LlamaIndex的5种高级RAG方法
LlamaPacks: Building RAG in Fewer Lines of Code.
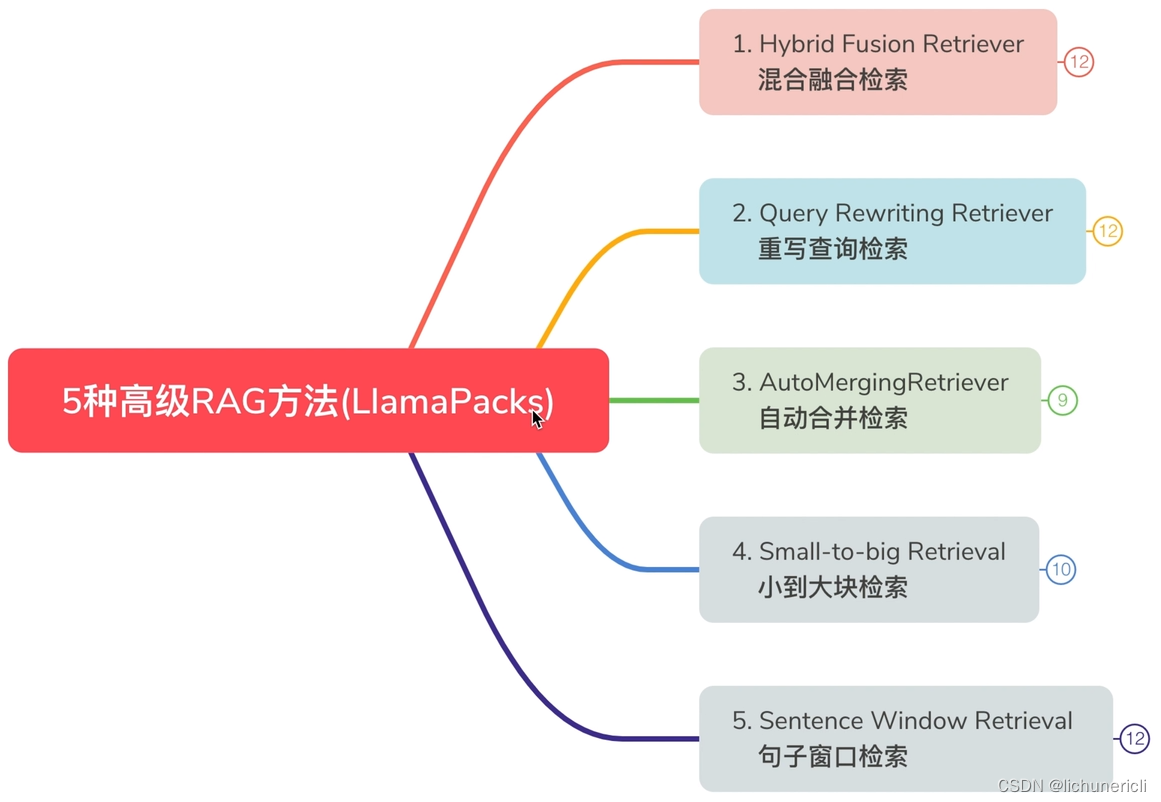
Comparison conducted among the following advanced retrieval with Llamapacks.
-
Baseline: Naive query engine with Llamaindex
-
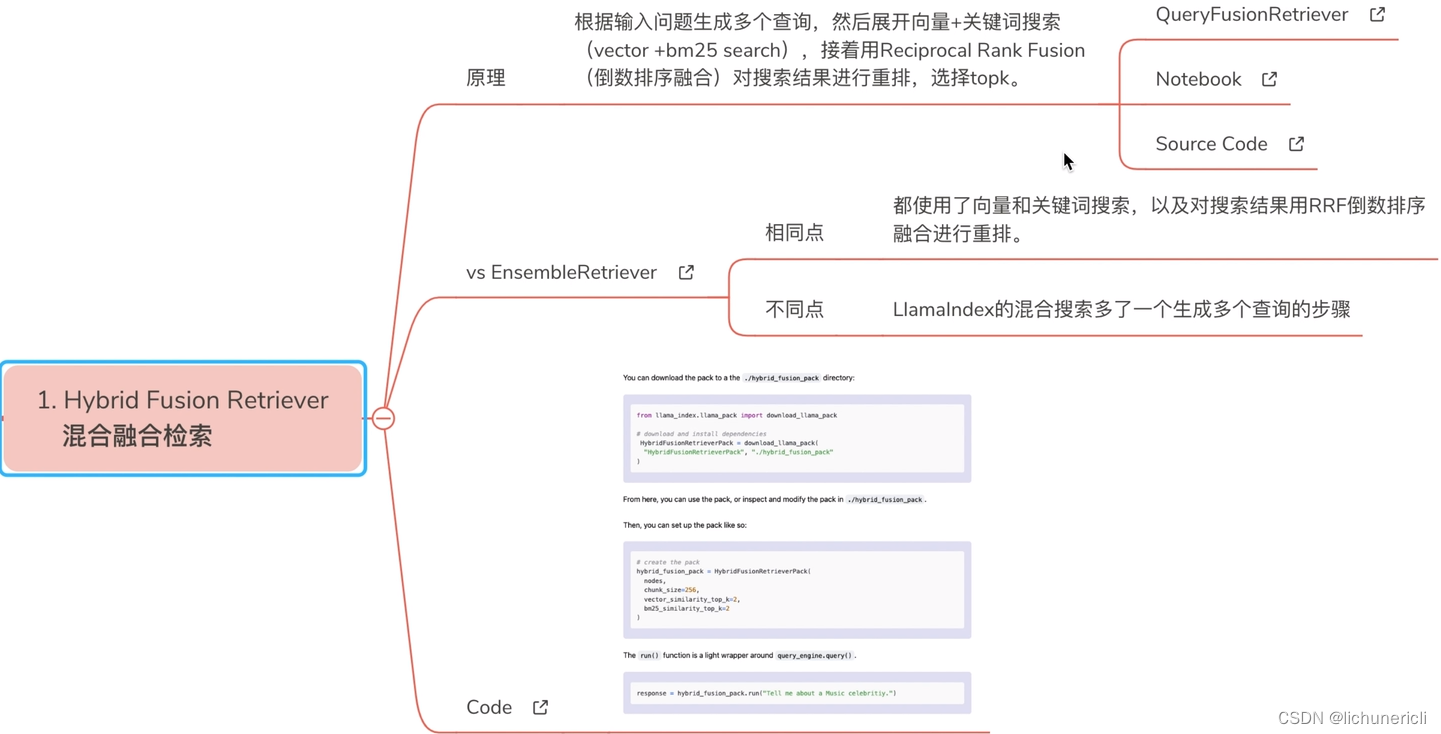
Pack 1: Hybrid Fusion Retriever Pack?[Notebook]?[Source]
Built on top of?QueryFusionRetriever. Generates multiple queries from the input question and then ensembles vector and bm25 retrievers using fusion(vector + keyword search + reciprocal_rerank_fusion)

- Pack 2: Query Rewriting Retriever Pack?[Notebook]?[Source]
Built on top of?QueryFusionRetriever. Rewrite(Generates) multiple queries from the input question, retrieve with vector search and rerank the results with reciprocal_rerank_fusion.


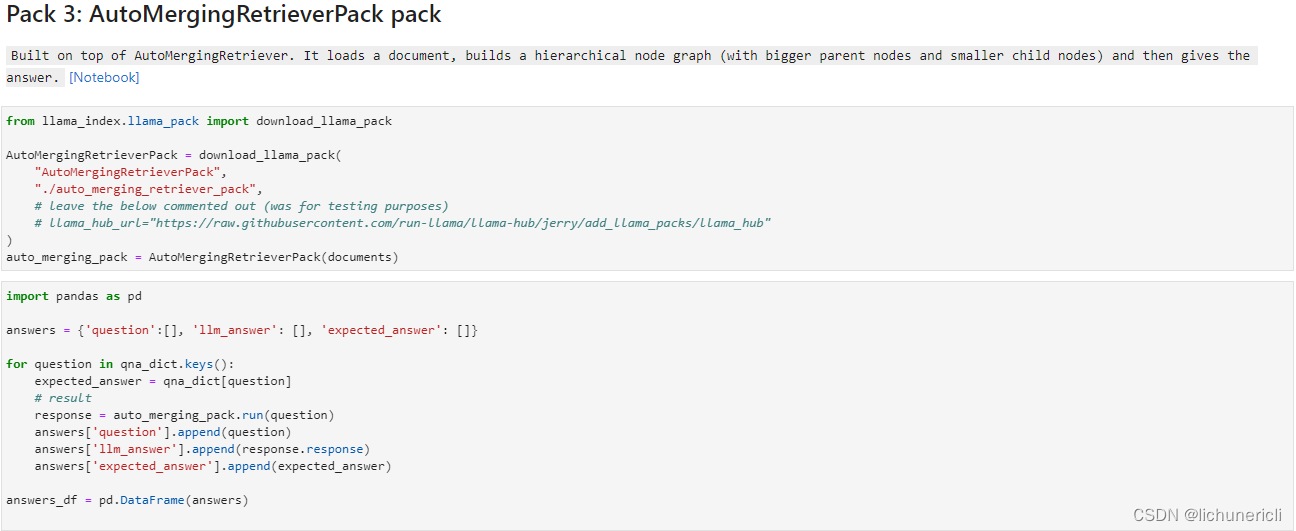
- Pack 3: AutoMergingRetrieverPack pack?[Notebook]?Source
Built on top of?AutoMergingRetriever. It loads a document, builds a hierarchical node graph (with bigger parent nodes and smaller child nodes) and then check if enough children nodes of a parent node have been retrieved and merge and replace with that parent.


- Pack 4: Small-to-big Retrieval Pack?[Notebook]?[Source]
Built on top of?RecursiveRetriever. Given input documents, and an initial set of "parent" chunks, subdivide each chunk further into "child" chunks. Link each child chunk to its parent chunk, and index the child chunks.


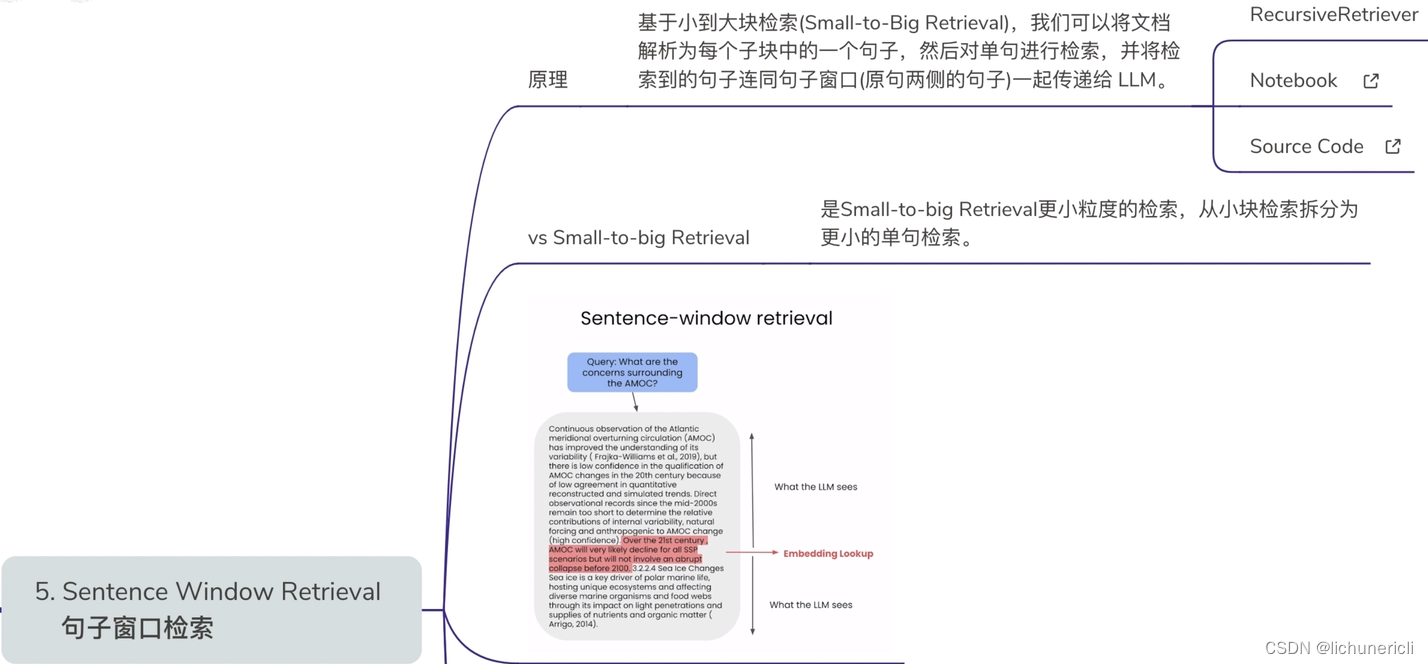
- Pack 5: Sentence Window Retrieval Pack?[Notebook]?[Source]
Built on top of?SentenceWindowNodeParser. It loads a document, split a document into Nodes, with each node being a sentence. Each node contains a window from the surrounding sentences in the metadata.

MODEL = "gpt-3.5-turbo"So, which one will perform best? My answer is: "It depends! Different retrieval tasks and datasets have varying requirements, and there's no one-size-fits-all solution. "
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 微信小程序嵌入H5页面,在H5页面中分享base64的pdf文件给微信好友
- 机器人制作开源方案 | 森林管理员
- Vue框架入门基础知识
- (CVE-2019-9193)PostgreSQL 高权限命令执行漏洞的复现
- Java毕业设计第96期-基于springboot的图书后台管理系统
- 使用Tushare获取股票数据(最新更新版)
- 地图 - 实现有多条定位,显示多条定位,并且使用一个圆形遮罩层将多条定位进行覆盖
- AI国际顶会ICLR 2024结果揭晓,蚂蚁集团11篇论文入选
- day18 二叉树 part05
- 【漏洞复现】锐捷RG-UAC统一上网行为管理系统信息泄露漏洞