poi操作Excel给列设置下拉菜单(数据验证)
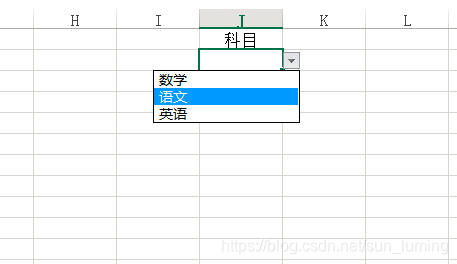
效果图:
pom.xml文件增加依赖:
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi</artifactId>
<version>4.0.1</version>
</dependency>
12345
Workbook实现类有三个:HSSFWorkbook、XSSFWorkbook和SXSSFWorkbook,实现类不同,操作方法也不同
HSSFWorkbook
HSSFWorkbook读取操作Excel2003以前(包括2003)的版本,文件扩展名为 .xls,导出的数据最多为65535,优点:一般不会发生内存溢出
设置下拉菜单方式:
String[] strs = {"语文","数学","体育"};
DVConstraint constraint = DVConstraint.createExplicitListConstraint(strs);
//参数顺序:开始行、结束行、开始列、结束列
CellRangeAddressList regions = new CellRangeAddressList(1,objects.size()+1,9,9);
HSSFDataValidation data = new HSSFDataValidation(regions,constraint);
data.setSuppressDropDownArrow(false);
sheet.addValidationData(data);
1234567
XSSFWorkbook
XSSFWorkbook读取操作Excel2007以后(包括2007)的版本,文件扩展名为 .xlsx,导出的数据最多为1048576行,16384列,缺点:有可能发生内存溢出
设置下拉菜单方式:
String[] strs = {"语文","数学","体育"};
XSSFDataValidationHelper helper = new XSSFDataValidationHelper(sheet);
XSSFDataValidationConstraint constraint = (XSSFDataValidationConstraint)helper.createExplicitListConstraint(strs);
//参数顺序:开始行、结束行、开始列、结束列
CellRangeAddressList addressList = new CellRangeAddressList(1,objects.size()+1,8,8);
XSSFDataValidation validation = (XSSFDataValidation)helper.createValidation(constraint, addressList);
validation.setSuppressDropDownArrow(true);
validation.setShowErrorBox(true);
sheet.addValidationData(validation);
123456789
可以根据自己使用的Workbook的具体实现类来选择使用上面哪种方式为列添加数据验证。
SXSSFWorkbook
为了解决XSSFWorkbook有时会发生内存溢出应运而生的,在生成Workbook 时给工作簿一个内存数据存在条数:
Workbook wb = new SXSSFWorkbook(5000);
1
这样一旦这个Workbook中数据量超过5000就会写入到磁盘中,减少内存的使用量来提高速度和避免溢出。
其实,就算生成很小的excel(比如几Mb),它用掉的内存是远大于excel文件实际的size的。如果单元格还有各种格式(比如,加粗,背景标红之类的),那它占用的内存就更多了。对于大型excel的创建且不会内存溢出的,就只有SXSSFWorkbook了。它的原理很简单,用硬盘空间换内存(就像hash map用空间换时间一样)。
SXSSFWorkbook的工作方式决定了它只会保存最新的excel rows在内存里供查看,在此之前的excel rows都会被写入到硬盘里(Windows电脑的话,是写入到C盘根目录下的temp文件夹)。被写入到硬盘里的rows是不可见的/不可访问的。只有还保存在内存里的才可以被访问到。
SXSSF与XSSF的对比:
a. 在一个时间点上,只可以访问一定数量的数据
b. 不再支持Sheet.clone()
c. 不再支持公式的求值
d. 在使用Excel模板下载数据时将不能动态改变表头,因为这种方式已经提前把excel写到硬盘的了就不能再改了
当数据量超出65536条后,在使用HSSFWorkbook或XSSFWorkbook,程序会报OutOfMemoryError:Javaheap space;内存溢出错误。这时应该用SXSSFworkbook。
所以如果使用SXSSFWorkbook操作Excel就别玩那么多花里胡哨的,比如设置什么下拉菜单。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 正态总体的假设检验
- [C++]使用yolov5的onnx模型结合onnxruntime和bytetrack实现目标追踪
- EfficientDet:Scalable and Efficient Object Detection中文版 (BiFPN)
- vue3 setup语法糖
- PyQt6 QInputDialog输入对话框控件
- 大泽动力柴油发电机配备移动式高速拖车
- 如何使用指针和字符数组完成单词统计?(语言-c++)
- C#.NET 7 全栈开发框架(含代码生成) -WMS 仓库管理系统搭建
- Elasticsearch之常用DSL语句
- Mysql利用备份数据恢复单表