达摩研究院Paraformer-large模型已支持windows
简介
FunASR是一个基础语音识别工具包,提供多种功能,包括语音识别(ASR)、语音端点检测(VAD)、标点恢复、语言模型、说话人验证、说话人分离和多人对话语音识别等。FunASR提供了便捷的脚本和教程,支持预训练好的模型的推理与微调。FunASR开源了大量在工业数据上预训练模型,用户可以在模型许可协议下自由使用、复制、修改和分享FunASR模型。
代表性的模型Paraformer非自回归端到端语音识别模型具有高精度、高效率、便捷部署的优点,支持快速构建语音识别服务。最重要的是,支持标点符号识别、低语音识别、音频-视觉语音识别等功能,也就是说,它不仅可以实现语音转写,还能在转写后进行标注。
Paraformer是达摩院语音团队提出的一种高效的非自回归端到端语音识别框架。本项目为Paraformer中文通用语音识别模型,采用工业级数万小时的标注音频进行模型训练,保证了模型的通用识别效果。模型可以被应用于语音输入法、语音导航、智能会议纪要等场景。
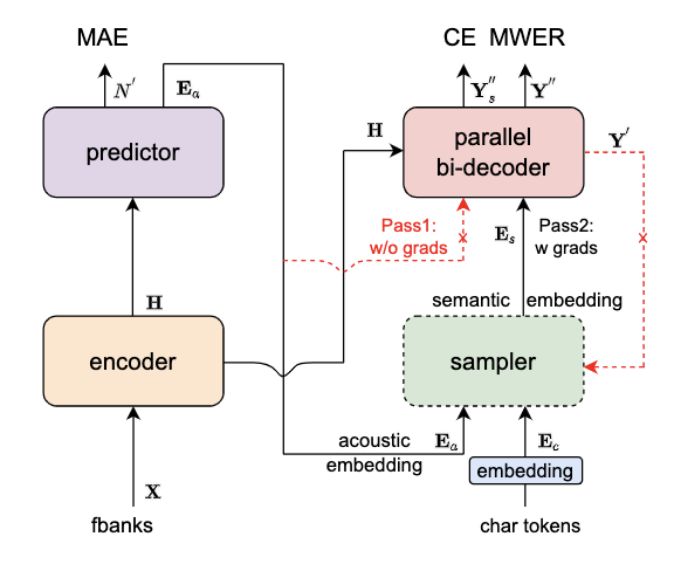
主要核心
1.Predictor 模块:基于 Continuous integrate-and-fire (CIF) 的 预测器 (Predictor) 来抽取目标文字对应的声学特征向量,可以更加准确的预测语音中目标文字个数。2.Sampler:通过采样,将声学特征向量与目标文字向量变换成含有语义信息的特征向量,配合双向的 Decoder 来增强模型对于上下文的建模能力。3.基于负样本采样的 MWER 训练准则。
在本地机器中开发FunASR框架安装
· 安装FunASR和ModelScope,pip3 install -U modelscopegit clone https://github.com/alibaba/FunASR.git && cd FunASRpip3 install -e ./
基于FunASR进行推理
推理支持音频格式如下:
- wav文件路径,例如:data/test/audios/asr_example.wav
- pcm文件路径,例如:data/test/audios/asr_example.pcm
- wav文件url,例如:https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/asr_example_zh.wav
- wav二进制数据,格式bytes,例如:用户直接从文件里读出bytes数据或者是麦克风录出bytes数据。
- 已解析的audio音频,例如:audio, rate = soundfile.read("asr_example_zh.wav"),类型为numpy.ndarray或者torch.Tensor。
- wav.scp文件,需符合如下要求:cat wav.scpasr_example1 data/test/audios/asr_example1.wavasr_example2data/test/audios/asr_example2.wav
识别结果输出路径结构如下:
tree output_dir/output_dir/└── 1best_recog├── rtf├── score└── text1 directory, 3 filesrtf:计算过程耗时统计score:识别路径得分text:语音识别结果文件接下来会以私有数据集为例,介绍如何在FunASR框架中使用Paraformer-large进行推理以及微调。cd egs_modelscope/paraformer/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-pytorchpython demo.py
基于FunASR进行微调
cd egs_modelscope/paraformer/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-pytorchpython finetune.py若修改输出路径、数据路径、采样率、batch_size等配置及使用多卡训练,可参照在Notebook开发中私有数据微调部分的代码,修改finetune.py文件中配置。
使用方式以及适用范围
项目地址https://github.com/alibaba-damo-academy/FunASR
运行范围支持Linux-x86_64、Mac和Windows运行。
使用方式
直接推理:可以直接对输入音频进行解码,输出目标文字。
微调:加载训练好的模型,采用私有或者开源数据进行模型训练。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Kafka - Topic 消费状态常用命令
- TSP(Python):Qlearning求解旅行商问题TSP(提供Python代码)
- 【华为OD真题 Python】多段线数据压缩
- addslashes()函数
- java.lang.UnsupportedOperationException: null 其一解决办法
- CCF模拟_202312-1_仓库规划
- YZ系列工具之YZ04:文本批量替换使用说明文档
- 「用户与社区的深度对话」2023年度IvorySQL满意度调研
- 基于JavaWeb+SSM+Vue周边乡村游小程序系统的设计和实现
- 深入探究 JavaScript 中的 String:常用方法和属性全解析(中)