感受野、更高的灵活性进行网络设计和更强的鲁棒性。通常的注意力计算,关注的是单个token对之间的相关性计算。然而,经验发现,Q-K-V自注意力存在一个主要局限性,如图1所示:注意力图仅在一个粒度上描述了每个单独的token对之间的相关性(图1(a)),并且将注意力图与Value相乘会线性重组单个token。该框架显然没有考虑不同维度上不同token groups(即邻域)之间的相关性。举一个具体的例子,自注意并没有将左上角的九个tokens作为一个整体与右下角的那些组相关联。这个限制虽然很明显,但无意中被忽略了,因为Q-K-V计算似乎能够对从输入到输出的映射进行建模,因为输出中的任何entry都与输入中的每个entry有关。
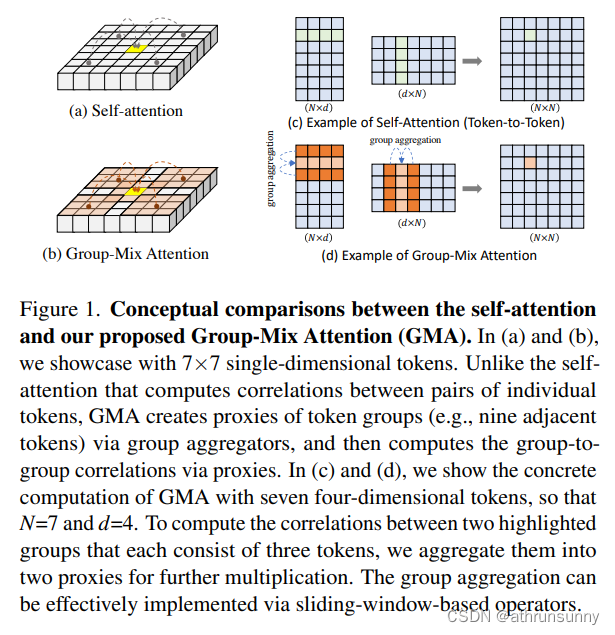
????????可以观察到,生成的注意力图仅捕捉了单一粒度上的 token 到 token 的关联,从而忽略了不同 token 组之间的关联。为解决这一局限性,本文提出了 Group-Mix Attention(GMA)。GMA 将 token 分割为片段,并通过组聚合器生成组代理替代一些个别 token。GMA旨在高效计算 token-to-token、token-to-group 以及 group-to-group的关联,提供更全面的建模方法。
????????在自注意力中,关注的焦点是token对之间的线性关系,而GMA引入了组代理的概念,使其能够在更高的层次上捕捉token组之间的关联。通过组代理,GMA能够在图像中的不同区域之间建立关联,而不仅仅是在个别tokens之间。这种设计使得GMA能够更全面地理解图像的结构信息,为视觉识别任务提供更强大的建模能力。图1(c)和(d)进一步说明了GMA在计算组到组关联时的具体步骤,突显了通过组代理和聚合实现的高效计算。这种设计使得GMA不仅能够更全面地捕捉tokens之间的关联,而且在计算效率上也具有优势。
GMA具有一些吸引人的优点:
(1)GMA不仅能够模拟单个token之间的相关性,还能够模拟token group之间的相关性。将不同种类的注意力混合在一起,以便从综合方面更好地了解token。 token-to-token、token-to-group 以及 group-to-group的相关性在每个单层中同时建模,以实现更高的表示能力。
(2)GMA高效且易于实施。group-to-group的相关性是通过将组聚合到?proxy tokens中,然后计算代理之间的相关性来计算的(如图 3 所示)。这样的过程可以通过基于滑动窗口的操作(例如池化和卷积)有效地实现。

2. Related Works
省略。。。
3. GroupMix Attention and GroupMixFormer
3.1. Motivation: from Individual to Groups
作者从最初的注意力机制讨论自注意力的局限性,如下式:
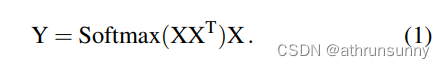
作者认为上式的局限在于,不能将某些特定的token建模成具有不同粒度的组的形式,上式仅考虑了单个token之间的相关性。在本文中,作者试图利用单个模式和组模式进行综合建模。与以前跨多个阶段(通常四个阶段Transformer主干网络)的不同模式建模的方法不同,作者的方法引入了一种新的方法,在每个阶段的每个单独层中对这个建模过程进行编码。具体来说,对于组模式,试图将一些token周围的token与其他token相关联。本文提出通过在 Query、Key 和 Value 中生成组代理来实现这一点(其实就是通过卷积和池化将token周围的信息聚合到一个token中来实现),并使用代理执行 Q-K-V 计算。
3.2. GMA: Mixing Groups for Better Attention
-
生成组代理:?首先,GMA引入了组代理的概念,通过替换Query、Key、和Value中的一些条目为整个组的聚合结果,这是通过滑动窗口操作(例如maxpooling、convolution等)高效实现的,其中不同的组使用不同大小的滑动窗口尺寸。这种替换将注意力从仅关注个别token扩展到了关注整个组。
-
关联不同大小组和个别token:?GMA通过使用不同大小的聚合器,对不同大小的组进行混合,同时通过深度卷积实现聚合,使得模型可以有效地关联不同大小的组和个别token。这在视觉任务中特别重要,因为图像中的信息可能以不同大小的组织存在。
-
维持特征分辨率:?在聚合的过程中,GMA保持了特征的分辨率,确保在注意力计算中不降低空间分辨率。这意味着GMA为注意力计算提供了更细粒度的特征,相较于降低特征大小的方法具有更好的性能。
-
同时关联多个token:?由于输入是组代理,而不是单个token,GMA能够同时关联多个token,这在建模关联方面更为全面和充分。这是通过在计算中使用不同的核大小来实现的。
-
结合个别token和组:?最后,通过将注意力计算得到的映射与Value相乘,实现了将关联的组和个别token重新组合,从而更好地捕捉了图像中的结构信息。
总体来说,GMA通过引入组代理和巧妙的聚合操作,实现了对不同大小组和个别token关联的全面建模,从而提升了模型在视觉识别任务中的性能。这种机制使得模型能够更全面地捕捉图像中的结构信息,提高了对不同尺度和层次的视觉模式的敏感性,使得模型更加适应各种复杂的视觉场景。
code
以下是本文的核心代码
class Aggregator(nn.Module):
def __init__(self, dim, seg=4):
super().__init__()
self.dim = dim
self.seg = seg
seg_dim = self.dim // self.seg
self.norm0 = nn.SyncBatchNorm(seg_dim)
self.act0 = nn.Hardswish()
self.agg1 = SeparableConv2d(seg_dim, seg_dim, 3, 1, 1)
self.norm1 = nn.SyncBatchNorm(seg_dim)
self.act1 = nn.Hardswish()
self.agg2 = SeparableConv2d(seg_dim, seg_dim, 5, 1, 2)
self.norm2 = nn.SyncBatchNorm(seg_dim)
self.act2 = nn.Hardswish()
self.agg3 = SeparableConv2d(seg_dim, seg_dim, 7, 1, 3)
self.norm3 = nn.SyncBatchNorm(seg_dim)
self.act3 = nn.Hardswish()
self.agg0 = Agg_0(seg_dim)
def forward(self, x, size, num_head):
B, N, C = x.shape
H, W = size
assert N == H * W
x = x.transpose(1, 2).view(B, C, H, W)
seg_dim = self.dim // self.seg # 按维度进行分组,相当于分了seg个head,每个head的维度为seg_dim
x = x.split([seg_dim]*self.seg, dim=1)
x_local = x[4].reshape(3, B//3, seg_dim, H, W).permute(1,0,2,3,4).reshape(B//3, 3*seg_dim, H, W)
x_local = self.agg0(x_local) # 把qkv的信息通过深度可分离卷积进行聚合
# 相当于在每个head上使用不同大小的核做深度可分离卷积,得到不同尺度的编码信息
# 就是将不同的核大小视为滑动窗的大小,并将滑动窗中的信息通过卷积编入滑动窗的中心,并以该中心作为该组的proxy
x0 = self.act0(self.norm0(x[0]))
x1 = self.act1(self.norm1(self.agg1(x[1]))) # 使用3*3的深度可分离卷积
x2 = self.act2(self.norm2(self.agg2(x[2]))) # 使用5*5的深度可分离卷积
x3 = self.act3(self.norm3(self.agg3(x[3]))) # 使用7*7的深度可分离卷积
x = torch.cat([x0, x1, x2, x3], dim=1)
C = C // 5 * 4
x = x.reshape(3, B//3, num_head, C//num_head, H*W).permute(0, 1, 2, 4, 3)
return x, x_local
3.3. Architectural Configurations
1. 层级拓扑:基于提出的Group-Mix Attention(GMA),引入了一系列名为GroupMixFormer的视觉Transformer模型,模型采用了具有四个阶段的分层拓扑结构,与主流的ViT模型保持一致。
2. 图像嵌入层:模型的第一层是一个4×的图像嵌入层,将图像嵌入为tokens。此过程通过两个连续的3×3卷积层实现,每个卷积层的步幅为2,然后是另外两个3×3的卷积层,步幅为1。在每个最后的三个阶段的开始,使用了一个2×的图像嵌入,同样通过3×3卷积实现。
3. 编码器块:在每个阶段内,构建了多个编码器块。每个编码器块除了包含上一子节中介绍的GMA块之外,还包含了一个Feed-Forward Network(FFN)、Layer Normalization和identity快捷连接,这符合大多数网络架构的通用处理方法。
4. 输出层:对于图像分类任务,最终的输出tokens通过全局平均池化(GAP)后输入分类器;对于密集预测任务(例如目标检测和语义分割),各自任务的头部可以利用四个阶段输出的金字塔特征。
5. 位置编码:与一些Transformer模型不同,该模型没有采用位置编码,因为通过GMA聚合器,模型自然地破坏了排列不变性。
6. 不同配置的模型:模型实例化了四个不同配置的模型,这些配置的架构超参数包括每个阶段的编码器块数目L、嵌入维度D和MLP比例R,具体见下表。

4. Experiments
作者提出的GroupMixFormer在多个任务中都做到了SOTA,主要是这里没有和TransNext作比较,将组代理的思想和TransNext的聚焦注意力相结合应该能达到更好的效果
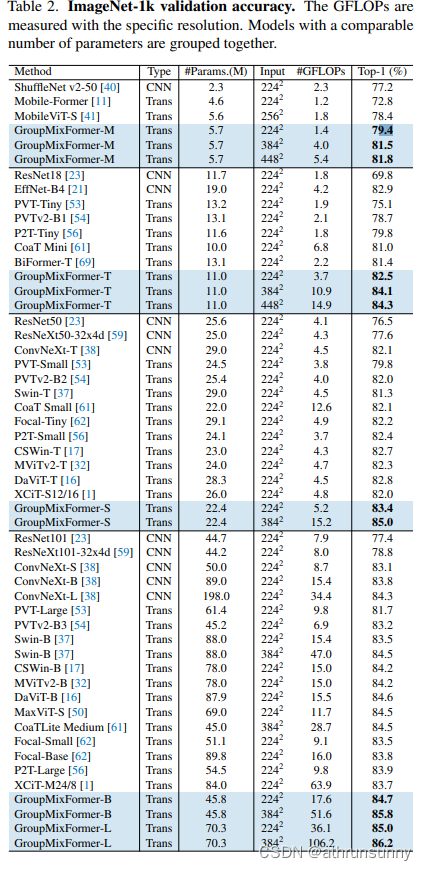
分类模型的结果对比
?检测的结果对比
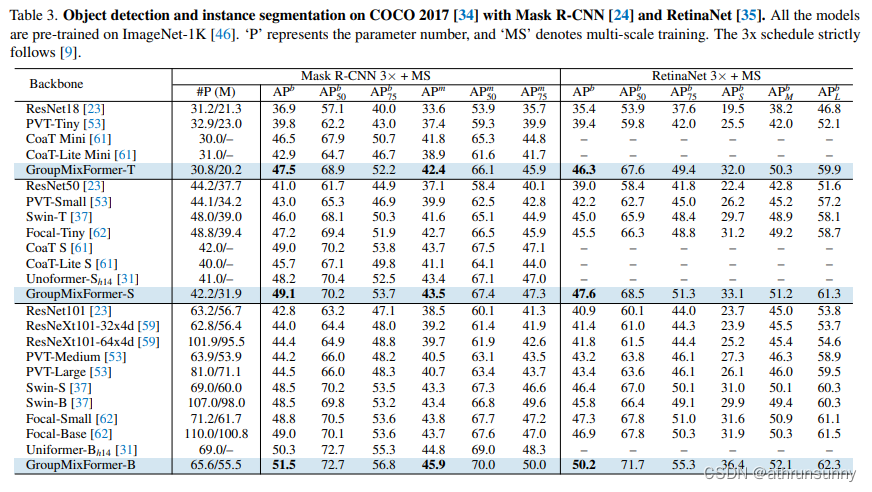
?分割模型结果对比
在附录中做了可视化的分析
在Attention Visualization部分的可视化结果如上图所示,当中展示了输入图像(a)以及来自集成层的注意力响应图(b)。此外,还展示了来自前注意力分支和非注意力分支的输出的响应图(c)到(g)。
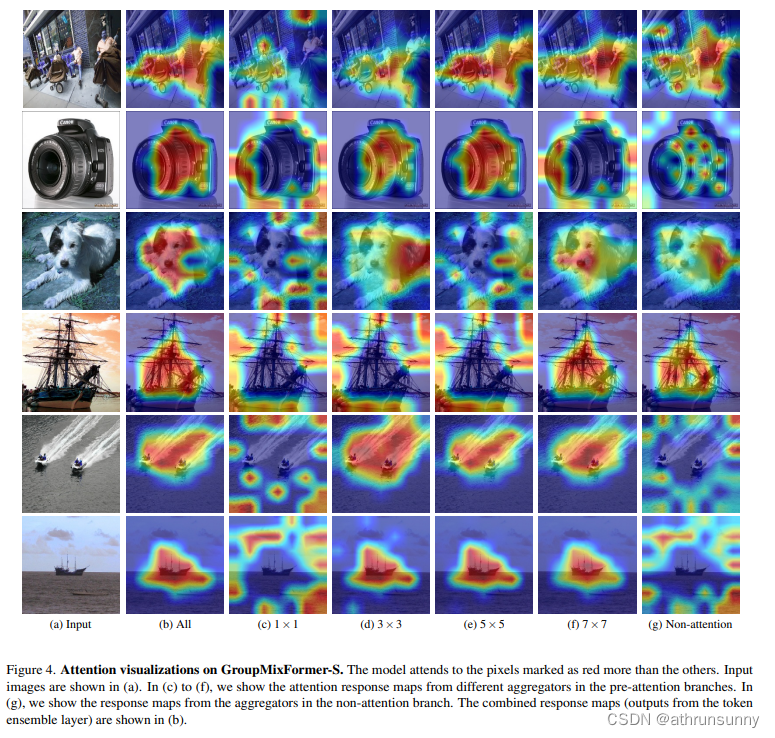
????????可以观察到,在应用自注意力于个别tokens时,有时会无法关注到对象,如(c)所示。在这种情况下,计算由聚合器生成的组代理之间的关联可能会有所帮助。例如,如第三行所示,通过处理由核大小为3和7的聚合器处理的组之间的关联,成功地集中注意力于狗,而在(c)中建模token-to-token的关联更多地关注背景。这些结果表明存在某些模式,因此应将一些tokens视为整体以捕捉对象特征。在GMA中,不同聚合器捕获的表示被组合在一起。这验证了全面建模token-to-token、token-to-group和group-to-group关联会导致更好的视觉识别。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- stm32 FOC系列 直流有刷控制原理
- docker rabbitmq控制台访问失败,rabbitmq控制台访问不了
- 【数据结构第 6 章 ④】- 用 C 语言实现图的深度优先搜索遍历和广度优先搜索遍历
- 客服智能管理系统是如何应用的
- 《机器人学一(Robotics(1))》_台大林沛群 第4周 Quiz4
- 【Pytorch简介】2.What are Tensors 什么是张量?
- x-cmd pkg | sd - sed 命令的现代化替代品
- String、StringBuilder、StringBuffer三者区别
- 第7章 7.6.5 常量指针 Page406~407
- Django 简单图书管理系统