UCB Data100:数据科学的原理和技巧:第十三章到第十五章
十三、梯度下降
译者:飞龙
学习成果
-
优化复杂模型
-
识别直接微积分或几何论证无法帮助解决损失函数的情况
-
应用梯度下降进行数值优化
到目前为止,我们已经非常熟悉选择模型和相应损失函数的过程,并通过选择最小化损失函数的 θ \theta θ的值来优化参数。到目前为止,我们已经通过以下两种方法优化了 θ \theta θ:1. 使用微积分对损失函数关于 θ \theta θ的导数进行求导,将其置为 0,并解出 θ \theta θ。2. 使用正交性的几何论证来推导 OLS 解 θ ^ = ( X T X ) ? 1 X T Y \hat{\theta} = (\mathbb{X}^T \mathbb{X})^{-1}\mathbb{X}^T \mathbb{Y} θ^=(XTX)?1XTY。
然而,需要注意的一点是,我们上面使用的技术只有在我们做出一些重大假设时才能应用。对于微积分方法,我们假设损失函数在所有点上都是可微的,并且代数是可管理的;对于几何方法,OLS仅适用于使用 MSE 损失的线性模型。当我们有更复杂的模型和不同的更复杂的损失函数时会发生什么?到目前为止我们学到的技术将不起作用,所以我们需要一种新的优化技术:梯度下降。
重要思想:使用算法而不是求解精确答案
13.1?最小化 1D 函数
让我们考虑一个任意的函数。我们的目标是找到最小化这个函数的 x x x的值。
代码
import pandas as pd
import seaborn as sns
import plotly.express as px
import matplotlib.pyplot as plt
import numpy as np
pd.options.mode.chained_assignment = None # default='warn'
def arbitrary(x):
return (x**4 - 15*x**3 + 80*x**2 - 180*x + 144)/10
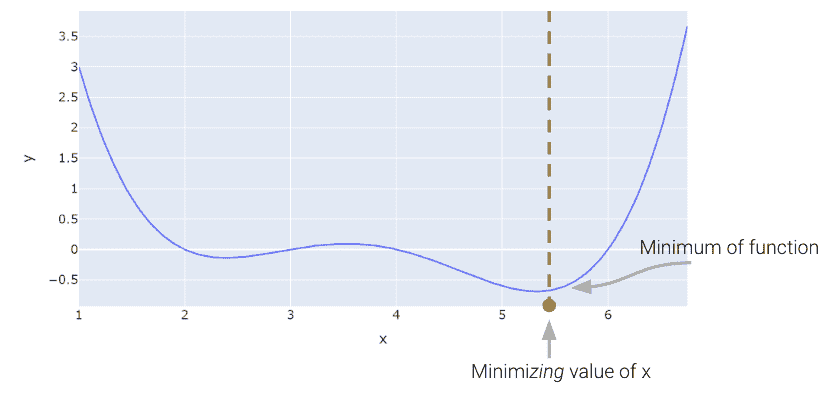
13.1.1?天真的方法:猜测和检查
以上,我们看到最小值大约在 5.3 左右。让我们看看我们是否能够弄清楚如何从头开始算法地找到确切的最小值。一种非常慢(而且糟糕)的方法是手动猜测和检查。
arbitrary(6)
0.0
一个稍微好一点(但仍然很慢)的方法是使用蛮力来尝试一堆 x 值,并返回产生最低损失的值。
def simple_minimize(f, xs):
# Takes in a function f and a set of values xs.
# Calculates the value of the function f at all values x in xs
# Takes the minimum value of f(x) and returns the corresponding value x
y = [f(x) for x in xs]
return xs[np.argmin(y)]
guesses = [5.3, 5.31, 5.32, 5.33, 5.34, 5.35]
simple_minimize(arbitrary, guesses)
5.33
这个过程本质上与我们以前制作图形图表的过程相同,只是我们只看了 20 个选定的点。
代码
xs = np.linspace(1, 7, 200)
sparse_xs = np.linspace(1, 7, 5)
ys = arbitrary(xs)
sparse_ys = arbitrary(sparse_xs)
fig = px.line(x = xs, y = arbitrary(xs))
fig.add_scatter(x = sparse_xs, y = arbitrary(sparse_xs), mode = "markers")
fig.update_layout(showlegend= False)
fig.update_layout(autosize=False, width=800, height=600)
fig.show()
这种基本方法存在三个主要缺陷:1. 如果最小值在我们猜测的范围之外,答案将完全错误。2. 即使我们的猜测范围是正确的,如果猜测太粗糙,我们的答案将不准确。3. 考虑到可能庞大的无用猜测数量,这是绝对计算效率低下的。
13.1.2?Scipy.optimize.minimize
最小化这个数学函数的一种方法是使用scipy.optimize.minimize函数。它接受一个函数和一个起始猜测,并尝试找到最小值。
from scipy.optimize import minimize
# takes a function f and a starting point x0 and returns a readout
# with the optimal input value of x which minimizes f
minimize(arbitrary, x0 = 3.5)
message: Optimization terminated successfully.
success: True
status: 0
fun: -0.13827491292966557
x: [ 2.393e+00]
nit: 3
jac: [ 6.486e-06]
hess_inv: [[ 7.385e-01]]
nfev: 20
njev: 10
scipy.optimize.minimize很棒。它也可能看起来有点神奇。你怎么能写一个函数来找到任何数学函数的最小值呢?有许多方法可以做到这一点,我们将在今天的讲座中探讨这些方法,最终到达scipy.optimize.minimize使用的梯度下降的重要思想。
事实证明,在幕后,LinearRegression模型的fit方法使用了梯度下降。梯度下降也是许多机器学习模型的工作原理,甚至包括先进的神经网络模型。
在 Data 100 中,梯度下降过程通常对我们来说是不可见的,隐藏在抽象层下。然而,作为优秀的数据科学家,我们知道优化函数利用的基本原理是很重要的。
13.2?深入研究梯度下降
在这个域中查看函数,很明显函数的最小值出现在 θ = 5.3 \theta = 5.3 θ=5.3附近。假设一下,我们看不到成本函数的完整视图。我们如何猜测最小化函数的 θ \theta θ值?
原来,函数的一阶导数可以给我们一些线索。在下面的图中,线表示每个 θ \theta θ值的导数值。导数为负值时为红色,为正值时为绿色。
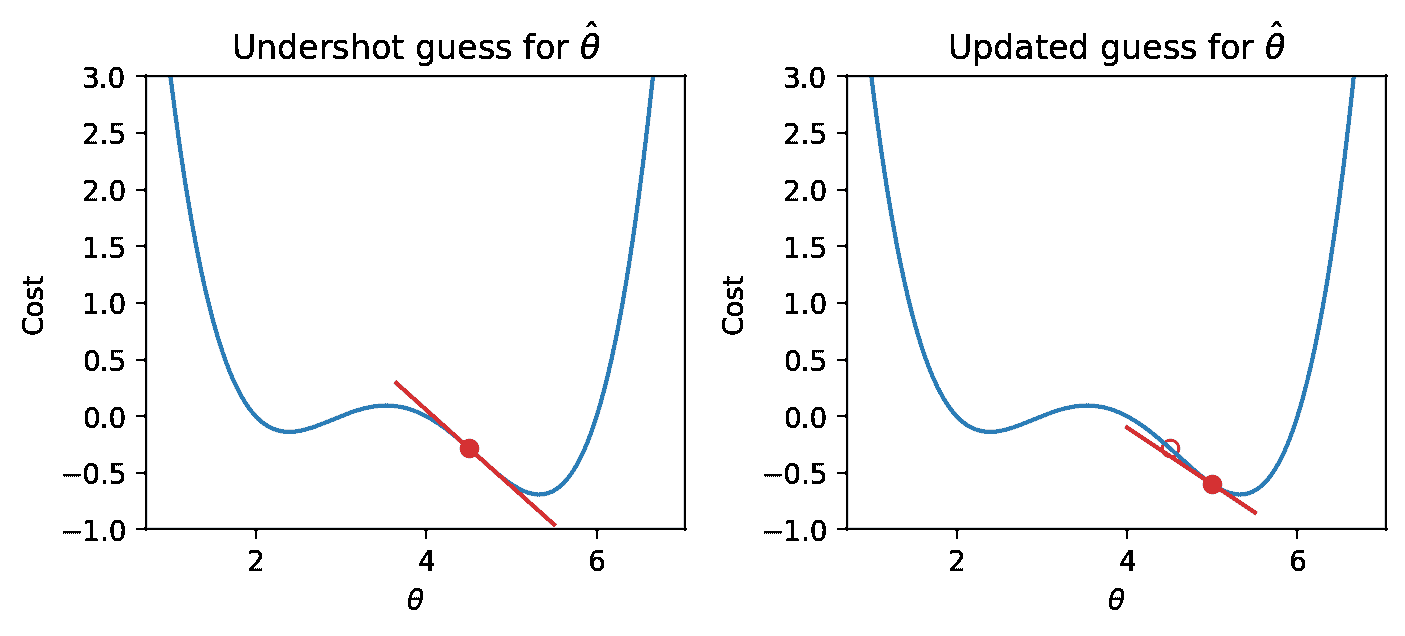
假设我们对最小化 θ \theta θ的值进行了猜测。记住我们从左到右读取图,并假设我们的起始 θ \theta θ值在最佳 θ ^ \hat{\theta} θ^的左边。如果猜测“低估”了真正的最小值 - 我们对最小化函数的 θ ^ \hat{\theta} θ^的猜测低于真正的 θ ^ \hat{\theta} θ^值 - 导数将是负数。这意味着如果我们增加 θ \theta θ(向右移动),那么我们可以进一步减少我们的损失函数。如果这个猜测“高估”了真正的最小值,导数将是正数,暗示着相反。
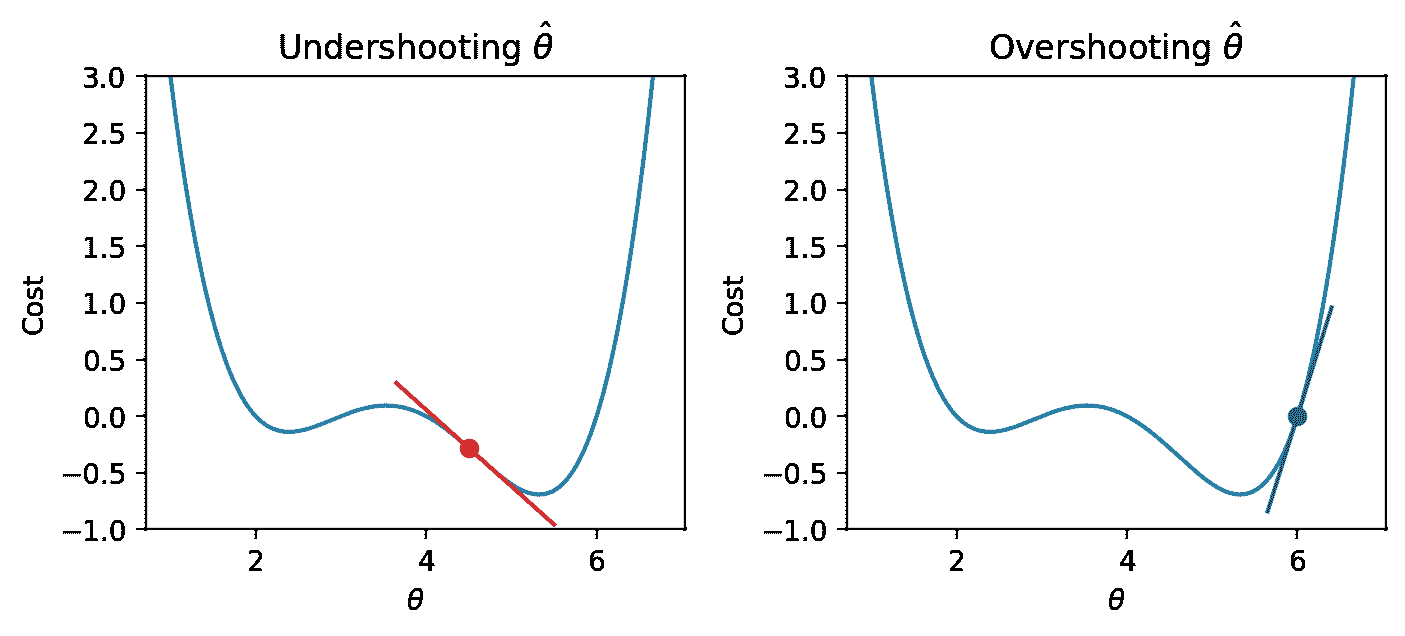
我们可以利用这种模式来帮助制定我们对最佳 θ ^ \hat{\theta} θ^的下一个猜测。考虑一种情况,我们通过猜测一个太低的值而低估了 θ \theta θ。我们希望我们的下一个猜测的值比上一个猜测的值更大 - 也就是说,我们希望将我们的猜测向右移动。你可以把这看作是沿着斜坡“下坡”到函数的最小值。
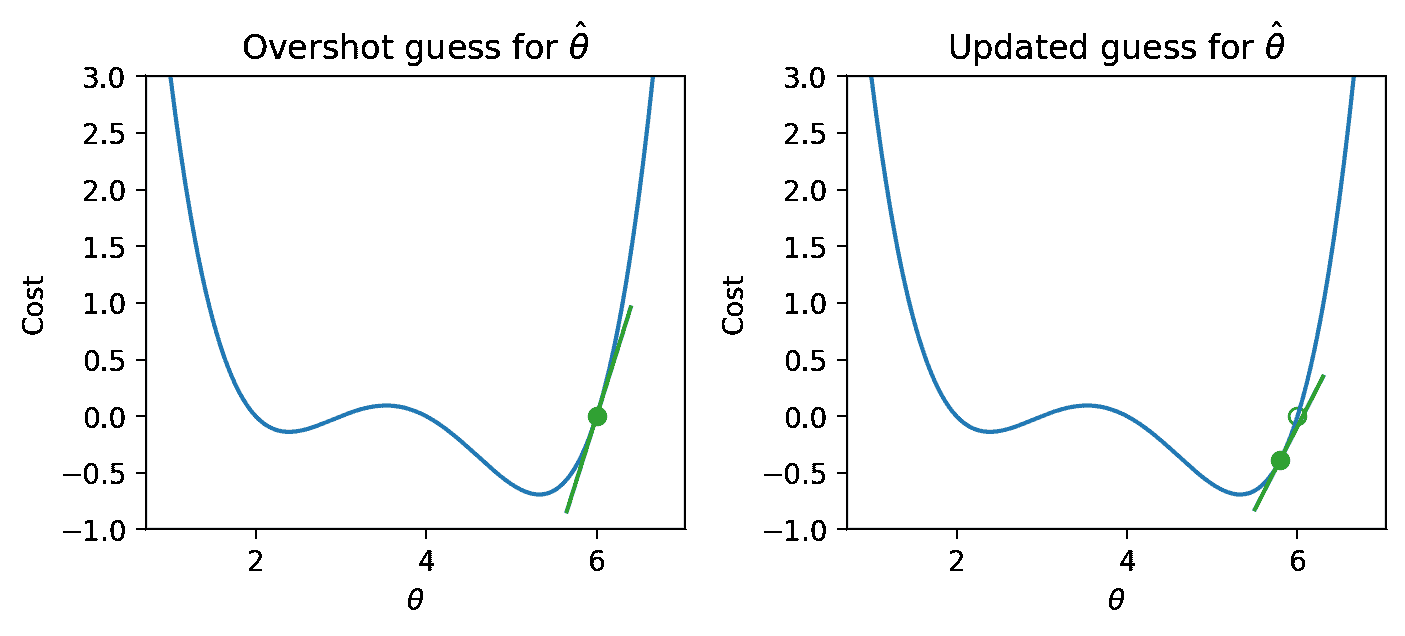
如果我们通过猜测一个太高的值而高估了 θ ^ \hat{\theta} θ^,我们希望我们的下一个猜测的值更低 - 我们希望将 θ ^ \hat{\theta} θ^的猜测向左移动。
换句话说,每个点的函数的导数告诉我们我们下一个猜测的方向。负斜率意味着我们想向右走,或者向正方向移动。正斜率意味着我们想向左走,或者向负方向移动。
13.2.1 算法尝试 1
有了这个知识,让我们试着看看我们是否可以使用导数来优化函数。
我们首先对 x x x的最小值进行一些猜测。然后,我们查看该 x x x值的函数的导数,并向相反方向下坡。我们可以将我们的新规则表示为一个递归关系:
x ( t + 1 ) = x ( t ) ? d d x f ( x ( t ) ) x^{(t+1)} = x^{(t)} - \frac{d}{dx} f(x^{(t)}) x(t+1)=x(t)?dxd?f(x(t))
将这个陈述翻译成英文:我们通过取上一次的猜测( x ( t ) x^{(t)} x(t))并减去该点的函数的导数( d d x f ( x ( t ) ) \frac{d}{dx} f(x^{(t)}) dxd?f(x(t)))来获得我们下一次的猜测,即在时间步长 t + 1 t+1 t+1( x ( t + 1 ) x^{(t+1)} x(t+1))的最小值 x x x。
下面显示了一些步骤,其中旧步骤显示为透明点,下一个步骤是填充为绿色的点。
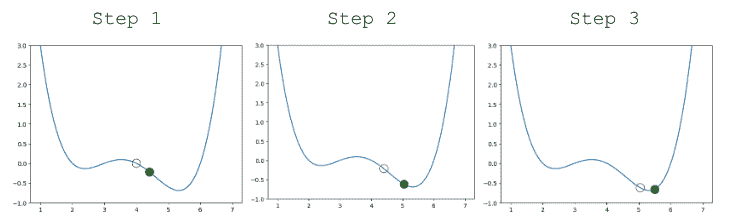
看起来不错!但是我们确实有一个问题 - 一旦我们接近函数的最小值,我们的猜测就会在最小值附近“反弹”而永远无法到达它。
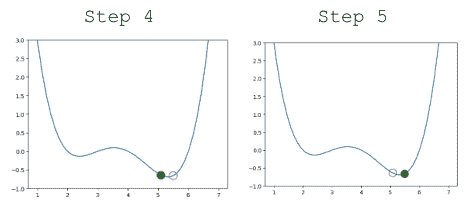
换句话说,每次更新我们的猜测时,我们走得太远了。我们可以通过减小每个步骤的大小来解决这个问题。
13.2.2 算法尝试 2
让我们更新我们的算法以使用学习率(有时也称为步长),它控制我们每次更新的距离。我们用 α \alpha α表示学习率。
x ( t + 1 ) = x ( t ) ? α d d x f ( x ( t ) ) x^{(t+1)} = x^{(t)} - \alpha \frac{d}{dx} f(x^{(t)}) x(t+1)=x(t)?αdxd?f(x(t))
小的 α \alpha α意味着我们会采取小步;大的 α \alpha α意味着我们会采取大步。
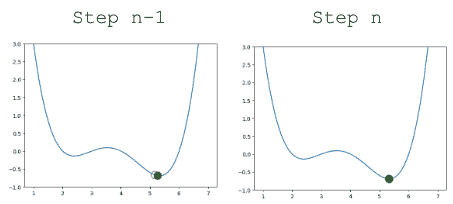
更新我们的函数使用 α = 0.3 \alpha=0.3 α=0.3,我们的算法成功地收敛(在最小值上解决并停止显着更新,或者完全停止)。
13.2.3 凸性
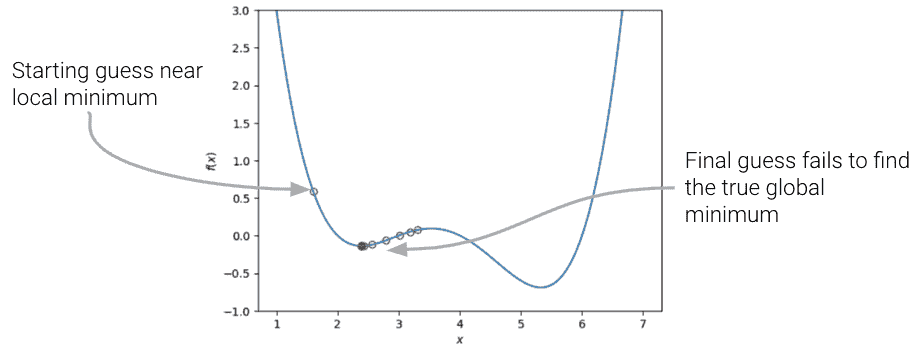
在我们上面的分析中,我们把注意力集中在损失函数的全局最小值上。你可能会想:左边的局部最小值呢?
如果我们选择了不同的 θ \theta θ起始猜测,或者不同的学习率 α \alpha α值,我们的算法可能会“卡住”,收敛到局部最小值,而不是真正的最优损失值。
如果损失函数是凸的,梯度下降保证会收敛并找到目标函数的全局最小值。形式上,如果一个函数 f f f满足: t f ( a ) + ( 1 ? t ) f ( b ) ≥ f ( t a + ( 1 ? t ) b ) tf(a) + (1-t)f(b) \geq f(ta + (1-t)b) tf(a)+(1?t)f(b)≥f(ta+(1?t)b) 对于所有 f f f的定义域中的 a , b a, b a,b和 t ∈ [ 0 , 1 ] t \in [0, 1] t∈[0,1]。
换句话说:如果你在曲线上的任意两点之间画一条线,曲线上的所有值必须在或下于该线。重要的是,凸函数的任何局部最小值也是它的全局最小值。
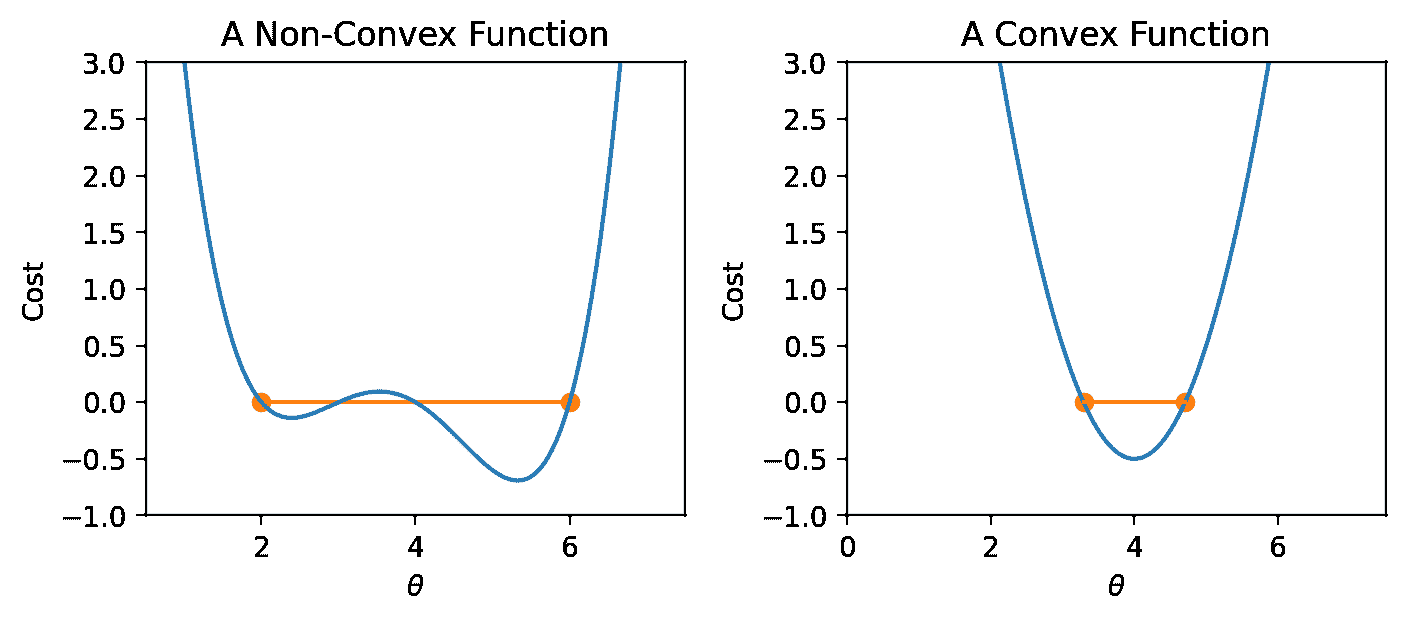
总之,非凸损失函数可能会导致优化问题。这意味着我们选择的损失函数是建模过程中的关键因素。事实证明,MSE 是凸的,这也是它成为如此受欢迎的损失函数的主要原因。
13.3 一维梯度下降
术语澄清:在过去的讲座中,我们使用“损失”来指代单个数据点上发生的错误。在应用中,我们通常更关心所有数据点的平均误差。未来,我们将把“模型的损失”理解为数据集上的模型平均误差。这有时也被称为经验风险、成本函数或目标函数。 L ( θ ) = R ( θ ) = 1 n ∑ i = 1 n L ( y , y ^ ) L(\theta) = R(\theta) = \frac{1}{n} \sum_{i=1}^{n} L(y, \hat{y}) L(θ)=R(θ)=n1?i=1∑n?L(y,y^?)
在上面的讨论中,我们使用了一些任意函数 f f f。作为数据科学家,我们几乎总是在优化模型的情况下使用梯度下降 - 具体来说,我们想要应用梯度下降来找到损失函数的最小值。在建模的情况下,我们的目标是通过选择最小化的模型参数来最小化损失函数。
回顾一下我们过去几节讲座的建模工作流程:* 定义具有一些参数 θ i \theta_i θi?的模型 * 选择一个损失函数 * 选择使数据上的损失函数最小化的 θ i \theta_i θi?的值
梯度下降是完成最后任务的强大技术。通过应用梯度下降算法,我们可以选择参数 θ i \theta_i θi?的值,这将导致模型在训练数据上损失最小。
在建模上下文中使用梯度下降时:* 我们对最小化的 θ i \theta_i θi?进行猜测 * 我们计算损失函数 L L L的导数
我们可以通过用 θ \theta θ替换 x x x和用 L L L替换 f f f来“翻译”我们之前的梯度下降规则:
θ ( t + 1 ) = θ ( t ) ? α d d θ L ( θ ( t ) ) \theta^{(t+1)} = \theta^{(t)} - \alpha \frac{d}{d\theta} L(\theta^{(t)}) θ(t+1)=θ(t)?αdθd?L(θ(t))
13.3.1 在tips数据集上的梯度下降
为了看到这一点,让我们考虑一个没有偏移的线性模型的情况。我们想要预测小费(y)给定一顿饭的价格(x)。为了做到这一点,我们
-
选择一个模型: y ^ = θ 1 x \hat{y} = \theta_1 x y^?=θ1?x,
-
选择一个损失函数: L ( θ ) = M S E ( θ ) = 1 n ∑ i = 1 n ( y i ? θ 1 x i ) 2 L(\theta) = MSE(\theta) = \frac{1}{n} \sum_{i=1}^n (y_i - \theta_1x_i)^2 L(θ)=MSE(θ)=n1?∑i=1n?(yi??θ1?xi?)2。
让我们应用之前的gradient_descent函数来优化我们在tips数据集上的模型。我们将尝试选择最佳参数
θ
i
\theta_i
θi?来预测total_bill
x
x
x的tip
y
y
y。
df = sns.load_dataset("tips")
df.head()
| total_bill | tip | sex | smoker | day | time | size | |
|---|---|---|---|---|---|---|---|
| 0 | 16.99 | 1.01 | Female | No | Sun | Dinner | 2 |
| 1 | 10.34 | 1.66 | Male | No | Sun | Dinner | 3 |
| 2 | 21.01 | 3.50 | Male | No | Sun | Dinner | 3 |
| 3 | 23.68 | 3.31 | Male | No | Sun | Dinner | 2 |
| 4 | 24.59 | 3.61 | Female | No | Sun | Dinner | 4 |
我们可以可视化我们的数据集上 MSE 的值,对于不同可能的 θ 1 \theta_1 θ1?的选择。为了优化我们的模型,我们希望选择导致最低 MSE 的 θ 1 \theta_1 θ1?的值。
代码
import plotly.graph_objects as go
def derivative_arbitrary(x):
return (4*x**3 - 45*x**2 + 160*x - 180)/10
fig = go.Figure()
roots = np.array([2.3927, 3.5309, 5.3263])
fig.add_trace(go.Scatter(x = xs, y = arbitrary(xs),
mode = "lines", name = "f"))
fig.add_trace(go.Scatter(x = xs, y = derivative_arbitrary(xs),
mode = "lines", name = "df", line = {"dash": "dash"}))
fig.add_trace(go.Scatter(x = np.array(roots), y = 0*roots,
mode = "markers", name = "df = zero", marker_size = 12))
fig.update_layout(font_size = 20, yaxis_range=[-1, 3])
fig.update_layout(autosize=False, width=800, height=600)
fig.show()
要应用梯度下降,我们需要计算损失函数对我们的参数 θ 1 \theta_1 θ1?的导数。
-
给定我们的损失函数, L ( θ ) = M S E ( θ ) = 1 n ∑ i = 1 n ( y i ? θ 1 x i ) 2 L(\theta) = MSE(\theta) = \frac{1}{n} \sum_{i=1}^n (y_i - \theta_1x_i)^2 L(θ)=MSE(θ)=n1?i=1∑n?(yi??θ1?xi?)2
-
我们对 θ 1 \theta_1 θ1?进行导数 ? ? θ 1 L ( θ 1 ( t ) ) = ? 2 n ∑ i = 1 n ( y i ? θ 1 ( t ) x i ) x i \frac{\partial}{\partial \theta_{1}} L(\theta_1^{(t)}) = \frac{-2}{n} \sum_{i=1}^n (y_i - \theta_1^{(t)} x_i) x_i ?θ1???L(θ1(t)?)=n?2?i=1∑n?(yi??θ1(t)?xi?)xi?
-
这导致梯度下降更新规则 θ 1 ( t + 1 ) = θ 1 ( t ) ? α d d θ L ( θ 1 ( t ) ) \theta_1^{(t+1)} = \theta_1^{(t)} - \alpha \frac{d}{d\theta}L(\theta_1^{(t)}) θ1(t+1)?=θ1(t)??αdθd?L(θ1(t)?)
对于一些学习率 α \alpha α。
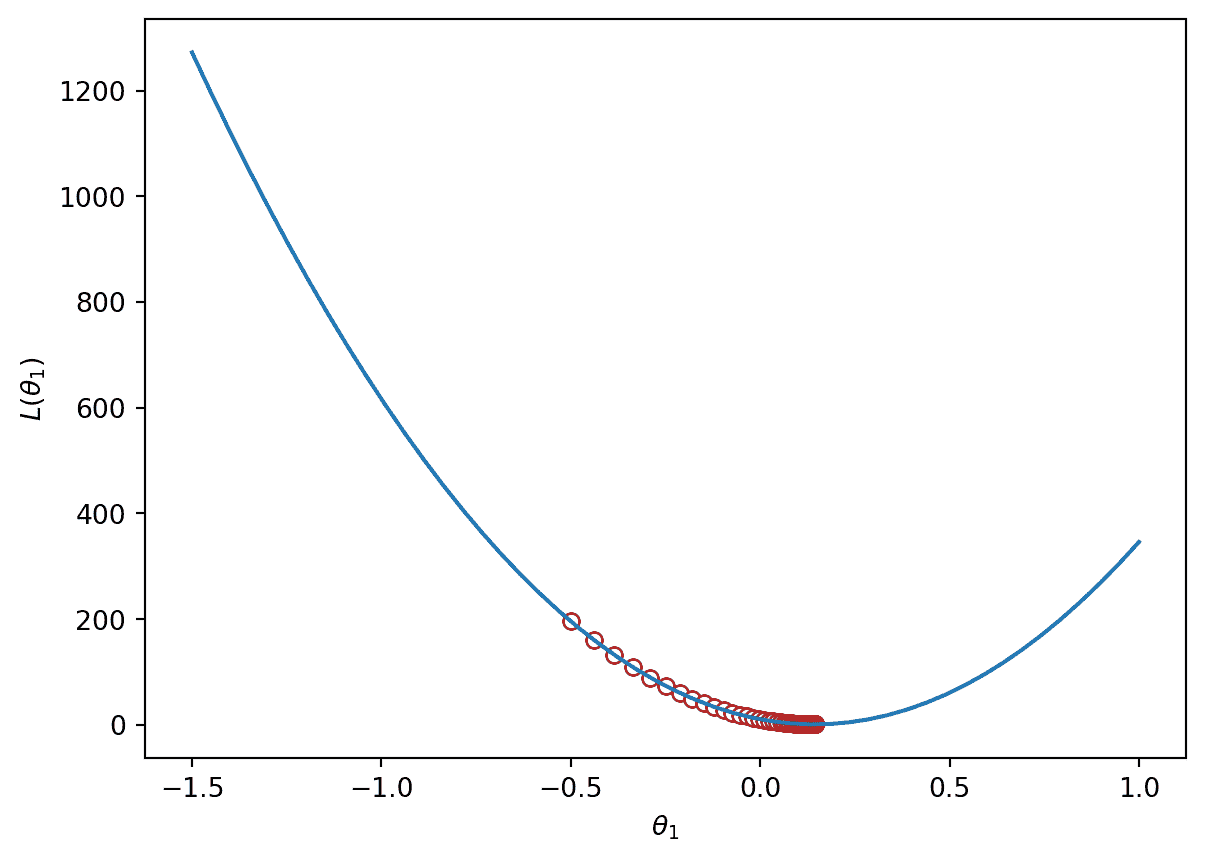
在代码中实现这一点,我们可以可视化tips数据上的 MSE 损失。MSE 是凸的,因此有一个全局最小值。
代码
def gradient_descent(df, initial_guess, alpha, n):
"""Performs n steps of gradient descent on df using learning rate alpha starting
from initial_guess. Returns a numpy array of all guesses over time."""
guesses = [initial_guess]
current_guess = initial_guess
while len(guesses) < n:
current_guess = current_guess - alpha * df(current_guess)
guesses.append(current_guess)
return np.array(guesses)
def mse_single_arg(theta_1):
"""Returns the MSE on our data for the given theta1"""
x = df["total_bill"]
y_obs = df["tip"]
y_hat = theta_1 * x
return np.mean((y_hat - y_obs) ** 2)
def mse_loss_derivative_single_arg(theta_1):
"""Returns the derivative of the MSE on our data for the given theta1"""
x = df["total_bill"]
y_obs = df["tip"]
y_hat = theta_1 * x
return np.mean(2 * (y_hat - y_obs) * x)
loss_df = pd.DataFrame({"theta_1":np.linspace(-1.5, 1), "MSE":[mse_single_arg(theta_1) for theta_1 in np.linspace(-1.5, 1)]})
trajectory = gradient_descent(mse_loss_derivative_single_arg, -0.5, 0.0001, 100)
plt.plot(loss_df["theta_1"], loss_df["MSE"])
plt.scatter(trajectory, [mse_single_arg(guess) for guess in trajectory], c="white", edgecolor="firebrick")
plt.scatter(trajectory[-1], mse_single_arg(trajectory[-1]), c="firebrick")
plt.xlabel(r"$\theta_1$")
plt.ylabel(r"$L(\theta_1)$");
print(f"Final guess for theta_1: {trajectory[-1]}")
Final guess for theta_1: 0.14369554654231262
13.4 多维模型的梯度下降
我们上面使用的函数是一维的 - 我们只是在最小化函数相对于单个参数 θ \theta θ。然而,模型通常具有需要优化的多个参数的成本函数。例如,简单线性回归有 2 个参数: y ^ + θ 0 + θ 1 x \hat{y} + \theta_0 + \theta_1x y^?+θ0?+θ1?x,多元线性回归有 p + 1 p+1 p+1个参数: Y = θ 0 + θ 1 X : , 1 + θ 2 X : , 2 + ? + θ p X : , p \mathbb{Y} = \theta_0 + \theta_1 \Bbb{X}_{:,1} + \theta_2 \Bbb{X}_{:,2} + \cdots + \theta_p \Bbb{X}_{:,p} Y=θ0?+θ1?X:,1?+θ2?X:,2?+?+θp?X:,p?
我们需要扩展梯度下降,这样我们就可以一次性更新所有模型参数的猜测。
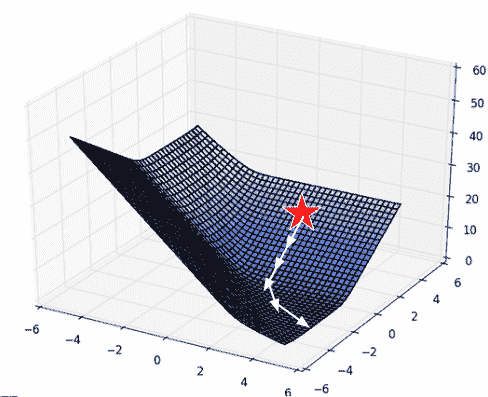
有多个参数要优化时,我们考虑损失表面,或者模型对一组可能的参数值的损失。
代码
import plotly.graph_objects as go
def mse_loss(theta, X, y_obs):
y_hat = X @ theta
return np.mean((y_hat - y_obs) ** 2)
tips_with_bias = df.copy()
tips_with_bias["bias"] = 1
tips_with_bias = tips_with_bias[["bias", "total_bill"]]
uvalues = np.linspace(0, 2, 10)
vvalues = np.linspace(-0.1, 0.35, 10)
(u,v) = np.meshgrid(uvalues, vvalues)
thetas = np.vstack((u.flatten(),v.flatten()))
def mse_loss_single_arg(theta):
return mse_loss(theta, tips_with_bias, df["tip"])
MSE = np.array([mse_loss_single_arg(t) for t in thetas.T])
loss_surface = go.Surface(x=u, y=v, z=np.reshape(MSE, u.shape))
ind = np.argmin(MSE)
optimal_point = go.Scatter3d(name = "Optimal Point",
x = [thetas.T[ind,0]], y = [thetas.T[ind,1]],
z = [MSE[ind]],
marker=dict(size=10, color="red"))
fig = go.Figure(data=[loss_surface, optimal_point])
fig.update_layout(scene = dict(
xaxis_title = "theta0",
yaxis_title = "theta1",
zaxis_title = "MSE"), autosize=False, width=800, height=600)
fig.show()
我们还可以使用等高线图从上方可视化损失表面的鸟瞰图:
contour = go.Contour(x=u[0], y=v[:, 0], z=np.reshape(MSE, u.shape))
fig = go.Figure(contour)
fig.update_layout(
xaxis_title = "theta0",
yaxis_title = "theta1", autosize=False, width=800, height=600)
fig.show()
13.4.1 梯度向量
与以前一样,损失函数的导数告诉我们通往最小值的最佳方式。
在 2D(或更高维度)的表面上,向下(梯度)的最佳方式由向量描述。
数学旁注:偏导数 - 对于具有多个变量的方程,我们通过分别针对一个变量进行微分来进行偏导数。偏导数用 ? \partial ?表示。直观地,我们想要看到函数在只改变一个变量的情况下如何变化,同时保持其他变量不变。- 以 f ( x , y ) = 3 x 2 + y f(x, y) = 3x^2 + y f(x,y)=3x2+y为例,- 对 x 进行偏导数并将 y 视为常数,得到 ? f ? x = 6 x \frac{\partial f}{\partial x} = 6x ?x?f?=6x - 对 y 进行偏导数并将 x 视为常数,得到 ? f ? y = 1 \frac{\partial f}{\partial y} = 1 ?y?f?=1
对于参数值的向量 θ ? = [ θ 0 θ 1 ] \vec{\theta} = \begin{bmatrix} \theta_{0} \\ \theta_{1} \\ \end{bmatrix} θ=[θ0?θ1??],我们对每个参数的损失进行偏导数: ? L ? θ 0 \frac{\partial L}{\partial \theta_0} ?θ0??L?和 ? L ? θ 1 \frac{\partial L}{\partial \theta_1} ?θ1??L?。
梯度向量因此为 ? θ L = [ ? L ? θ 0 ? L ? θ 1 ? ] \nabla_\theta L = \begin{bmatrix} \frac{\partial L}{\partial \theta_0} \\ \frac{\partial L}{\partial \theta_1} \\ \vdots \end{bmatrix} ?θ?L= ??θ0??L??θ1??L??? ?其中 ? θ L \nabla_\theta L ?θ?L始终指向表面的下坡方向。
我们可以使用这个来更新我们的具有多个参数的 1D 梯度规则的模型。
-
回想一下我们的 1D 更新规则: θ ( t + 1 ) = θ ( t ) ? α d d θ L ( θ ( t ) ) \theta^{(t+1)} = \theta^{(t)} - \alpha \frac{d}{d\theta}L(\theta^{(t)}) θ(t+1)=θ(t)?αdθd?L(θ(t))
-
对于具有多个参数的模型,我们使用向量来工作: [ θ 0 ( t + 1 ) θ 1 ( t + 1 ) ? ] = [ θ 0 ( t ) θ 1 ( t ) ? ] ? α [ ? L ? θ 0 ? L ? θ 1 ? ] \begin{bmatrix} \theta_{0}^{(t+1)} \\ \theta_{1}^{(t+1)} \\ \vdots \end{bmatrix} = \begin{bmatrix} \theta_{0}^{(t)} \\ \theta_{1}^{(t)} \\ \vdots \end{bmatrix} - \alpha \begin{bmatrix} \frac{\partial L}{\partial \theta_{0}} \\ \frac{\partial L}{\partial \theta_{1}} \\ \vdots \\ \end{bmatrix} ?θ0(t+1)?θ1(t+1)??? ?= ?θ0(t)?θ1(t)??? ??α ??θ0??L??θ1??L??? ?
-
更紧凑地写成, θ ? ( t + 1 ) = θ ? ( t ) ? α ? θ ? L ( θ ( t ) ) \vec{\theta}^{(t+1)} = \vec{\theta}^{(t)} - \alpha \nabla_{\vec{\theta}} L(\theta^{(t)}) θ(t+1)=θ(t)?α?θ?L(θ(t))
-
θ \theta θ 是我们模型权重的向量
-
L L L 是损失函数
-
α \alpha α 是学习率(我们的是恒定的,但其他技术使用随时间减小的 α \alpha α)
-
θ ? ( t ) \vec{\theta}^{(t)} θ(t) 是 θ \theta θ 的当前值
-
θ ? ( t + 1 ) \vec{\theta}^{(t+1)} θ(t+1) 是 θ \theta θ 的下一个值
-
? θ ? L ( θ ( t ) ) \nabla_{\vec{\theta}} L(\theta^{(t)}) ?θ?L(θ(t)) 是在当前 θ ? ( t ) \vec{\theta}^{(t)} θ(t) 处评估的损失函数的梯度
-
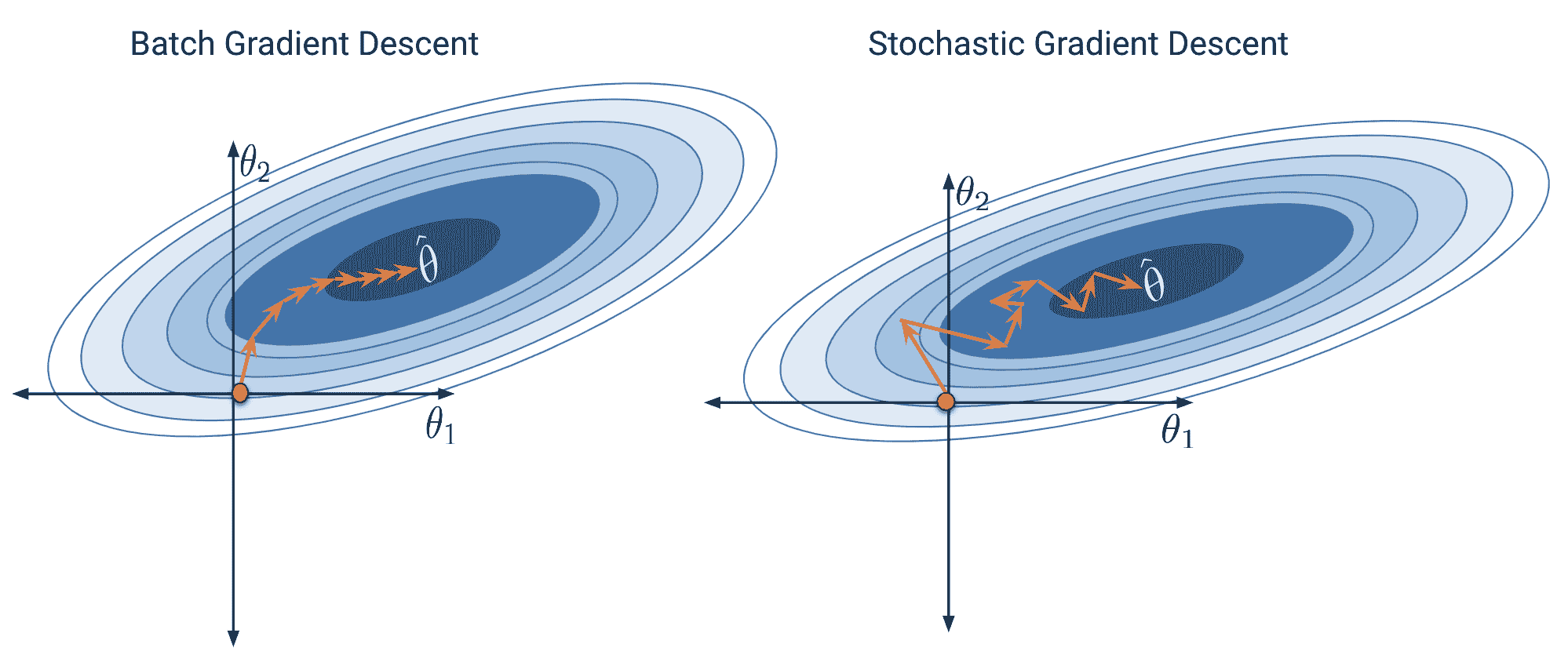
13.5 批量、小批量梯度下降和随机梯度下降
形式上,我们上面推导的算法称为批量梯度下降。对于算法的每次迭代,计算整个包含所有 n n n 个数据点的批次的损失的导数。虽然这个更新规则在理论上效果很好,但在大多数情况下并不实用。对于大型数据集(可能有数十亿个数据点),在所有数据上找到梯度是非常耗费计算资源的;梯度下降会收敛缓慢,因为每次单独的更新都很慢。
小批量梯度下降试图解决这个问题。在小批量下降中,只使用子集数据来估计梯度。批量大小是每个子集中使用的数据点数。
每次完整“通过”数据称为训练周期。在小批量梯度下降的单个训练周期中,我们
-
计算第一个 x% 的数据的梯度。更新参数猜测。
-
计算下一个 x% 的数据的梯度。更新参数猜测。
-
(省略)
-
计算最后 x% 的数据的梯度。更新参数猜测。
每个数据点在单个训练周期中只出现一次。然后我们进行多个训练周期,直到满意为止。
在最极端的情况下,我们可能选择只有 1 个数据点的批量大小——也就是说,每次更新步骤中只使用一个数据点来估计损失的梯度。这被称为随机梯度下降。在随机梯度下降的单个训练周期中,我们
-
计算第一个数据点的梯度。更新参数猜测。
-
计算下一个数据点的梯度。更新参数猜测。
-
(省略)
-
计算最后一个数据点的梯度。更新参数猜测。
批量梯度下降是一种确定性技术——因为在每次更新迭代中都使用整个数据集,算法总是朝着损失曲面的最小值前进。相比之下,小批量和随机梯度下降都涉及一定的随机性。由于每次迭代更新参数 θ ? \vec{\theta} θ 时只使用完整数据的子集,算法有可能不会在每次更新中朝着真正的损失最小值前进。从长远来看,这些随机技术仍然应该收敛到最优解。
下面的图表代表了从上方俯视的损失曲面。注意批量梯度下降直接朝向最优的 θ ^ \hat{\theta} θ^。相比之下,随机梯度下降在损失曲面上“跳跃”。这反映了每次更新步骤中抽样过程的随机性。
十四、Sklearn 和特征工程
原文:Sklearn and Feature Engineering
译者:飞龙
学习成果
-
应用
sklearn库进行模型创建和训练 -
认识到特征工程作为提高模型性能的工具的价值
-
实现多项式特征生成和独热编码
-
了解模型复杂性、模型方差和训练误差之间的相互作用
到目前为止,我们已经对建模过程非常熟悉。我们介绍了损失的概念,用它来拟合多种类型的模型,并且最近扩展了我们的分析到多元回归。在这个过程中,我们通过推导出最佳模型参数的数学细节,艰难地走过了一段路。现在是时候让我们的生活变得更轻松一些了-让我们在代码中实现建模过程!
在本讲座中,我们将探讨两种模型拟合技术:
-
将我们推导出的回归公式翻译成
python -
使用
python的sklearn包
有了我们手头的新编程框架,我们还将通过引入更复杂的特征来增强模型性能,为我们的模型增加复杂性。
14.1 在代码中实现推导出的公式
在本讲座中,我们将引用penguins数据集。
import pandas as pd
import seaborn as sns
import numpy as np
penguins = sns.load_dataset("penguins")
penguins = penguins[penguins["species"] == "Adelie"].dropna()
penguins.head()
| species | island | bill_length_mm | bill_depth_mm | flipper_length_mm | body_mass_g | sex | |
|---|---|---|---|---|---|---|---|
| 0 | Adelie | Torgersen | 39.1 | 18.7 | 181.0 | 3750.0 | Male |
| 1 | Adelie | Torgersen | 39.5 | 17.4 | 186.0 | 3800.0 | Female |
| 2 | Adelie | Torgersen | 40.3 | 18.0 | 195.0 | 3250.0 | Female |
| 4 | Adelie | Torgersen | 36.7 | 19.3 | 193.0 | 3450.0 | Female |
| 5 | Adelie | Torgersen | 39.3 | 20.6 | 190.0 | 3650.0 | Male |
我们的目标是预测给定企鹅的“flipper_length_mm”和“body_mass_g”时,“bill_depth_mm”的值。我们还将添加一个全为 1 的偏置列来表示我们模型的截距项。
# Add a bias column of all ones to `penguins`
penguins["bias"] = np.ones(len(penguins), dtype=int)
# Define the design matrix, X...
X = penguins[["bias", "flipper_length_mm", "body_mass_g"]].to_numpy()
# ...as well as the target variable, y
Y = penguins[["bill_depth_mm"]].to_numpy()
# Converting X and Y to NumPy arrays avoids misinterpretation of column labels
在普通最小二乘法的讲座中,我们使用矩阵表示法表示多元线性回归。
Y ^ = X θ \hat{\mathbb{Y}} = \mathbb{X}\theta Y^=Xθ
我们使用了几何方法来推导出最佳模型参数的以下表达式:
θ ^ = ( X T X ) ? 1 X T Y \hat{\theta} = (\mathbb{X}^T \mathbb{X})^{-1}\mathbb{X}^T \mathbb{Y} θ^=(XTX)?1XTY
这是大量的矩阵操作。我们如何在python中实现它呢?
这里有三个操作我们需要执行:矩阵相乘、求转置和求逆。
-
要进行矩阵乘法,使用
@运算符 -
要进行转置,调用
NumPy数组或DataFrame的.T属性 -
要计算逆矩阵,使用
NumPy的内置方法np.linalg.inv
将这一切放在一起,我们可以计算存储在数组theta_hat中的最佳模型参数的 OLS 估计值。
theta_hat = np.linalg.inv(X.T @ X) @ X.T @ Y
theta_hat
array([[1.10029953e+01],
[9.82848689e-03],
[1.47749591e-03]])
要使用我们优化的参数值进行预测,我们将设计矩阵与参数向量进行矩阵乘法:
Y ^ = X θ \hat{\mathbb{Y}} = \mathbb{X}\theta Y^=Xθ
Y_hat = X @ theta_hat
pd.DataFrame(Y_hat).head()
| 0 | |
|---|---|
| 0 | 18.322561 |
| 1 | 18.445578 |
| 2 | 17.721412 |
| 3 | 17.997254 |
| 4 | 18.263268 |
14.2 sklearn
通过将我们推导出的公式转化为代码,我们已经节省了大量时间(并避免了繁琐的计算)。但是,我们仍然需要自己编写线性代数的过程。
为了让生活变得更加轻松,我们可以转向sklearnpython库。sklearn是一个强大的机器学习工具库,在研究和工业中被广泛使用。它为我们提供了各种内置的建模框架和方法,因此在我们进行 Data 100 的过程中,我们将不断返回sklearn技术。
无论实现的具体模型类型是什么,sklearn都遵循一套标准的创建模型步骤。
-
创建一个模型对象。这将生成模型类的一个新实例。你可以把它看作是对模型的标准“模板”进行新的“复制”。在代码中,这看起来像:
my_model = ModelClass() -
将模型拟合到
X设计矩阵和Y目标向量。这将在不需要显式进行计算的情况下“在后台”计算出最佳的模型参数。然后,拟合的参数将存储在模型中以备将来进行预测使用:my_model.fit(X, Y) -
使用拟合的模型对
X输入数据进行预测,使用.predict。my_model.predict(X)
要提取拟合的参数,我们可以使用:
my_model.coef_
my_model.intercept_
让我们在多元回归任务中将其付诸实践。
1. 初始化模型类的一个实例
sklearn存储了用于机器学习的有用模型的“模板”。我们通过制作一个这些模板的“副本”来开始建模过程以供我们自己使用。模型初始化看起来像ModelClass(),其中ModelClass是我们希望创建的模型类型。
现在,让我们使用LinearRegression()创建一个线性回归模型。
my_model现在是LinearRegression类的一个实例。你可以把它看作是线性回归模型的“想法”。我们还没有对它进行训练,所以它不知道任何模型参数,也不能用来进行预测。事实上,我们甚至还没有告诉它要用什么数据进行建模!它只是等待进一步的指示。
import sklearn.linear_model as lm
my_model = lm.LinearRegression()
2. 使用.fit训练模型
在模型可以进行预测之前,我们需要将其拟合到我们的训练数据中。当我们拟合模型时,sklearn将在后台运行梯度下降来确定最佳的模型参数。然后它会将这些模型参数保存到我们的模型实例中以备将来使用。
所有sklearn模型类都包括一个.fit方法,用于拟合模型。它接受两个输入:设计矩阵X和目标变量Y。
让我们从只有一个特征的模型开始:脚蹼长度。我们通过从DataFrame中提取"flipper_length_mm"列来创建一个设计矩阵X。
# .fit expects a 2D data design matrix, so we use double brackets to extract a DataFrame
X = penguins[["flipper_length_mm"]]
Y = penguins["bill_depth_mm"]
my_model.fit(X, Y)
LinearRegression()
**在 Jupyter 环境中,请重新运行此单元格以显示 HTML 表示或信任笔记本。
在 GitHub 上,HTML 表示无法呈现,请尝试使用 nbviewer.org 加载此页面。**
LinearRegression()
请注意,我们使用双括号来提取这一列。为什么使用双括号而不是单括号?.fit方法默认期望接收二维数据 - 一种包含行和列的数据。写penguins["flipper_length_mm"]会返回一个 1DSeries,导致sklearn出错。我们通过写penguins[["flipper_length_mm"]]来产生一个 2DDataFrame来避免这种情况。
我们的模型只用了三行代码就运行了梯度下降来确定最佳的模型参数!我们的单特征模型采用以下形式:
bill?depth = θ 0 + θ 1 flipper?length \text{bill depth} = \theta_0 + \theta_1 \text{flipper length} bill?depth=θ0?+θ1?flipper?length
请注意,LinearRegression将自动包括一个截距项。
拟合的模型参数被存储为模型实例的属性。my_model.intercept_将返回
θ
^
0
\hat{\theta}_0
θ^0?的值作为标量。my_model.coef_将以数组的形式返回所有值
θ
^
1
,
θ
^
1
,
.
.
.
\hat{\theta}_1, \hat{\theta}_1, ...
θ^1?,θ^1?,...。因为我们的模型只包含一个特征,所以下面的单元格中只会看到
θ
^
1
\hat{\theta}_1
θ^1?的值。
# The intercept term, theta_0
my_model.intercept_
7.297305899612306
# All parameters theta_1, ..., theta_p
my_model.coef_
array([0.05812622])
3. 使用拟合的模型进行预测
现在模型已经训练好了,我们可以用它进行预测!为此,我们使用.predict方法。.predict接受一个参数:应该用来生成预测的设计矩阵。为了了解模型在训练集上的表现,我们会传入训练数据。或者,为了对未见过的数据进行预测,我们会传入一个未用于训练模型的新数据集。
在下面,我们调用.predict来在原始训练数据上生成模型预测。与之前一样,我们使用双括号来确保我们提取的是二维数据。
Y_hat_one_feature = my_model.predict(penguins[["flipper_length_mm"]])
print(f"The RMSE of the model is {np.sqrt(np.mean((Y-Y_hat_one_feature)**2))}")
The RMSE of the model is 1.1549363099239012
如果我们想要一个具有两个特征的模型呢?
bill?depth = θ 0 + θ 1 flipper?length + θ 2 body?mass \text{bill depth} = \theta_0 + \theta_1 \text{flipper length} + \theta_2 \text{body mass} bill?depth=θ0?+θ1?flipper?length+θ2?body?mass
我们通过初始化一个新的模型对象,然后像以前一样调用.fit和.predict来重复这个三步过程。
# Step 1: initialize LinearRegression model
two_feature_model = lm.LinearRegression()
# Step 2: fit the model
X_two_features = penguins[["flipper_length_mm", "body_mass_g"]]
Y = penguins["bill_depth_mm"]
two_feature_model.fit(X_two_features, Y)
# Step 3: make predictions
Y_hat_two_features = two_feature_model.predict(X_two_features)
print(f"The RMSE of the model is {np.sqrt(np.mean((Y-Y_hat_two_features)**2))}")
The RMSE of the model is 0.9881331104079044
我们还可以看到,我们使用sklearn得到的预测与之前应用普通最小二乘公式时得到的预测相同!
代码
pd.DataFrame({"Y_hat from OLS":np.squeeze(Y_hat), "Y_hat from sklearn":Y_hat_two_features}).head()
| Y_hat from OLS | Y_hat from sklearn | |
|---|---|---|
| 0 | 18.322561 | 18.322561 |
| 1 | 18.445578 | 18.445578 |
| 2 | 17.721412 | 17.721412 |
| 3 | 17.997254 | 17.997254 |
| 4 | 18.263268 | 18.263268 |
14.3 特征工程
在课程的这一阶段,我们已经掌握了一些强大的技术来构建和优化模型。我们已经探讨了如何开发多变量模型,以及如何转换变量以帮助线性化数据集,并拟合这些模型以最大化它们的性能。
所有这些都是在一个主要的警告下完成的:到目前为止,我们所使用的回归模型都是输入变量的线性。我们假设我们的预测应该是一些线性变量的组合。虽然在某些情况下这很有效,但现实世界并不总是那么简单。我们将学习一种重要的方法来解决这个问题 - 特征工程 - 并考虑在这样做时可能出现的一些新问题。
特征工程是将原始特征转换为更具信息性的特征的过程,这些特征可以用于建模或 EDA 任务,并提高模型性能。
特征工程允许您:
-
捕获领域知识
-
使用线性模型表达非线性关系
-
在模型中使用非数值特征
14.4 特征函数
特征函数描述了我们对数据集中的原始特征应用的转换,以创建一个转换特征的设计矩阵。我们通常将特征函数表示为 Φ \Phi Φ(想想:“phi”-ture 函数)。当我们将特征函数应用于我们的原始数据集 X \mathbb{X} X时,结果 Φ ( X ) \Phi(\mathbb{X}) Φ(X)是一个经过转换的设计矩阵,可以用于建模。
例如,我们可以设计一个特征函数,计算现有特征的平方并将其添加到设计矩阵中。在这种情况下,我们现有的矩阵 [ x ] [x] [x]被转换为 [ x , x 2 ] [x, x^2] [x,x2]。其维度从 1 增加到 2。通常,特征化数据集的维度会增加,如此处所示。

特征函数引入的新特征然后可以用于建模。通常,我们使用符号 ? i \phi_i ?i?表示特征工程后的转换特征。
y ^ = θ 1 x + θ 2 x 2 \hat{y} = \theta_1 x + \theta_2 x^2 y^?=θ1?x+θ2?x2
y ^ = θ 1 ? 1 + θ 2 ? 2 \hat{y}= \theta_1 \phi_1 + \theta_2 \phi_2 y^?=θ1??1?+θ2??2?
在矩阵表示中,符号 Φ \Phi Φ有时用于表示特征工程后的设计矩阵。请注意,在下面的用法中, Φ \Phi Φ现在是一个经过特征工程处理的矩阵,而不是一个函数。
Y ^ = Φ θ \hat{\mathbb{Y}} = \Phi \theta Y^=Φθ
更正式地,我们将特征函数描述为将原始的 R n × p \mathbb{R}^{n \times p} Rn×p数据集 X \mathbb{X} X转换为一个经过特征处理的 R n × p ′ \mathbb{R}^{n \times p'} Rn×p′数据集 Φ \mathbb{\Phi} Φ的过程,其中 p ′ p' p′通常大于 p p p。
X ∈ R n × p ? Φ ∈ R n × p ′ \mathbb{X} \in \mathbb{R}^{n \times p} \longrightarrow \Phi \in \mathbb{R}^{n \times p'} X∈Rn×p?Φ∈Rn×p′
14.5 独热编码
特征工程为设计更好的性能模型打开了一整套新的可能性。正如您将在实验室和家庭作业中看到的那样,特征工程是整个建模过程中最重要的部分之一。
特征工程的一个特别强大的用途是允许我们对非数值特征执行回归。独热编码是一种特征工程技术,它从分类数据生成数值特征,使我们能够使用通常的方法在数据上拟合回归模型。
为了说明这是如何工作的,我们将回顾以前讲座中的“小费”数据集。考虑数据集的“day”列:
代码
import numpy as np
tips = sns.load_dataset("tips")
tips.head()
| total_bill | tip | sex | smoker | day | time | size | |
|---|---|---|---|---|---|---|---|
| 0 | 16.99 | 1.01 | Female | No | Sun | Dinner | 2 |
| 1 | 10.34 | 1.66 | Male | No | Sun | Dinner | 3 |
| 2 | 21.01 | 3.50 | Male | No | Sun | Dinner | 3 |
| 3 | 23.68 | 3.31 | Male | No | Sun | Dinner | 2 |
| 4 | 24.59 | 3.61 | Female | No | Sun | Dinner | 4 |
乍一看,似乎不可能对这些数据拟合回归模型——我们无法直接对“太阳”进行任何数学运算。
为了解决这个问题,我们创建一个新表,其中包含原始“day”列中每个唯一值的特征。然后我们迭代“day”列。对于“day”中的每个条目,我们将新表中对应的特征填充为 1。所有其他特征都设置为 0。
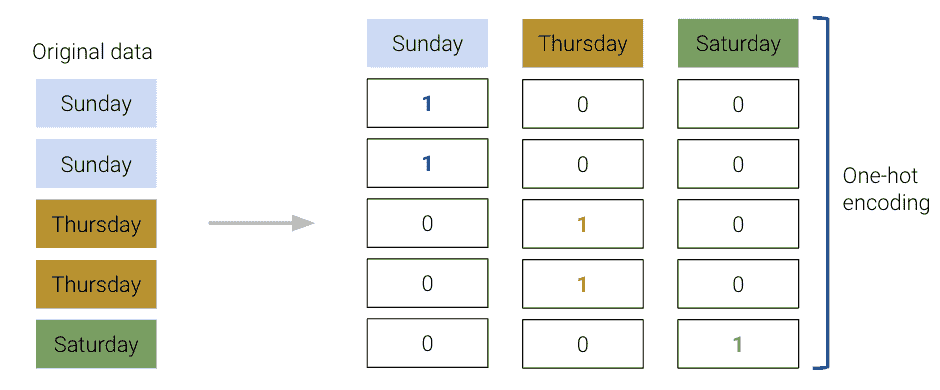
sklearn的OneHotEncoder类(文档)提供了一种快速执行这种独热编码的方法。您将在实验室中详细探讨它的用法。现在,要认识到我们遵循的工作流程与我们使用LinearRegression类时非常相似:我们初始化一个OneHotEncoder对象,将其拟合到我们的数据,然后使用.transform来应用拟合的编码器。
from sklearn.preprocessing import OneHotEncoder
# Initialize a OneHotEncoder object
ohe = OneHotEncoder()
# Fit the encoder
ohe.fit(tips[["day"]])
# Use the encoder to transform the raw "day" feature
encoded_day = ohe.transform(tips[["day"]]).toarray()
encoded_day_df = pd.DataFrame(encoded_day, columns=ohe.get_feature_names_out())
encoded_day_df.head()
| day_Fri | day_Sat | day_Sun | day_Thur | |
|---|---|---|---|---|
| 0 | 0.0 | 0.0 | 1.0 | 0.0 |
| 1 | 0.0 | 0.0 | 1.0 | 0.0 |
| 2 | 0.0 | 0.0 | 1.0 | 0.0 |
| 3 | 0.0 | 0.0 | 1.0 | 0.0 |
| 4 | 0.0 | 0.0 | 1.0 | 0.0 |
然后,独热编码的特征可以用于设计矩阵来训练模型:
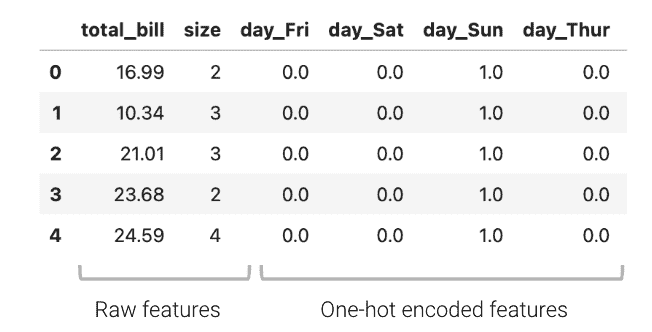
KaTeX parse error: Undefined control sequence: \textunderscore at position 33: …1 (\text{total}\?t?e?x?t?u?n?d?e?r?s?c?o?r?e?\text{bill}) + …
或者简写为:
y ^ = θ 1 ? 1 + θ 2 ? 2 + θ 3 ? 3 + θ 4 ? 4 + θ 5 ? 5 + θ 6 ? 6 \hat{y} = \theta_1\phi_1 + \theta_2\phi_2 + \theta_3\phi_3 + \theta_4\phi_4 + \theta_5\phi_5 + \theta_6\phi_6 y^?=θ1??1?+θ2??2?+θ3??3?+θ4??4?+θ5??5?+θ6??6?
现在,“day”特征(或者说,代表天的四个新布尔特征)可以用来拟合模型。
使用sklearn来拟合新模型,我们可以确定模型系数,从而了解每个特征对预测小费的影响。
from sklearn.linear_model import LinearRegression
data_w_ohe = tips[["total_bill", "size", "day"]].join(encoded_day_df).drop(columns = "day")
ohe_model = lm.LinearRegression(fit_intercept=False) #Tell sklearn to not add an additional bias column. Why?
ohe_model.fit(data_w_ohe, tips["tip"])
pd.DataFrame({"Feature":data_w_ohe.columns, "Model Coefficient":ohe_model.coef_})
| Feature | Model Coefficient | |
|---|---|---|
| 0 | total_bill | 0.092994 |
| 1 | size | 0.187132 |
| 2 | day_Fri | 0.745787 |
| 3 | day_Sat | 0.621129 |
| 4 | day_Sun | 0.732289 |
| 5 | day_Thur | 0.668294 |
例如,当查看day_Fri的系数时,我们可以了解星期五的事实对预测小费的影响有多大。
在独热编码时,要记住任何一组独热编码的列总是会加和为全为 1 的一列,表示偏置列。更正式地说,偏置列是 OHE 列的线性组合。
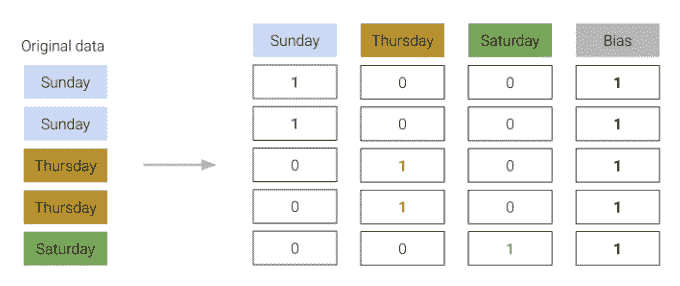
我们必须小心不要在我们的设计矩阵中包含这个偏置列。否则,模型中将存在线性依赖,这意味着 X T X \mathbb{X}^T\mathbb{X} XTX将不再可逆,我们的 OLS 估计 θ ^ = ( X T X ) ? 1 X T Y \hat{\theta} = (\mathbb{X}^T\mathbb{X})^{-1}\mathbb{X}^T\mathbb{Y} θ^=(XTX)?1XTY将失败。
为了解决这个问题,我们简单地省略了一个独热编码的列或不包括截距项。
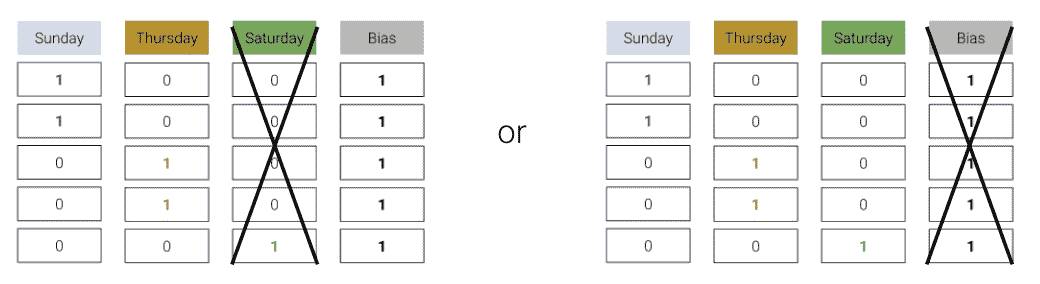
任何一种方法都可以——我们仍然保留了与省略列相同的信息,即省略列是剩余列的线性组合。
14.6 多项式特征
我们已经遇到了几种情况,其中具有线性特征的模型在显示明显非线性曲率的数据集上表现不佳。
举个例子,考虑包含有关汽车信息的vehicles数据集。假设我们想要使用汽车的hp(马力)来预测其"mpg"(每加仑英里数的汽油里程)。如果我们可视化这两个变量之间的关系,我们会看到一个非线性的曲率。将线性模型拟合到这些变量会导致高(差)的 RMSE 值。
y ^ = θ 0 + θ 1 ( hp ) \hat{y} = \theta_0 + \theta_1 (\text{hp}) y^?=θ0?+θ1?(hp)
代码
pd.options.mode.chained_assignment = None
vehicles = sns.load_dataset("mpg").dropna().rename(columns = {"horsepower": "hp"}).sort_values("hp")
X = vehicles[["hp"]]
Y = vehicles["mpg"]
hp_model = lm.LinearRegression()
hp_model.fit(X, Y)
hp_model_predictions = hp_model.predict(X)
import matplotlib.pyplot as plt
sns.scatterplot(data=vehicles, x="hp", y="mpg")
plt.plot(vehicles["hp"], hp_model_predictions, c="tab:red");
print(f"MSE of model with (hp) feature: {np.mean((Y-hp_model_predictions)**2)}")
MSE of model with (hp) feature: 23.943662938603108
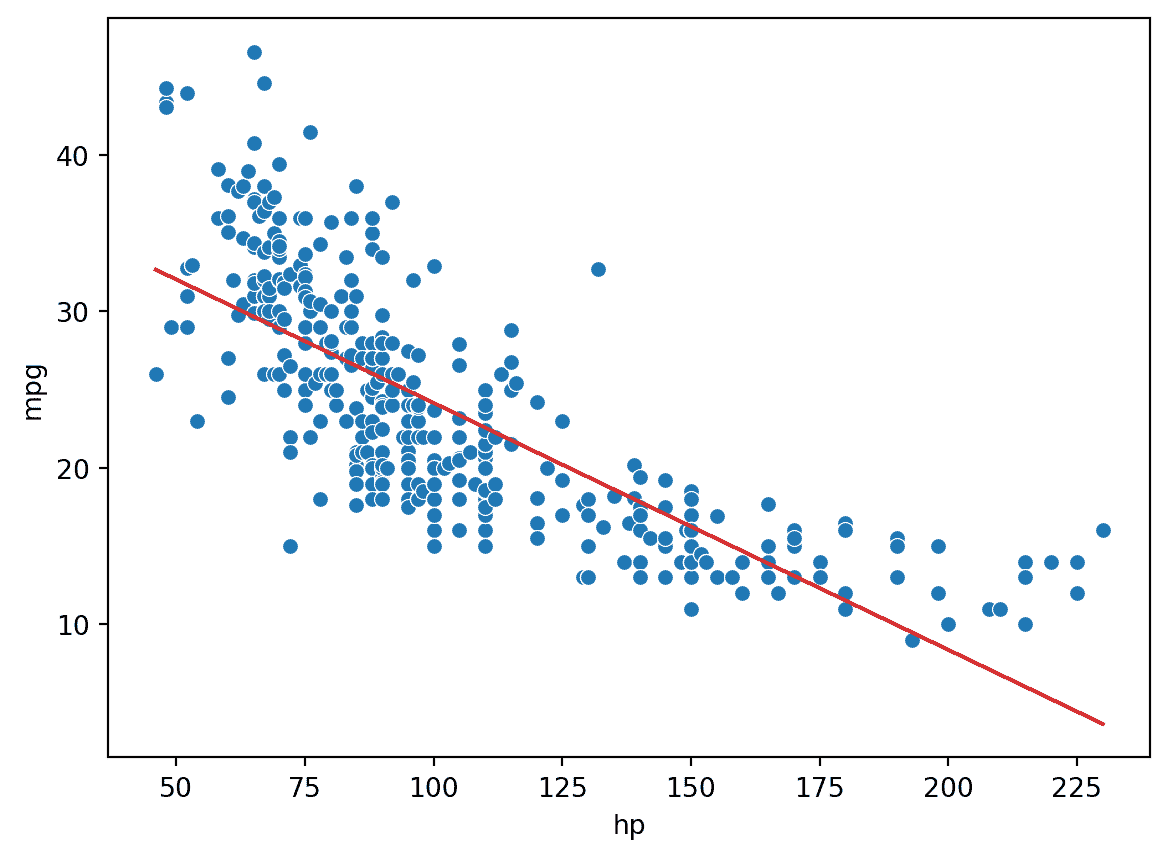
为了捕捉数据集中的非线性,将非线性特征纳入其中是有意义的。让我们在回归模型中引入一个多项式项, hp 2 \text{hp}^2 hp2。模型现在的形式是:
y ^ = θ 0 + θ 1 ( hp ) + θ 2 ( hp 2 ) \hat{y} = \theta_0 + \theta_1 (\text{hp}) + \theta_2 (\text{hp}^2) y^?=θ0?+θ1?(hp)+θ2?(hp2)
y ^ = θ 0 + θ 1 ? 1 + θ 2 ? 2 \hat{y} = \theta_0 + \theta_1 \phi_1 + \theta_2 \phi_2 y^?=θ0?+θ1??1?+θ2??2?
我们如何拟合具有非线性特征的模型?我们可以使用与以前完全相同的技术:普通最小二乘法、梯度下降或sklearn。这是因为我们的新模型仍然是一个线性模型。尽管它包含非线性特征,但它在模型参数方面是线性的。我们以前所有拟合模型的工作都是在假设我们正在处理线性模型的情况下进行的。因为我们的新模型仍然是线性的,我们可以应用我们现有的方法来确定最佳参数。
# Add a hp^2 feature to the design matrix
X = vehicles[["hp"]]
X["hp^2"] = vehicles["hp"]**2
# Use sklearn to fit the model
hp2_model = lm.LinearRegression()
hp2_model.fit(X, Y)
hp2_model_predictions = hp2_model.predict(X)
sns.scatterplot(data=vehicles, x="hp", y="mpg")
plt.plot(vehicles["hp"], hp2_model_predictions, c="tab:red");
print(f"MSE of model with (hp^2) feature: {np.mean((Y-hp2_model_predictions)**2)}")
MSE of model with (hp^2) feature: 18.984768907617223
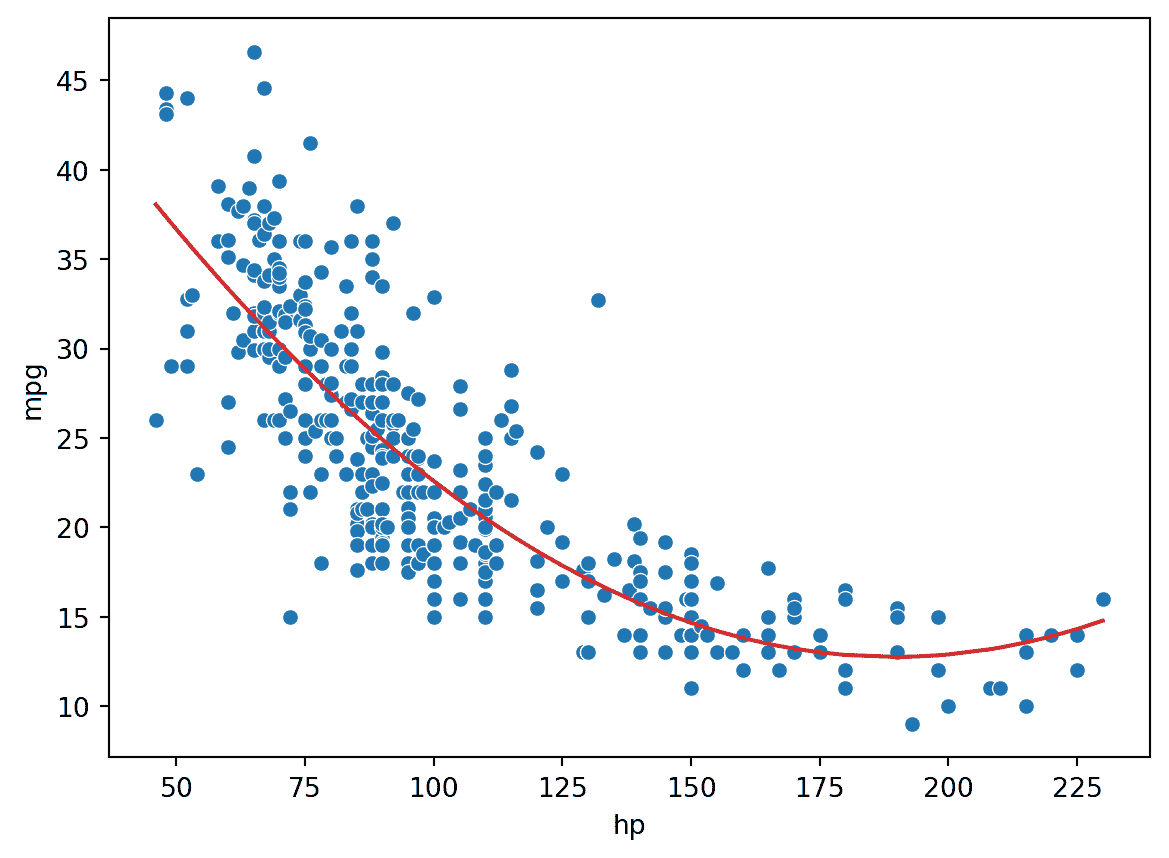
看起来好多了!通过引入一个平方特征,我们能够捕捉数据集的曲率。我们的模型现在是一个以我们的数据为中心的抛物线。请注意,相对于具有线性特征的原始模型,我们的新模型的误差已经减少了。
14.7 复杂性和过拟合
我们现在已经看到,特征工程使我们能够构建各种特征来提高模型的性能。特别是,我们看到设计更复杂的特征(在先前的vehicles数据中对hp进行平方)大大提高了模型捕捉非线性关系的能力。为了充分利用这一点,我们可能倾向于设计越来越复杂的特征。考虑以下三个不同阶数的模型(每个模型的最大指数幂):
-
二次模型: mpg ^ = θ 0 + θ 1 ( hp ) + θ 2 ( hp 2 ) \hat{\text{mpg}} = \theta_0 + \theta_1 (\text{hp}) + \theta_2 (\text{hp}^2) mpg^?=θ0?+θ1?(hp)+θ2?(hp2)
-
三次模型: mpg ^ = θ 0 + θ 1 ( hp ) + θ 2 ( hp 2 ) + θ 3 ( hp 3 ) \hat{\text{mpg}} = \theta_0 + \theta_1 (\text{hp}) + \theta_2 (\text{hp}^2) + \theta_3 (\text{hp}^3) mpg^?=θ0?+θ1?(hp)+θ2?(hp2)+θ3?(hp3)
-
四次模型: mpg ^ = θ 0 + θ 1 ( hp ) + θ 2 ( hp 2 ) + θ 3 ( hp 3 ) + θ 4 ( hp 4 ) \hat{\text{mpg}} = \theta_0 + \theta_1 (\text{hp}) + \theta_2 (\text{hp}^2) + \theta_3 (\text{hp}^3) + \theta_4 (\text{hp}^4) mpg^?=θ0?+θ1?(hp)+θ2?(hp2)+θ3?(hp3)+θ4?(hp4)
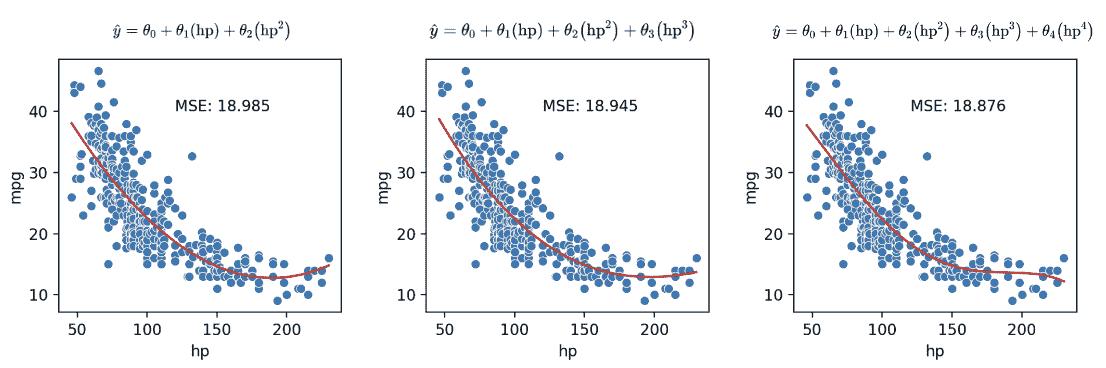
正如我们在上面的图中所看到的,随着每个额外的多项式项,均方误差继续减小。为了进一步可视化,让我们将模型从复杂度 0 增加到 6 进行绘制:
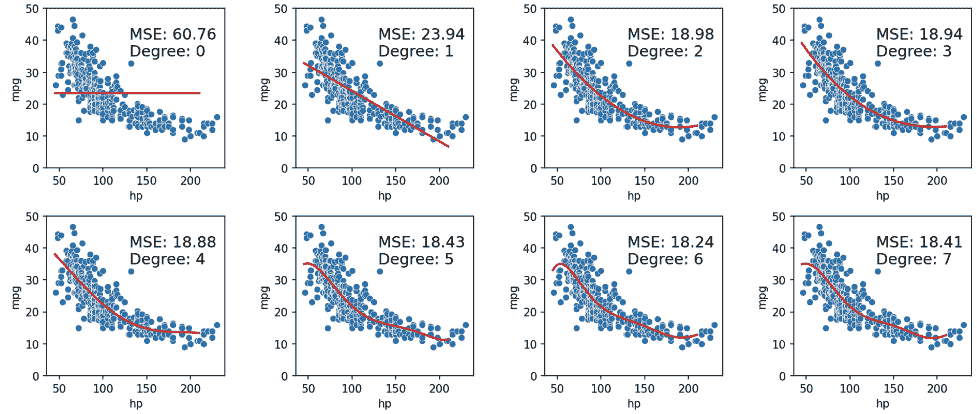
当我们使用我们的模型对用于拟合模型的相同数据进行预测时,我们发现随着每个额外的多项式项(随着我们的模型变得更复杂),MSE 会减少。训练误差是模型在生成来自用于训练目的的相同数据的预测时的误差。我们可以得出结论,随着模型复杂度的增加,训练误差会下降。
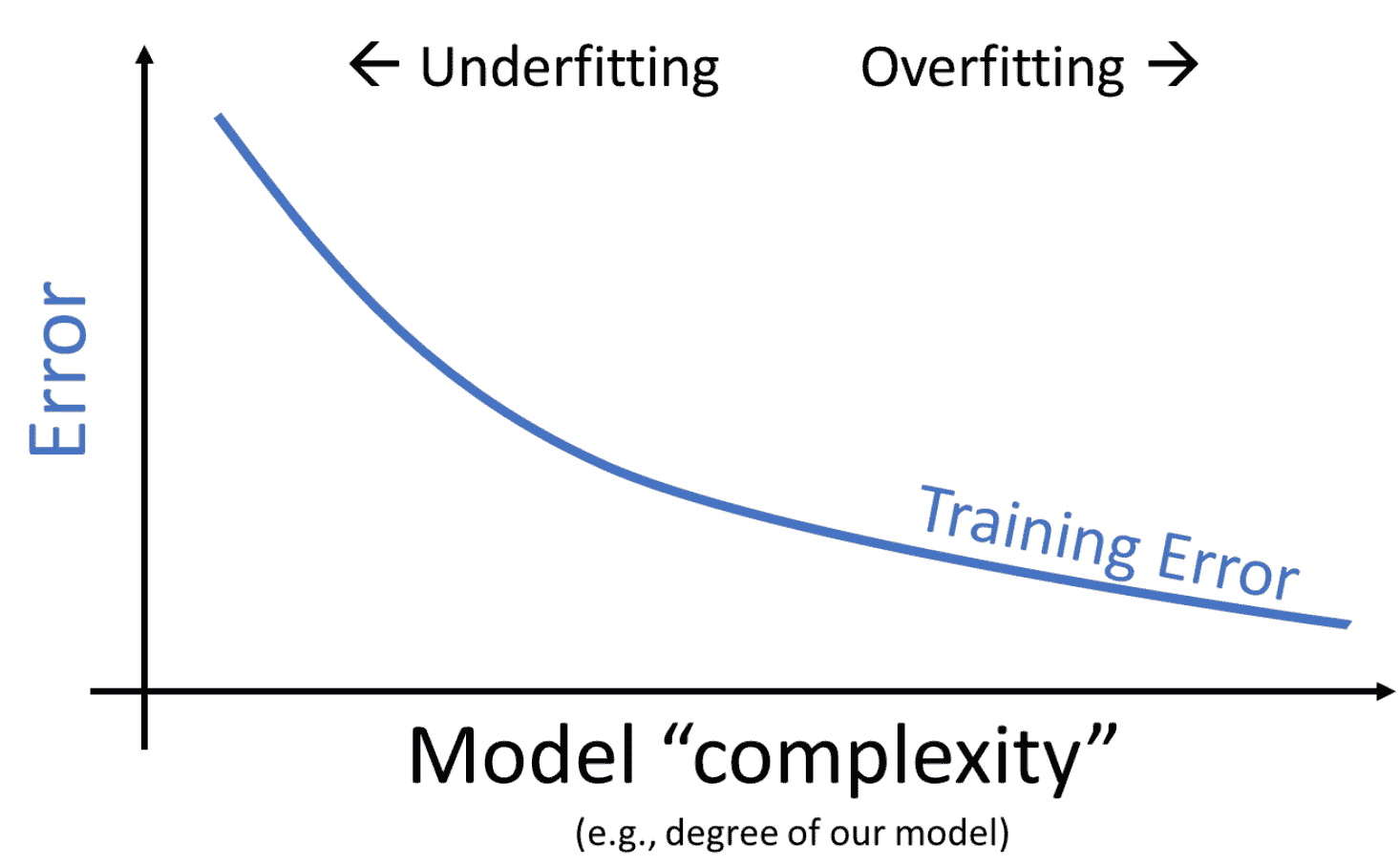
这看起来像是个好消息 - 在处理训练数据时,我们可以通过设计越来越复杂的模型来提高模型性能。
数学事实:给定 N N N个重叠的数据点,我们总是可以找到一个通过所有这些点的 N ? 1 N-1 N?1次多项式。
例如:总是存在一个 4 次多项式曲线,可以完美地模拟一个包含 5 个数据点的数据集!train_error
{kind=link}
然而,高模型复杂性也带来了自己的一系列问题。在构建上述vehicles模型时,我们在整个数据集上训练了模型,然后评估了它们在同一数据集上的性能。实际上,我们很可能会在样本中训练模型,然后使用它对在训练期间未遇到的数据进行预测。
让我们通过一个更现实的例子来看看。假设我们有一个仅包含 6 个数据点的训练数据集,并希望训练一个模型,然后对不同的数据点进行预测。我们可能会倾向于制作一个非常复杂的模型(例如,5 次方),特别是考虑到它在左侧清晰地对训练数据进行了完美的预测。然而,如右侧图表所示,这个模型在整个数据集上的表现会非常糟糕!
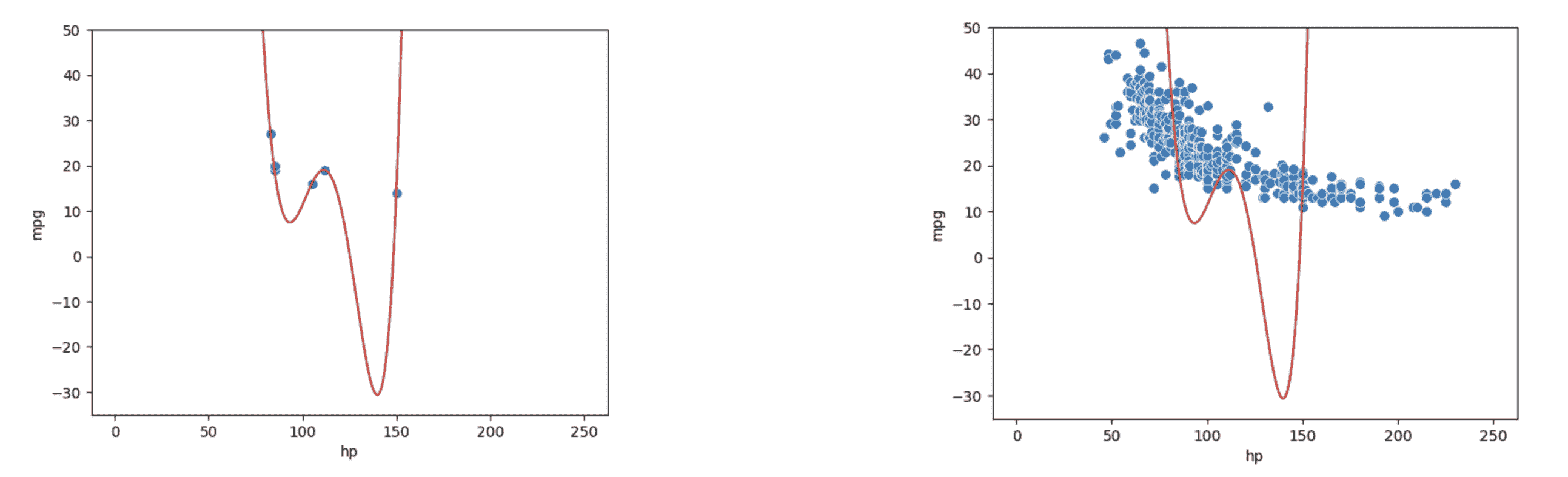
上述现象被称为过拟合。该模型实际上只是记住了它在拟合时遇到的训练数据,导致它无法很好地对在训练期间未遇到的数据进行泛化。
此外,由于复杂模型对用于训练它们的特定数据集敏感,它们具有高方差。具有高方差的模型在训练不同数据集时往往会产生更大的变化。回到上面的例子,我们可以看到我们的 5 次方模型在拟合来自vehicles的不同 6 点样本时变化不稳定。
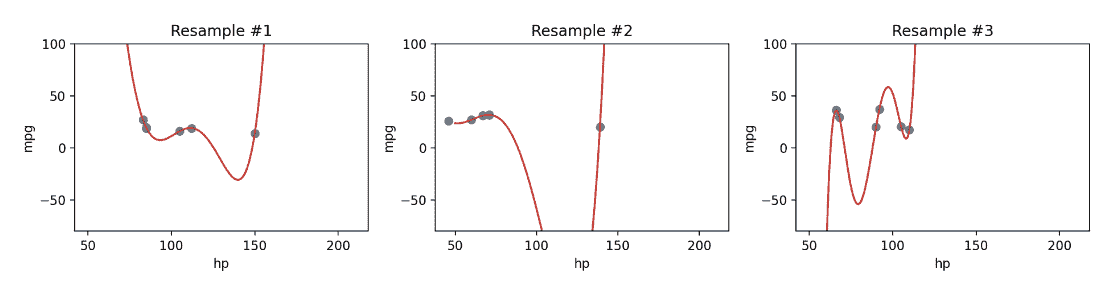
现在我们面临一个两难选择:我们知道我们可以通过增加模型复杂性来减少训练误差,但是过于复杂的模型开始过拟合,并且由于高方差无法重新应用于新的数据集。
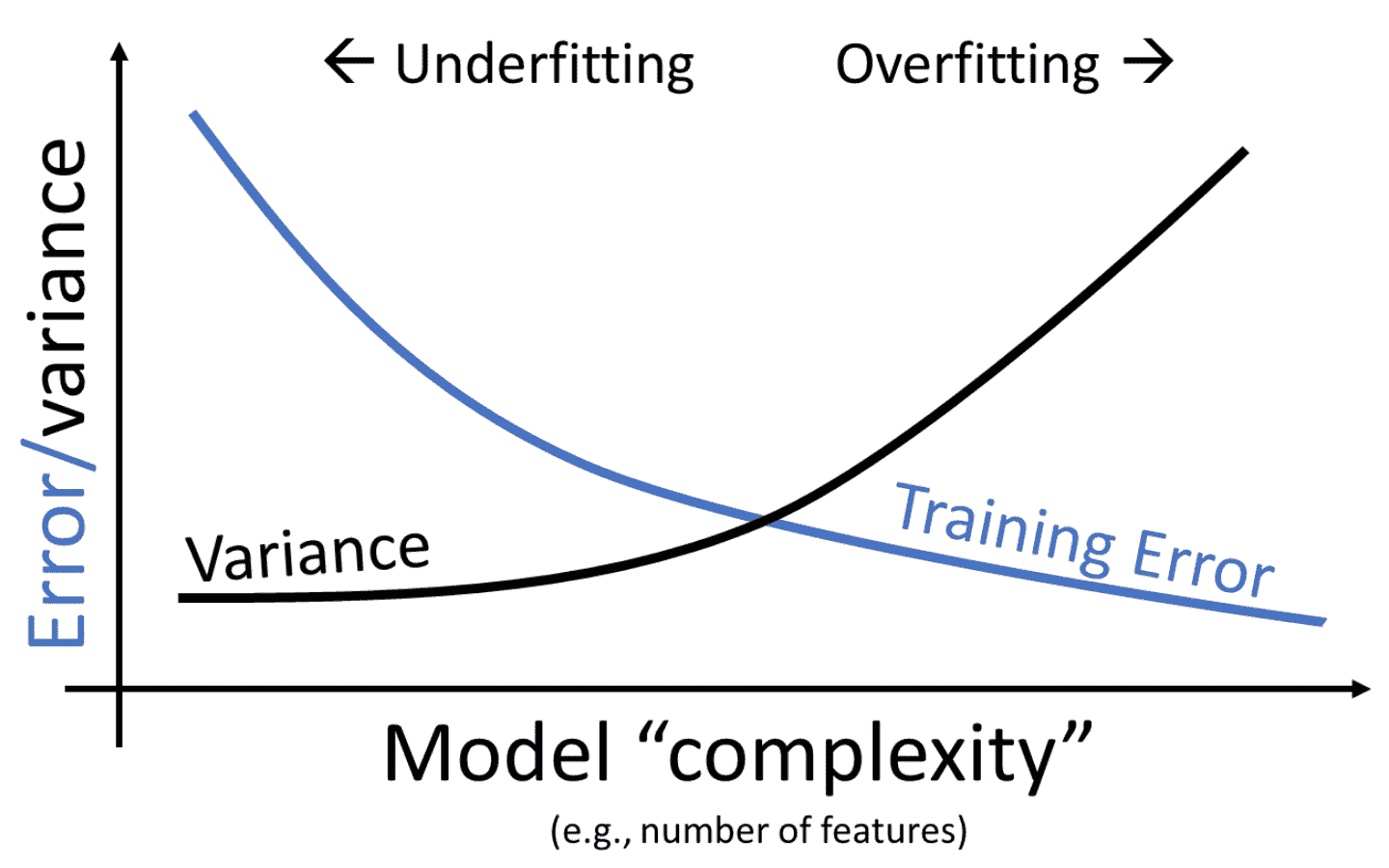
我们可以看到,模型复杂性带来了明显的权衡。随着模型复杂性的增加,模型在训练数据上的误差减少。与此同时,模型的方差往往会增加。
这里的要点是:我们需要在模型的复杂性上取得平衡;我们希望模型能够泛化到“未见过”的数据。一个太简单的模型将无法捕捉我们感兴趣的变量之间的关键关系;一个太复杂的模型则有过拟合的风险。
这引出了一个问题:我们如何控制模型的复杂性?请关注我们的第 16 讲,交叉验证和正则化!
十五、人类背景和伦理的案例研究
原文:Case Study in Human Contexts and Ethics
译者:飞龙
学习成果
-
了解数据科学家面临的道德困境。
-
了解如何使用有关数据的上下文知识批判模型。
免责声明:以下章节讨论了结构性种族主义的问题。本章中的一些内容可能比较敏感,可能或可能不是收集材料的学生的意见、想法和信念。Data 100 课程工作人员尽最大努力只呈现与教授课程相关的信息。
**注意:**由于讲座中提出的一些论点的微妙性质,强烈建议您观看讲座录像,以便充分参与和理解材料。课程笔记将具有相同的更广泛结构,但绝不是全面的。
让我们沉浸在一个名为库克县评估员办公室(CCAO)的组织的数据科学家的现实故事中。他们的工作是估算房屋的价值以分配财产税。这是因为该地区的税收负担是由房屋的估算价值决定的,这与其价格不同。由于价值随时间变化,且没有明显的价值指标,他们创建了一个模型来估算房屋的价值。在本章中,我们将深入探讨偏见模型存在的问题,对人类生活的后果,以及我们如何从这个例子中学习以做得更好。
15.1 问题
《芝加哥论坛报》的一份报告揭露了一个重大丑闻:该团队表明该模型延续了一个高度累进的税收体系,不成比例地加重了库克县的非裔美国人和拉丁裔房主的负担。他们是如何知道的呢?
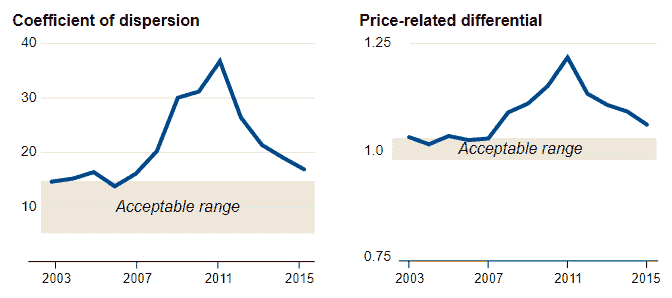
在住房评估领域,评估员使用的标准指标是:离散系数和价格相关差异。这些指标已经在该领域的专家进行了严格测试,超出了我们课程的范围。对库克县价格计算这些指标显示,CCAO 制定的价格不在可接受范围内(见上图)。这本身并不是故事的结束,但是一个很好的指示有些不对劲。
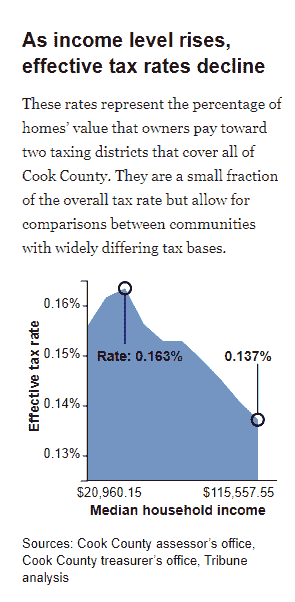
这促使他们调查模型本身是否产生了公平的税率。显然,当考虑到房主的收入时,他们发现该模型实际上产生了累进的税率(见上图)。如果百分比税率对收入较低的个人更高,则税率是累进的。如果百分比税率对收入较高的个人更高,则税率是累进的。
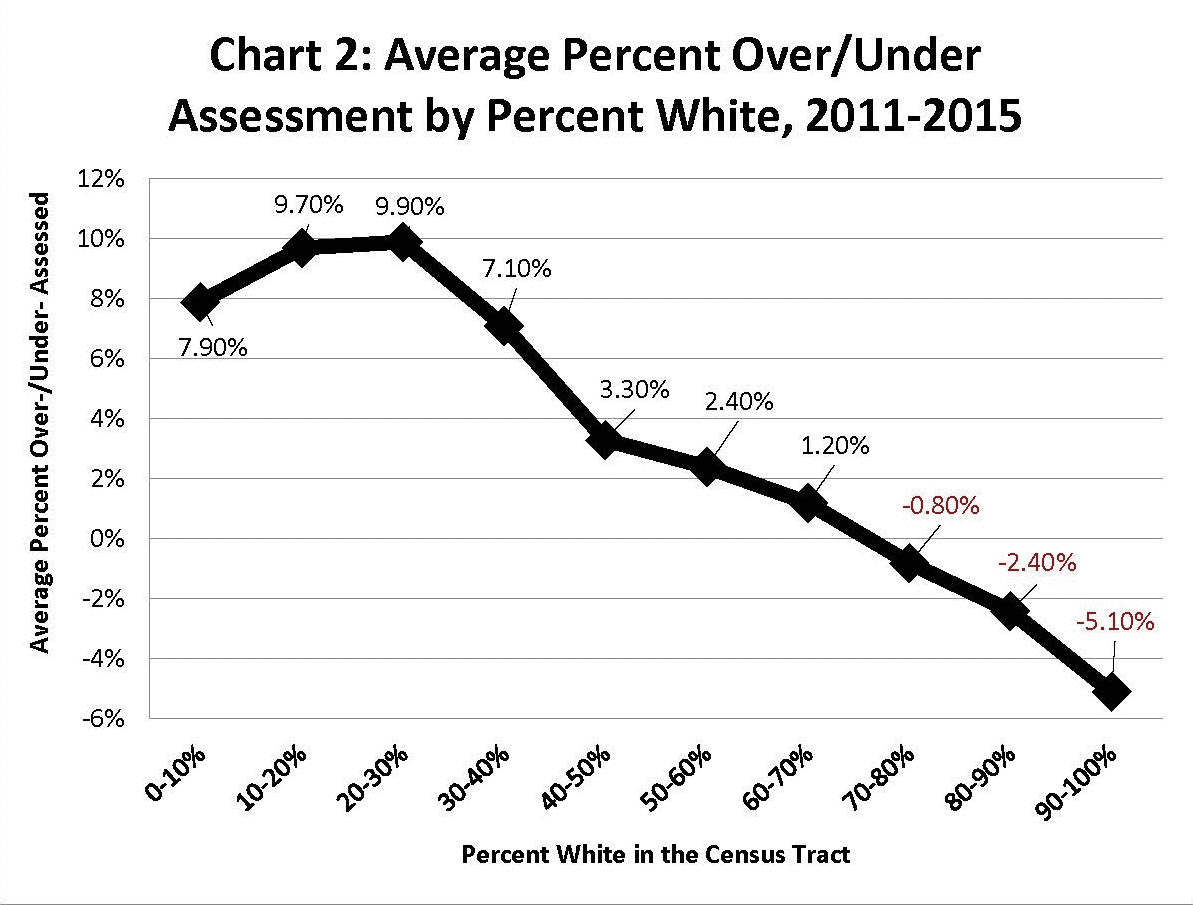
进一步的调查表明,这个系统不仅对收入的轴线上的人不公平,也对种族的轴线上的人不公平(见上图)。一栋房产被低估或高估的可能性高度依赖于业主的种族,这让许多房主感到不安。
15.1.1 重点:上诉
这到底是什么导致了这种情况?一个全面的答案超出了模型。归根结底,这些都是有很多活动部分的真实系统。其中之一是上诉系统。房主会收到 CCAO 评估的房屋价值的邮件,房主可以选择向一组选举官员上诉,试图改变他们的房屋价值清单,从而改变他们被征税的金额。从理论上讲,这听起来是一个非常公平的系统:有人监督房屋的最终定价,而不仅仅是一个算法。然而,它最终加剧了问题。
“上诉是一件好事,”估价和上诉副主管托马斯·雅科内蒂在一次采访中说。“这里的目标是公平。我们制定了这些数字。我们可以改变它们。”
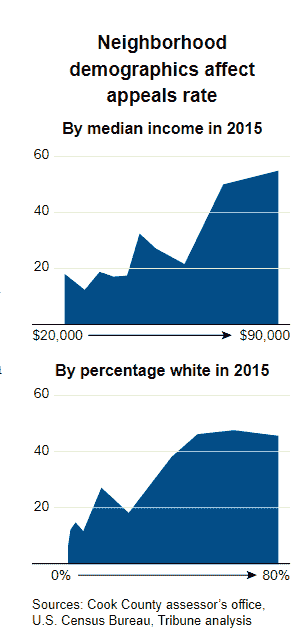
在这里,我们可以从批判种族理论中汲取教训。表面上,每个人都有法定权利尝试上诉是不可否认的。然而,并非每个人都有平等的能力这样做。那些有钱雇佣税务律师为他们上诉的人尝试和成功的机会大大提高(见上图)。这种模式是潜在腐败的深层制度模式的一部分。
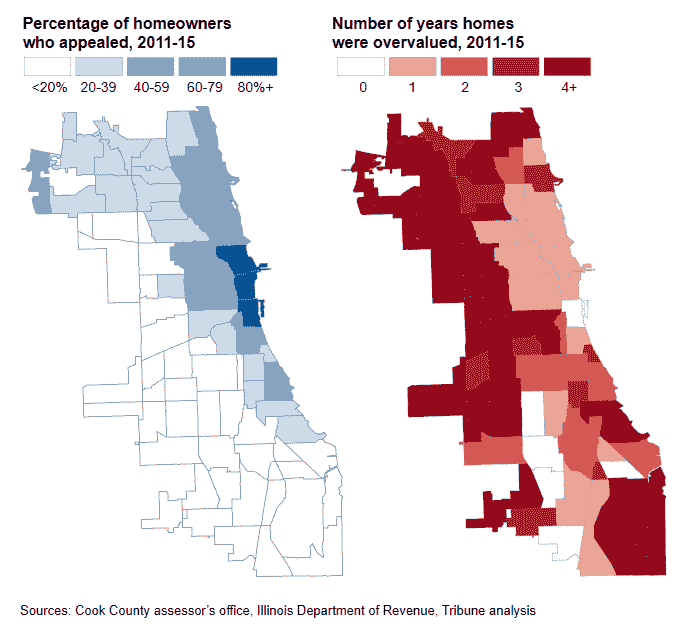
上诉的房主相对于没有上诉的房主通常被低估(见上图)。收入较高的人支付较少的房产税,税务律师能够因为他们在上诉中的角色而发展业务,政客通常与上述税务律师和富裕的房主有社会联系。所有这些利益相关者都有理由宣传这种模式作为公平制度的一个组成部分。在这里提出问题是有价值的:一个表面上看起来公平的系统在仔细观察后实际上可能是不公平的。
15.1.2 人类影响

住房模式的影响超出了房屋所有权和税收的范围。歧视性做法在美国有着悠久的历史,而这种模式则服务于延续这一事实。直到今天,芝加哥是美国最种族隔离的城市之一(来源)。这些因素对我们作为数据科学家来说至关重要。
15.1.3 聚焦:房地产和种族的交汇
住房一直是美国历史上种族不平等的持续来源,也是其他因素之一。它是不平等产生和再生产的主要领域之一。起初,吉姆·克劳法明确禁止有色人种进入学校、公共设施等。
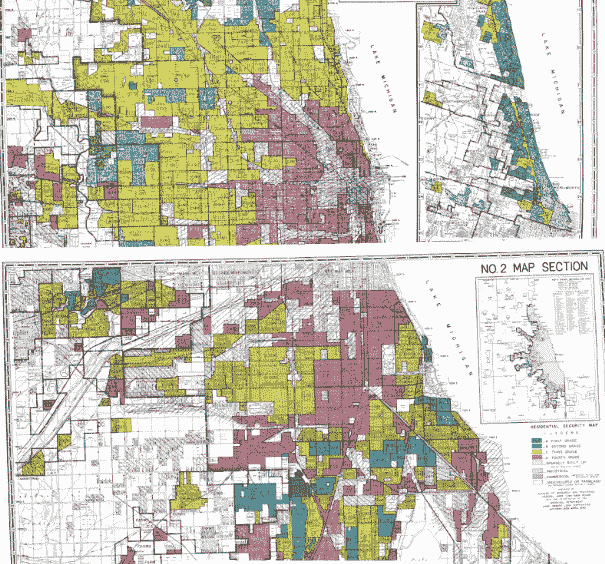
今天,尽管民权方面取得了进展,但美国许多地方的法律精神仍然存在。房地产行业在 20 世纪 20 年代和 30 年代被“专业化”,渴望成为一门由严格方法和原则指导的科学,如下所述:
-
红线政策:使在特定被编码为“高风险”(红色)的社区购买联邦支持抵押贷款变得困难或不可能。
-
根据这些制造商的说法,是什么使它们“高风险”。
-
种族隔离不仅是联邦政策的结果,而且是房地产专业人士发展起来的。
-
-
方法集中在创建客观的评级系统(信息技术)来评估房产价值,这些系统将种族编码为估值因素(见下图),
- 这反过来影响了联邦政策和实践。

来源:Colin Koopman,《我们如何成为我们的数据》(2019 年)第 137 页
15.2 回应:库克县开放数据倡议
回应始于政治。新的评估员弗里茨·凯吉当选并制定了两个目标的新任务:
-
财产税的分配公平,意味着同等价值的财产在评估过程中受到同等对待。
-
创建一个新的数据科学办公室。

15.2.1 问题/问题的形成
驱动问题
-
我们想知道什么?
-
我们试图解决什么问题?
-
我们想要测试什么假设?
-
我们的成功指标是什么?
数据科学办公室通过重新定义他们的目标来开始。
-
准确、一致和公正地评估房屋价值
-
遵循国际标准(离散系数)
-
尽可能准确地预测所有房屋的价值
-
-
创建一个强大的管道,能够准确评估规模化的财产价值,并且公平
-
打破腐败的循环(评审委员会的上诉程序)
-
消除累退性
-
在所有利益相关者中建立对系统的信任
-
定义:公平和透明度
库克县评估员办公室给出的定义如下:
-
公平:我们的管道能够准确评估财产价值,考虑到地理、信息等方面的差异。
-
透明度:数据科学部门分享和解释管道结果和决策的能力,向内部和外部利益相关者
请注意办公室如何以准确性来定义“公平”。因此,问题——使系统更公平——已经以数据科学家易于处理的术语来表述:使评估更准确。
这里的想法是,如果模型更准确,它也会(或许必然会)变得更公平,这是一个很大的假设。从某种意义上说,存在两个不同的问题——做出准确的评估,建立一个公平的系统。
目标的定义方式导致我们提出了一个问题:准确评估财产价值实际上意味着什么,以及“规模”在其中扮演了什么角色?
-
房屋价值的评估是什么?
-
一项评估比另一项更准确的原因是什么?
-
一批评估比另一批更准确的原因是什么?
以上每个问题都引发了一系列更多的问题。仅考虑第一个问题,一个答案可能是评估是对房屋价值的估计。这带来了更多的疑问:房屋的价值是多少?是什么决定了它?我们怎么知道?在这个课程中,我们认为它是房屋的市场价值。
15.2.2 数据获取和清理
驱动问题
-
我们有什么数据,我们需要什么数据?
-
我们将如何取样更多的数据?
-
我们的数据是否代表我们想研究的人口?
数据科学家还对他们最初的销售数据进行了批判性审查:
并提出了以下问题:
-
这些数据是如何收集的?
-
这些数据是何时收集的?
-
谁收集了这些数据?
-
数据收集的目的是什么?
-
特定类别是如何创建的,为什么创建的?
例如,属性在数据中出现的可能性不同,芝加哥洪水平原地理区域的住房数据比其他地区少。
这些特征甚至可以以不同的速度报告。改善房屋,往往会增加房产价值,但业主们不太可能报告这一点。
此外,他们发现低收入社区的缺失数据更多。
15.2.3 探索性数据分析
驱动问题
-
我们的数据是如何组织的,它包含了什么?
-
我们已经有相关的数据了吗?
-
数据中存在什么偏见、异常或其他问题?
-
我们如何转换数据以实现有效的分析?
在建模步骤之前,他们调查了许多关键问题:
-
哪些属性对销售价格的预测最有帮助?
-
数据是否均匀分布?
-
所有社区的数据都是最新的吗?所有社区的粒度都一样吗?
-
一些社区的数据是否缺失或过时?
首先,他们发现某些特征的影响,比如卧室数量,在确定某些社区内房屋价值方面比其他社区更有影响力。这让他们知道应该根据社区使用不同的模型。
他们还注意到低收入社区的数据不足。这让他们知道他们需要开发新的数据收集实践,包括寻找新的数据来源。
15.2.4 预测和推断
驱动问题
-
数据对世界有何说法?
-
它是否回答了我们的问题或准确解决了问题?
-
我们的结论有多可靠,我们能相信这些预测吗?
CCA0 不是使用单一模型来预测未售出房产的销售价格(“公平市场价”),而是使用机器学习模型来发现使用已知销售价格和相似和附近房产特征的模式。它为每个乡镇使用不同的模型权重。
与传统的大规模评估相比,CCA0 的新方法更加细致,并对社区变化更加敏感。
在这里,我们可能会问为什么任何特定的个人应该相信该模型对他们的房产是准确的?
这让我们认识到,CCA0 依赖于其“透明度”的表现(将数据、模型、管道放到 GitLab 上)来促进公众的信任,这将有助于将“准确评估”的产出与“公平”相提并论。
在评估我们的模型时,准确性、公平性和我们倾向使用的指标之间的关系还有很多需要讨论的地方。鉴于论点的微妙性质,建议您查看相应的讲座,因为课程笔记对于讲座的这一部分并不那么全面。
15.2.5 报告决策和结论
驱动问题
-
系统对每个目标有多成功?
-
模型的准确性/一致性
-
消除回归性和建立信任的公平和透明度
-
-
你怎么知道的?
模型并不是终点。新办公室仍然向房主发送他们的房屋评估报告,但现在他们会考虑从房主那里得到的数据。办公室本身正在撰写更详细的报告,以使信息民主化。市政厅和其他面向公众的宣传活动有助于让整个社区参与到住房评估的过程中,而不是仅限于少数人参与。****
15.3 主要收获
-
准确性是公平系统的必要条件,但不是充分条件。
-
公平和透明度是依赖于环境和社会技术概念的。
-
学会与环境一起工作,并考虑你的数据分析将如何重塑它们。
-
牢记数据分析的力量和局限性。
15.4 数据科学实践的教训
-
问题/问题的制定
-
谁负责框定问题?
-
谁是利益相关者?他们如何参与问题的框架?
-
你能提供什么?你的立场如何影响你对问题的理解?
-
你正在利用哪些叙事?
-
-
数据获取和清理
-
数据从哪里来?
-
谁收集了它?为了什么目的?
-
使用了什么样的收集和记录系统和技术?
-
过去如何使用这些数据?
-
对于数据访问有什么限制,以及是什么使您能够访问?
-
-
探索性数据分析和可视化
-
在这些数据中,有哪些个人或群体身份变得突出?
-
哪些变量变得突出,它们之间有什么样的关系?
-
任何可见的关系是否会导致对特定社区可能有害的争论?
-
-
预测和推断
-
预测或推断在世界上起到什么作用?
-
结果对预期目的有用吗?
-
是否有基准可以比较结果?
-
你的预测和推断如何依赖于模型所在的更大系统?
-
-
报告、决策和解决方案
-
我们如何知道我们是否实现了我们的目标?
-
你的工作如何融入更广泛的文献?
-
你的工作在哪些方面与现状一致或不一致?
-
你的结论是否合理?
-
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- DTO与VO
- pytest之allure测试报告03:allure动态自定义报告
- 网站地址栏提示“不安全”该如何解决
- 虚拟机配置网络
- 重要涉密文件怎样防窃取:文件防止泄密的措施(怎么能够让公司文件更安全防泄密?)
- 云计算:Vmware 安装 FreeNAS
- JVM工作原理与实战(一):初识JVM
- 《数学之友》期刊投稿方式投稿邮箱
- 「alias」Linux 给命令起别名,自定义bash命令
- 软件园实习生管理分析系统(JSP+java+springmvc+mysql+MyBatis)