【Python数据分析系列】一文搞懂二维数组中的排列组合(案例源码)
一、问题场景
? ? 在工作中,我们经常会碰到这样的问题场景,有一个4行5列的二维数组(4个波段,5个采样点),一行(一个一维数组)代表一个波段,我想知道数组中任意两个波段的差(即构造一个新指数)和水质参数(目标特征变量)的相关系数绝对值最大的情形,之后借助这个新指数做水质参数反演。即需要,计算任意两个一维数组的差值,求相关系数,并记录索引。
from itertools import permutations
from itertools import combinations
# itertools.permutations和itertools.combinations是Python标准库itertools中的两个函数,
# 用于生成集合元素的排列和组合。-
itertools.permutations(iterable, r=None):
-
permutations函数返回可迭代对象iterable中长度为r的元素排列。
-
如果不指定r,则默认为None,表示生成所有元素的全排列。
-
返回的排列是以元组的形式表示的。
-
排列的顺序是按照输入可迭代对象的顺序生成的。
-
-
itertools.combinations(iterable, r):
-
combinations函数返回可迭代对象iterable中长度为r的元素组合。
-
r必须大于等于0且小于等于可迭代对象的长度。
-
返回的组合是以元组的形式表示的。
-
组合的顺序是按照输入可迭代对象的顺序生成的。
-
二、实现过程
2.1 构造二维数组
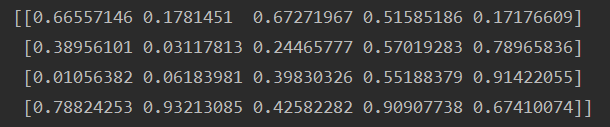
array_2d = np.random.rand(4, 5)
print(array_2d)????????这里我构造了一个四行五列的二维数组:
2.2 计算任意两个一维数组的差值,求相关系数,并记录索引
B_1 = []
B_2 = []
dif = []
parameter = [1.2, 1, 0.8, 2, 0.3]
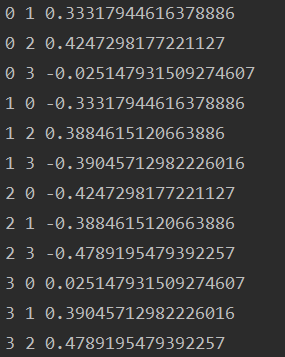
for pair in permutations(enumerate(array_2d), 2):
idx_a, array_a = pair[0]
idx_b, array_b = pair[1]
diff = array_a - array_b
diff_corr = pd.Series(parameter).corr(pd.Series(diff))
print(idx_a, idx_b, diff_corr)
B_1.append(idx_a)
B_2.append(idx_b)
dif.append(diff_corr)????????由于我想知道最优的情形,因此我用了enumerate函数给二维数组打上索引,记录每次取出的数组索引:
2.3 整理结果
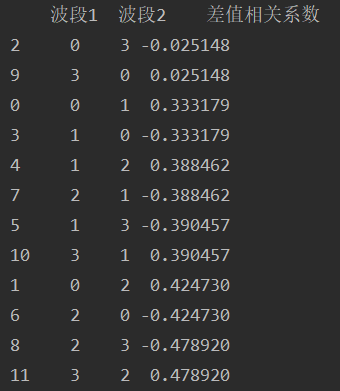
df = pd.DataFrame({'波段1':B_1, '波段2':B_2, '差值相关系数':dif})
df = df.sort_values(by='差值相关系数', key=abs)
print(df)????????结果如下:
小结
????????在上面的例子中,我只演示了itertools.permutations的用法,itertools.permutations函数会生成所有可能的排列,包括考虑元素的顺序。换句话说,它会生成包含相同元素但顺序不同的不同排列。如果不考虑元素的顺序,可以使用itertools.combinations函数,itertools.combinations函数生成的是包含不同元素的组合,不考虑元素的顺序。
好了,本篇内容就到这里,需要数据集和源码的小伙伴可以关注联系我!
作者简介:
读研期间发表6篇SCI数据挖掘相关论文,现在某研究院从事数据算法相关科研工作,结合自身科研实践经历不定期分享关于Python、机器学习、深度学习、人工智能系列基础知识与应用案例。致力于只做原创,以最简单的方式理解和学习,关注我一起交流成长。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- C#使用IsLeapYear方法判断指定年份是否为闰年
- 浅聊雷池社区版(WAF)的tengine
- 强大矢量图编辑器 Boxy SVG 激活最新
- 吐血整理,接口自动化测试实战(超详细)
- 葡萄酒术语中的“时髦”是什么意思?
- 如何搭建企业管理系统Odoo并实现无公网ip远程访问管理界面
- java&SSM&mysql书籍借阅管理系统04770-计算机毕业设计项目选题推荐(附源码)
- 在mt5上哪里可以添加指数品种?
- 组里新来了个00后,真卷不过....
- [网络安全] 远程登录