python 正则分割字符串
python 正则分割字符串
前段时间 对字符串的处理遇到了一个小问题,我希望在一个字符串中做特定的分割, 通过传入一个 pattern正则来分割字符串.
看例子 self.s 就是原始的字符串 ,字符串中包含一个时间,地点,事件 这样的一个结构. 但是下一个结构和上一个结构没有明显的分隔符, 我想通过分割字符串 分割成 self.expected_result 这种格式
def setUp(self):
self.s = '14:00,中国科技大学,KZB 阶段总结推进会-贺董(周总、沈总)15:00,中国科技大学,公司深改领导小组会(视频)班子成员16:30,中国科技大学,C929供应商选择领导小组会-贺董(周总、张总、沈总、戚总)18:30,中国科技大学,国内大飞机产业链布局方案专题会议-周总(张总、沈总)'
self.expected_result = [
'14:00,中国科技大学,KZB 阶段总结推进会-贺董(周总、沈总)',
'15:00,中国科技大学,公司深改领导小组会(视频)班子成员',
'16:30,中国科技大学,C929供应商选择领导小组会-贺董(周总、张总、沈总、戚总)',
'18:30,中国科技大学,国内大飞机产业链布局方案专题会议-周总(张总、沈总)'
]
首先想到使用正则模块的re.split 来处理一下
>>> s = '14:00,中国科技大学,KZB 阶段总结推进会-贺董(周总、沈总)15:00,中国科技大学,公司深改领导小组会(视频)班子成员16:30,中国科技大学,C929供应商选择领导小组会-贺董(周总、张总、沈总、戚总)18:30,中国科技大学,国内大飞机产业链布局方案专题会议-周总(张总、沈总)'
...
>>>
>>>
>>> res = re.split(r'\d{1,2}:\d{2}',s)
>>> from pprint import pprint
>>> pprint(res)
['',
',中国科技大学,KZB 阶段总结推进会-贺董(周总、沈总)',
',中国科技大学,公司深改领导小组会(视频)班子成员',
',中国科技大学,C929供应商选择领导小组会-贺董(周总、张总、沈总、戚总)',
',中国科技大学,国内大飞机产业链布局方案专题会议-周总(张总、沈总)']
结果发现 分割是成功了, 就是分割点 也被删除了. 我是想保留分割点的内容.所以这种方法也不行了.
于是要写个函数来处理
方法1:
通过 re.findall 寻找到 ‘分割点’ 然后记录要分割的索引位置, 最后分割字符串.
from typing import List
import re
def split_str(s: str, pattern=r'\d{1,2}:\d{2}') -> List:
"""
正则分割字符串, 根据正则分割特定的字符串
time_pattern = r'\d{1,2}:\d{2}'
"""
res_list = re.findall(pattern, s)
idxs = []
for res in res_list:
flag = re.search(res, s)
if flag:
idxs.append(flag.span()[0])
results = []
idxs_len = len(idxs)
s_len = len(s)
if idxs_len <= 1:
return [s]
for i in range(1, idxs_len):
results.append(s[idxs[i - 1]:idxs[i]])
# last 一个也放进去
results.append(s[idxs[idxs_len - 1]:s_len])
return results
方法2:
我们可以这样来实现,每次记录要分割的位置, 当要分割的位置数量为2 时候 ,可以进行分割, 然后删除最先的分割点. 这样就不需要 使用 re.findall ,每次匹配到一个分割点,就把 i更新到分割点最后一个字符的位置, 如果分割点为2个,那么就获取当前的元素,同时删除最先进去的元素. 最后记得 把最后一条分割结果保存一下, 还有特殊的边界情况,就是没有分割点的情况 如何处理.
def regex_split_01(s: str, pattern=r'\d{1,2}:\d{2}') -> List:
"""
pattern = r'\d{1,2}:\d{2}'
"""
result = []
i = 0
length = len(s)
position = deque([])
while i < length:
match = re.search(pattern, s[i:])
if match:
cur_start_position = match.span()[0] + i
cur_end_position = match.span()[1] + i
if len(position) < 2:
position.append(cur_start_position)
i = cur_end_position
if len(position) == 2:
# collect result
start, end = position
result.append(s[start:end])
i = cur_end_position
position.popleft()
else:
break
if position:
# 最后一条分割结果
result.append(s[position.popleft():length])
else:
result.append(s)
return result
仔细想了一下上面的方法 是否有问题呢? 是否可以在优化一下呢? 首先 就是关于len(position) 的长度判断 是不是可以先放进去 postion 在判断长度呢 ?
方法3:
我们 不需要单独判断 长度是否小于2 ,直接让匹配到位置点 入队列即可. 之后在判断 是否 长度大于等于2 , 然后在进行切割字符串. 切割字符串的时候取出开头的两个位置, 之后要把第二个位置放进去,因为下一次切割还会用到这个分割点.
def regex_split_02(s: str, pattern=r'\d{1,2}:\d{2}') -> List:
"""
pattern = r'\d{1,2}:\d{2}'
"""
result = []
i = 0
length = len(s)
position = deque([])
while i < length:
match = re.search(pattern, s[i:])
if not match:
# 此时说明 没有找到要分割的点
break
cur_start_position = match.span()[0] + i
cur_end_position = match.span()[1] + i
position.append(cur_start_position)
if len(position) >= 2:
# collect result
start = position.popleft()
end = position.popleft()
# 这里不能丢掉这个元素,还要再次 从左边添加回来,作为下一次切割的位置开始点
position.appendleft(end)
result.append(s[start:end])
i = cur_end_position
if position:
# 最后一条分割结果
result.append(s[position.popleft():length])
else:
# 没有要分割的点,直接返回原来的一条结果
result.append(s)
return result
此时分割 (a,b) (b,c) (c,最后的位置)

postion来回 出队列 入队列 确实容易让人产生疑惑. 我们也可以一次性把所有的分割点 都收集一下,最后在进行切割.
方法4:
就是 有分割点就放入position 中 ,最后统一处理分割点. 每次取相邻的分割点, 最后把最后一段放入到结果集中.
def regex_split_03(s: str, pattern=r'\d{1,2}:\d{2}') -> List:
"""
pattern = r'\d{1,2}:\d{2}'
"""
result = []
i = 0
length = len(s)
position = deque([])
while i < length:
match = re.search(pattern, s[i:])
if not match:
# 此时说明 没有找到要分割的点
break
cur_start_position = match.span()[0] + i
cur_end_position = match.span()[1] + i
position.append(cur_start_position)
i = cur_end_position
# found 分割点
if position:
for i in range(1, len(position)):
result.append(s[position[i - 1]:position[i]])
result.append(s[position[len(position) - 1]:length])
else:
result.append(s)
return result
如果s 的第一个匹配位置 不在开头的位置, 这样在收集结果的时候 会丢失调 从(0,a) 这段字符串的数据.
例如下面的情况
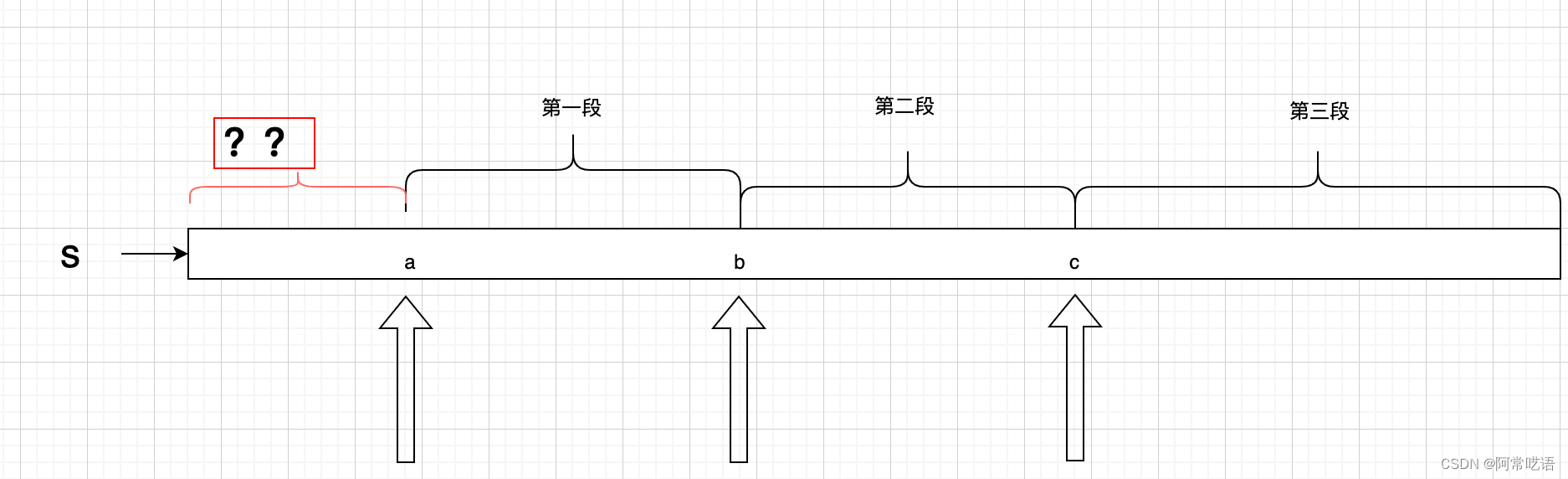
所以上面的代码都有这个问题, 第一段数据会被丢掉.
方法5:
改进了一下, 当position 所有的数据 收集了所有的分割点, 我们在首尾添加 两个 位置,分别是 字符串开始位置,以及字符串最后一个位置,这样在遍历 position 数组, 来分割字符串即可.
def regex_split(s: str, pattern=r'\d{1,2}:\d{2}') -> List:
"""
pattern = r'\d{1,2}:\d{2}'
"""
result = []
i = 0
length = len(s)
position = deque([])
while i < length:
match = re.search(pattern, s[i:])
if not match:
# 此时说明 没有找到要分割的点
break
cur_start_position = match.span()[0] + i
cur_end_position = match.span()[1] + i
position.append(cur_start_position)
i = cur_end_position
# found 分割点
if position:
begin = position[0]
end = position[-1]
if begin != 0:
position.appendleft(0)
if end != length:
position.append(length)
for i in range(0, len(position) - 1):
result.append(s[position[i]:position[i + 1]])
else:
result.append(s)
return result
测试代码
下面给出一个完整的测试代码
测试代码中 我仅仅测试了方法5中,如果匹配不是头开始的情况, 其他的情况 相信 小伙伴可以自己修改代码补上去,使测试代码能够完全跑过去.
@pytest.mark.skip 这个装饰器的内容, 方法1 到方法4 都需要修改一下, 这个 小伙伴可以 修改上面的代码, 使测试代码可以完全通过哦.
from typing import List
import re
from collections import deque
import unittest
import pytest
from pprint import pprint
def split_str(s: str, pattern=r'\d{1,2}:\d{2}') -> List:
"""
正则分割字符串, 根据正则分割特定的字符串
time_pattern = r'\d{1,2}:\d{2}'
"""
res_list = re.findall(pattern, s)
idxs = []
for res in res_list:
flag = re.search(res, s)
if flag:
idxs.append(flag.span()[0])
results = []
idxs_len = len(idxs)
s_len = len(s)
if idxs_len <= 1:
return [s]
for i in range(1, idxs_len):
results.append(s[idxs[i - 1]:idxs[i]])
# last 一个也放进去
results.append(s[idxs[idxs_len - 1]:s_len])
return results
def regex_split_01(s: str, pattern=r'\d{1,2}:\d{2}') -> List:
"""
pattern = r'\d{1,2}:\d{2}'
"""
result = []
i = 0
length = len(s)
position = deque([])
while i < length:
match = re.search(pattern, s[i:])
if match:
cur_start_position = match.span()[0] + i
cur_end_position = match.span()[1] + i
if len(position) < 2:
position.append(cur_start_position)
i = cur_end_position
if len(position) == 2:
# collect result
start, end = position
result.append(s[start:end])
i = cur_end_position
position.popleft()
else:
break
if position:
# 最后一条分割结果
result.append(s[position.popleft():length])
else:
result.append(s)
return result
def regex_split_02(s: str, pattern=r'\d{1,2}:\d{2}') -> List:
"""
pattern = r'\d{1,2}:\d{2}'
"""
result = []
i = 0
length = len(s)
position = deque([])
while i < length:
match = re.search(pattern, s[i:])
if not match:
# 此时说明 没有找到要分割的点
break
cur_start_position = match.span()[0] + i
cur_end_position = match.span()[1] + i
position.append(cur_start_position)
if len(position) >= 2:
# collect result
start = position.popleft()
end = position.popleft()
# 这里不能丢掉这个元素,还要再次 从左边添加回来,作为下一次切割的位置开始点
position.appendleft(end)
result.append(s[start:end])
i = cur_end_position
if position:
# 最后一条分割结果
result.append(s[position.popleft():length])
else:
# 没有要分割的点,直接返回原来的一条结果
result.append(s)
return result
def regex_split_03(s: str, pattern=r'\d{1,2}:\d{2}') -> List:
"""
pattern = r'\d{1,2}:\d{2}'
"""
result = []
i = 0
length = len(s)
position = deque([])
while i < length:
match = re.search(pattern, s[i:])
if not match:
# 此时说明 没有找到要分割的点
break
cur_start_position = match.span()[0] + i
cur_end_position = match.span()[1] + i
position.append(cur_start_position)
i = cur_end_position
# found 分割点
if position:
for i in range(1, len(position)):
result.append(s[position[i - 1]:position[i]])
result.append(s[position[len(position) - 1]:length])
else:
result.append(s)
return result
def regex_split(s: str, pattern=r'\d{1,2}:\d{2}') -> List:
"""
pattern = r'\d{1,2}:\d{2}'
"""
result = []
i = 0
length = len(s)
position = deque([])
while i < length:
match = re.search(pattern, s[i:])
if not match:
# 此时说明 没有找到要分割的点
break
cur_start_position = match.span()[0] + i
cur_end_position = match.span()[1] + i
position.append(cur_start_position)
i = cur_end_position
# found 分割点
if position:
begin = position[0]
end = position[-1]
if begin != 0:
position.appendleft(0)
if end != length:
position.append(length)
for i in range(0, len(position) - 1):
result.append(s[position[i]:position[i + 1]])
else:
result.append(s)
return result
class TestSplitStr(unittest.TestCase):
def setUp(self):
self.s = '14:00,中国科技大学,KZB 阶段总结推进会-贺董(周总、沈总)15:00,中国科技大学,公司深改领导小组会(视频)班子成员16:30,中国科技大学,C929供应商选择领导小组会-贺董(周总、张总、沈总、戚总)18:30,中国科技大学,国内大飞机产业链布局方案专题会议-周总(张总、沈总)'
self.expected_result = [
'14:00,中国科技大学,KZB 阶段总结推进会-贺董(周总、沈总)',
'15:00,中国科技大学,公司深改领导小组会(视频)班子成员',
'16:30,中国科技大学,C929供应商选择领导小组会-贺董(周总、张总、沈总、戚总)',
'18:30,中国科技大学,国内大飞机产业链布局方案专题会议-周总(张总、沈总)'
]
def tearDown(self) -> None: # 表示该方法没有返回值
pass
def test_split(self):
real_result = split_str(self.s, pattern=r'\d{1,2}:\d{2}')
self.assertListEqual(real_result, self.expected_result, msg="real != expected result.Test failed...")
pass
def test_split_one_match(self):
data_string = "14:00,中国科技大学,KZB 阶段总结推进会-贺董(周总、沈总)中国科技大学,公司深改领导小组会(视频)班子成员"
expected_result = [
"14:00,中国科技大学,KZB 阶段总结推进会-贺董(周总、沈总)中国科技大学,公司深改领导小组会(视频)班子成员"
]
real_result = split_str(data_string, pattern=r'\d{1,2}:\d{2}')
self.assertListEqual(real_result, expected_result, msg="real != expected result.Test failed...")
pass
@pytest.mark.skip(reason='split_str_not_begin_match 暂时没有实现不是从头开始匹配的情况')
def test_split_not_begin_match(self):
data_string = "阶段总结推进会-贺董(周总、沈总)中国科技大学,公司深改领导小组会(视频)班子成员15:00,中国科技大学,公司深改领导小组会(视频)班子成员"
expected_result = [
"阶段总结推进会-贺董(周总、沈总)中国科技大学,公司深改领导小组会(视频)班子成员",
"15:00,中国科技大学,公司深改领导小组会(视频)班子成员"
]
real_result = split_str(data_string, pattern=r'\d{1,2}:\d{2}')
self.assertListEqual(real_result, expected_result, msg="real != expected result.Test failed...")
pass
def test_split_03_not_match(self):
real_result = regex_split_03(self.s, pattern=r'Frank\d{1,2}:\d{2}')
self.assertListEqual(real_result, [self.s], msg="real != expected result.Test failed...")
pass
def test_regex_split_03(self):
real_result = regex_split_03(self.s, pattern=r'\d{1,2}:\d{2}')
self.assertListEqual(real_result, self.expected_result, msg="real != expected result.Test failed...")
pass
def test_regex_split_03_one_match(self):
data_string = "14:00,中国科技大学,KZB 阶段总结推进会-贺董(周总、沈总)中国科技大学,公司深改领导小组会(视频)班子成员"
expected_result = [
"14:00,中国科技大学,KZB 阶段总结推进会-贺董(周总、沈总)中国科技大学,公司深改领导小组会(视频)班子成员"
]
real_result = regex_split_03(data_string, pattern=r'\d{1,2}:\d{2}')
self.assertListEqual(real_result, expected_result, msg="real != expected result.Test failed...")
pass
def test_regex_split_03_not_match(self):
real_result = regex_split_03(self.s, pattern=r'Frank\d{1,2}:\d{2}')
self.assertListEqual(real_result, [self.s], msg="real != expected result.Test failed...")
pass
@pytest.mark.skip(reason='regex_split_03_not_begin_match 暂时没有实现不是从头开始匹配的情况')
def test_regex_split_03_not_begin_match(self):
data_string = "阶段总结推进会-贺董(周总、沈总)中国科技大学,公司深改领导小组会(视频)班子成员15:00,中国科技大学,公司深改领导小组会(视频)班子成员"
expected_result = [
"阶段总结推进会-贺董(周总、沈总)中国科技大学,公司深改领导小组会(视频)班子成员",
"15:00,中国科技大学,公司深改领导小组会(视频)班子成员"
]
real_result = regex_split_03(data_string, pattern=r'\d{1,2}:\d{2}')
self.assertListEqual(real_result, expected_result, msg="real != expected result.Test failed...")
pass
def test_regex_split(self):
real_result = regex_split(self.s, pattern=r'\d{1,2}:\d{2}')
self.assertListEqual(real_result, self.expected_result, msg="real != expected result.Test failed...")
pass
def test_regex_split_one_match(self):
data_string = "14:00,中国科技大学,KZB 阶段总结推进会-贺董(周总、沈总)中国科技大学,公司深改领导小组会(视频)班子成员"
expected_result = [
"14:00,中国科技大学,KZB 阶段总结推进会-贺董(周总、沈总)中国科技大学,公司深改领导小组会(视频)班子成员"
]
real_result = regex_split(data_string, pattern=r'\d{1,2}:\d{2}')
self.assertListEqual(real_result, expected_result, msg="real != expected result.Test failed...")
pass
def test_regex_split_not_begin_match(self):
data_string = "阶段总结推进会-贺董(周总、沈总)中国科技大学,公司深改领导小组会(视频)班子成员15:00,中国科技大学,公司深改领导小组会(视频)班子成员"
expected_result = [
"阶段总结推进会-贺董(周总、沈总)中国科技大学,公司深改领导小组会(视频)班子成员",
"15:00,中国科技大学,公司深改领导小组会(视频)班子成员"
]
real_result = regex_split(data_string, pattern=r'\d{1,2}:\d{2}')
self.assertListEqual(real_result, expected_result, msg="real != expected result.Test failed...")
pass
def test_regex_split_01(self):
real_result = regex_split_01(self.s, pattern=r'\d{1,2}:\d{2}')
self.assertListEqual(real_result, self.expected_result, msg="real != expected result.Test failed...")
pass
def test_regex_split_01_not_match(self):
real_result = regex_split_01(self.s, pattern=r'Frank\d{1,2}:\d{2}')
self.assertListEqual(real_result, [self.s], msg="real != expected result.Test failed...")
pass
def test_regex_split_01_one_match(self):
data_string = "14:00,中国科技大学,KZB 阶段总结推进会-贺董(周总、沈总)中国科技大学,公司深改领导小组会(视频)班子成员"
expected_result = [
"14:00,中国科技大学,KZB 阶段总结推进会-贺董(周总、沈总)中国科技大学,公司深改领导小组会(视频)班子成员"
]
real_result = regex_split_01(data_string, pattern=r'\d{1,2}:\d{2}')
self.assertListEqual(real_result, expected_result, msg="real != expected result.Test failed...")
pass
@pytest.mark.skip(reason='regex_split_01_not_begin_match 暂时没有实现不是从头开始匹配的情况')
def test_regex_split_01_not_begin_match(self):
data_string = "阶段总结推进会-贺董(周总、沈总)中国科技大学,公司深改领导小组会(视频)班子成员15:00,中国科技大学,公司深改领导小组会(视频)班子成员"
expected_result = [
"阶段总结推进会-贺董(周总、沈总)中国科技大学,公司深改领导小组会(视频)班子成员",
"15:00,中国科技大学,公司深改领导小组会(视频)班子成员"
]
real_result = regex_split_01(data_string, pattern=r'\d{1,2}:\d{2}')
self.assertListEqual(real_result, expected_result, msg="real != expected result.Test failed...")
def test_regex_split_02(self):
real_result = regex_split_02(self.s, pattern=r'\d{1,2}:\d{2}')
self.assertListEqual(real_result, self.expected_result, msg="real != expected result.Test failed...")
pass
def test_regex_split_02_one_match(self):
data_string = "14:00,中国科技大学,KZB 阶段总结推进会-贺董(周总、沈总)中国科技大学,公司深改领导小组会(视频)班子成员"
expected_result = [
"14:00,中国科技大学,KZB 阶段总结推进会-贺董(周总、沈总)中国科技大学,公司深改领导小组会(视频)班子成员"
]
real_result = regex_split_02(data_string, pattern=r'\d{1,2}:\d{2}')
self.assertListEqual(real_result, expected_result, msg="real != expected result.Test failed...")
pass
def test_regex_split_02_not_match(self):
real_result = regex_split_02(self.s, pattern=r'Frank\d{1,2}:\d{2}')
self.assertListEqual(real_result, [self.s], msg="real != expected result.Test failed...")
pass
@pytest.mark.skip(reason='regex_split_02_not_begin_match 暂时没有实现不是从头开始匹配的情况')
def test_regex_split_02_not_begin_match(self):
data_string = "阶段总结推进会-贺董(周总、沈总)中国科技大学,公司深改领导小组会(视频)班子成员15:00,中国科技大学,公司深改领导小组会(视频)班子成员"
expected_result = [
"阶段总结推进会-贺董(周总、沈总)中国科技大学,公司深改领导小组会(视频)班子成员",
"15:00,中国科技大学,公司深改领导小组会(视频)班子成员"
]
real_result = regex_split_02(data_string, pattern=r'\d{1,2}:\d{2}')
self.assertListEqual(real_result, expected_result, msg="real != expected result.Test failed...")
if __name__ == '__main__':
unittest.main()
pass
总结
? 本文总结了一个常见的字符串的处理的问题,如何处理字符串分割, 使用内置的库 re模块 分割 会把 分隔符 弄掉. 基于内置库 无法满足这样的分割, 于是就写了这个文章来进行分割. 通过匹配固定的正则 来实现对字符串的分隔. 文中留了一个小问题, 把方法1到方法4 中 错误的地方, 改正过来, 感兴趣的同学可以评论留言,看到必回.
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 计算机体系结构----缓存一致性/多处理机
- docker安装及入门
- spring boot使用配置文件对静态变量进行赋值
- Jtti:电影服务器的带宽和存储空间怎么选择?
- Redis第1讲——入门简介
- 12V升48V升60升80V升压恒压WT3207
- 2023 年度龙蜥最佳用户案例奖揭晓,中国移动、小红书、中国人寿财险等企业上榜!
- C语言多线程编程-线程终止
- VMware之FTP的简介以及搭建&计算机端口的介绍
- 创酷rs2022车机安装app