vpp node 及 vpp 多线程
node 注册
node注册,即宏VLIB_REGISTER_NODE(x, ...)流程:
- 创建vlib_node_registration_t x;vlib_node_registration_t结构只是存放了用户提供的node相关信息。
- 把x添加到全局变量vlib_global_main中的node_registrations链表中(从头加)。
- 使用__attribute__ ((__constructor__))修饰,表示为构造函数,会在main函数之前被执行。
- 在main函数中会根据vlib_node_registration_t结构分配vlib_node_t结构,vlib_node_t结构是真正node对应的结构,数据处理流程中访问的也是vlib_node_t结构。
- 函数调用:vlib_main --> vlib_register_all_static_nodes --> vlib_register_node --> vec_add1,函数vlib_register_node中会申请空间并调用函数vec_add1将新分配的节点加入vm->node_main.nodes 数组中,其中node->index 就是该 node 在 vm->node_main.nodes 数组中的索引;
- hash_set (nm->node_by_name, n->name, n->index);以 node 的名称作为 key, index 作为 value 加入 hash 表 node_by_name 中
- 复制 vlib_node_registration_t 结构的各个字段到 vlib_node_t 结构里
- ?error 和 elog 的初始化
- 私有数据runtime_data指针的拷贝,该部分数据由用户提供
node 图的初始化
node图的初始化,即函数vlib_node_main_init处理,在函数vlib_main中被调用。
- VLIB_NODE_MAIN_RUNTIME_STARTED表示node图已经初始化过了。
- 遍历nm->nodes,nm->nodes在节点注册时会有元素加入,判断是否又兄弟节点。
- 如果有兄弟节点,就将该节点index加入到所有的兄弟节点的位图中,同时把所有的兄弟节点的index加入到该节点的位图中。
指定下一个节点的一般步骤
- 根据业务确定下一个节点
- 调用vlib_get_next_frame函数确定下一个节点保存数据包的位置to_next
- 根据业务将数据包给到to_next中
- 执行vlib_put_next_frame函数将下一个node要处理的数据加入到nm->pending_frames
- vlib_main_loop中会在dispatch_pending_node函数中处理pending_node
- 创建 vlib_pending_frame_t 结构,并把它加入数组 vm->node_main. pending_frames 等待调度vlib_pending_frame_t 结构记录报文所在的结构 vlib_next_frame_t 的 index,以及处理这些报文的node 的 vlib_node_runtime_t 结构的索引,这样通过 vlib_pending_frame_t 结构里面的信息就可以把报文分发给指定的 node 处理了
node节点调度
调度类型
老版本中只有主线程中才运行pre_input类型节点,新版本中主线程和worker线程都可以运行pre_input节点

调度方式总结

个人理解:从代码上来看只有Input类型的node节点注册的时候state设置成中断方式,才会出现中断和轮训的切换,默认全是轮询方式。PRE_INPUT类型node只能按照轮询当时来调度。设置成state为中断也是一样的。
中断方式和轮询方式之间切换。
??? 模式切换依据累计报文数量,在vlib_main_or_worker_loop启动中设置。

开启多线程
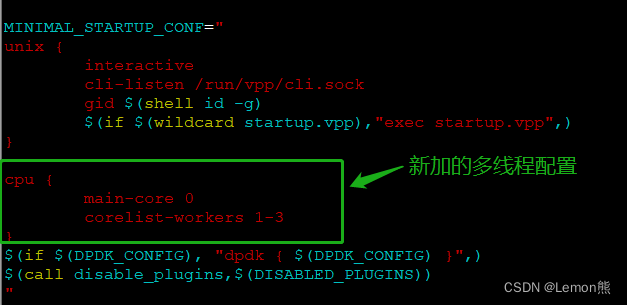
修改配置文件startup.conf,添加下面的内容,表示主线程运行在0核,3个worker线程运行在1-3核。
cpu {
?? main-core 0
?? corelist-workers 1-3
}执行make run不会使用配置文件,是在Makefile文件中指定启动参数,所以需要修改Makefile文件,将开启多线程的配置添加上,如下图
创建接口后就会绑定worker,通过命令show interface rx-placement查看接口收包被分配到那个线程中。
设置对称哈希算法,保证同一个流总是由相同的worker处理,参考https://blog.csdn.net/sina t_20184565/article/details/126923384
set interface handoff host-vpp workers 0-1 symmetrical
set interface handoff vpp1/0 workers 1-1 symmetrical注册线程
使用宏VLIB_REGISTER_THREAD注册。

- 定义vlib_thread_registration_t x,添加到vlib_thread_main的next链表(vlib_thread_registration_t类型指针)
- 函数cpu_config中,解析配置文件确定线程名字和数量,然后对vlib_thread_main.next链表中的元素的coremask和count进行设置。
- 在函数start_workers中根据vlib_thread_main.next链表的元素进行线程的创建。
线程初始化(创建线程)
- 创建线程的函数为start_workers,在文件thread.c中会使用宏VLIB_MAIN_LOOP_ENTER_FUNCTION注册start_workers函数。宏VLIB_MAIN_LOOP_ENTER_FUNCTION会将函数注册到链表vgm->main_loop_enter_function_registrations中,主函数vlib_main中会调用vlib_call_all_main_loop_enter_functions函数统一对注册的函数进行处理,该函数中会遍历vgm->main_loop_enter_function_registrations链表并执行链表中已经注册的函数(start_workers)。
- start_workers函数中会调用vlib_launch_thread_int函数创建线程,即调用函数pthread_create和pthread_setaffinity_np等函数创建线程并设置线程亲核性,线程处理函数为vlib_worker_thread_bootstrap_fn,该函数中会调用vlib_worker_thread_fn函数,该函数中会调到vlib_worker_loop。创建线程个数和线程亲核性由tr->coremask和tr->count决定,tr->coremask为线程和cpu的位图映射,tr->count表示线程数。
- tr->coremask和tr->count的设置:在函数cpu_config中通过解析配置文件内容设置,coremask位表示那个核绑定线程,count为线程总数。
vlib_main_or_worker_loop函数流程
- 初始化nm->pending_frames,记录开始运行时间,初始化运行环境。
- 遍历nm->processes,调用dispatch_process函数处理process类型节点。
- 进入死循环
- m->pending_rpc_requests
- vlib_worker_thread_barrier_check,worker线程和主线程同步操作,会有锁操作
- tm->frame_queue_mains
- 处理pre-input类型节点
- 处理input类型节点
- 处理中断方式触发的input节点,例如xdp的收包节点就是在这里完成调度。
- 遍历pending_frames数组,处理所有internal节点,从input节点或internal节点调度到internal节点一般都是这样调度的。
- 更新循环计数和时间等操作。
接收包队列分配线程
上面提到使用命令show interface rx-placement可以查看接口和线程绑定信息,这条命令的处理函数show_interface_rx_placement_fn中会遍历所有的接口收包队列从而获取每个队列绑定的线程ID,即qptr[0]->thread_index。然后将线程ID对应的线程信息和绑定接口的收包节点信息显示出来。收包队列和线程的绑定在xdp接口创建时完成。
- 函数af_xdp_create_if中会调用af_xdp_finalize_queues函数完成创建收包队列等一系列工作,这里会完成接口收包队列和线程的绑定。
- 函数af_xdp_finalize_queues中会调用函数vnet_hw_if_register_rx_queue分配一个收包队列并分配一个线程完成绑定。
- 函数vnet_hw_if_register_rx_queue中会调用next_thread_index函数分配一个 线程,并将分配的线程id记录到rxq->thread_index。
- 函数next_thread_index中返回vdm->next_worker_thread_index++,vdm->next_worker_thread_index值在vdm->first_worker_thread_index和vdm->last_worker_thread_index区间中。
- vdm->first_worker_thread_index、last_worker_thread_index和next_worker_thread_index的初始化在函数vnet_device_init中完成。
- vdm->first_worker_thread_index = tr->first_index;
- vdm->next_worker_thread_index = tr->first_index;
- vdm->last_worker_thread_index = tr->first_index + tr->count - 1;
- tr->first_index在函数vlib_thread_init中完成初始化,默认值为1
- tr->count在函数cpu_config中解析配置文件被赋值
多线程是怎样收包和处理包的
每个线程都有独立的处理占和数据包缓存空间,同一个数据包不会在多个线程中被处理。
- 创建worker线程时会指定线程处理函数vlib_worker_thread_bootstrap_fn,该函数中会记录当前线程的索引__os_thread_index中,即__os_thread_index = w - vlib_worker_threads,__os_thread_index在后面的流程中会被使用,然后执行每个worker线程的处理函数w->thread_function,worker线程的处理函数为vlib_worker_thread_fn函数,这个函数在注册线程时指定。
- 函数vlib_worker_thread_fn中,首先会根据__os_thread_index值获取每个线程的一个全局结构vm(vlib_main_t ),即vm = vlib_get_main (),后续的所有数据都是从该vm中获取。紧接着会执行vlib_worker_loop函数。
- vlib_worker_loop函数中会执行vlib_main_or_worker_loop函数,该函数中完成了所有节点的调度。其中的node信息和数据包信息都是从全局变量vm中获取的。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 2023国赛 陕西省省级二等奖得主 数学建模学习资源推荐
- 消息队列之堆积问题分析
- C //练习 5-4 编写函数strend(s, t)。如果字符串t出现在字符串s的尾部,该函数返回1;否则返回0。
- 【力扣 2】两数相加 C++题解(链表+模拟+数学)
- Mybatis-Plus基础之Mapper增删改
- ArkTS - @Builder自定义构建函数
- 美易平台:美股芯片股盘前持续走高
- 互联网医院|北京互联网医院成品功能及优势
- zlib.decompressFile报错 【Bug已解决-鸿蒙开发】
- 【Oracle】 Oracle Sequence 性能优化