第4章 树
前言
????????对于大量的输入数据,链表的线性访问时间太慢,不宜使用。本章介绍一种简单的数据结构,其大部分操作的运行时间平均为。我们还会简述对这种数据结构在概念上的简单修改,它保证了在最坏情形下的上述时间界。此外,还讨论了第二种修改,对于长的指令序列它对每种操作的运行时间基本上是
。
????????本章涉及的这种数据结构叫作二叉查找树(binary?search?tree)。在计算机科学中树(tree)是非常有用的抽象概念,因此,我们将讨论树在其他更一般的应用中的使用。
????????在这一章,我们将:
- 了解树是如何用于实现几个流行的操作系统中的文件系统的。
- 看到树如何能够用来计算算术表达式的值。
- 指出如何利用树支持以
平均时间进行的各种搜索操作,以及如何细化以得到最坏情况时间界
4.1 预备知识
????????树(tree)可以用几种方式定义。定义树的一种自然的方式是递归方法。一棵树是一些节点的集合。这个集合可以是空集;若非空,则一棵树由称作根(root)的节点r以及0个或多个非空的(子)树组成,这些子树中每一棵的根都被来自根r的一条有向的边(edge)所连接。
????????每一棵子树的根叫作根r的儿子(child),而r是每一棵子树的根的父亲(parent)。图4-1显示用递归定义的典型的树。
????????从递归定义中我们发现,一棵树是N个节点和N-1条边的集合,其中的一个节点叫
作根。存在N-1条边的结论是由下面的事实得出的,每条边都将某个节点连接到它的父
亲,而除去根节点外每一个节点都有一个父亲(见图4-2)。
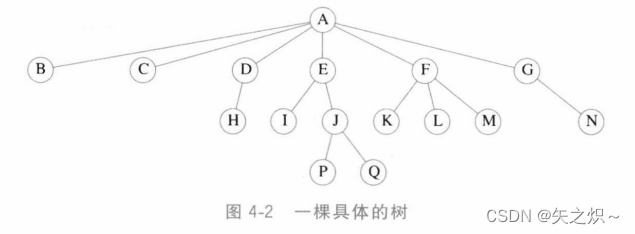
????????在图4-2的树中,节点A是根。节点F有一个父亲A并且有儿子K、L和M。每一个节点可以有任意多个儿子,也可能是零个儿子。没有儿子的节点称为树叶(leaf);上图中的树叶是B、C、H、I、P、Q、K、L、M和N。具有相同父亲的节点为兄弟(sibling);因此,K、L和M都是兄弟。用类似的方法可以定义祖父(grandparent)和孙子(grandchild)关系。
????????从节点到
的路径(path)定义为节点
的一个序列,使得对于
,节点
是
的父亲。这个路径的长(length)为该路径上边的条数,即k-1。从每一个节点到它自己有一条长为0的路径。注意,在一棵树中从根到每个节点恰好存在一条路径。
????????对任意节点,
的深度(depth)为从根到
的唯一路径的长。因此,根的深度为0。
的高(height)是从
到一片树叶的最长路径的长。因此所有的树叶的高都是0。一棵树的高等于它的根的高。对于图4-2中的树,E的深度为1而高为2;F的深度为1而高也是1;该树的高为3。一棵树的深度等于它的最深的树叶的深度;该深度总是等于这棵树的高。
????????如果存在从到
的一条路径,那么
是
的一位祖先(ancestor)而
是
的一个后裔(descendant)。如果
,那么
是
的一位真祖先(proper?ancestor)而
是
的一个真后裔(proper?descendant)。
4.1.1 树的实现
????????实现树的一种方法可以是在每一个节点除数据外还要有一些指针,使得该节点的每一个儿子都有一个指针指向它。然而,由于每个节点的儿子数可以变化很大并且事先不知道,因此在数据结构中建立到各儿子节点的直接链接是不可行的,因为这样会浪费太多的空间。实际上解法很简单:将每个节点的所有儿子都放在树节点的链表中。图4-3中的声明就是典型的声明。
????????图4-4显示一棵树可以用这种实现方法表示出来。图中向下的箭头是指向FirstChild(第一儿子)的指针。从左到右的箭头是指向NextSibling(下一兄弟)的指针。因为空指针太多,所以没有画出它们。
typedef struct TreeNode *PtrToNode;
struct TreeNode
{
ElementType Element;
PtrToNode FirstChild;
PtrToNode NextSibling;
};
????????在图4-4的树中,节点E有一个指针指向兄弟(F),另一指针指向儿子(I),而有的节
点这两种指针都没有。?
4.1.2 树的遍历及应用
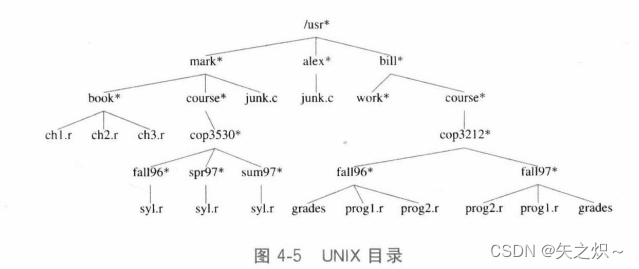
????????树有很多应用。流行的用法之一是包括UNIX、VAX/VMS和DOS在内的许多常用操作系统中的目录结构。图4-5是UNIX文件系统中一个典型的目录。
????????这个目录的根是/usr。(名字后面的星号指出/usr本身就是一个目录。)/usr有三个儿子:mark、alex和bill,它们自己也都是目录。因此,/usr包含三个目录而且没有正规的文件。文件名/usr/mark/book/ch1.r先后三次通过最左边的儿子节点而得到。在第一个“/”后的每个“/”都表示一条边;结果为一全路径名。这个分级文件系统非常流行,因为它能够使得用户逻辑地组织数据。不仅如此,在不同目录下的两个文件还可以享有相同的名字,因为它们必然有从根开始的不同的路径从而具有不同的路径名。在UNIX文件系统中的目录就是含有它的所有儿子的一个文件,因此,这些目录几乎是完全按照上述的类型声明构造的。事实上,如果将打印一个文件的标准命令应用到一个目录上,那么在该目录中的这些文件名能够在(与其他非ASCII信息一起的)输出中看到。
????????假设我们想要列出目录中所有文件的名字。我们的输出格式将是:深度为的文件的名字将被
次跳格(tab)缩进后打印出来。该算法在图4-6中给出。
????????算法的核心为递归程序ListDir。为了显示根时不进行缩进,该例程需要从目录名和深度0开始。这里的深度是一个内部簿记变量,而不是主调例程能够期望知道的那种参数。因此,驱动例程ListDirectory用于将递归例程和外界连接起来。?
static void ListDir(DirectoryOrFile D, int Depth)
{
if (D is a legitimate entry)
{
PrintName(D, Depth);
if (D is a directory)
for each child, C, of D
ListDir(C, Depth + 1);
}
}
void ListDirectory(DirectoryOrFile D)
{
ListDir(D, 0);
}????????算法逻辑简单易懂。ListDir的参数是到树中的某种引用。只要引用合理,则引用涉及的名字在进行适当次数的跳格缩进后被打印出来。如果是一个目录,那么我们递归地一个一个地处理它所有的儿子。这些儿子处在一个深度上,因此需要缩进一段附加的空格。整个输出如图4-7所示。

????????这种遍历的策略叫作先序遍历(preorder?traversal)。在先序遍历中,对节点的处理工作是在它的诸儿子节点被处理之前进行的。当该程序运行时,显然如图4-6所示,第2行对每个节点恰好执行一次,因为每个名字只输出一次。由于第2行对每个节点最多执行一次,因此第3行也必须对每个节点执行一次。不仅如此,对于每个节点的每一个儿子节点第5行最多只能执行一次。不过,儿子的个数恰好比节点的个数少1。最后,第5行每执行一次,for循环就迭代一次,每当循环结束时再执行一次。每个for循环终止在NULL指针上,但每个节点最多有一个这样的指针。因此,每个节点总的工作量是常数。如果有个文件名需要输出,则运行时间就是
。
????????另一种遍历树的方法是后序遍历(postorder?traversal)。在后序遍历中,在一个节点处的工作是在它的诸儿子节点被计算后进行的。例如,图4-8表示的是与前面相同的目录结构,其中圆括号内的数代表每个文件占用的磁盘区块(disk?block)的个数。?

????????由于目录本身也是文件,因此它们也有大小。设我们想要计算被该树所有文件占用的磁盘区块的总数。最自然的做法是找出含于子目录“/usr/mark(30)”“/usr/alex(9)”和“/usr/bi11(32)”中的块的个数。于是,磁盘块的总数就是子目录中的块的总数(71)加上“/usr”使用的一个块,共72个块。图4-9中的函数SizeDirectory实现这种遍历策略。
????????如果D不是一个目录,那么SizeDirectory只返回D所占用的块数。否则,将被D占用的块数与其所有子节点(递归地)发现的块数相加。为了区别后序遍历策略和先序遍历策略之间的不同,图4-10显示每个目录或文件的大小是如何由该算法产生的。?
static void SizeDirectory(DirectoryOrFile D)
{
int TotalSize;
TotalSize = 0;
if (D is a legitimate entry)
{
TotalSize = FileSize(D);
if (D is a directory)
for each child, C, of D
TotalSize += SizeDirectory(C);
}
return TotalSize;
}
4.2 二叉树
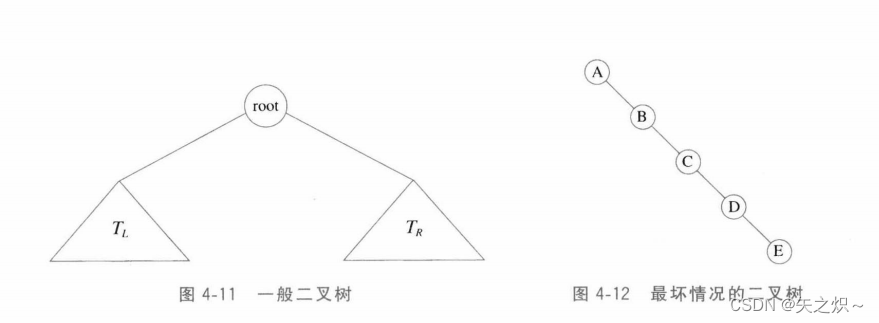
????????二叉树(binary?tree)是一棵树,其中每个节点的儿子都不能多于两个。
????????图4-11显示一棵由一个根和两棵子树组成的二叉树,和
均可能为空。
????????二叉树的一个性质是平均二叉树的深度要比小得多,这个性质有时很重要。分析表明,这个平均深度为
,而对于特殊类型的二叉树,即二叉查找树(binary?searchtree),其深度的平均值是
。不幸的是,如图4-12所示,这个深度是可以大到
的。
4.2.1 实现
????????因为一棵二叉树最多有两个儿子,所以我们可以用指针直接指向它们。树节点的声明在结构上类似于双链表的声明,在声明中,一个节点就是由Key(关键字)信息加上两个指向其他节点的指针(Left和Right)组成的结构(见图4-13)。
typedef struct TreeNode *PtrToNode;
typedef struct PtrToNode Tree;
struct TreeNode
{
ElementType Element;
Tree Left;
Tree Right;
};????????应用于链表上的许多法则也可以应用到树上。特别地,当进行一次插入时,必须调用malloc创建一个节点。节点可以在调用free删除后释放。
????????我们可以用在画链表时常用的矩形框画出二叉树,但是,树一般画成圆圈并用一些直线连接起来,因为二叉树实际上就是图(graph)。当涉及树时,我们也不显式地画出NULL指针,因为具有N个节点的每一棵二叉树都将需要N+1个NULL指针。
????????二叉树有许多与搜索无关的重要应用。二叉树的主要用处之一是在编译器的设计领域,我们现在就来探索这个问题。
4.2.2. 表达式树
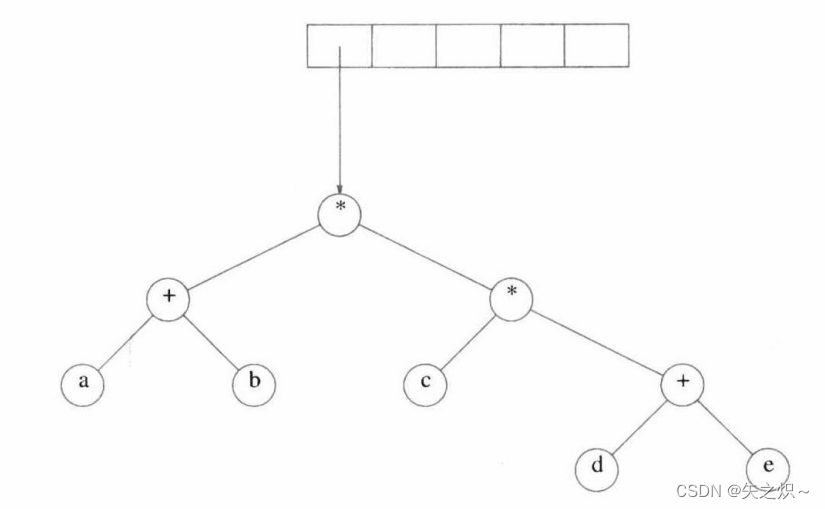
????????图4-14表示一个表达式树(expressiontree)的例子。表达式树的树叶是操作数(operand),比如常数或变量,而其他的节点为操作符(operator)。由于这里所有的操作都是二元的,因此这棵特定的树正好是二叉树,虽然这是最简单的情况,但是节点含有的儿子还是有可能多于两个的。一个节点也有可能只有一个儿子,如具有一目减算符(unary?minus?operator)的情形。可以将通过递归计算左子树和右子树所得到的值应用在根处的算符操作中而算出表达式树T的值。在我们的例中,左子树的值是“a + (b * c)”,右子树的值是“((d * e) + f) * g”,因此整棵树表示“(a + (b * c)) +? ? ? ?(((d * e) + f) * g)”。
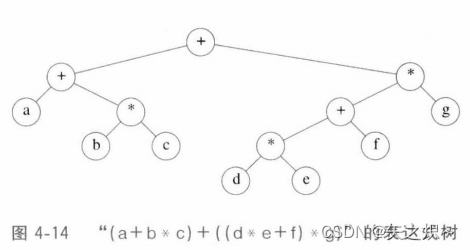
????????可以通过递归产生一个带括号的左表达式,然后打印出在根处的运算符,最后再递归地产生一个带括号的右表达式而得到一个(对两个括号整体进行运算的)中缀表达式(infix?expression)。这种一般的方法(左,节点,右)称为中序遍历(inorder?traversal);由于其产生的表达式类型,这种遍历很容易记忆。
????????另一个遍历策略是递归打印出左子树、右子树,然后打印运算符。如果我们应用这种策略于上面的树,则输出将是“a?b c * + d e * f + g * +”,容易看出,它就是3.3.3节中的后缀表达式。这种遍历策略一般称为后序遍历(postorder?traversal)。我们稍早已在4.1节中见过这种排序策略。
????????第三种遍历策略是先打印出运算符,然后递归地打印出右子树和左子树。其结果“+ + a * bc * + *defg”是不太常用的前缀(prefix)记法,这种遍历策略为先序遍历(preorder?traversal),稍早我们也在4.1节中见过它。以后,我们还要在本章讨论这些遍历策略。
????????构造一棵表达式树
????????现在给出一种算法来把后缀表达式转变成表达式树。由于我们已经有了将中缀表达式转变成后缀表达式的算法,因此我们能够从这两种常用类型的输入生成表达式树。所描述的方法酷似3.2.3节的后缀求值算法。一次一个符号地读入表达式。如果符号是操作数,那么我们就建立一个单节点树并将一个指向它的指针推入栈中。如果符号是操作符,那么我们就从栈中弹出指向两棵树和
的那两个指针(
的先弹出)并形成一棵新的树,该树的根就是操作符,它的左、右儿子分别指向
和
。然后将指向这棵新树的指针压入栈中。
????????来看一个例子。设输入为:
????????a?b + c d e + * *
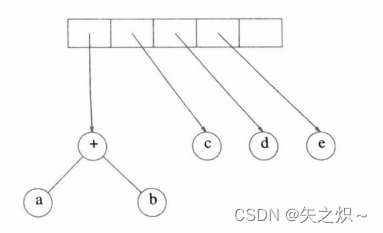
????????前两个符号是操作数,因此我们创建两棵单节点树并将指向它们的指针压入栈中。

接着,读入“+”,因此弹出指向这两棵树的指针,一棵新的树形成,而将指向该树的指针压入栈中。

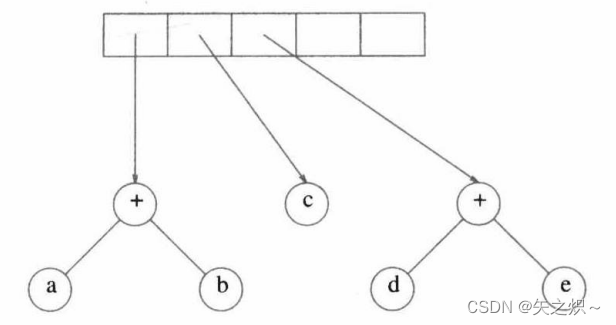
然后,读入c、d和e,在每棵单节点树创建后,将指向对应的树的指针压入栈中。
接下来读入“+”,因此两棵树合并。
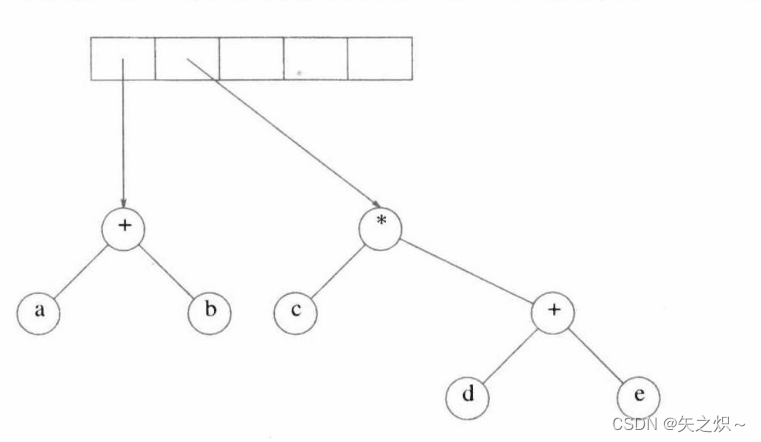
继续进行,读入“×”,因此,弹出两个树指针并形成一棵新的树,“”是它的根。
最后,读入最后一个符号,两棵树合并,而指向最后的树的指针留在栈中。
4.3 查找树ADT——二叉查找树
????????二叉树的一个重要的应用是它们在查找中的使用。假设给树中的每个节点指定一个关键字值。在我们的例子中,虽然任意复杂的关键字都是允许的,但为简单起见,假设它们都是整数。我们还将假设所有的关键字是互异的,以后再处理有重复的情况。
????????使二叉树成为二叉查找树的性质是,对于树中的每个节点X,它的左子树中所有关键字值小于X的关键字值,而它的右子树中所有关键字值大于X的关键字值。注意,这意味着,该树所有的元素可以用某种统一的方式排序。在图4-15中,左边的树是二叉查找树,但右边的树则不是。右边的树在其关键字值是6的节点(该节点正好是根节点)的左子树中,有一个节点的关键字值是7。

????????现在给出通常对二叉查找树进行的操作的简要描述。注意,由于树的递归定义,通常是递归地编写这些操作的例程。因为二叉查找树的平均深度是,所以我们一般不必担心栈空间被用尽。在图4-16中我们重复类型定义并列出函数的一些性质。由于所有的元素都是有序的,因此,虽然对某些类型也许会出现语法错误,但我们还是要假设运算符“<”“>”和“=”可以用于这些元素。
#ifndef _Tree_H
struct TreeNode;
typedef struct TreeNode *Position;
typedef struct TreeNode *SearchTree;
SearchTree MakeEmpty(SearchTree T);
Position Find(ElementType X, SearchTree T);
Position FindMin(SearchTree T);
Position FindMax(SearchTree T);
SearchTree Insert(ElementType X, SearchTree T);
SearchTree Delete(ElementType X, SearchTree T);
ElementType Retrieve(Position P);
#endif /*_Tree_H*/
struct TreeNode
{
ElementType Element;
SearchTree Left;
SearchTree Right;
};4.3.1 MakeEmpty
????????这个操作主要用于初始化。有些程序设计人员更愿意将第一个元素初始化为单节点树,但是,我们的实现方法更紧密地遵循树的递归定义。正如图4-17中显示的,它是一个简单的例程。
SearchTree MakeEmpty(SearchTree T)
{
if (T != NULL)
{
MakeEmpty(T->Left);
MakeEmpty(T->Right);
free(T);
}
return NULL;
}4.3.2 Find
????????这个操作一般需要返回指向树T中具有关键字X的节点的指针, 如果这样的节点不存在则返回NULL。树的结构使得这种操作很简单。如果T是NULL,那么我们可以就返回NULL。否则,如果存储在T中的关键字是X,那么我们可以返回T。否则,我们对树T的左子树或右子树进行一次递归调用,这依赖于X与存储在T中的关键字的关系。图4-18中的代码就是对这种策略的一种体现。
????????注意测试的顺序。关键的问题是首先要对是否为空树进行测试,否则就可能在NULL?指针上兜圈子。其余的测试应该使得最不可能的情况安排在最后进行。还要注意,这里的两个递归调用事实上都是尾递归并且可以很容易地用一次赋值和一个goto语句代替。尾递归的使用在这里是合理的,因为算法表达式的简明性是以速度的降低为代价的,而这里所使用的栈空间也只不过是而已。
Position Find(ElementType X, SearchTree T)
{
if (T == NULL)
return NULL;
if (X < T->Element)
return Find(X, T->Left);
else if (X > T->Element)
return Find(X, T->Right);
else
return T;
}4.3.3 FindMin 和 FindMax
????????这些例程分别返回树中最小元和最大元的位置。虽然返回这些元素的准确值似乎更合理,但是这将与Find操作不相容。重要的是,看起来类似的操作做的工作也是类似的。为执行FindMin,从根开始并且只要有左儿子就向左进行。终止点是最小的元素。FindMax例程除分支朝向右儿子外其余过程相同。
????????这种递归是如此容易以至于许多程序设计员不厌其烦地使用它。我们用两种方法编写这两个例程,用递归编写FindMin,而用非递归编写FindMax(见图4-19和图4-20)。
Position FindMin(SearchTree T)
{
if (T == NULL)
return NULL;
else if (T->Left == NULL)
return T;
else
return FindMin(T->Left);
}
Position FindMax(SearchTree T)
{
if (T != NULL)
while (T->Right != NULL)
T = T->Right;
return T;
}????????注意我们是如何小心地处理空树这种退化情况的。虽然小心总是重要的,但在递归程序中它尤其重要。此外,还要注意,在FindMax中对T的改变是安全的,因为我们只用拷贝来进行工作。不管怎么说,还是应该随时特别小心,因为诸如“T->Right=T->Right->Right”这样的语句将会产生一些变化。
4.3.4 Insert
????????进行插入操作的例程在概念上是简单的。为了将X插入到树T中,你可以像用Find那样沿着树查找。如果找到X,则什么也不用做(或做一些“更新”)。否则,将X插入到遍历的路径上的最后一点上。图4-21显示实际的插入情况。为了插入5,我们遍历该树就像在运行Find一样。在具有关键字4的节点处,我们需要向右行进,但右边不存在子树,因此5不在这棵树上,从而这个位置就是所要插入的位置。

????????重复元的插入可以通过在节点记录中保留一个附加域以指示发生的频率来处理。这使整棵树增加了某些附加空间,但是,却比将重复信息放到树中要好(它将使树的深度变得很大)。当然,如果关键字只是一个更大结构的一部分,那么这种方法行不通,此时我们可以把具有相同关键字的所有结构保留在一个辅助数据结构中,如表或是另一棵查找树中。
SearchTree Insert(ElementType X, SearchTree T)
{
if (T == NULL)
{
T = malloc(sizeof(struct TreeNode));
if (T == NULL)
FatalError("Out of space!!!");
else
{
T->Element = X;
T->Left = T->Right = NULL;
}
}
else if (X < T->Element)
T->Left = Insert(X, T->Left);
else if (X > T->Element)
T->Right = Insert(X, T->Right);
return T;
}????????图4-22显示插入例程的代码。由于T指向该树的根,而根又在第一次插入时变化,因
此将Insert写成一个返回指向新树根的指针的函数。第8行和第10行递归地插入X到适
当的子树中。?
4.3.5 Delete
????????正如许多数据结构一样,最困难的操作是删除。一旦发现要删除的节点,我们就需要考虑几种可能的情况。
????????如果节点是一片树叶,那么可以立即删除。如果节点有一个儿子,则该节点可以在其父节点调整指针绕过该节点后删除(为了清楚起见,我们将明确地画出指针的指向),见图4-23。注意,所删除的节点现在已不再引用,而该节点只有在指向它的指针已被省去的情况下才能删除。
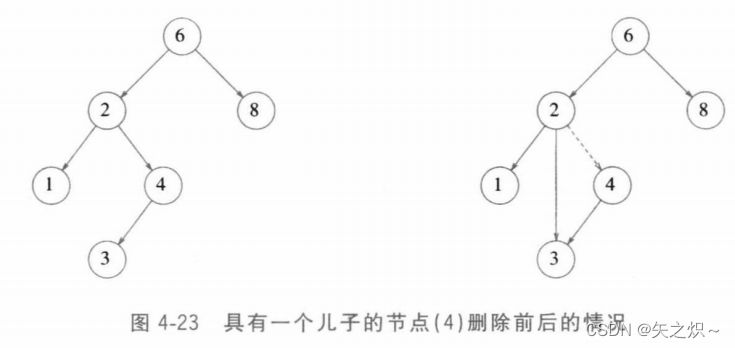
????????复杂的情况是处理具有两个儿子的节点。一般的删除策略是用其右子树中最小的数据(很容易找到)代替该节点的数据并递归地删除那个节点(现在它是空的)。因为右子树中最小的节点不可能有左儿子,所以第二次Delete(删除)更容易。图4-24显示一棵初始的树及其中一个节点被删除后的结果。要删除的节点是根的左儿子;其关键字是2。它被右子树中的最小数据(3)所代替,然后关键字是3的原节点如前例那样删除。?

????????图4-25中的程序完成删除的工作,但它的效率并不高,因为它沿该树进行两趟搜索以
查找和删除右子树中最小的节点。写一个特殊的DeleteMin函数可以容易地改变效率不高
的缺点,我们将它略去只是为了简明紧凑。?
SearchTree Delete(ElementType X, SearchTree T)
{
Position TmpCell;
if (T == NULL)
Error("Element not found");
else if (X < T->Element)
T->Left = Delete(X, T->Left);
else if (X > T->Element)
T->Right = Delete(X, T->Right);
else if (T->Left && T->Right)
{
TmpCell = FindMin(T->Right);
T->Element = TmpCell->Element;
T->Right = Delete(T->Element, T->Right);
}
else
{
TmpCell = T;
if (T->Left == NULL)
T = T->Right;
else if (T->Right == NULL)
T = T->Left;
free(TmpCell);
}
return T;
}????????如果删除的次数不多,则通常使用的策略是懒惰删除(lazy?deletion):当一个元素要被删除时,它仍留在树中,只是做了个被删除的记号。这种做法特别是在有重复关键字时很流行,因为此时记录出现频率数的域可以减1。如果树中的实际节点数和“被删除”的节点数相同,那么树的深度预计只上升一个小的常数。(请读者思考原因。)因此,存在一个与懒惰删除相关的非常小的时间损耗。再有,如果被删除的关键字是重新插入的,那么分配一个新单元的开销就避免了。
4.3.6 平均情形分析
????????直观上,除MakeEmpty外,我们期望前一节所有的操作都花费时间,因为我们用常数时间在树中降低了一层,这样一来,对树的操作大致减少一半左右。因此,除MakeEmpty外,所有的操作都是
的,其中
是包含所访问的关键字的节点的深度。
????????我们在本节要证明,假设所有的树出现的机会均等,则树的所有节点的平均深度为
????????一棵树的所有节点的深度的和称为内部路径长(internal?path?length)。我们现在将要计算二叉查找树平均内部路径长,其中平均是相对于二叉查找树的所有可能的插入序列而言的。
????????令是具有
个节点的某棵树
的内部路径长,
。一棵
节点树是由一棵
节点左子树和一棵
节点右子树以及深度为0的一个根节点组成,其中
,
为根的左子树的内部路径长。但是在原树中,所有这些节点都要加深一度。同样的结论对于右子树也是成立的。因此我们得到递归关系:
如果所有子树的大小都等可能地出现,这对于二叉查找树是成立的(因为子树的大小只依赖于第一个插入到树中的元素的相对的秩),但对于二叉树则不成立,那么和
的
平均值都是。于是

在第7章将遇到并求解这个递归关系,得到的平均值为。因此任意节点的期望深度为
。举一个例子,图4-26展示了随机生成500个节点的树的节点平均深度为9.98。
????????但是,上来就断言这个结果意味着上一节讨论的所有操作的平均运行时间是并不完全正确。原因在于删除操作,我们并不清楚是否所有的二叉查找树都是等可能出现的。特别是上面描述的删除算法有助于使得左子树比右子树深度深,因为我们总是用右子树的一个节点来代替删除的节点。这种策略的准确效果仍然是未知的,但它似乎只是理论上的谜团。已经证明,如果我们交替插入和删除
次,那么树的期望深度将是
。在25万次随机 Insert/Delete后,图4-26中右沉的树看起来明显不平衡(平均深度=12.51),见图4-27。
????????在删除操作中,我们可以通过随机选取右子树的最小元素或左子树的最大元素来代替被删除的元素以消除这种不平衡问题。这种做法明显地消除了上述偏向并使树保持平衡,但是,没有人实际上证明过这一点。这种现象似乎主要是理论上的问题,因为对于小的树上述效果根本显示不出来,甚至更奇怪,如果使用对Insert/Delete,那么树似乎可以得到平衡!
????????上面的讨论主要是说明,明确“平均”意味着什么一般是极其困难的,可能需要一些假设,这些假设可能合理,也可能不合理。不过,在没有删除或是使用懒惰删除的情况下,可以证明所有二叉查找树都是等可能出现的,而且我们可以断言:上述那些操作的平均运行时间都是。除像上面讨论的一些个别情形外,这个结果与实际观察到的情形是非常吻合的。
????????如果向一棵树输入预先排序的数据,那么一连串Insert操作将花费二次时间,而用链表实现Insert的代价会非常巨大,因为此时的树将只由那些没有左儿子的节点组成。一种解决办法就是要有一个称为平衡(balance)的附加的结构条件:任何节点的深度均不得过深。
????????有许多一般的算法可以实现平衡树。但是,大部分算法都要比标准的二叉查找树复杂得多,而且更新要平均花费更长的时间。不过,它们确实防止了处理起来非常麻烦的一些简单情形。下面,我们将介绍最老的一种平衡查找树,即AVL树。
????????另外,较新的方法是放弃平衡条件,允许树有任意的深度,但是在每次操作之后要使用一个调整规则进行调整,使得后面的操作效率更高。这种类型的数据结构一般属于自调整(self-adjusting)类结构。在二叉查找树的情况下,对于任意单个运算我们不再保证的时间界,但是可以证明任意连续M次操作在最坏的情形下花费的时间为
。一般这足以防止令人棘手的最坏情形。我们将要讨论的这种数据结构叫作伸展树(splaytree),它的分析相当复杂,我们将在第11章讨论。
4.4 AVL树
4.4.1 单旋转
4.4.2 双旋转
4.5 伸展树
4.5.1 一个简单的想法
4.5.2 展开
4.6 树的遍历
4.7 B树
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 搭建FTP服务器
- 抽象类和接口的区别
- vite 如何打包 dist 文件到 zip 使用插件 vite-plugin-zip-pack,vue3 ts
- 证件照3秒换底色|有手机就行,一学就会
- NIST随机数统计工具windows版安装及运行
- PySide6/PyQt如何使用QWebEngineView获取网页Cookie
- 剖析setinterval用法
- 【华为OD机试真题2023C&D卷 JAVA&JS】攀登者1
- 【无标题】Linux应用程序中 rpm yum
- facebook广告个人户和企业户的区别