【头歌系统数据库实验】实验11 SQL互联网业务查询-2
目录
如果对你有帮助的话,不妨点赞收藏评论一下吧,爱你么么哒😘??????
第1关:查询某网站每个日期新用户的次日留存率
任务描述
本关任务:查询某网站每个日期新用户的次日留存率。
相关知识
某网站每天有很多人登录,请你统计一下该网站每个日期新用户的次日留存率。 有一个登录(login)记录表,简况如下:
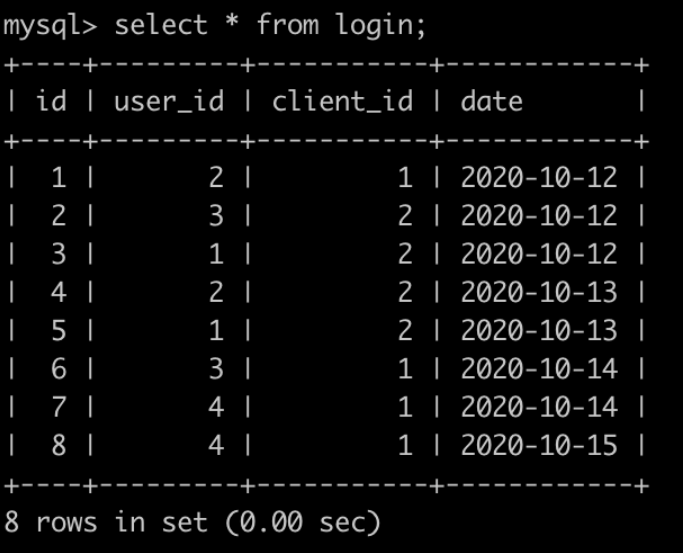
第1行表示user_id为2的用户在2020-10-12使用了客户端id为1的设备登录了该网站,因为是第1次登录,所以是新用户。
第4行表示user_id为2的用户在2020-10-13使用了客户端id为2的设备登录了该网站,因为是第2次登录,所以是老用户。
最后1行表示user_id为4的用户在2020-10-15使用了客户端id为1的设备登录了该网站,因为是第2次登录,所以是老用户。
请你写出一个sql语句查询每个日期新用户的次日留存率,结果保留小数点后面3位数(3位之后的四舍五入),并且查询结果按照日期升序排序,上面的例子查询结果如下:
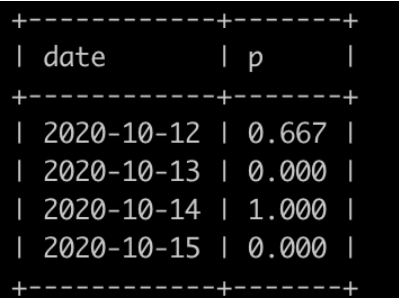
查询结果表明: 2020-10-12登录了3个(user_id为2,3,1)新用户,2020-10-13,只有2个(id为2,1)登录,故2020-10-12新用户次日留存率为2/3=0.667; 2020-10-13没有新用户登录,输出0.000; 2020-10-14登录了1个(user_id为4)新用户,2020-10-15,user_id为4的用户登录,故2020-10-14新用户次日留存率为1/1=1.000; 2020-10-15没有新用户登录,输出0.000; 提示: 1、本题的新用户不是真正的新用户定义,是本题给出的新用户定义。
2、MYSQL里计算日期t2与日期t1差的函数为:datediff(t2,t1)。
3、round(x,y):按y位小数,对x四舍五入。
4、ifnull函数的语法:
ifnull(expression_1,expression_2);
如果expression_1不为NULL,则ifnull函数返回expression_1; 否则返回expression_2的结果。ifnull函数根据使用的上下文返回字符串或数字。如果要返回基于true或false条件的值,而不是null,则应使用if函数。
5、MySQL语句with是 MySQL 8.0中的一个新特性,用于帮助简化复杂查询以及提高查询效率。它是一种临时表的方式,得到的结果集可以作为查询的结果集。在with语句中,可以定义多个别名,然后嵌套使用。
with t1 as (select col1 from table1),t2 as (select col1 from table2)--使用select * from t1 inner join t2 on t1.col1 = t2.col1;
在这个例子中,我们定义了两张表,t1和t2,然后使用了这两张表来进行查询,这样我们就可以避免在查询语句中多次嵌套使用相同的子查询,并且也不需要为每个查询定义一个临时表。
注意2:本次实验切换到了mysql8.0,要注意以下问题: 1、order by的关键字段,要来自select关键字段; 2、group by的关键字段,要和select关键字段一致。
示例1 输入: drop table if exists login; create table login ( id int(4) not null, user_id int(4) not null, client_id int(4) not null, date date not null, primary key (id));
insert into login values (1,2,1,'2020-10-12'), (2,3,2,'2020-10-12'), (3,1,2,'2020-10-12'), (4,2,2,'2020-10-13'), (5,1,2,'2020-10-13'), (6,3,1,'2020-10-14'), (7,4,1,'2020-10-14'), (8,4,1,'2020-10-15');
输出: date p 2020-10-12 0.667 2020-10-13 0.000 2020-10-14 1.000 2020-10-15 0.000
开始你的任务吧,祝你成功!
USE mydata;
#请在此处添加实现代码
########## Begin ##########
select x.date,
#三位小数
round(count(y.user_id)/count(x.user_id),3) as p
from(
select user_id,min(date) as date
from login
group by user_id
)x
#新建一个表
left join login y on x.user_id=y.user_id and
#函数计算两者日期
y.date=date_add(x.date,interval+1 day)
group by x.date
union
#不在小日期
select date,0 as p
from login
where date not in(
select min(date)
from login
group by user_id
)
order by date;
########## End ##########第2关:查询满足条件的用户
任务描述
有的同学会购买网上训练课程来学习,某教育网站对购买记录会产生订单存到数据库,有一个订单信息表(order_info),表的部分内容如下:
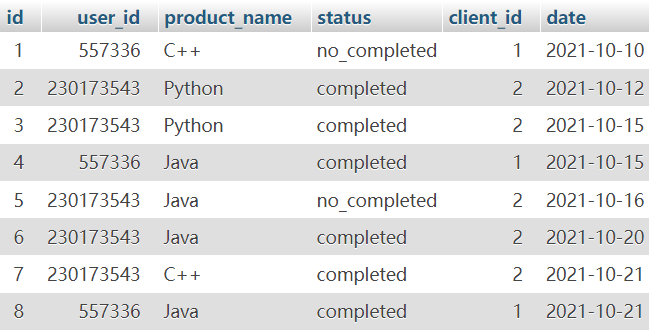
第1行表示user_id为557336的用户在2021-10-10的时候使用了client_id为1的客户端下了C++课程的订单,但是状态为没有购买成功。第2行为购买成功。
查询满足以下条件的用户: 在2021-10-15以后,如果有一个用户下单2个以及2个以上状态为购买成功的C++课程或Java课程或Python课程,那么输出这个用户的user_id,以及满足该条件的第一次购买成功的日期first_buy_date,以及满足前面条件的第二次购买成功的日期second_buy_date,以及购买成功的次数cnt,并且输出结果按照user_id升序排序。
函数提示 1、row_number() over(partition by某字段 order by 某字段):窗口函数按某字段分组,生成从1开始的顺序编号。 2、count(*) over(partition by 某字段):求分组后的总数。
注意,本次实验切换到了mysql8.0,要注意以下问题: 1、order by的关键字段,要来自select关键字段; 2、group by的关键字段,要和select关键字段一致。
开始你的任务吧,祝你成功!
USE mydata;
#请在此处添加实现代码
########## Begin ##########
select user_id,min(case when num=1 then date end) as first_buy_date,max(case when num=2 then date end) as second_buy_date,count(1) as cnt
from (
select*,row_number() over(partition by user_id order by date) as num
from order_info
where status='completed' and date>'2021-10-15' and product_name in ('C++','Java','Python'))v
group by user_id having count(1)>=2;
########## End ##########第3关:查询未完成订单率排名前三的用户
任务描述
有的同学会购买网上训练课程来学习,某教育网站对购买记录会产生订单存到数据库,有一个订单信息表(order_info),表的部分内容如下:
第1行表示user_id为557336的用户在2021-10-10的时候使用了client_id为1的客户端下了C++课程的订单,但是状态为没有购买成功。第2行为购买成功。
查询满足以下条件的用户: 找出双11预热期间,(2021.10.16-2021.10.31),各product_name(要呈现)的用户未完成订单率(%后显示2位小数)排前三名(降序排序,不为0,且用dense_rank函数)的user_id、rnk(名次)、incomp_rate(未完成订单率),并先按product_name升序排序,再按rnk升序排序。
函数提示 1、round(x,y):按y位小数,对x四舍五入。
2、concat(s1,s2...sn):字符串s1,s2等多个字符串合并为一个字符串。
3、dense_rank() over(partition by a字段order by b字段):窗口函数按a字段分组,按b字段排序(缺省升序)生成从1开始数值编号,多值并列但排名仅+1。 (说明:和rank() over 的作用相同,区别在于dense_rank() over 排名是密集连续的。例如学生排名,使用这个函数,成绩相同的两名是并列,下一位同学接着下一个名次。即:1 1 2 3 4 5 5 6)
4、if函数是MySQL中的条件函数之一,用于在满足条件时返回一个值,否则返回另一个值。IF函数的语法如下:
-
if(condition, true_value, false_value)
其中,condition是一个布尔表达式,true_value是满足条件时返回的值,false_value是不满足条件时返回的值。
5、在MySQL中,我们可以使用if和sum函数的组合来实现多条件计算。假设我们有一个名为"orders"的表格,其中包含了订单信息,包括订单ID、客户ID、订单金额amount和订单状态status。现在我们要计算不同状态订单的总金额,可以使用如下的MySQL查询语句:
-
select -
sum(if(status = 'pending', amount, 0)) as pending_amount, -
sum(if(status = 'completed', amount, 0)) as completed_amount, -
sum(if(status = 'canceled', amount, 0)) as canceled_amount -
from -
orders;
6、MySQL语句with是 MySQL 8.0中的一个新特性,用于帮助简化复杂查询以及提高查询效率。它是一种临时表的方式,得到的结果集可以作为查询的结果集。在with语句中,可以定义多个别名,然后嵌套使用。
with t1 as (select col1 from table1),t2 as (select col1 from table2)--使用select * from t1 inner join t2 on t1.col1 = t2.col1;
在这个例子中,我们定义了两张表,t1和t2,然后使用了这两张表来进行查询,这样我们就可以避免在查询语句中多次嵌套使用相同的子查询,并且也不需要为每个查询定义一个临时表。
注意,本次实验切换到了mysql8.0,要注意以下问题: 1、order by的关键字段,要来自select关键字段; 2、group by的关键字段,要和select关键字段一致.
开始你的任务吧,祝你成功!
USE mydata;
#请在此处添加实现代码
########## Begin ##########
SELECT product_name, v.user_id,v.rnk,CONCAT(FORMAT(v.incomp_rate*100, 2), '%') AS incomp_rate
FROM(
SELECT product_name, user_id,
DENSE_RANK() OVER (PARTITION BY product_name ORDER BY SUM(CASE WHEN status = 'no_completed' THEN 1 ELSE 0 END) / COUNT(*) DESC) AS rnk,
ROUND(SUM(CASE WHEN status = 'no_completed' THEN 1 ELSE 0 END) / COUNT(*), 4) AS incomp_rate
FROM order_info
WHERE date BETWEEN '2021-10-16' AND '2021-10-31'
GROUP BY product_name, user_id
HAVING incomp_rate > 0
ORDER BY product_name ASC, rnk ASC
)v
GROUP BY product_name, user_id
HAVING v.rnk<=3
########## End ##########本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 安装nvidia driver出现 the cc vision check falied
- 计算机毕业设计-----SSM宠物商城带后台管理系统
- 光伏行业如何高效起步?选对创业项目是关键!
- 深度学习引领信息检索革新:从传统方法到神经网络信息检索的探索
- 招聘难 ?C++抓取前程招聘财务会计的数据
- 新年送长辈礼物怎么选?华为畅享70 Pro 给长辈的新年贴心机
- 2024通信技术与航空航天工程国际会议(ICCTAE2024)
- pyDAL一个python的ORM(11) pyDAL的连接查询2
- windows系统Mysql备份脚本
- vue3 接入腾讯云验证码(Captcha)后端二次校验