Hive分区表实战 - 单分区字段
发布时间:2024年01月10日
文章目录
一、实战概述
-
在本Hive分区表管理实战中,我们通过一系列实际操作演示了如何有效地利用分区功能来组织和查询大规模数据。首先,创建了一个名为
book的内部分区表,其结构包含id与name字段,并根据country字段进行分区。接下来,准备并加载了不同国家(中国和英国)书籍的数据文件到对应的分区目录中。 -
为了展示分区灵活性,我们还模拟了手动创建新分区(日本),上传数据文件并通过
msck repair table命令将新分区纳入表的元数据管理中。此外,实战还涉及分区的删除、重命名等操作,直观展示了Hive如何同步更新分区状态至HDFS存储及元数据层面。 -
最后,通过查看MySQL中Hive Metastore数据库的相关表信息,揭示了Hive如何记录分区的具体元数据内容,包括分区位置等关键信息。整个实战过程充分展现了Hive分区表在提升查询效率、实现数据分类存储以及简化数据管理方面的强大能力。
二、实战步骤
(一)创建图书数据库
- 执行命令:
create database bookdb;

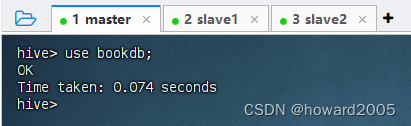
- 执行命令:
use bookdb;,切换到bookdb数据库
(二)创建国别分区的图书表
- 执行语句:
create table book (id int, name string) partitioned by (country string) row format delimited fields terminated by ' ';,创建book表

(三)在本地创建数据文件
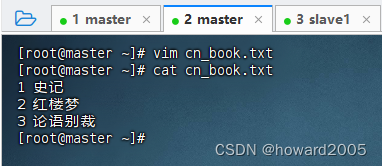
- 在master虚拟机上创建中文书籍数据文件
cn_book.txt
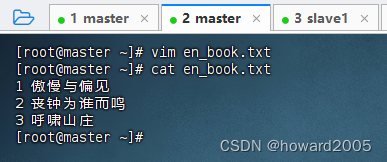
- 在master虚拟机上创建英文书籍数据文件
en_book.txt
(四)按分区加载数据
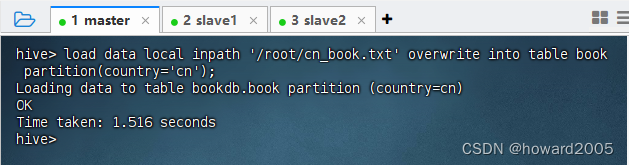
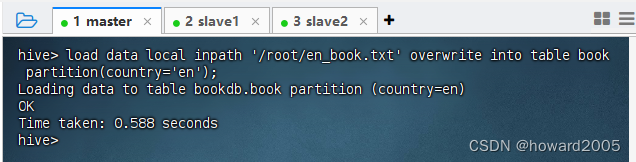
1、加载中文书籍数据到country=cn分区
- 执行语句:
load data local inpath '/root/cn_book.txt' overwrite into table book partition(country='cn');
2、加载英文书籍数据到country=en分区
- 执行语句:
load data local inpath '/root/en_book.txt' overwrite into table book partition(country='en');
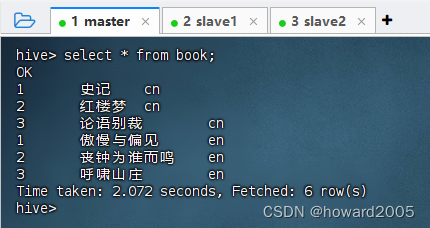
(五)查看分区表book全部记录
- 执行语句:
select * from book;,注意:第三列是分区字段
(六) 通过HDFS查看分区对应的目录及文件
- 使用HDFS Shell命令检查
/user/hive/warehouse/bookdb.db/book(假设这是hive表的默认存储位置)下的country=cn和country=en分区目录及其内部的数据文件。 - 执行命令:
hdfs dfs -ls -r /user/hive/warehouse/bookdb.db/book

(七)手动创建分区并上传数据
1、在HDFS上手动创建country=jp分区目录
- 执行命令:
hdfs dfs -mkdir /user/hive/warehouse/bookdb.db/book/country=jp

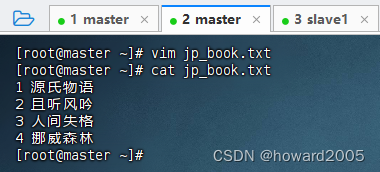
2、创建日文书籍数据文件jp_book.txt
- 在master虚拟机上创建
jp_book.txt
3、上传文件到HDFS日本分区目录
- 执行命令:
hdfs dfs -put jp_book.txt /user/hive/warehouse/bookdb.db/book/country=jp

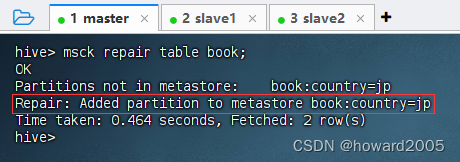
4、更新元数据以识别新分区
- 执行语句:
msck repair table book;
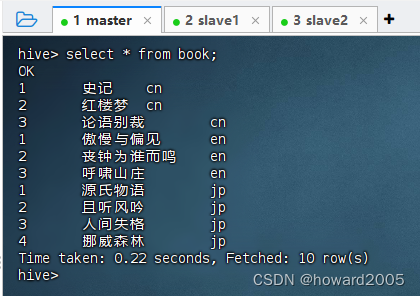
(八)再次查看book表全部记录
- 执行语句:
select * from book;,注意:第三列是分区字段
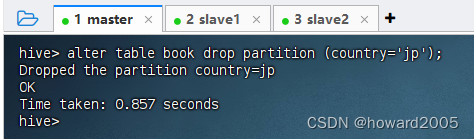
(九)删除指定分区
- 执行语句:
alter table book drop partition (country='jp');,删除country=jp分区
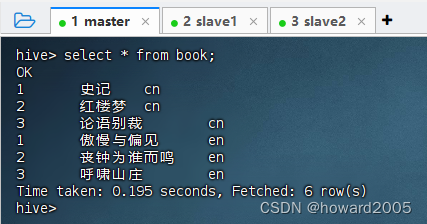
- 此时,查看分区表全部记录,就会发现没有日本书籍记录
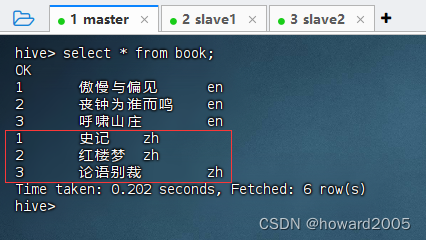
(十)更改分区名
- 将原有
country=cn分区重命名为country=zh,执行语句:alter table book partition (country='cn') rename to partition (country='zh');

- 此时,查看分区表全部记录
(十一)在MySQL中查看Hive元数据(分区信息)
1、登录MySQL Hive Metastore数据库
- 执行命令:
mysql -uroot -p903213,登录MySQL,然后执行use hive;,打开hive元数据库
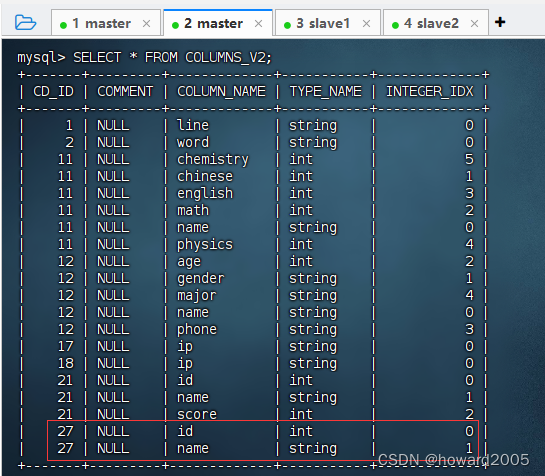
2、 查看book表分区元数据信息
-
执行语句:
SELECT * FROM COLUMNS_V2;,book分区表的CD_ID值是27
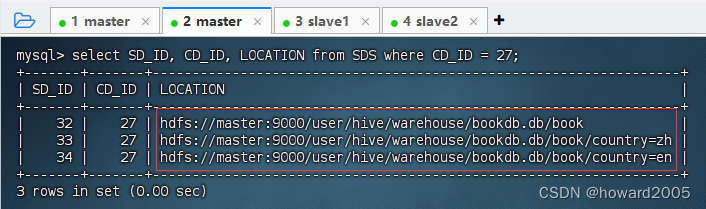
-
执行语句:
select SD_ID, CD_ID, LOCATION from SDS where CD_ID = 27;
三、实战总结
- 本实战演练全面展示了如何在Hive中创建和管理分区表,通过实际操作演示了数据按国别分区存储、加载与查询的全过程。从创建
book表开始,依次完成了数据文件准备、分区数据加载、分区查看及更新元数据等任务,并进一步演示了分区的增删改查操作,最后通过MySQL查看Hive Metastore中记录的分区元数据信息,充分体现了Hive分区表在提升查询效率与简化数据管理方面的优势。
文章来源:https://blog.csdn.net/howard2005/article/details/135495805
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 解决ELement-UI三级联动数据不回显
- 大网站都在用的HAproxy+Web群集还不快来学
- Zoho Mail:1600万企业用户的信赖之选
- 商城系统哪家好,如何选择商城系统?
- 小区物业大数据监控服务平台(PSD文件资料)
- mongodb相关信息
- 利用HTML+CSS+JS打造炫酷时钟网页的完整指南
- php项目laravel框架下在yapi接口文档中运行生产环境的接口
- 首个!百度飞桨会客厅落地广州,打通AI应用落地的“最后一公里”
- 现代软件测试中的自动化测试工具