本地读取Excel文件并进行数据压缩传递到服务器
发布时间:2024年01月22日
? ? ? ? 在项目开发过程中,读取excel文件,可能存在几百或几百万条数据内容,那么对于大型文件来说,我们应该如何思考对于大型文件的读取操作以及性能的注意事项。
第一步:安装
npm install papaparse
第二步:内容的引入
import Papa from 'papaparse';
import { useState } from "react";
export default function App() {
const [results,setResults] = useState([]); //保留解析后的数据
const handleFile = (e) => {
const file = e.target.files[0];
Papa.parse(file,{
header:true, //指定第一行为标题行
skipEmptyLines:true, //跳过空行
complete:(parsedResult) => {
const data = parsedResult.data;
console.log(data) // 在控制台打印解析后的数据
}
})
};
return (
<div>
<h1>本地读取Excel文件并进行数据压缩传递到服务器</h1>
<input type="file" onChange={handleFile} accept='.csv' />
</div>
)
}
当我们上传的数据为百万条数据的时候,数据量是非常的庞大的,那么如果将数据传输到服务器上,将会对http的请求资源产生极大的浪费。所以我们考虑使用第三方类库pako进行数据的压缩。
对于pako,可以查看以下文章进行一个了解:https://github.com/nodeca/pako
第三步:pako安装
npm install pako
第四步:在组件中进行pako引入且对数据进行gzip的压缩
import pako from "pako";引入之后,将我们获取到的数据进行gzip的压缩
// gzip压缩
const gzip = pako.gzip(JSON.stringify(data),{to:"string"});
console.log(JSON.stringify(data).length,gzip.length); //打印的则是压缩后的数据信息
//原先的长度为41万,压缩后的长度为4万
且发送到后端(以下是改事件的全部代码,gzip的压缩数据也在其内)
const handleFile = (e) => {
const file = e.target.files[0];
Papa.parse(file,{
header:true, //指定第一行为标题行
skipEmptyLines:true, //跳过空行
complete:async (parsedResult) => {
const data = parsedResult.data;
console.log(data) // 在控制台打印解析后的数据
// gzip压缩
const gzip = pako.gzip(JSON.stringify(data),{to:"string"});
console.log(JSON.stringify(data).length,gzip.length); //打印的则是压缩后的数据信息
const response = await fetch("http://localhost:3000",{
method:"POST",
body:gzip,
headers:{
"Content-Type":"application/octet-stream", //数据流的方式进行上传处理
}
});
console.log(response)
}
})
};第五步:后端,后端也需要下载pako进行解压缩处理
const express = require("express");
const bodyParser = require("body-parser");
const cors = require("cors");
const pako = require("pako");
const app = express();
// 使用 cors 中间件处理跨域请求
app.use(cors());
// 使用 bodyParser 中间件解析请求体
app.use(bodyParser.raw({ type: "application/octet-stream", limit: "100mb" }));
// 处理 POST 请求
app.post("/", (req, res) => {
// 获取压缩后的数据
const compressedData = req.body;
// 解压缩数据
const uncompressedData = pako.ungzip(compressedData, { to: "string" });
// 将解压缩后的数据解析为 JSON 对象
const jsonData = JSON.parse(uncompressedData);
// 打印压缩前数据长度,解压缩后数据长度和 JSON 对象长度
console.log(
compressedData.length,
uncompressedData.length,
jsonData.length
);
// 构造响应消息
const msg =
compressedData.length +
" " +
uncompressedData.length +
" " +
jsonData.length;
// 发送响应
res.status(200).send(msg);
});
// 启动服务器,监听端口 3000
app.listen(3000, () => {
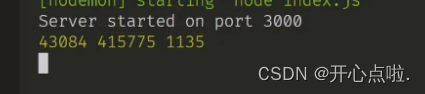
console.log("Server started on port 3000");
});
执行以上操作后,我们运行项目选择文件,后端返回三条数据
已压缩的长度? ?未压缩的长度? ?最终记录的条数
前端也已经返回了response的一个相应数据
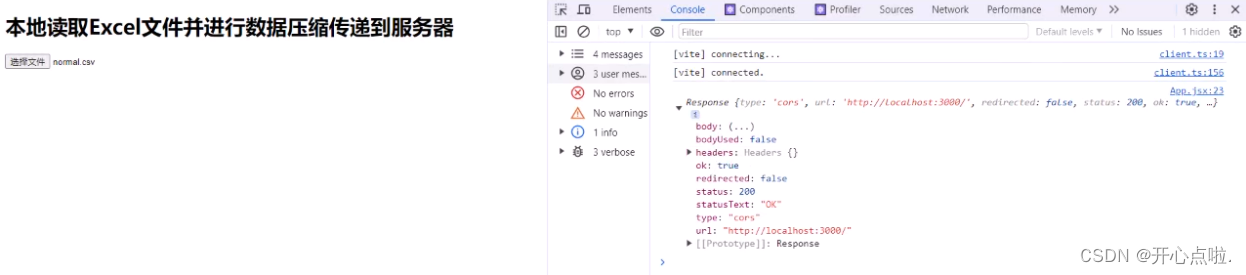
第六步:对打印的response进行进一步的处理?
console.log(response)
const result = {
success:response.ok.toString(),
status:response.status,
message:response.statusText,
};
setResults(result)第七步:展示到页面上
<h2>结果显示</h2>
<ul>
{results &&
Object.keys(results).map((key) => {
<li key={key}>
{key}:{results[key]}
</li>
})
}
</ul>
第八步:添加一个点击按钮事件切换背景颜色
const toggleBodyBackground = () => {
if(document.body.style.background === "red"){
document.body.style.background = "white";
}else{
document.body.style.background = "red"
}
}
<button onClick={toggleBodyBackground}>change body background</button>?当我进行大文件读取的时候会造成主线程的阻塞,那么后续我们可以进行功能的强化,在强化过程中,我们可以去考虑,是不是可以对现有的数据进行拆分,如果是一百多万条数据的时候,我们可以将一百多万条数据进行五万条,五万条的切片处理,然后不断的在后端进行压缩后数据的请求处理,最终可以在服务器端进行对数据的操作,减轻服务器的压力。
第九步:是否可以减轻服务器的压力,以下操作可以进行一个测试
使用console.time('test')开始时间设置和console.timeEnd("test")结束时间设置
const handleFile = (e) => {
console.time('test') //开始时间
const file = e.target.files[0];
Papa.parse(file,{
...............
};
setResults(result)
console.timeEnd("test"); //结束时间
}
})
};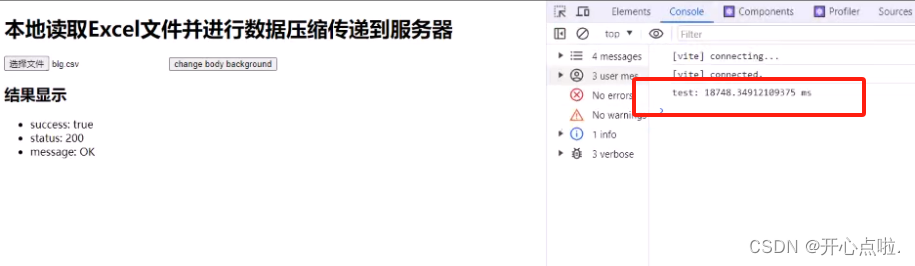
当前的测试时间为18秒左右,耗费时常比较久,那么随后我们会对其进行功能优化处理。
此内容已结束,希望对您有所帮助。?
文章来源:https://blog.csdn.net/zxcvb0825/article/details/135747183
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- vue3中canvas使用成组件不展示
- Hidataplus-3.3.2.0-005公测版本基于openEuler release 22.03 (LTS-SP2)的测试
- Oracle中带条件插入数据的使用方法
- 简单Web UI 自动化测试框架 seldom
- Hadoop集群部署
- xtu oj 1183 sum & times
- 360绩效评估该如何应用才能把效益值最大化?
- 小说推文总结
- C语言老兵学RUST了
- C 向数组输入五个整数求其均值