ansible从入门到精通(完整篇)
文章目录
01 Ansible介绍与安装
1. 介绍 Ansible
1.1 什么是 Ansible?
Ansible是一款自动化运维工具,基于Python开发,集合了众多运维工具(puppet、cfengine、chef、func、fabric)的优点,实现了批量系统配置、批量程序部署、批量运行命令等功能。
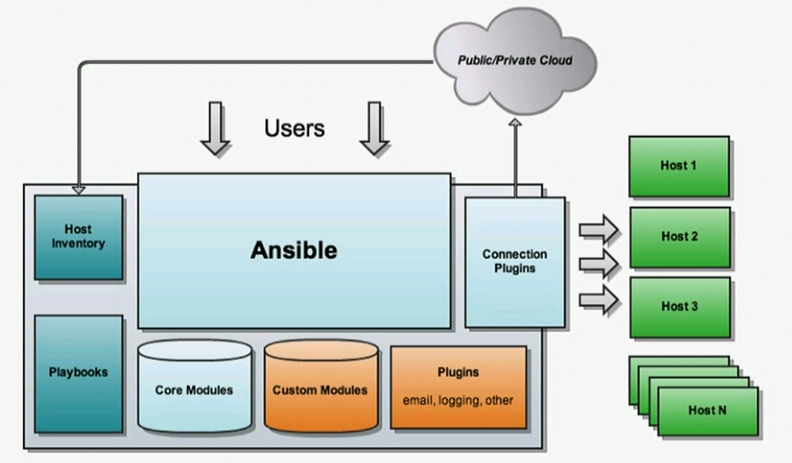
Ansible是基于模块工作的,本身没有批量部署的能力。真正具有批量部署的是Ansible所运行的模块,Ansible只是提供一种框架。主要包括:
(1) 连接插件connection plugins:负责和被监控端实现通信;
(2) host inventory:指定操作的主机,是一个配置文件里面定义监控的主机;
(3) 各种模块核心模块、command模块、自定义模块;
(4) 借助于插件完成记录日志邮件等功能;
(5) playbook:剧本执行多个任务时,非必需可以让节点一次性运行多个任务。
Ansible架构图:

1.2 Ansible 无需代理
Ansible 围绕无代理架构构建。通常而言,Ansible 通过 OpenSSH 或 WinRM 连接它所管理的主机并且运行任务,方法通常是将称为 Ansible 模块的小程序推送至这些主机。这些程序用于将系统置于需要的特定状态。在 Ansible 运行完其任务后,推送的所有模块都会被删除。
Ansible 不需要批准使用任何特殊代理,然后再部署到受管主机上。由于没有代理,也不需要额外的自定义安全基础架构,
Ansible 具有多个重要的优点:
- 跨平台支持:Ansible 提供Linux、Windows、UNIX和网络设备的无代理支持,适用于物理、虚拟、云和容器环境。
- 人类可读的自动化:Ansible Playbook采用YAML文本文件编写,易于阅读,有助于确保所有人都能理解它们的用途。
- 完美描述应用:可以通过 Ansible Playbook进行每种更改,并描述和记录应用环境的每一个方面。
- 轻松管理版本控制:Ansible Playbook和项目是纯文本。它们可以视作源代码,放在现有版本控制系统中。
- 支持动态清单:可以从外部来源动态更新 Ansible 管理的计算机列表,随时获取所有受管服务器的当前正确列表,不受基础架构或位置的影响。
- 编排可与其他系统轻松集成:能够利用环境中现有的 HP SA、Puppet、Jenkins、红帽卫星和其他系统,并且集成到 Ansible 工作流中。
1.3 Ansible 方式
Ansible 的设计宗旨是工具易用,自动化易写易读。所以在创建自动化时我们应追求简单化。
Ansible 自动化语言围绕简单易读的声明性文本文件来构建。正确编写的 Ansible Playbook可以清楚地记录你的工作自动化。
Ansible 是一种要求状态引擎。它通过表达你所希望系统处于何种状态来解决如何自动化IT部署的问题。Ansible 的目标是通过仅执行必要的更改,使系统处于所需的状态。试图将 Ansible 视为脚本语言并非正确的做法。
2. 安装 Ansible
2.1 控制节点
Ansible 易于安装。 Ansible 软件只需要安装到要运行它的一个(或多个)控制节点上。由 Ansible管理的主机不需要安装 Ansible。
对控制节点的要求:
- 控制节点应是Linux或UNIX系统。不支持将Windows用作控制节点,但Windows系统可以是受管主机。
- 控制节点需要安装Python3(版本3.5或以上)或Python2(版本2.7或以上)。
如果操作系统是红帽8.0,Ansible 2.9可以自动使用 platform-python 软件包,该软件包支持使用Python的系统实用程序。你不需要从 AppStream安装python37或python27软件包。
[root@localhost ~]# yum list installed platform-python
Updating Subscription Management repositories.
Unable to read consumer identity
This system is not registered to Red Hat Subscription Management. You can use subscription-manager to register.
Installed Packages
platform-python.x86_64 3.6.8-1.el8.0.1 @anaconda
2.2 受管主机
Ansible的一大优点是受管主机不需要安装特殊代理。Ansible控制节点使用标准的网络协议连接受管主机,从而确保系统处于指定的状态。
受管主机可能要满足一些要求,具体取决于控制节点连接它们的方式以及它们要运行的模块。
Linux和UNIX受管主机需要安装有Python2(版本2.6或以上)或Python3(版本3.5或以上),这样才能运行大部分的模块。
对于红帽8,可以启用并安装python36应用流(或python27应用流)
yum module install python36
如果受管主机上启用了SELinux,还需要确保安装python3-libselinux软件包,然后才能使用与任何复制、文件或模板功能相关的模块。所以在工作的时候,应当把SELinux功能关闭。
2.3 基于Windows的受管主机
Ansible有许多专门为Windows系统设计的模块。这些模块列在https://docs.ansible.com/ansible/latest/modules/list_of_windows_modules.html部分中。
大部分专门为Windows受管主机设计的模块需要在受管主机上安装PowerShell 3.0或更高版本,而不是安装Python。此外,受管主机也需要配置PowerShell远程连接。Ansible还要求至少将.NET Framework 4.0或更高版本安装在Windows受管主机上。
本课程不对Windows受管主机做过多说明,未来在工作当中需要用到时请查阅以上官方文档链接。
2.4 受管网络设备
Ansible还可以配置受管网络设备,例如路由器和交换机。Ansible包含大量专门为此目的而设计的模块。其中包括对Cisco IOS、IOS XR和NX-OS的支持;Juniper Junos;Arsta EOS;以及基于VyOS的网络设备等。
我们可以使用为服务器编写playbook时使用的相同基本技术为网络设备编写Ansible Playbook。由于大多数网络设备无法运行Python,因此Ansible在控制节点上运行网络模块,而不是在受管主机上运行。特殊连接方法也用于与网络设备通信,通常使用SSH上的CLI、SSH上的XML或HTTP(S)上的API。
本课程不对受管网络设备做过多说明,未来在工作当中需要用到时请查阅官方文档链接https://docs.ansible.com/ansible/latest/modules/list_of_network_modules.html。
2.5 安装Ansible
# 提供YUM源
mv /etc/yum.repos.d/* /opt/
curl -o /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-vault-8.5.2111.repo
sed -i -e '/mirrors.cloud.aliyuncs.com/d' -e '/mirrors.aliyuncs.com/d' /etc/yum.repos.d/CentOS-Base.repo
yum clean all
yum makecache
yum -y install centos-release-ansible-29
# 安装ansible
yum -y install ansible
ansible --version
# 通过使用setup模块验证localhost上的ansible_python_version
ansible -m setup localhost|grep ansible_python_version
02 部署Ansible
1. 构建Ansible清单
1.1 定义清单
清单定义Ansible将要管理的一批主机。这些主机也可以分配到组中,以进行集中管理。组可以包含子组,主机也可以是多个组的成员。清单还可以设置应用到它所定义的主机和组的变量。
可以通过两种方式定义主机清单。静态主机清单可以通过文本文件定义。动态主机清单可以根据需要使用外部信息提供程序通过脚本或其他程序来生成。
1.2 使用静态清单指定受管主机
静态清单文件是指定Ansible目标受管主机的文本文件。可以使用多种不同的格式编写此文件,包括INI样式或YAML。
在最简单的形式中。INI样式的静态清单文件是受管主机的主机名或IP地址的列表,每行一个:
alpha.example.org
beta.example.org
192.168.1.100
但通常而言,可以将受管主机组织为主机组。通过主机组,可以更加有效的对一系列系统运行Ansible。这时,每一部分的开头为以中括号括起来的主机组名称。其后为该组中每一受管主机的主机名或IP地址,每行一个。
[webservers]
alpha.example.org
beta.example.org
192.168.1.100
www[001:006].example.com
[dbservers]
db01.intranet.mydomain.net
db02.intranet.mydomain.net
10.25.1.56
db-[99:101]-node.example.com
1.3 验证清单
若有疑问,可使用 ansible 命令验证计算机是否存在于清单中:
[root@localhost ~]# ansible db-99-node.example.com --list-hosts
hosts (1):
db-99-node.example.com
[root@localhost ~]# ansible db-999-node.example.com --list-hosts
[WARNING]: Could not match supplied host pattern, ignoring: db-999-node.example.com
[WARNING]: No hosts matched, nothing to do
hosts (0):
运行以下命令来列出指定组中的所有主机:
[root@localhost ~]# ansible webservers --list-hosts
hosts (2):
alpha.example.org
beta.example.org
192.168.1.100
如果清单中含有名称相同的主机和主机组,ansible 命令将显示警告并以主机作为其目标。主机组则被忽略。
应对这种情况的方法有多种,其中最简单的是确保主机组不使用与清单中主机相同的名称。
1.4 覆盖清单的位置
/etc/ansible/hosts文件被视为系统的默认静态清单文件。不过,通常的做法是不使用该文件,而是在Ansible配置文件中为清单文件定义一个不同的位置。
1.5 构建Ansible清单
修改默认清单文件**/etc/ansible/hosts**添加以下内容:
172.16.103.129
[webservers]
172.16.103.130
172.16.103.131
使用以下命令列出默认清单文件中的所有受管主机:
ansible all --list-hosts
使用以下命令列出不属于任何组的受管主机:
ansible ungrouped --list-hosts
使用以下命令列出属于某组的受管主机:
ansible webservers --list-hosts
1.6 自定义清单文件
在/etc/ansible/目录中,创建一个名为inventory的自定义静态清单文件。
服务器清单规格
| 主机IP | 用途 | 位置 | 运行环境 |
|---|---|---|---|
| 172.16.103.129 | web服务器 | 北京 | 测试 |
| 172.16.103.130 | web服务器 | 上海 | 生产 |
| 172.16.103.131 | 数据库服务器 | 上海 | 生产 |
编辑/etc/ansible/inventory文件,将上表中所列出的主机加入受管主机序列。
[root@localhost ~]# vim /etc/ansible/inventory
[webservers]
172.16.103.129 ansible_user=root ansible_password=your_pass
172.16.103.130 ansible_user=root ansible_password=your_pass
[db-servers]
172.16.103.131 ansible_user=root ansible_password=your_pass
执行以下命令列出所有受管主机:
ansible all -i /etc/ansible/inventory --list-hosts
执行以下命令列出webservers组中的所有受管主机:
ansible webservers -i /etc/ansible/inventory --list-hosts
2. 管理Ansible配置文件
2.1 配置Ansible
可以通过修改 Ansible 配置文件中的设置来自定义 Ansible安装的行为。Ansible从控制节点上多个可能的位置之一选择其配置文件。
使用/etc/ansible/ansible.cfg
ansible软件包提供一个基本的配置文件,它位于**/etc/ansible/ansible.cfg**。如果找不到其他配置文件,则使用此文件。
使用~/.ansible.cfg
Ansible在用户的家目录中查找**.ansible.cfg文件。如果存在此配置文件并且当前工作目录中也没有ansible.cfg文件,则使用此配置取代/etc/ansible/ansible.cfg**。
使用./ansible.cfg
如果执行ansible命令的目录中存在ansible.cfg文件,则使用它,而不使用全局文件或用户的个人文件。这样,管理员可以创建一种目录结构,将不同的环境或项目存储在单独的目录中,并且每个目录包含为独特的一组设置而定制的配置文件。
推荐的做法是在需要运行Ansible命令的目录中创建ansible.cfg文件。此目录中也将包含任何供Ansible项目使用的文件,如清单和playbook。这是用于Ansible配置文件的最常用位置。实践中不常使用**~/.ansible.cfg或/etc/ansible/ansible.cfg**文件
使用ANSIBLE_CONFIG环境变量
我们可以通过将不同的配置文件放在不同的目录中,然后从适当的目录执行Ansible命令,以此利用配置文件。但是,随着配置文件数量的增加,这种方法存在局限性并且难以管理。有一个更加灵活的选项,即通过ANSIBLE_CONFIG环境变量定义配置文件的位置。定义了此变量时,Ansible将使用变量所指定的配置文件,而不用上面提到的任何配置文件。
2.2 配置文件优先级
ANSIBLE_CONFIG环境变量指定的任何文件将覆盖所有其他配置文件。如果没有设置该变量,则接下来检查运行ansible命令的目录中是否有ansible.cfg文件。如果不存在该文件,则检查用户的家目录是否有**.ansible.cfg文件。只有在找不到其他配置文件时,才使用全局/etc/ansible/ansible.cfg文件。如果/etc/ansible/ansible.cfg**配置文件不存在,Ansible包含它使用的默认值。
由于Ansible配置文件可以放入的位置有多种,因此Ansible当前使用哪一个配置文件可能会令人困惑。我们可以运行以下命令来清楚地确认所安装的Ansible版本以及正在使用的配置文件。
ansible --version
Ansible仅使用具有最高优先级的配置文件中的设置。即使存在优先级较低的其他配置文件,其设置也会被忽略,不会与选定配置文件中的设置结合。因此,如果你选择自行创建配置文件来取代全局**/etc/ansible/ansible.cfg**配置文件,就需要将该文件中所有需要的设置复制到自己的用户级配置文件中。用户组配置文件中未定义的设置将保持设为内置默认值,即使已在全局配置文件中设为某个其他值也是如此。
2.3 管理配置文件中的设置
Ansible配置文件由几个部分组成,每一部分含有以键值对形式定义的设置。部分的标题以中括号括起来。对于基本操作,请使用以下两部分:
- [defaults]部分设置Ansible操作的默认值
- [privilege_escalation]配置Ansible如何在受管主机上执行特权升级
例如,下面是典型的ansible.cfg文件:
[defaults]
inventory = ./inventory
remote_user = user
ask_pass = false
[privilege_escalation]
become = true
become_method = sudo
become_user = root
become_ask_pass = false
下表说明了此文件中的指令:
Ansible配置
| 指令 | 描述 |
|---|---|
| inventory | 指定清单文件的路径。 |
| remote_user | 要在受管主机上登录的用户名。如果未指定则使用当前用户名 |
| ask_pass | 是否提示输入SSH密码。如果使用SSH公钥身份验证则可以是false |
| become | 连接后是否自动在受管主机上切换用户(通常切换为root) 这也可以通过play来指定。 |
| become_method | 如何切换用户(通常为sudo,这也是默认设置,但可选择su) |
| become_user | 要在受管主机上切换到的用户(通常是root,这也是默认值) |
| become_ask_pass | 是否需要为become_method提示输入密码。默认为false。 |
2.4 配置连接
Ansible需要知道如何与其受管主机通信。更改配置文件的一个最常见原因是为了控制Ansible使用什么方法和用户来管理受管主机。需要的一些信息包括:
- 列出受管主机和主机组的清单的位置
- 要使用哪一种连接协议来与受管主机通信(默认为SSH),以及是否需要非标准网络端口来连接服务器
- 要在受管主机上使用哪一远程用户;这可以是root用户或者某一非特权用户
- 如果远程用户为非特权用户,Ansible需要知道它是否应尝试将特权升级为root以及如何进行升级(例如,通过sudo)
- 是否提示输入SSH密码或sudo密码以进行登录或获取特权
2.4.1 清单位置
在[defaults]部分中,inventory指令可以直接指向某一静态清单文件,或者指向含有多个静态清单文件和动态清单脚本的某一目录。
[defaults]
inventory = ./inventory
2.4.2 连接设置
默认情况下,Ansible使用SSH协议连接受管主机。控制Ansible如何连接受管主机的最重要参数在[defaults]部分中设置。
默认情况下,Ansible尝试连接受管主机时使用的用户名与运行ansible命令的本地用户相同。若要指定不同的远程用户,请将remote_user参数设置为该用户名。
如果为运行Ansible的本地用户配置了SSH私钥,使得它们能够在受管主机上进行远程用户的身份验证,则Ansible将自动登录。如果不是这种情况,可以通过设置指令ask_pass = true,将Ansible配置为提示本地用户输入由远程用户使用的密码。
【defaults]
inventory = ./inventory
remote_user = root
ask_pass = true
假设在使用一个Linux控制节点,并对受管主机使用OpenSSH,如果可以使用密码以远程用户身份登录,那么我们可以设置基于SSH密钥的身份验证,从而能够设置ask_pass = false。
第一步是确保在**~/.ssh中为控制节点上的用户配置了SSH密钥对。并且使用ssh-copy-id**命令将本地的公钥复制到受管主机中。此过程请参考文章openssh
2.4.3 升级特权
鉴于安全性和审计原因,Ansible可能需要先以非特权用户身份连接远程主机,然后再通过特权升级获得root用户身份的管理权限。这可以在Ansible配置文件的**[privilege_escalation]**部分中设置。
要默认启用特权升级,可以在配置文件中设置指令become = true。即使默认为该设置,也可以在运行临时命令或Ansible Playbook时通过各种方式覆盖它。(例如,有时候可能要运行一些不需要特权升级的任务或play。)
become_method指令指定如何升级特权。有多个选项可用,但默认为使用sudo。类似地,become_user指令指定要升级到的用户,但默认为root。
如果所选的become_method机制要求用户输入密码才能升级特权,可以在配置文件中设置become_ask_pass = true指令。
以下示例ansible.cfg文件假设你可以通过基于SSH密钥的身份验证以someuser用户身份连接受管主机,并且someuser可以使用sudo以root用户身份运行命令而不必输入密码:
[defaults]
inventory = ./inventory
remote_user = someuser
ask_pass = false
[privilege_escalation]
become = true
become_method = sudo
become_user = root
become_ask_pass = false
2.4.4 非SSH连接
默认情况下,Ansible用于连接受管主机的协议设置为smart,它会确定使用SHH的最高效方式。可以通过多种方式将其设置为其他的值。
例如,默认使用SSH的规则有一个例外。如果目录中没有localhost,Ansible将设置一个隐式localhost条目以便允许运行以localhost为目标的临时命令和playbook。这一特殊清单条目不包括在all或ungrouped主机组中。此外,Ansible不使用smart SSH连接类型,而是利用默认的特殊local连接类型来进行连接。
ansible localhost --list-hosts
local连接类型忽略remote_user设置,并且直接在本地系统上运行命令。如果使用特权升级,它会在运行sudo时使用运行Ansible命令的用户,而不是remote_user。如果这两个用户具有不同的sudo特权,这可能会导致混淆。
如果你要确保像其他受管主机一样使用SSH连接localhost,一种方法是在清单中列出它。但是,这会将它包含在all和ungrouped组中,而你可能不希望如此。
另一种方法是更改用于连接localhost的协议。执行此操作的最好方法是为localhost设置ansible_connection主机变量。为此,你需要在运行Ansible命令的目录中创建host_vars子目录。在该子目录中,创建名为localhost的文件,其应含有ansible_connection: smart这一行。这将确保对localhost使用smart(SSH)连接协议,而非local。
你也可以通过另一种变通办法来使用它。如果清单中列有127.0.0.1,则默认情况下,将会使用smart来连接它。也可以创建一个含有ansible_connection: local这一行的host_vars/127.0.0.1文件,它会改为使用local。
2.5 配置文件注释
Ansible配置文件允许使用两种注释字符:井号或分号。
位于行开头的#号会注释掉整行。它不能和指令位于同一行中。
分号字符可以注释掉所在行中其右侧的所有内容。它可以和指令位于同一行中,只要该指令在其左侧。
3. 运行临时命令
使用临时命令可以快速执行单个Ansible任务,不需要将它保存下来供以后再次运行。它们是简单的在线操作,无需编写playbook即可运行。
临时命令对快速测试和更改很有用。例如,可以使用临时命令确保一组服务器上的**/etc/hosts**文件中存在某一特定的行。可以使用另一个临时命令在许多不同的计算机上高效的重启服务,或者确保特定的软件包为最新版本。
临时命令对于通过Ansible快速执行简单的任务非常有用。它们确实也存在局限,而且总体而言,要使用Ansible Playbook来充分发挥Ansible的作用。但在许多情形中,临时命令正是快速执行简单任务所需要的工具。
3.1 运行临时命令
Ansible运行临时命令的语法如下:
ansible host-pattern -m module [-a 'module arguments'] [-i inventory]
host-pattern参数用于指定在其上运行临时命令的受管主机。它可以是清单中的特定受管主机或主机组。也可以用后面的-i选项指定特定的清单而不使用默认清单。
-m选项将Ansible应在目标主机上运行的module名称作为参数。模块是为了实施任务而执行的小程序。一些模块不需要额外的信息,但其他模块需要使用额外的参数来指定其操作详情。-a选项以带引号字符串形式取这些参数的列表。
一种最简单的临时命令使用ping模块。此模块不执行ICMP ping,而是检查能否在受管主机上运行基于Python的模块。例如,以下临时命令确定清单中的所有受管主机能否运行标准的模块:
[root@localhost ~]# ansible all -m ping
172.16.103.131 | SUCCESS => {
"ansible_facts": {
"discovered_interpreter_python": "/usr/bin/python"
},
"changed": false,
"ping": "pong"
}
......
3.2 使用临时命令通过模块来执行任务
模块是临时命令用于完成任务的工具。Ansible提供了数百个能够完成不同任务的模块。通常我们可以查找一个经过测试的专用模块,作为标准安装的一部分来完成所需的任务。
ansible-doc -l命令可以列出系统上安装的所有模块。可以使用ansible-doc来按照名称查看特定模块的帮助文档,再查找关于模块将取什么参数作为选项的信息。例如以下命令显示ping模块的帮助文档,在帮助文档里面输入**q**命令表示退出:
ansible-doc ping
更多的模块信息请访问在线Ansible文档,网址:https://docs.ansible.com/ansible/latest/modules/modules_by_category.html。
Ansible常用模块
| 模块类别 | 模块 |
|---|---|
| 文件模块 | copy:将本地文件复制到受管主机 file:设置文件的权限和其他属性 lineinfile:确保特定行是否在文件中 synchronize:使用rsync同步内容 |
| 软件包模块 | package:使用操作系统本机的自动检测软件包管理器管理软件包 yum:使用yum管理软件包 apt:使用APT管理软件包 dnf:使用dnf管理软件包 gem:管理Ruby gem pip:从PyPI管理Python软件包 |
| 系统模块 | firewalld:使用firewalld管理防火墙 reboot:重启计算机 service:管理服务 user:添加、删除和管理用户帐户 |
| Net Tools模块 | get_url:通过HTTP、HTTPS或FTP下载文件 nmcli:管理网络 uri:与Web服务交互 |
大部分模块会取用参数。可在模块的文档中找到可用于该模块的参数列表。临时命令可以通过-a选项向模块传递参数。无需参数时,可从临时命令中省略-a选项。如果需要指定多个参数,请以引号括起的空格分隔列表形式提供。
例如,以下临时命令使用user模块来确保runtime用户存在于172.16.103.129上并且其UID为4000:
ansible 172.16.103.129 -m user -a 'name=runtime uid=4000 state=present'
大多数模块为idempotent,这表示它们可以安全地多次运行;如果系统已处于正确的状态,它们不会进行任何操作。
3.3 在受管主机上运行任意命令
command模块允许管理员在受管主机的命令行中运行任意命令。要运行的命令通过-a选项指定为该模块的参数。例如,以下命令将对webservers组的受管主机运行hostname命令:
[root@localhost ~]# ansible webservers -m command -a 'hostname'
172.16.103.130 | CHANGED | rc=0 >>
node03-linux.example.com
172.16.103.129 | CHANGED | rc=0 >>
node02-linux.example.com
这条命令为每个受管主机返回两行输出。第一行是状态报告,显示对其运行临时操作的受管主机名称及操作的结果。第二行是使用Ansible command模块远程执行的命令的输出。
若要改善临时命令输出的可读性和解析,管理员可能会发现使对受管主机执行的每一项操作具有单行输出十分有用。使用-o选项以单行格式显示Ansible临时命令的输出。
[root@localhost ~]# ansible webservers -m command -a 'hostname' -o
172.16.103.130 | CHANGED | rc=0 | (stdout) node03-linux.example.com
172.16.103.129 | CHANGED | rc=0 | (stdout) node02-linux.example.com
command模块允许管理员对受管主机快速执行远程命令。这些命令不是由受管主机上的shell加以处理。因此,它们无法访问shell环境变量,也不能执行重定向和管道等shell操作。
在命令需要shell处理的情形中,管理员可以使用shell模块。与command模块类似,可以在临时命令中将要执行的命令作为参数传递给该模块。Ansible随后对受管主机远程执行该命令。与command模块不同的是,这些命令将通过受管主机上的shell进行处理。因此,可以访问shell环境变量,也可以使用重定向和管道等操作。
以下示例演示了command与shell的区别。如果尝试使用这两个模块执行内建的Bash命令set,只有使用shell模块才会成功:
[root@localhost ~]# ansible 172.16.103.129 -m command -a 'set'
172.16.103.129 | FAILED | rc=2 >>
[Errno 2] No such file or directory
[root@localhost ~]# ansible 172.16.103.129 -m shell -a 'set'
172.16.103.129 | CHANGED | rc=0 >>
BASH=/bin/sh
BASHOPTS=cmdhist:extquote:force_fignore:hostcomplete:interactive_comments:progcomp:promptvars:sourcepath
BASH_ALIASES=()
BASH_ARGC=()
BASH_ARGV=()
......
command和shell模块都要求受管主机上安装正常工作的Python。第三个模块是raw,它可以绕过模块子系统,直接使用远程shell运行命令。在管理无法安装Python的系统(如网络路由器)时,可以利用这个模块。它也可以用于将Python安装到主机上。
在大多数情况下,建议避免使用command、shell和raw这三个“运行命令”模块。
其他模块大部分都是幂等的,可以自动进行更改跟踪。它们可以测试系统的状态,在这些系统已处于正确状态时不执行任何操作。相反,以幂等方式使用“运行命令”模块要复杂得多。依靠它们,你更难以确信再次运行临时命令或playbook不会造成意外的失败。当shell或command模块运行时,通常会基于它是否认为影响了计算机状态而报告CHANGED状态。
有时候,“运行命令”模块是有用的工具,也是解决问题的好办法。如果确实需要使用它们,可能最好先尝试用command模块,只有在需要shell或raw模块的特殊功能时才利用它们。
3.4 配置临时命令的连接
受管主机连接和特权升级的指令可以在Ansible配置文件中配置,也可以使用临时命令中的选项来定义。使用临时命令中的选项定义时,它们将优先于Ansible配置文件中配置的指令。下表显示了与各项配置文件指令类同的命令行选项。
Ansible命令行选项
| 配置文件指令 | 命令行选项 |
|---|---|
| inventory | -i |
| remote_user | -u |
| become | —become、-b |
| become_method | –become-method |
| become_user | –become-user |
| become_ask_pass | –ask-become-pass、-K |
在使用命令行选项配置这些指令前,可以通过查询ansible --help的输出来确定其当前定义的值。
ansible --help
03 ansible常用模块
1. ansible常用模块使用详解
ansible常用模块有:
- ping
- yum
- template
- copy
- user
- group
- service
- raw
- command
- shell
- script
ansible常用模块raw、command、shell的区别:
- shell模块调用的/bin/sh指令执行
- command模块不是调用的shell的指令,所以没有bash的环境变量
- raw很多地方和shell类似,更多的地方建议使用shell和command模块。但是如果是使用老版本python,需要用到raw,又或者是客户端是路由器,因为没有安装python模块,那就需要使用raw模块了
2. ansible常用模块之ping
ping模块用于检查指定节点机器是否连通,用法很简单,不涉及参数,主机如果在线,则回复pong
[root@ansible ~]# ansible all -m ping
172.16.103.129 | SUCCESS => {
"changed": false,
"ping": "pong"
}
3. ansible常用模块之command
command模块用于在远程主机上执行命令,ansible默认就是使用command模块。
command模块有一个缺陷就是不能使用管道符和重定向功能。
//查看受控主机的/tmp目录内容
[root@ansible ~]# ansible 172.16.103.129 -a 'ls /tmp'
172.16.103.129 | SUCCESS | rc=0 >>
ansible_Xs1oym
systemd-private-fa034beb13644acfb2aadc35bfe64d46-chronyd.service-cVTNsE
systemd-private-fa034beb13644acfb2aadc35bfe64d46-vgauthd.service-XAgkCm
systemd-private-fa034beb13644acfb2aadc35bfe64d46-vmtoolsd.service-rwqet5
//在受控主机的/tmp目录下新建一个文件test
[root@ansible ~]# ansible 172.16.103.129 -a 'touch /tmp/test'
[WARNING]: Consider using the file module with state=touch rather than running touch. If you need to use command because
file is insufficient you can add warn=False to this command task or set command_warnings=False in ansible.cfg to get rid
of this message.
172.16.103.129 | SUCCESS | rc=0 >>
[root@ansible ~]# ansible 172.16.103.129 -a 'ls /tmp'
172.16.103.129 | SUCCESS | rc=0 >>
ansible_7YD229
systemd-private-fa034beb13644acfb2aadc35bfe64d46-chronyd.service-cVTNsE
systemd-private-fa034beb13644acfb2aadc35bfe64d46-vgauthd.service-XAgkCm
systemd-private-fa034beb13644acfb2aadc35bfe64d46-vmtoolsd.service-rwqet5
test
//command模块不支持管道符,不支持重定向
[root@ansible ~]# ansible 172.16.103.129 -a "echo 'hello world' > /tmp/test"
172.16.103.129 | SUCCESS | rc=0 >>
hello world > /tmp/test
[root@ansible ~]# ansible 172.16.103.129 -a 'cat /tmp/test'
172.16.103.129 | SUCCESS | rc=0 >>
[root@ansible ~]# ansible 172.16.103.129 -a 'ps -ef|grep vsftpd'
172.16.103.129 | FAILED | rc=1 >>
error: unsupported SysV option
Usage:
ps [options]
Try 'ps --help <simple|list|output|threads|misc|all>'
or 'ps --help <s|l|o|t|m|a>'
for additional help text.
For more details see ps(1).non-zero return code
4. ansible常用模块之raw
raw模块用于在远程主机上执行命令,其支持管道符与重定向
//支持重定向
[root@ansible ~]# ansible 172.16.103.129 -m raw -a 'echo "hello world" > /tmp/test'
172.16.103.129 | SUCCESS | rc=0 >>
Shared connection to 172.16.103.129 closed.
[root@ansible ~]# ansible 172.16.103.129 -a 'cat /tmp/test'
172.16.103.129 | SUCCESS | rc=0 >>
hello world
//支持管道符
[root@ansible ~]# ansible 172.16.103.129 -m raw -a 'cat /tmp/test|grep -Eo hello'
172.16.103.129 | SUCCESS | rc=0 >>
hello
Shared connection to 172.16.103.129 closed.
5. ansible常用模块之shell
shell模块用于在受控机上执行受控机上的脚本,亦可直接在受控机上执行命令。
shell模块亦支持管道与重定向。
//查看受控机上的脚本
[root@localhost ~]# ll /scripts/
总用量 4
-rwxr-xr-x 1 root root 52 9月 7 22:49 test.sh
//使用shell模块在受控机上执行受控机上的脚本
[root@ansible ~]# ansible 172.16.103.129 -m shell -a '/bin/bash /scripts/test.sh &> /tmp/test'
172.16.103.129 | SUCCESS | rc=0 >>
[root@ansible ~]# ansible 172.16.103.129 -m shell -a 'cat /tmp/test'
172.16.103.129 | SUCCESS | rc=0 >>
1
2
3
4
5
6
7
8
9
10
6. ansible常用模块之script
script模块用于在受控机上执行主控机上的脚本
[root@ansible ~]# ll /etc/ansible/scripts/
总用量 4
-rw-r--r--. 1 root root 61 9月 8 18:59 a.sh
[root@ansible ~]# ansible 172.16.103.129 -m script -a '/etc/ansible/scripts/a.sh &>/tmp/a'
172.16.103.129 | SUCCESS => {
"changed": true,
"rc": 0,
"stderr": "Shared connection to 172.16.103.129 closed.\r\n",
"stderr_lines": [
"Shared connection to 172.16.103.129 closed."
],
"stdout": "",
"stdout_lines": []
}
//查看受控机上的/tmp/a文件内容
[root@ansible ~]# ansible 172.16.103.129 -m shell -a 'cat /tmp/a'
172.16.103.129 | SUCCESS | rc=0 >>
root:x:0:0:root:/root:/bin/bash
....此处省略N行
jerry:x:1000:1000::/home/jerry:/bin/bash
//由此可见确是在受控机上执行了主控机上的脚本,且输出记录到了受控机上。因为此处 \
//的jerry用户是在受控机上才有的用户
7. ansible常用模块之template
template模块用于生成一个模板,并可将其传输至远程主机上。
//下载一个163的yum源文件并开启此源
[root@ansible ~]# cd /etc/yum.repos.d/
[root@ansible yum.repos.d]# curl -o CentOS7-Base-163.repo http://mirrors.163.com/.help/CentOS7-Base-163.repo
[root@localhost ~]# sed -i 's/\$releasever/7/g' /etc/yum.repos.d/CentOS7-Base-163.repo
[root@localhost ~]# sed -i 's/^enabled=.*/enabled=1/g' /etc/yum.repos.d/CentOS7-Base-163.repo
//将设置好的163源传到受控主机
[root@ansible ~]# ansible 172.16.103.129 -m template -a 'src=/etc/yum.repos.d/CentOS7-Base-163.repo dest=/etc/yum.repos.d/163.repo'
172.16.103.129 | SUCCESS => {
"changed": true,
"checksum": "60b8868e0599489038710c45025fc11cbccf35f2",
"dest": "/etc/yum.repos.d/163.repo",
"gid": 0,
"group": "root",
"md5sum": "5a3e688854d9ceccf327b953dab55b21",
"mode": "0644",
"owner": "root",
"size": 1462,
"src": "/root/.ansible/tmp/ansible-tmp-1536311319.27-78101453778196/source",
"state": "file",
"uid": 0
}
//查看受控机上是否有163源
[root@localhost ~]# ls /etc/yum.repos.d/
163.repo
8. ansible常用模块之yum
yum模块用于在指定节点机器上通过yum管理软件,其支持的参数主要有两个
- name:要管理的包名
- state:要进行的操作
state常用的值:
- latest:安装软件
- installed:安装软件
- present:安装软件
- removed:卸载软件
- absent:卸载软件
若想使用yum来管理软件,请确保受控机上的yum源无异常。
//在受控机上查询看vsftpd软件是否安装
[root@localhost ~]# rpm -qa|grep vsftpd
[root@localhost ~]#
//在ansible主机上使用yum模块在受控机上安装vsftpd
[root@ansible ~]# ansible 172.16.103.129 -m yum -a 'name=vsftpd state=present'
172.16.103.129 | SUCCESS => {
"changed": true,
"msg": "warning: /var/cache/yum/x86_64/7Server/base/packages/vsftpd-3.0.2-22.el7.x86_64.rpm: Header V3 RSA/SHA256 Signature, key ID f4a80eb5: NOKEY\nImporting GPG key 0xF4A80EB5:\n Userid : \"CentOS-7 Key (CentOS 7 Official Signing Key) <security@centos.org>\"\n Fingerprint: 6341 ab27 53d7 8a78 a7c2 7bb1 24c6 a8a7 f4a8 0eb5\n From : http://mirrors.163.com/centos/RPM-GPG-KEY-CentOS-7\n",
"rc": 0,
"results": [
"Loaded plugins: product-id, search-disabled-repos, subscription-manager\nThis system is not registered with an entitlement server. You can use subscription-manager to register.\nResolving Dependencies\n--> Running transaction check\n---> Package vsftpd.x86_64 0:3.0.2-22.el7 will be installed\n--> Finished Dependency Resolution\n\nDependencies Resolved\n\n================================================================================\n Package Arch Version Repository Size\n================================================================================\nInstalling:\n vsftpd x86_64 3.0.2-22.el7 base 169 k\n\nTransaction Summary\n================================================================================\nInstall 1 Package\n\nTotal download size: 169 k\nInstalled size: 348 k\nDownloading packages:\nPublic key for vsftpd-3.0.2-22.el7.x86_64.rpm is not installed\nRetrieving key from http://mirrors.163.com/centos/RPM-GPG-KEY-CentOS-7\nRunning transaction check\nRunning transaction test\nTransaction test succeeded\nRunning transaction\n Installing : vsftpd-3.0.2-22.el7.x86_64 1/1 \n Verifying : vsftpd-3.0.2-22.el7.x86_64 1/1 \n\nInstalled:\n vsftpd.x86_64 0:3.0.2-22.el7 \n\nComplete!\n"
]
}
//查看受控机上是否安装了vsftpd
[root@localhost ~]# rpm -qa|grep vsftpd
vsftpd-3.0.2-22.el7.x86_64
9. ansible常用模块之copy
copy模块用于复制文件至远程受控机。
[root@ansible ~]# ls /etc/ansible/scripts/
a.sh
[root@ansible ~]# ansible 172.16.103.129 -m copy -a 'src=/etc/ansible/scripts/a.sh dest=/scripts/'
172.16.103.129 | SUCCESS => {
"changed": true,
"checksum": "83f66f804c195247885b013912cf9dc649f36391",
"dest": "/scripts/a.sh",
"gid": 0,
"group": "root",
"md5sum": "a63e880a932bba1160f329836cbfd730",
"mode": "0644",
"owner": "root",
"size": 61,
"src": "/root/.ansible/tmp/ansible-tmp-1536406467.26-35192956264311/source",
"state": "file",
"uid": 0
}
[root@ansible ~]# ansible 172.16.103.129 -m shell -a 'ls /scripts/'
172.16.103.129 | SUCCESS | rc=0 >>
a.sh
test.sh
10. ansible常用模块之group
group模块用于在受控机上添加或删除组。
//在受控机上添加一个系统组,其gid为306,组名为mysql
[root@ansible ~]# ansible 172.16.103.129 -m group -a 'name=mysql gid=306 state=present'
172.16.103.129 | SUCCESS => {
"changed": true,
"gid": 306,
"name": "mysql",
"state": "present",
"system": false
}
[root@ansible ~]# ansible 172.16.103.129 -m shell -a 'grep mysql /etc/group'
172.16.103.129 | SUCCESS | rc=0 >>
mysql:x:306:
//删除受控机上的mysql组
[root@ansible ~]# ansible 172.16.103.129 -m group -a 'name=mysql state=absent'
172.16.103.129 | SUCCESS => {
"changed": true,
"name": "mysql",
"state": "absent"
}
[root@ansible ~]# ansible 172.16.103.129 -m shell -a 'grep mysql /etc/group'
172.16.103.129 | FAILED | rc=1 >>
non-zero return code
11. ansible常用模块之user
user模块用于管理受控机的用户帐号。
//在受控机上添加一个系统用户,用户名为mysql,uid为306,设置其shell为/sbin/nologin,无家目录
[root@ansible ~]# ansible 172.16.103.129 -m user -a 'name=mysql uid=306 system=yes create_home=no shell=/sbin/nologin state=present'
172.16.103.129 | SUCCESS => {
"changed": true,
"comment": "",
"create_home": false,
"group": 306,
"home": "/home/mysql",
"name": "mysql",
"shell": "/sbin/nologin",
"state": "present",
"system": true,
"uid": 306
}
[root@ansible ~]# ansible 172.16.103.129 -m shell -a 'grep mysql /etc/passwd'
172.16.103.129 | SUCCESS | rc=0 >>
mysql:x:306:306::/home/mysql:/sbin/nologin
[root@ansible ~]# ansible 172.16.103.129 -m shell -a 'ls /home'
172.16.103.129 | SUCCESS | rc=0 >>
jerry
//修改mysql用户的uid为366
[root@ansible ~]# ansible 172.16.103.129 -m user -a 'name=mysql uid=366'
172.16.103.129 | SUCCESS => {
"append": false,
"changed": true,
"comment": "",
"group": 306,
"home": "/home/mysql",
"move_home": false,
"name": "mysql",
"shell": "/sbin/nologin",
"state": "present",
"uid": 366
}
[root@ansible ~]# ansible 172.16.103.129 -m shell -a 'grep mysql /etc/passwd'
172.16.103.129 | SUCCESS | rc=0 >>
mysql:x:366:306::/home/mysql:/sbin/nologin
//删除受控机上的mysql用户
[root@ansible ~]# ansible 172.16.103.129 -m user -a 'name=mysql state=absent'
172.16.103.129 | SUCCESS => {
"changed": true,
"force": false,
"name": "mysql",
"remove": false,
"state": "absent"
}
[root@ansible ~]# ansible 172.16.103.129 -m shell -a 'grep mysql /etc/passwd'
172.16.103.129 | FAILED | rc=1 >>
non-zero return code
12. ansible常用模块之service
service模块用于管理受控机上的服务。
//查看受控机上的vsftpd服务是否启动
[root@ansible ~]# ansible 172.16.103.129 -m shell -a 'systemctl is-active vsftpd'
172.16.103.129 | FAILED | rc=3 >>
unknownnon-zero return code
//启动受控机上的vsftpd服务
[root@ansible ~]# ansible 172.16.103.129 -m service -a 'name=vsftpd state=started'
172.16.103.129 | SUCCESS => {
"changed": true,
"name": "vsftpd",
"state": "started",
"status": {
"ActiveEnterTimestampMonotonic": "0",
....此处省略N行
}
//查看受控机上的vsftpd服务是否启动
[root@ansible ~]# ansible 172.16.103.129 -m shell -a 'systemctl is-active vsftpd'
172.16.103.129 | SUCCESS | rc=0 >>
active
//查看受控机上的vsftpd服务是否开机自动启动
[root@ansible ~]# ansible 172.16.103.129 -m shell -a 'systemctl is-enabled vsftpd'
172.16.103.129 | FAILED | rc=1 >>
disablednon-zero return code
//设置受控机上的vsftpd服务开机自动启动
[root@ansible ~]# ansible 172.16.103.129 -m service -a 'name=vsftpd enabled=yes'
172.16.103.129 | SUCCESS => {
"changed": true,
"enabled": true,
"name": "vsftpd",
"status": {
"ActiveEnterTimestamp": "六 2018-09-08 00:02:39 EDT",
....此处省略N行
}
//查看受控机上的vsftpd服务是否开机自动启动
[root@ansible ~]# ansible 172.16.103.129 -m shell -a 'systemctl is-enabled vsftpd'
172.16.103.129 | SUCCESS | rc=0 >>
enabled
//停止受控机上的vsftpd服务
[root@ansible ~]# ansible 172.16.103.129 -m service -a 'name=vsftpd state=stopped'
172.16.103.129 | SUCCESS => {
"changed": true,
"name": "vsftpd",
"state": "stopped",
"status": {
"ActiveEnterTimestamp": "六 2018-09-08 00:02:39 EDT",
....此处省略N行
}
[root@ansible ~]# ansible 172.16.103.129 -m shell -a 'systemctl is-active vsftpd'
172.16.103.129 | FAILED | rc=3 >>
inactivenon-zero return code
[root@ansible ~]# ansible 172.16.103.129 -m shell -a 'ss -antl'
172.16.103.129 | SUCCESS | rc=0 >>
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 0 128 *:22 *:*
LISTEN 0 100 127.0.0.1:25 *:*
LISTEN 0 128 :::22 :::*
LISTEN 0 100 ::1:25 :::*
04 playbook
1. 实施playbook
1.1 Ansible Playbook与临时命令
临时命令可以作为一次性命令对一组目标主机运行一项简单的任务。不过,若要真正发挥Ansible的力量,需要了解如何使用playbook以便轻松重复的方式对一组目标主机执行多项复杂的任务。
play是针对清单中选定的主机运行的一组有序任务。playbook是一个文本文件,其中包含由一个或多个按特定顺序运行的play组成的列表。
Play可以将一系列冗长而复杂的手动管理任务转变为可轻松重复的例程,并且具有可预测的成功成果。在playbook中,可以将play内的任务序列保存为人类可读并可立即运行的形式。根据任务的编写方式,任务本身记录了部署应用或基础架构所需的步骤。
1.2 格式化Ansible Playbook
前面我们学习了临时命令模块,下面以一条命令做为案例来讲解下其在playbook中是如何编写的。
ansible 172.16.103.129 -m user -a 'name=runtime uid=4000 state=present'
这个任务可以将其编写为一个单任务的play并保存在playbook中。生成的playbook如下方所示:
---
- name: Configure important user consistently
hosts: 172.16.103.129
task:
- name: runtime exists with UID 4000
user:
name: runtime
uid: 4000
state: present
Playbook是以YAML格式编写的文本文件,通常使用扩展名yml保存。Playbook使用空格字符缩进来表示其数据结构。YAML对用于缩进的空格数量没有严格的要求,但有两个基本的规则:
- 处于层次结构中同一级别的数据元素(例如同一列表中的项目)必须具有相同的缩进量。
- 如果项目属于其他项目的子项,其缩进量必须大于父项
只有空格字符可用于缩进,不允许使用tab键。约定俗成的缩进量一般是一级2个空格。
Playbook开头的一行由三个破折号(—)组成,这是文档开始标记。其末尾可能使用三个圆点(…)作为文档结束标记,尽管在实践中这通常会省略。
在这两个标记之间,会以一个play列表的形式来定义playbook。YAML列表中的项目以一个破折号加空格开头。例如,YAML列表可能显示如下:
- apple
- orange
- grape
Play本身是一个键值对集合。同一play中的键应当使用相同的缩进量。以下示例显示了具有三个键的YAML代码片段。前两个键具有简单的值。第三个将含有三个项目的列表作为值。
- name: just an example
hosts: webservers
tasks:
- first
- second
- third
作为play中的一部分,tasks属性按顺序实际列出要在受管主机上运行的任务。列表中各项任务本身是一个键值对集合。
还以上面创建用户的play为例,play中唯一任务有两个键:
- name是记录任务用途的可选标签。最好命名所有的任务,从而帮助记录自动流程中的每一步用途。
- user是要为这个任务运行的模块。其参数作为一组键值对传递,它们是模块的子项(name、uid和state)。
下面再来看一个含有多项任务的tasks属性案例:
tasks:
- name: web server is enabled
service:
name: httpd
enabled: true
- name: NTP server is enabled
service:
name: chronyd
enabled: true
- name: Postfix is enabled
service:
name: postfix
enabled: true
playbook中play和任务列出的顺序很重要,因为Ansible会按照相同的顺序运行它们。
1.3 运行playbook
absible-playbook命令可用于运行playbook。该命令在控制节点上执行,要运行的playbook的名称则作为参数传递。
ansible-playbook site.yml
在运行playbook时,将生成输出来显示所执行的play和任务。输出中也会报告执行的每一项任务的结果。
以下示例中显示了一个简单的playbook的内容,后面是运行它的结果。
[root@localhost ~]# mkdir playdemo
[root@localhost ~]# cd playdemo/
[root@localhost playdemo]# vim webserver.yml
---
- name: play to setup web server
hosts: webservers
tasks:
- name: latest httpd version installed
yum:
name: httpd
state: latest
- name: service is enabled
service:
name: httpd
enabled: true
[root@localhost playdemo]# ansible-playbook webserver.yml
PLAY [play to setup web server] *****************************************************
TASK [Gathering Facts] **************************************************************
ok: [172.16.103.129]
ok: [172.16.103.130]
TASK [latest httpd version installed] ***********************************************
ok: [172.16.103.129]
ok: [172.16.103.130]
TASK [service is enabled] ***********************************************************
changed: [172.16.103.129]
changed: [172.16.103.130]
PLAY RECAP **************************************************************************
172.16.103.129 : ok=3 changed=1 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
172.16.103.130 : ok=3 changed=1 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
请注意,在playbook运行时,屏幕中会显示每个play和任务的name键的值。(Gathering Facts任务是一项特别的任务,setup模块通常在play启动时自动运行这项任务。)对于含有多个play和任务的playbook,设置name属性后可以更加轻松地监控playbook执行的进展。
通常而言,Ansible Playbook中的任务是幂等的,而且能够安全地多次运行playbook。如果目标受管主机已处于正确的状态,则不应进行任何更改。如果再次运行这个playbook,所有任务都会以状态OK传递,且不报告任何更改。
1.4 提高输出的详细程度
ansible-playbook命令提供的默认输出不提供详细的任务执行信息。ansible-playbook -v命令提供了额外的信息,总共有四个级别。
配置Playbook执行的输出详细程序
| 选项 | 描述 |
|---|---|
| -v | 显示任务结果 |
| -vv | 任务结果和任务配置都会显示 |
| -vvv | 包含关于与受管主机连接的信息 |
| -vvvv | 增加了连接插件相关的额外详细程序选项,包括受管主机上用于执行脚本的用户以及所执行的脚本 |
1.5 语法验证
在执行playbook之前,最好要进行验证,确保其内容的语法正确无误。ansible-playbook命令提供了一个–syntax-check选项,可用于验证playbook的语法。
下例演示了一个playbook成功通过语法验证:
[root@localhost playdemo]# ansible-playbook --syntax-check webserver.yml
playbook: webserver.yml
语法验证失败时,将报告语法错误。输出中包含语法问题在playbook中的大致位置。
下例演示了一个playbook语法验证失败的情况:
[root@localhost playdemo]# ansible-playbook --syntax-check webserver.yml
Syntax Error while loading YAML.
did not find expected '-' indicator
The error appears to be in '/root/playdemo/webserver.yml': line 3, column 1, but may
be elsewhere in the file depending on the exact syntax problem.
The offending line appears to be:
- name: play to setup web server
hosts: webservers
^ here
1.6 执行空运行
可以使用-C选项对playbook执行空运行。这会使Ansible报告在执行该playbook时将会发生什么更改,但不会对受管主机进行任何实际的更改。
下例演示了一个playbook的空运行,它包含单项任务,可确保在受管主机上安装了最新版本的httpd软件包。注意该空运行报告此任务会对受管主机产生的更改。
ansible-playbook -C webserver.yml
2. 实施多个play
2.1 缩写多个play
Playbook是一个YAML文件,含有由一个或多个play组成的列表。记住一个play按顺序列出了要对清单中的选定主机执行的任务。因此,如果一个playbook中有多个play,每个play可以将其任务应用到单独的一组主机。
在编排可能涉及对不同主机执行不同任务的复杂部署时,这会大有帮助。我们可以这样进行编写:对一组主机运行一个play,完成后再对另一组主机运行另一个play。
缩写包含多个play的playbook非常简单。Playbook中的各个play编写为playbook中的顶级列表项。各个play是含有常用play关键字的列表项。
以下示例显示了含有两个play的简单playbook。第一个play针对172.16.103.129运行,第二个play则针对172.16.103.131运行。
---
# This is a simple playbook with two plays
- name: first play
hosts: 172.16.103.129
tasks:
- name: first task
yum:
name: httpd
status: present
- name: second task
service:
name: httpd
enabled: true
- name: second play
hosts: 172.16.103.131
tasks:
- name: first task
service:
name: mariadb
enabled: true
2.2 play中的远程用户和特权升级
Play可以将不同的远程用户或特权升级设置用于play,取代配置文件中指定的默认设置。这些在play本身中与hosts或tasks关键字相同的级别上设置。
2.2.1 用户属性
playbook中的任务通常通过与受管主机的网络连接来执行。与临时命令相同,用于任务执行的用户帐户取决于Ansible配置文件/etc/ansible/ansible.cfg中的不同关键字。运行任务的用户可以通过remote_user关键字来定义。不过,如果启用了特权升级,become_user等其他关键字也会发生作用。
如果用于任务执行的Ansible配置中定义的远程用户不合适,可以通过在play中使用remote_user关键字覆盖。
remote_user: remoteuser
2.2.2 特权升级属性
Ansible也提供额外的关键字,从而在playbook内定义特权升级参数。become布尔值关键字可用于启用或禁用特权升级,无论它在Ansible配置文件中的定义为何。它可取yes或true值来启用特权升级,或者取no或false值来禁用它。
become: true
如果启用了特权升级,则可以使用become_method关键字来定义特定play期间要使用的特权升级方法。
以下示例中指定sudo用于特权升级:
become_method: sudo
此外,启用了特权升级时,become_user关键字可定义特定play上下文内要用于特权升级的用户帐户。
become_user: privileged_user
以下示例演示了如何在play中使用这些关键字:
- name: /etc/hosts is up to date
hosts: 172.16.103.129
remote_user: automation
become: yes
tasks:
- name: 172.16.103.129 in /etc/hosts
lineinfile:
path: /etc/hosts
line: '172.16.103.129 web1.example.com'
state: present
2.3 查找用于任务的模块
2.3.1 模块文档
Ansible随附打包的大量模块为管理员提供了许多用于常见管理任务的工具。前面我们介绍了Ansible官方网站的帮助文档链接https://docs.ansible.com/。通过模块索引,可以很轻松的找到对应的模块。例如,适用于用户和服务管理的模块可以在Systems Modules下找到,而适合数据库管理的模块则可在Database Modules下找到。
对于每一个模块,Ansible官网提供了其功能摘要,以及关于如何通过模块的选项来调用各项具体功能的说明。文档还提供了实用的示例,演示各个模块的用法,以及任务中关键字的设置方法。
前面我们用到过ansible-doc -l命令。这将显示模块名称列表以及其功能的概要。
ansible-doc -l
使用ansible-doc [module name]命令来显示模块的详细文档。与Ansible官网一样,该命令提供模块功能的概要、其不同选项的详细信息,以及示例。
ansible-doc yum # 显示yum模块的帮助文档
ansible-doc命令还提供-s选项,它会生成示例输出,可以充当如何在playbook在使用特定模块的示范。此输出可以作为起步模板,包含在实施该模块以执行任务的playbook中。输出中包含的注释,提醒管理员各个选项的用法。下例演示了yum模块的这种输出:
ansible-doc -s yum
使用ansible-doc命令可以查找和了解如何使用模块。尽管command、shell和raw模块的用法可能看似简单,但在可能时,应尽量避免在playbook中使用它们因为它们可以取胜任意命令,因此使用这些模块时很容易写出非幂等的playbook。
例如,以下使用shell模块的任务为非幂等。每次运行play时,它都会重写/etc/resolv.conf,即使它已经包含了行nameserver 172.16.103.2。
- name: Non-idepotent approach with shell module
shell: echo "nameserver 172.16.103.2" > /etc/resolv.conf
可以通过多种方式编写以幂等方式使用shell模块的任务,而且有时候进行这些更改并使用shell是最佳的做法。但更快的方案或许是使用ansible-doc发现copy模块,再使用它获得所需的效果。
在以下示例中,如果/etc/resolv.conf文件已包含正确的内容,则不会重写该文件:
- name: Idempotent approach with copy module
copy:
dest: /etc/resolv.conf
content: "nameserver 172.16.103.2\n"
copy模块可以测试来了解是否达到了需要的状态,如果已达到,则不进行任何更改。shell模块容许非常大的灵活性,但需要格外小心,从而确保它以幂等方式运行。
幂等的playbook可以重复运行,确保系统处于特定的状态,而不会破坏状态已经正确的系统。
2.3.2 Playbook语法变化
YAML注释
注释也可以用于提高可读性。在YAML中,编号或井号字符(#)右侧的所有内容都是注释。如果注释的左侧有内容,请在该编号符号的前面加一个空格。
# This is a YAML comment
some data # This is also a YAML comment
YAML字符串
YAML中的字符串通常不需要放在引号里,即使字符串中包含空格。字符串可以用双引号或单引号括起。
this is a string
'this is another string'
"this is yet another a string"
编写多行字符串有两种方式。可以使用管道符表示要保留字符串中的换行字符。
include_newlines: |
Example Company
123 Main Street
Atlanta, GA 30303
要编写多行字符串,还可以使用大于号字符来表示换行字符转换成空格并且行内的引导空白将被删除。这种方法通常用于将很长的字符串在空格字符处断行,使它们跨占多行来提高可读性。
fold_newlines: >
This is an example
of a long string,
that will become
a single sentence once folded.
YAML字典
下面是一个简单的字典形式:
name: svcrole
svcservice: httpd
svcport: 80
字典也可以使用以大括号括起的内联块格式编写,如下所示:
{name: svcrole, svcservice: httpd, svcport: 80}
大多数情况下应避免内联块格式,因为其可读性较低。不过,至少有一种情形中会较常使用它。当playbook中包含角色列表时,较常使用这种语法,从而更加容易区分play中包含的角色和传递给角色的变量。
YAML列表
最简单的列表如下:
hosts:
- servera
- serverb
- serverc
列表也有以中括号括起的内联格式,如下所示:
hosts: [servera, serverb, serverc]
我们应该避免使用此语法,因为它通常更难阅读。
2.3.3 过时的“键=值” playbook简写
某些playbook可能使用较旧的简写方法,通过将模块的键值对放在与模块名称相同的行上来定义任务。例如,你可能会看到这种语法:
tasks:
- name: shorthand form
service: name=httpd enabled=true state=started
通常我们应该将这样的语法编写为如下所示:
tasks:
- name: normal form
service:
name: httpd
enabled: true
state: started
通常我们应避免简写形式,而使用普通形式。
普通形式的行数较多,但更容易操作。任务的关键字垂直堆叠,更容易区分。阅读play时,眼睛直接向一扫视,左右运动较少。而且,普通语法是原生的YAML。
你可能会在文档和他人提供的旧playbook中看到这种语法,而且这种语法仍然可以发挥作用。
05 管理变量、机密和事实
1. 管理变量
1.1 Ansible变量简介
Ansible支持利用变量来存储值,并在Ansible项目的所有文件中重复使用这些值。这可以简化项目的创建和维护,并减少错误的数量。
通过变量,可以轻松地在Ansible项目中管理给定环境的动态值。例如,变量可能包含下面这些值:
- 要创建的用户
- 要安装的软件包
- 要重新启动的服务
- 要删除的文件
- 要从互联网检索的存档
1.1.1 命名变量
变量的名称必须以字母开头,并且只能包含字母、数字和下划线。
无效和有效的Ansible变量名称示例
| 无效的变量名称 | 有效的变量名称 |
|---|---|
| web server | web_server |
| remote.file | remote_file |
| 1st file | file_1 file1 |
| remoteserver$1 | remote_server_1 remote_server1 |
1.1.2 定义变量
可以在Ansible项目中的多个位置定义变量。不过,这些变量大致可简化为三个范围级别:
- 全局范围:从命令行或Ansible配置设置的变量
- Play范围:在play和相关结构中设置的变量
- 主机范围:由清单、事实收集或注册的任务,在主机组和个别主机上设置的变量
如果在多个xeklh定义了相同名称的变量,则采用优先级别最高的变量。窄范围优先于更广泛的范围:由清单定义的变量将被playbook定义的变量覆盖,后者将被命令行中定义的变量覆盖。
1.2 playbook中的变量
变量在Ansible Playbook中发挥着重要作用,因为它们可以简化playbook中变量数据的管理。
1.2.1 在Playbook中定义变量
编写playbook时,可以定义自己的变量,然后在任务中调用这些值。例如,名为web_package的变量可以使用值httpd来定义。然后,任务可以使用yum模块调用该变量来安装httpd软件包。
Playbook变量可以通过多种方式定义。一种常见的方式是将变量放在playbook开头的vars块中:
- hosts: all
vars:
user: joe
home: /home/joe
也可以在外部文件中定义playbook变量。此时不使用playbook中的vars块,可以改为使用vars_files指令,后面跟上相对于playbook位置的外部变量文件名称列表:
- hosts: all
vars_files:
- vars/users.yml
而后,可以使用YAML格式在这一/这些文件中定义playbook变量:
user: joe
home: /home/joe
1.2.2 在Playbook中使用变量
声明了变量后,可以在任务中使用这些变量。若要引用变量,可以将变量名放在双大括号内。在任务执行时,Ansible会将变量替换为其值。
vars:
user: joe
tasks:
# This line will read: Creates the user joe
- name: Creates the user {{ user }}
user:
# This line will create the user named joe
name: "{{ user }}"
注意:当变量用作开始一个值的第一元素时,必须使用引号。这可以防止Ansible将变量引用视为YAML字典的开头。
1.3 主机变量和组变量
直接应用于主机的清单变量分为两在类:
- 主机变量,应用于特定主机
- 组管理,应用于一个主机组或一组主机组中的所有主机
主机变量优先于组变量,但playbook中定义的变量的优先级比这两者更高。
若要定义主机变量和组变量,一种方法是直接在清单文件中定义。这是较旧的做法,不建议采用,但你可能会在未来的工作当中遇到。
定义172.16.103.129的ansible_user主机变量:
[servers]
172.16.103.129 ansible_user=joe
定义servers主机组的user组变量:
[servers]
172.16.103.129
172.16.103.130
[servers:vars]
user=joe
定义servers组的user组变量,该组由两个主机组成,每个主机组有两个服务器:
[servers1]
node1.example.com
node2.example.com
[servers2]
node3.example.com
node4.example.com
[servers:children]
servers1
servers2
[servers:vars]
user=joe
此做法存在一些缺点,它使得清单文件更难以处理,在同一文件中混合提供了主机和变量信息,而且采用的也是过时的语法。
1.3.1 使用目录填充主机和组变量
定义主机和主机组的变量的首选做法是在与清单文件或目录相同的工作目录中,创建group_vars和host_vars两个目录。这两个目录分别包含用于定义组变量和主机变量的文件。
建议的做法是使用host_vars和group_vars目录定义清单变量,而不直接在清单文件中定义它们。
为了定义用于servers组的组变量,需要创建名为group_vars/servers的YAML文件,然后该文件的内容将使用与playbook相同的语法将变量设置为值:
user: joe
类似的,为了定义用于特定主机的主机变量,需要在host_vars目录中创建名称与主机匹配的文件来存放主机变量。
下面的示例更加详细的说明了这一做法。例如在一个场景中,需要管理两个数据中心,并在~/project/inventory清单文件中定义数据中心主机:
[root@localhost ~]# mkdir ~/project
[root@localhost ~]# vim ~/project/inventory
[datacenter1]
node1.example.com
node2.example.com
[datacenter2]
node3.example.com
node4.example.com
[datacenters:children]
datacenter1
datacenter2
如果需要为两个数据中心的所有服务器定义一个通用值,可以为datacenters主机组设置一个组变量:
[root@localhost ~]# mkdir ~/project/groupo_vars
[root@localhost ~]# vim ~/project/groupo_vars/datacenters
package: httpd
如果要为每个数据中心定义不同的值,可以为每个数据中心主机组设置组变量:
[root@localhost ~]# vim ~/project/groupo_vars/datacenter1
package: httpd
[root@localhost ~]# vim ~/project/groupo_vars/datacenter2
package: apache2
如果要为每一数据中心的各个主机定义不同的值,则在单独的主机变量文件中定义变量:
[root@localhost ~]# mkdir ~/project/host_vars
[root@localhost ~]# vim ~/project/host_vars/node1.example.com
package: httpd
[root@localhost ~]# vim ~/project/host_vars/node2.example.com
package: apache2
[root@localhost ~]# vim ~/project/host_vars/node3.example.com
package: mariadb-server
[root@localhost ~]# vim ~/project/host_vars/node4.example.com
package: mysql-server
以上示例项目project的目录结构如果包含上面所有示例文件,将如下所示:
[root@localhost ~]# tree ~/project
/root/project
├── ansible.cfg
├── group_vars
│ ├── datacenters
│ ├── datacenters1
│ └── datecenters2
├── host_vars
│ ├── node1.example.com
│ ├── node2.example.com
│ ├── node3.example.com
│ └── node4.example.com
├── inventory
└── playbook.yml
2 directories, 10 files
1.4 从命令行覆盖变量
清单变量可被playbook中设置的变量覆盖,这两种变量又可通过在命令行中传递参数到ansible或ansible-playbook命令来覆盖。在命令行上设置的变量称为额外变量。
当需要覆盖一次性运行的playbook的变量的已定义值时,额外变量非常有用。例如:
ansible-playbook main.yml -e "package=apache2"
1.5 使用数组作为变量
除了将同一元素相关的配置数据(软件包列表、服务列表和用户列表等)分配到多个变量外,也可以使用数组。这种做法的一个好处在于,数组是可以浏览的。
例如,假设下列代码片段:
user1_first_name: Bob
user1_last_name: Jones
user1_home_dir: /users/bjones
user2_first_name: Anne
user2_last_name: Cook
user2_home_dir: /users/acook
这将可以改写成名为users的数组:
users:
bjones:
first_name: Bob
last_name: jones
home_dir: /users/bjones
acook:
first_name: Anne
last_name: Cook
home_dir: /users/acook
然后可以使用以下变量来访问用户数据:
# Returns 'Bob'
users.bjones.first_name
# Returns '/users/acook'
users.acook.home_dir
由于变量被定义为Python字典,因此可以使用替代语法:
# Returns 'Bob'
users['bjones']['first-name']
# Returns '/users/acook'
users['acook']['home_dir']
如果键名与python方法或属性的名称(如discard、copy和add)相同,点表示法可能会造成问题。使用中括号表示法有助于避免冲突和错误。
但要声明的是,上面介绍的两种语法都有效,但为了方便故障排除,建议在任何给定Ansible项目的所有文件中一致地采用一种语法,不要混用。
1.6 使用已注册变量捕获命令输出
可以使用register语句捕获命令输出。输出保存在一个临时变量中,然后在playbook中可用于调试用途或者达成其他目的,例如基于命令输出的特定配置。
以下playbook演示了如何为调试用途捕获命令输出:
---
- name: Installs a package and prints the result
hosts: all
tasks:
- name: Install the package
yum:
name: httpd
state: installed
register: install_result
- debug: var=install_result
运行该playbook时,debug模块用于将install_result注册变量的值转储到终端。
[root@localhost ~]# ansible-playbook playbook.yml
PLAY [Installs a package and prints the result] *************************************
TASK [Gathering Facts] **************************************************************
ok: [172.16.103.129]
TASK [Install the package] **********************************************************
ok: [172.16.103.129]
TASK [debug] ************************************************************************
ok: [172.16.103.129] => {
"install_result": {
"changed": false,
"failed": false,
"msg": "",
"rc": 0,
"results": [
"httpd-2.4.6-93.el7.centos.x86_64 providing httpd is already installed"
]
}
}
PLAY RECAP **************************************************************************
t129 : ok=3 changed=0 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
2. 管理机密
2.1 Ansible Vault
Ansible可能需要访问密码或API密钥等敏感数据,以便能配置受管主机。通常,此信息可能以纯文本形式存储在清单变量或其他Ansible文件中。但若如此,任何有权访问Ansible文件的用户或存储这些Ansible文件的版本控制系统都能够访问此敏感数据。这显示存在安全风险。
Ansible提供的Ansible Vault可以加密和解密任何由Ansible使用的结构化数据文件。若要使用Ansible Vault,可通过一个名为ansible-vault的命令行工具创建、编辑、加密、解密和查看文件。Ansible Vault可以加密任何由Ansible使用的结构化数据文件。这可能包括清单变量、playbook中含有的变量文件、在执行playbook时作为参数传递的变量文件,或者Ansible角色中定义的变量。
2.1.1 创建加密的文件
要创建新的加密文件,可使用ansible-vault create filename命令。该命令将提示输入新的vault密码,然后利用默认编辑器vi打开文件。我们可以设置和导出EDITOR环境变量,通过设置和导出指定其他默认编辑器。例如,若要将默认编辑器设为nano,可设置为export EDITOR=nano。
[root@localhost ~]# ansible-vault create secret.yml
New Vault password: redhat
Confirm New Vault password: redhat
我们还可以用vault密码文件来存储vault密码,而不是通过标准输入途径输入vault密码。这样做需要使用文件权限和其他方式来严密保护该文件。
ansible-vault create --vault-password-file=vault-pass secret.yml
2.1.2 查看加密的文件
可以使用ansible-vault view filename命令查看Ansible Vault加密的文件,而不必打开它进行编辑。
ansible-vault view secret.yml
查看时需要输入加密文件的加密密码。
2.1.3 编辑现有的加密文件
要编辑现有的加密文件,Ansible Vault提供了ansible-vault edit filename命令。此命令将文件解密为一个临时文件,并允许编辑。保存时,它将复制其内容并删除临时文件。
ansible-vault edit secret.yml
编辑时需要输入加密文件的加密密码。
edit子命令始终重写文件,因此只应在进行更改时使用它。要查看文件的内容而不进行更改时,应使用view子命令。
2.1.4 加密现有的文件
要加密已存在的文件,请使用ansible-vault encrypt filename命令。此命令可取多个欲加密文件的名称作为参数。
ansible-vault encrypt secret1.yml secret2.yml
使用**–output=OUTPUT_FILE选项,可将加密文件保存为新的名称。只能通过–output**选项使用一个输入文件。
2.1.5 解密现有的文件
现有的加密文件可以通过ansible-vault decrypt filename命令永久解密。在解密单个文件时,可使用**–output**选项以其他名称保存解密的文件。
ansible-vault decrypt secret1.yml --output=secret1-decrypted.yml
2.1.6 更改加密文件的密码
使用ansible-vault rekey filename命令更改加密文件的密码。此命令可一次性更新多个数据文件的密钥。它将提示提供原始密码和新密码。
ansible-vault rekey secret.yml
在使用vault密码文件时,请使用–new-vault-password-file选项:
ansible-vault rekey --new-vault-password-file=NEW_VAULT_PASSWORD_FILE secret.yml
2.2 playbook和ansible vault
要运行可访问通过Ansible Vault加密的文件的playbook,需要向ansible-playbook命令提供加密密码。如果不提供密码,playbook将返回错误:
[root@localhost ~]# ansible-playbook site.yml
ERROR: A Vault password must be specified to decrypt vars/api_key.yml
要为playbook提供vault密码,可使用–vault-id选项。例如,要以交互方式提供vault密码,请使用下例中所示的–vault-id @prompt:
ansible-playbook --vault-id @prompt site.yml
此外,也可使用–vault-password-file选项指定以纯文本存储加密密码的文件。密码应当在该文件中存储为一行字符串。由于该文件包含敏感的纯文本密码,因此务必要通过文件权限和其他安全措施对其加以保护。
ansible-playbook --vault-password-file=vault-pw-file site.yml
也可以使用ANSIBLE_VAULT_PASSWORD_FILE环境变量,指定密码文件的默认位置。
从Ansible2.4开始,可以通过ansible-playbook使用多个Ansible Vault密码。要使用多个密码,需要将多个**–vault-id或–vault-password-file选项传递给ansible-playbook**命令。
ansible-playbook --vault-id one@prompt --vault-id two@prompt site.yml
注意:@prompt前面的vaultIDone和two可以是任何字符,甚至可以完全省略它们。不过,如果在使用ansible-vault命令加密文件时使用**–vault-id id选项,则在运行ansible-playbook时,将最先尝试匹配ID的密码。如果不匹配,将会尝试用户提供的其他密码。没有ID的vaultID@prompt实际上是default@prompt的简写,这意味着提示输入vaultIDdefault**的密码。
2.2.1 变量文件管理的推荐做法
若要简化管理,务必要设置Ansible项目,使敏感变量和其他变量保存在相互独立的文件中。然后,包含敏感变量的文件可通过ansible-vault命令进行保护。
管理组变量和主机变量的首选方式是在playbook级别上创建目录。group_vars目录通常包含名称与它们所应用的主机组匹配的变量文件。host_vars目录通常包含名称与它们所应用的受管主机名称匹配的变量文件。
不过,除了使用group_vars和host_vars中的文件外,也可对每一主机组或受管主机使用目录。这些目录可包含多个变量文件,它们都由该主机组或受管主机使用。例如,在playbook.yml的以下项目目录中,webservers的主机组的成员将使用group_vars/webservers/vars文件中的变量,而172.16.103.129将使用host_vars/172.16.103.129/vars和host_vars/172.16.103.129/vault中的变量:
.
├── ansible.cfg
├── group_vars
│ └── webservers
│ └── vars
├── host_vars
│ └── 172.16.103.129
│ ├── vars
│ └── vault
├── inventory
└── playbook.yml
在这种情况中,其好处在于用于172.16.103.129的大部分变量可以放在vars文件中,敏感变量则可单独放在vault文件中保密。然后使用ansible-vault加密vault文件,而将vars文件保留为纯文本。
在本例中,host_vars/172.16.103.129目录内使用的文件名没有什么特别之处。该目录可以包含更多文件,一些由Ansible Vault加密,另一些则不加密。
Playbook变量(与清单变量相对)也可通过Ansible Vault保护。敏感的playbook变量可以放在单独的文件中,此文件通过Ansible Vault加密,并能vars_files指令包含在该playbook中。这也是推荐做法,因为playbook变量的优先级高于清单变量。
如果需要在playbook中使用多个vault密码,请确保每个加密文件分配一个vaultID,并在运行playbook时输入具有该vaultID的匹配密码。这可确保在解密vault加密文件时先选择正确的密码,这比强制Ansible尝试用户提供的所有vault密码直至找到正确的密码要快。
3. 管理事实
3.1 描述Ansible事实
Ansible事实是Ansible在受管主机上自动检测到的变量。事实中包含有与主机相关的信息,可以像play中的常规变量、条件、循环或依赖于从受管主机收集的值的任何其他语句那样使用。
为受管主机收集的一些事实可能包括:
- 主机名称
- 内核版本
- 网络接口
- IP地址
- 操作系统版本
- 各种环境变量
- CPU数量
- 提供的或可用的内存
- 可用磁盘空间
借助事实,可以方便地检索受管主机的状态,并根据该状态确定要执行的操作。例如:
- 可以根据含有受管主机当前内核版本的事实运行条件任务,以此来重启服务器
- 可以根据通过事实报告的可用内存来自定义MySQL配置文件
- 可以根据事实的值设置配置文件中使用的IPv4地址
通常,每个play在执行第一个任务之前会先自动运行setup模块来收集事实。
查看为受管主机收集的事实的一种方式是,运行一个收集事实并使用debug模块显示ansible_facts变量值的简短playbook。
- name: Fact dump
hosts: all
tasks:
- name: Print all facts
debug:
var: ansible_facts
运行该playbook时,事实将显示在作业输出中:
ansible-playbook facts.yml
Playbook以JSON格式显示ansible_facts变量的内容。
下表显示了可能从受管节点收集的并可在playbook中使用的一些事实:
Ansible事实的示例
| 事实 | 变量 |
|---|---|
| 短主机名 | ansible_facts[‘hostname’] |
| 完全限定域名 | ansible_facts[‘fqdn’] |
| IPv4地址 | ansible_facts[‘default_ipv4’][‘address’] |
| 所有网络接口的名称列表 | ansible_facts[‘interfaces’] |
| /dev/vda1磁盘分区的大小 | ansible_facts[‘devices’][‘vda’][‘partitions’][‘vda1’][‘size’] |
| DNS服务器列表 | ansible_facts[‘dns’][‘nameservers’] |
| 当前运行的内核版本 | ansible_facts[‘kernel’] |
如果变量的值为散列/字典类型,则可使用两种语法来获取其值。比如:
- ansible_facts[‘default_ipv4’][‘address’]也可以写成ansible_facts.default_ipv4.address
- ansible_facts[‘dns’][‘nameservers’]也可以写成ansible_facts.dns.nameservers
在playbook中使用事实时,Ansible将事实的变量名动态替换为对应的值:
---
- hosts: all
tasks:
- name: Prints various Ansible facts
debug:
msg: >
The default IPv4 address of {{ ansible_facts.fqdn }}
is {{ ansible_facts.default_ipv4.address }}
3.2 Ansible事实作为变量注入
在Ansible2.5之前,事实是作为前缀为字符串ansible_的单个变量注入,而不是作为ansible_facts变量的一部分注入。例如,ansible_facts[‘distribution’]事实会被称为ansible_distribution。
许多较旧的playbook仍然使用作为变量注入的事实,而不是在ansible_facts变量下创建命名空间的新语法。我们可以使用临时命令来运行setup模块,以此形式显示所有事实的值。以下示例中使用一个临时命令在受管主机172.16.103.129上运行setup模块:
ansible 172.16.103.129 -m setup
选定的Ansible事实名称比较
| ansible_facts形式 | 旧事实变量形式 |
|---|---|
| ansible_facts[‘hostname’] | ansible_hostname |
| ansible_facts[‘fqdn’] | ansible_fqdn |
| ansible_facts[‘default_ipv4’][‘address’] | ansible_default_ipv4[‘address’] |
| ansible_facts[‘interfaces’] | ansible_interfaces |
| ansible_facts[‘devices’][‘vda’][‘partitions’][‘vda1’][‘size’] | ansible_devices[‘vda’][‘partitions’][‘vda1’][‘size’] |
| ansible_facts[‘dns’][‘nameservers’] | ansible_dns[‘nameservers’] |
| ansible_facts[‘kernel’] | ansible_kernel |
目前,Ansible同时识别新的事实命名系统(使用ansible_facts)和旧的2.5前“作为单独变量注入的事实”命名系统。
将Ansible配置文件的**[default]部分中inject_facts_as_vars参数设置为False**,可关闭旧命名系统。默认设置目前为True。
inject_facts_as_vars的默认值在Ansible的未来版本中可能会更改为False。如果设置为False,则只能使用新的**ansible_facts.***命名系统引用Ansible事实。所以建议大家一开始就要适应这种方式。
3.3 关闭事实收集
有时我们不想为play收集事实。这样做的原因可能有:
- 不准备使用任何事实
- 希望加快play速度
- 希望减小play在受管主机上造成的负载
- 受管主机因为某种原因无法运行setup模块
- 需要安装一些必备软件后再收集事实
以上种种原因导致我们可能想要永久或暂时关闭事实收集的功能,要为play禁用事实收集功能,可将gather_facts关键字设置为no:
---
- name: This play gathers no facts automatically
hosts: large_farm
gather_facts: no
即使play设置了gather_facts: no,也可以随时通过运行使用setup模块的任务来手动收集事实:
---
- name: gather_facts
hosts: 172.16.103.129
gather_facts: no
tasks:
- name: get gather_facts
setup:
- name: debug
debug:
var: ansible_facts
3.4 创建自定义事实
除了使用系统捕获的事实外,我们还可以自定义事实,并将其本地存储在每个受管主机上。这些事实整合到setup模块在受管主机上运行时收集的标准事实列表中。它们让受管主机能够向Ansible提供任意变量,以用于调整play的行为。
自定义事实可以在静态文件中定义,格式可为INI文件或采用JSON。它们也可以是生成JSON输出的可执行脚本,如同动态清单脚本一样。
有了自定义事实,我们可以为受管主机定义特定的值,供play用于填充配置文件或有条件地运行任务。动态自定义事实允许在play运行时以编程方式确定这些事实的值,甚至还可以确定提供哪些事实。
默认情况下,setup模块从各受管主机的**/etc/ansible/facts.d目录下的文件和脚本中加载自定义事实。各个文件或脚本的名称必须以.fact**结尾才能被使用。动态自定义事实脚本必须输出JSON格式的事实,而且必须是可执行文件。
以下是采用INI格式编写的静态自定义事实文件。INI格式的自定义事实文件包含由一个部分定义的顶层值,后跟用于待定义的事实的键值对:
[packages]
web_package = httpd
db_package = mariadb-server
[users]
user1 = joe
user2 = jane
同样的事实可能以JSON格式提供。以下JSON事实等同于以上示例中INI格式指定的事实。JSON数据可以存储在静态文本文件中,或者通过可执行脚本输出到标准输出:
{
"packages": {
"web_package": "httpd",
"db_package": "mariadb-server"
},
"users": {
"user1": "joe",
"user2": "jane"
}
}
自定义事实文件不能采用playbook那样的YAML格式。JSON格式是最为接近的等效格式。
自定义事实由setup模块存储在ansible_facts.ansible_local变量中。
事实按照定义它们的文件的名称来整理。例如,假设前面的自定义事实由受管主机上保存为**/etc/ansible/facts.d/custom.fact**的文件生成。在这种情况下,ansible_facts.ansible_local[‘custom’][‘users’][‘user1’]的值为joe。
可以利用临时命令在受管主机上运行setup模块来检查自定义事实的结构。
ansible 172.16.103.129 -m setup
自定义事实的使用方式与playbook中的默认事实相同:
---
- hosts: all
tasks:
- name: Prints various Ansible facts
debug:
msg: >
The package to install on {{ ansible_facts['fqdn'] }}
is {{ ansible_facts['ansible_local']['cutstom']['packages']['web_package'] }}
3.5 使用魔法变量
一些变量并非事实或通过setup模块配置,但也由Ansible自动设置。这些魔法变量也可用于获取与特定受管主机相关的信息。
最常用的有四个:
| 魔法变量 | 说明 |
|---|---|
| hostvars | 包含受管主机的变量,可以用于获取另一台受管主机的变量的值。 如果还没有为受管主机收集事实,则它不会包含该主机的事实。 |
| group_names | 列出当前受管主机所属的所有组 |
| groups | 列出清单中的所有组和主机 |
| inventory_hostname | 包含清单中配置的当前受管主机的主机名称。 因为各种原因有可能与事实报告的主机名称不同 |
另外还有许多其他的“魔法变量”。有关更多信息,请参见以下链接:
https://docs.ansible.com/ansible/latest/user_guide/playbooks_variables.html#variable-precedence-where-should-i-put-a-variable。
若要深入了解它们的值,一个途径是使用debug模块报告特定主机的hostvars变量的内容:
ansible 172.16.103.129 -m debug -a 'var=hostvars["localhost"]'
06 实施任务控制
1. 编写循环和条件任务
1.1 利用循环迭代任务
通过利用循环,我们无需编写多个使用同一模块的任务。例如,他们不必编写五个任务来确保存在五个用户,而是只需编写一个任务来对含有五个用户的列表迭代,从而确保它们都存在。
Ansible支持使用loop关键字对一组项目迭代任务。可以配置循环以利用列表中的各个项目、列表中各个文件的内容、生成的数字序列或更为复杂的结构来重复任务。
1.1.1 简单循环
简单循环对一组项目迭代任务。loop关键字添加到任务中,将应对其迭代任务的项目列表取为值。循环变量item保存每个迭代过程中使用的值。
请思考以下代码片段,它使用两次service模块来确保两个网络服务处于运行状态:
- name: Postfix is running
service:
name: postfix
state: started
- name: Devecot is running
service:
name: dovecot
state: started
这两个任务可以重新编写为使用一个简单循环,从而只需一个任务来确保两个服务都在运行:
- name: Postfix and Devecot are running
service:
name: "{{ item }}"
state: started
loop:
- postfix
- dovecot
可以通过一个变量提供loop所使用的列表。在以下示例中,变量mail_services含有需要处于运行状态的服务的列表。
vars:
mail_services:
- postfix
- dovecot
tasks:
- name: Postfix and Dovecot are running
service:
name: "{{ item }}"
state: started
loop: "{{ mail_services }}"
1.1.2 循环散列或字典列表
loop列表不需要是简单值列表。在以下示例中,列表中的每个项实际上是散列或字典。示例中的每个散列或字典具有两个键,即name和groups,当前item循环变量中每个键的值可以分别通过item.name和item.groups变量来检索。
- name: Users exist and are in the correct groups
user:
name: "{{ item.name }}"
state: present
groups: "{{ item.groups }}"
loop:
- name: jane
groups: wheel
- name: joe
groups: root
这一示例中结果是用户jane存在且为组wheel的成员,并且用户joe存在且为组root的成员。
1.1.3 较早样式的循环关键字
在Ansible2.5之前,大多数playbook使用不同的循环语法。提供了多个循环关键字,前缀为whth_,后面跟Ansible查找插件的名称。这种循环语法在现有playbook中很常见,但在将来的某个时候可能会被弃用。
较早样式的Ansible循环
| 循环关键字 | 描述 |
|---|---|
| with_items | 行为与简单列表的loop关键字相同,例如字符串列表或散列/字典列表。 但与loop不同的是,如果为with_items提供了列表的列表, 它们将被扁平化为单级列表。循环变量item保存每次迭代过程中使用的列表项。 |
| with_file | 此关键字需要控制节点文件名列表。循环变量item在每次迭代过程中保存文件列表中相应文件的内容。 |
| with_sequence | 此关键字不需要列表,而是需要参数来根据数字序列生成值列表。 循环变量item在每次迭代过程中保存生成的序列中的一个生成项的值。 |
playbook中的with_items的示例如下所示:
vars:
data:
- user0
- user1
- user2
tasks:
- name: "with_items"
debug:
msg: "{{ item }}"
with_items: "{{ data }}"
从Ansible2.5开始,建议使用loop关键字编写循环。
1.1.4 将Register变量与Loop一起使用
register关键字也可以捕获循环任务的输出。以下代码片段显示了循环任务中register变量的结构:
[root@localhost ~]# vim loop_register.yml
---
- name: Loop Register Test
gather_facts: no
hosts: 172.16.103.129
tasks:
- name: Looping Echo Task
shell: "echo This is my item: {{ item }}"
loop:
- one
- two
register: echo_results # 注册echo_results变量
- name: Show echo_results variable
debug:
var: echo_results # echo_results变量的内容显示在屏幕上
[root@localhost ~]# ansible-playbook loop_register.yml
在上面的例子中,results键包含一个列表。在下面,修改了playbook,使第二个任务迭代此列表:
[root@localhost ~]# vim new_loop_register.yml
---
- name: Loop Register Test
gather_facts: no
hosts: 172.16.103.129
tasks:
- name: Looping Echo Task
shell: "echo This is my item: {{ item }}"
loop:
- one
- two
register: echo_results
- name: Show stdout from the previous task.
debug:
msg: "STDOUT from previous task: {{ item.stdout }}"
loop: "{{ echo_results['results'] }}"
1.2 有条件地运行任务
Ansible可使用conditionals在符合特定条件时执行任务或play。例如,可以利用一个条件在Ansible安装或配置服务前确定受管主机上的可用内存。
我们可以利用条件来区分不同的受管主机,并根据它们所符合的条件来分配功能角色。Playbook变量、注册的变量和Ansible事实都可通过条件来进行测试。可以使用比较字符串、数字数据和布尔值的运算符。
以下场景说明了在Ansible中使用条件的情况:
- 可以在变量中定义硬限制(如min_memory)并将它与受管主机上的可用内存进行比较。
- Ansible可以捕获并评估命令的输出,以确定某一任务在执行进一步操作前是否已经完成。例如,如果某一程序失败,则将路过批处理。
- 可以利用Ansible事实来确定受管主机网络配置,并决定要发送的模板文件(如,网络绑定或中继)。
- 可以评估CPU的数量,来确定如何正确调节某一Web服务器。
- 将注册的变量与预定义的变量进行比较,以确定服务是否已更改。例如,测试服务配置文件的MD5检验以和查看服务是否已更改。
1.2.1 条件任务语法
when语句用于有条件地运行任务。它取要测试的条件为值。如果条件满足,则运行任务。如果条件不满足,则跳过任务。
可以测试的一个最简单条件是某一布尔变量是True还是False。以下示例中的when语句导致任务仅在run_my_task为True时运行:
---
- name: Simple Boolean Task Demo
hosts: 172.16.103.129
vars:
run_my_task: True
tasks:
- name: httpd package is installed
yum:
name: httpd
when: run_my_task
以下示例测试my_service变量是否具有值。若有值,则将my_service的值用作要安装的软件包的名称。如果未定义my_service变量,则跳过任务且不显示错误。
---
- name: Test Variable is Defined Demo
hosts: 172.16.103.129
vars:
my_service: httpd
tasks:
- name: "{{ my_service }} package is installed"
yum:
name: "{{ my_service }}"
when: my_service is defined
下表显示了在处理条件时可使用的一些运算:
示例条件
| 操作 | 示例 |
|---|---|
| 等于(值为字符串) | ansible_machine == “x86_64” |
| 等于(值为数字) | max_memory == 512 |
| 小于 | min_memory < 128 |
| 大于 | min_memory > 256 |
| 小于等于 | min_memory <= 256 |
| 大于等于 | min_memory >= 512 |
| 不等于 | min_memory != 512 |
| 变量存在 | min_memory is defined |
| 变量不存在 | min_memory is not defined |
| 布尔变量是True。1、True或yes的求值为True | memory_available |
| 布尔变量是False。0、False或no的求值为False | not memory_available |
| 第一个变量的值存在,作为第二个变量的列表中的值 | ansible_distribution in supported_distros |
上表中的最后一个条目初看起来有些令人困惑。下例演示了它的工作原理。
在示例中,ansible_distribution变量是在Gathering Facts任务期间确定的事实,用于标识托管主机的操作系统分支。变量supported_distros由playbook创建,包含该playbook支持的操作系统分发列表。如果ansible_distribution的值在supported_distros列表中,则条件通过且任务运行。
---
- name: Demonstrale the "in" keyword
hosts: 172.16.103.129
gather_facts: yes
vars:
supported_distros:
- RedHat
- Fedora
tasks:
- name: Install httpd using yum, where supported
yum:
name: httpd
state: present
when: ansible_distribution in supported_distros
注意when语句的缩进。由于when语句不是模块变量,它必须通过缩进到任务的最高级别,放置在模块的外面。
任务是YAML散列/字典,when语句只是任务中的又一个键,就如任务的名称以及它所使用的模块一样。通常的惯例是将可能存在的任何when关键字放在任务名称和模块(及模块参数)的后面。
1.2.2 测试多个条件
一个when语句可用于评估多个条件。使用and和or关键字组合条件,并使用括号分组条件。
如果任一条件为真时满足条件语句,则应当使用or语句。例如,如果计算机上运行的是红帽企业linux或Fedora,则下述条件得到满足:
when: ansible_distribution == "Redhat" or ansible_distribution == "Fedora"
使用and运算时,两个条件都必须为真,才能满足整个条件语句。例如,如果远程主机是红帽企业Linux7.5主机,并且安装的内核是指定版本,则将满足以下条件:
when: ansible_distribution_version == "7.5" and ansible_kernel == "3.10.0-327.el7.x86_64"
when关键字还支持使用列表来描述条件列表。向when关键字提供列表时,将使用and运算组合所有条件。下面的示例演示了使用and运算符组合多个条件语句的另一方式:
when:
- ansible_distribution_version == "7.5"
- ansible_kernel == "3.10.0-327.el7.x86_64"
这种格式提高了可读性,而可读性是良好编写Ansible Playbook的关键目标。
通过使用括号分组条件,可以表达更复杂的条件语句。例如,如果计算机上运行的是红帽企业Linux7或Fedora28,则下述条件语句得到满足。此示例使用大于字符,这样长条件就可以在playbook中分成多行,以便于阅读。
when: >
( ansible_distribution == "Redhat" and
ansible_distribution_major_version == "7" )
or
( ansible_distribution == "Fedora" and
ansible_distribution_major_version == "28" )
1.3 组合循环和有条件任务
循环和条件可以组合使用。
在下例中,yum模块将安装mariadb-server软件包,只要/上挂载的文件系统具有超过300MB的可用空间。ansible_mounts事实是一组字典,各自代表一个已挂载文件系统的相关事实。循环迭代列表中每一字典,只有找到了代表两个条件都为真的已挂载文件系统的字典时,条件语句才得到满足。
- name: install mariadb-server if enough space on root
yum:
name: mariadb-server
state: latest
loop: "{{ ansible_mounts }}"
when: item.mount == "/" and item.size_available > 300000000
对某个任务结合使用when和loop时,将对每个项检查when语句。
下面是组合使用条件和注册变量的另一个示例。
---
- name: Restart HTTPD if Postfix is Running
hosts: 172.16.103.129
tasks:
- name: Get Postfix server status
command: /usr/bin/systemctl is-active postfix # Postfix是否在运行?
ignore_errors: yes # 如果它不在运行并且命令失败,则不停止处理。
register: result # 将模块的结果信息保存在名为result的变量中
- name: Restart Apache HTTPD based on Postfix status
service:
name: httpd
state: restarted
when: result.rc == 0 # 评估Postfix任务的输出。如果systemctl命令的退出代码为0,\
# 则Postfix激活并且此任务重启httpd服务
2. 实施处理程序
2.1 ansible处理程序
Ansible模块设计为具有幂等性。这表示,在正确编写的playbook中,playbook及其任务可以运行多次而不会改变受管主机,除非需要进行更改使受管主机进入所需的状态。
但在时候,在任务确实更改系统时,可能需要运行进一步的任务。例如,更改服务配置文件时可能要求重新加载该服务以便使其更改的配置生效。
处理程序是响应由其他任务触发的通知的任务。仅当任务在受管主机上更改了某些内容时,任务才通知其处理程序。每个处理程序具有全局唯一的名称,在playbook中任务块的末尾触发。如果没有任务通过名称通知处理程序,处理程序就不会运行。如果一个或多个任务通知处理程序,处理程序就会在play中的所有其他任务完成后运行一次。因为处理程序就是任务,所以可以在处理程序中使用他们将用于任何其他任务的模块。通常而言,处理程序被用于重新引导主机和重启服务。
处理程序可视为非活动任务,只有在使用notify语句显式调用时才会被触发。在下列代码片段中,只有配置文件更新并且通知了该任务,restart apache处理程序才会重启Apache服务器:
tasks:
- name: copy demo.example.conf configuratioon template # 通知处理程序的任务
template:
src: /var/lib/templates/demo.example.conf.template
dest: /etc/httpd/conf.d/demo.example.conf
notify: # notify语句指出该任务需要触发一个处理程序
- restart apache # 要运行的处理程序的名称
handlers: # handlers关键字表示处理程序任务列表的开头
- name: restart apache # 被任务调用的处理程序的名称
service: # 用于该处理程序的模块
name: httpd
state: restarted
在上面的例子中,restart apache处理程序只有在template任务通知已发生更改时才会触发。一个任务可以在其notify部分中调用多个处理程序。Ansible将notify语句视为数组,并且迭代处理程序名称:
tasks:
- name: copy demo.example.conf configuration template
template:
src: /var/lib/templates/demo.exammple.conf.template
dest: /etc/httpd/conf.d/demo.example.conf
notify:
- restart mysql
- restart apache
handlers:
- name: restart mysql
service:
name: mariadb
state: restarted
- name: restart apache
service:
name: httpd
state: restarted
2.2 使用处理程序的好处
使用处理程序时需要牢记几个重要事项:
- 处理程序始终按照play的handlers部分指定的顺序运行。它们不按在任务中由notify语句列出的顺序运行,或按任务通知它们的顺序运行。
- 处理程序通常在相关play中的所有其他任务完成后运行。playbook的tasks部分中某一任务调用的处理程序,将等到tasks下的所有任务都已处理后才会运行。
- 处理程序名称存在于各play命名空间中。如果两个处理程序被错误地给予相同的名称,则仅会运行一个。
- 即使有多个任务通知处理程序,该处理程序依然仅运行一次。如果没有任务通知处理程序,它就不会运行。
- 如果包含notify语句的任务没有报告changed结果(例如,软件包已安装并且任务报告ok),则处理程序不会获得通知。处理程序将被跳过,直到有其他任务通知它。只有相关任务报告了changed状态,Ansible才会通知处理程序。
处理程序用于在任务对受管主机进行更改时执行额外操作。它们不应用作正常任务的替代。
3. 处理任务失败
3.1 管理play中的任务错误
Ansible评估任务的返回代码,从而确定任务是成功还是失败。通常而言,当任务失败时,Ansible将立即在该主机上中止play的其余部分并且跳过所有后续任务。
但有些时候,可能希望即使在任务失败时也继续执行play。例如,或许预期待定任务有可能会失败,并且希望通过有条件地运行某项其他任务来修复。
Ansible有多种功能可用于管理任务错误。
3.2 忽略任务失败
默认情况下,任务失败时play会中止。不过,可以通过忽略失败的任务来覆盖此行为。可以在任务中使用ignore_errors关键字来实现此目的。
下列代码片段演示了如何在任务中使用ignore_errors,以便在任务失败时也继续在主机上执行playbook。例如,如果notapkg软件包不存在,则yum模块将失败,但若将ignore_errors设为yes,则执行将继续。
- name: Latest version of notapkg is installed
yum:
name: notapkg
state: latest
ignore_errors: yes
3.3 任务失败后强制执行处理程序
通常而言,如果任务失败并且play在该主机上中止,则收到play中早前任务通知的处理程序将不会运行。如果在play中设置force_handlers: yes关键字,则即使play因为后续任务失败而中止也会调用被通知的处理程序。
下列代码片段演示了如何在play中使用force_handlers关键字,以便在任务失败时也强制执行相应的处理程序:
---
- hosts: 172.16.103.129
force_handlers: yes
tasks:
- name: a task which always notifies its handler
command: /bin/true
notify: restart the database
- name: a task which fails because the package doesn't exist
yum:
name: notapkg
state: latest
handlers:
- name: restart the database
service:
name: mariadb
state: restarted
请记住,处理程序会在任务报告changed结果时获得通知,而在任务报告ok或failed结果时不会获得通知。
3.4 指定任务失败条件
可以在任务中使用failed_when关键字来指定表示任务已失败的条件。这通常与命令模块搭配使用,这些模块可能成功执行了某一命令,但命令的输出可能指示了失败。
例如,可以运行输出错误消息的脚本,并使用该消息定义任务的失败状态。下列代码片段演示了如何在任务中使用failed_when关键字:
tasks:
- name: Run user creation script
shell: /usr/local/bin/create_users.sh
register: command_result
failed_when: "'Password missing' in command_result.stdout"
fail模块也可用于强制任务失败。上面的场景也可以编写为两个任务:
tasks:
- name: Run user creation script
shell: /usr/local/bin/create_users.sh
register: command_result
ignore_errors: yes
- name: Report script failure
fail:
msg: "The password is missing in the output"
when: "'Password missing' in command_result.stdout"
我们可以使用fail模块为任务提供明确的失败消息。此方法还支持延迟失败,允许在运行中间任务以完成或回滚其他更改。
3.5 指定何时任务报告 “Changed” 结果
当任务对托管主机进行了更改时,会报告 changed 状态并通知处理程序。如果任务不需要进行更改,则会报告ok并且不通知处理程序。
changed_when关键字可用于控制任务在何时报告它已进行了更改。例如,下一示例中的shell模块将用于获取供后续任务使用的Kerberos凭据。它通常会在运行时始终报告changed。为抵制这种更改,应设置changed_when: false,以便它仅报告ok或failed。
- name: get Kerberos credentials as "admin"
shell: echo "{{ krb_admin_pass }}" | kinit -f admin
changed_when: false
以下示例使用shell模块,根据通过已注册变量收集的模块的输出来报告changed:
tasks:
- shell:
cmd: /usr/local/bin/upgrade-database
register: command_result
changed_when: "'Success' in command_result.stdout"
notify:
- restart_database
handlers:
- name: restart_database
service:
name: mariadb
state: restarted
3.6 Ansible块和错误处理
在playbook中,块是对任务进行逻辑分组的子句,可用于控制任务的执行方式。例如,任务块可以含有when关键字,以将某一条件应用到多个任务:
- name: block example
hosts: 172.16.103.129
tasks:
- name: installing and configuring Yum versionlock plugin
block:
- name: package needed by yum
yum:
name: yum-plugin-versionlock
state: present
- name: lock version of tadata
lineinfile:
dest: /etc/yum/pluginconf.d/versionlock.list
line: tzdata-2020j-1
state: present
when: ansible_distribution == "Redhat"
通过块,也可结合rescue和always语句来处理错误。如果块中的任何任务失败,则执行其rescue块中的任务来进行恢复。在block子句中的任务以及rescue子句中的任务(如果出现故障)运行之后,always子句中的任务运行。总结:
- block:定义要运行的主要任务
- rescue:定义要在block子句中定义的任务失败时运行的任务
- always:定义始终都独立运行的任务,不论block和rescue子句中定义的任务是成功还是失败
以下示例演示了如何在playbook中实施块。即使block子句中定义的任务失败,rescue和always子句中定义的任务也会执行。
tasks:
- name: Upgrade DB
block:
- name: upgrade the database
shell:
cmd: /usr/local/lib/upgrade-database
rescue:
- name: revert the database upgrade
shell:
cmd: /usr/local/lib/revert-database
always:
- name: always restart the database
service:
name: mariadb
state: restarted
block中的when条件也会应用到其rescue和always子句(若存在)。
07 在被管理节点上创建文件或目录
1. 修改文件并将其复制到主机
1.1 描述文件模块
Files模块库包含的模块允许用户完成与Linux文件管理相关的大多数任务,如创建、复制、编辑和修改文件的权限和其他属性。下表提供了常用文件管理模块的列表:
常用文件模块
| 模块名称 | 模块说明 |
|---|---|
| blockinfile | 插入、更新或删除由可自定义标记线包围的多行文本块 |
| copy | 将文件从本地或远程计算机复制到受管主机上的某个位置。 类似于file模块,copy模块还可以设置文件属性,包括SELinux上下文件。 |
| fetch | 此模块的作用和copy模块类似,但以相反方式工作。此模块用于从远程计算机获取文件到控制节点, 并将它们存储在按主机名组织的文件树中。 |
| file | 设置权限、所有权、SELinux上下文以及常规文件、符号链接、硬链接和目录的时间戳等属性。 此模块还可以创建或删除常规文件、符号链接、硬链接和目录。其他多个与文件相关的 模块支持与file模块相同的属性设置选项,包括copy模块。 |
| lineinfile | 确保特定行位于某文件中,或使用反向引用正则表达式来替换现有行。 此模块主要在用户想要更改文件的某一行时使用。 |
| stat | 检索文件的状态信息,类似于Linux中的stat命令。 |
| synchronize | 围绕rsync命令的一个打包程序,可加快和简化常见任务。 synchronize模块无法提供对rsync命令的完整功能的访问权限,但确实最常见的调用更容易实施。 用户可能仍需通过run command模块直接调用rsync命令。 |
1.2 files模块的自动化示例
在受管主机上创建、复制、编辑和删除文件是用户可以使用Files模块库中的模块实施的常见任务。
以下示例显示了可以使用这些模块自动执行常见文件管理任务的方式。
1.2.1 确保受管主机上存在文件
使用file模块处理受管主机上的文件。其工作方式与touch命令类似,如果不存在则创建一个空文件,如果存在,则更新其修改时间。在本例中,除了处理文件之外,Ansible还确保将文件的所有者、组和权限设置为特定值。
- name: Touch a file and set permissions
file:
path: /path/to/file
owner: user1
group: group1
mode: 0640
state: touch
1.2.2 修改文件属性
使用file模块还可以确保新的或现有的文件具有正确的权限和SELinux类型。
例如,以下文件保留了相对于用户主目录的默认SELinux上下文,这不是所需的上下文。
[root@localhost ~]# ls -Z samba_file
- rw-r--r-- owner group unconfined_u:object_r:user_home_t:s0 samba_file
以下任务确保了anaconda-ks.cfg文件的SELinux上下文件类型属性是所需的samba_share_t类型。此行为与Linux中的chcon命令类似。
- name: SELinux type is set to samba_share_t
file:
path: /path/to/samba_file
setype: samba_share_t
示例结果:
[root@localhost ~]# ls -Z samba_file
- rw-r--r-- owner group unconfined_u:object_r:samba_share_t:s0 samba_file
文件属性参数在多个文件管理模块中可用。运行ansible-doc file和ansible-doc copy命令以获取其他信息。
1.2.3 使SELinux文件上下文更改具有持久性
设置文件上下文时,file模块的行为与chcon类似。通过运行restorecon,可能会意外地撤消使用该模块所做的更改。使用file设置上下文后,用户可以使用system模块集合中的sefcontext来更新SELinux策略,如semanage fcontext。
- name: SELinux type is persistently set to samba_share_t
sefcontext:
target: /path/to/samba_file
setype: samba_share_t
state: present
注意:sefcontext模块更新SELinux策略中目标的默认上下文,但不更改现有文件的上下文。
1.2.4 在受管主机上复制和编辑文件
在此示例中,copy模块用于将位于控制节点上的Ansible工作目录中的文件复制到选定的受管主机。
默认情况下,此模块假定设置了force: yes。这会强制该模块覆盖远程文件(如果存在但包含与正在复制的文件不同的内容)。如果设置force: no,则它仅会将该文件复制到受管主机(如果该文件尚不存在)。
- name: Copy a file to managed hosts
copy:
src: file
dest: /path/to/file
要从受管主机检索文件,请使用fetch模块。这可用于在将参考系统分发给其他受管主机之前从参考系统中检查诸如SSH公钥之类的文件。
- name: Retrieve SSH key from reference host
fetch:
src: "/home/{{ user }}/.ssh/id_rsa.pub"
dest: "files/keys/{{ user }}.pub"
要确保现有文件中存在特定的单行文本,请使用lineinfile模块:
- name: Add a line of text to a file
lineinfile:
path: /path/to/file
line: 'Add this line to the file'
state: present
要将文本块添加到现有文件,请使用blockinfile模块:
- name: Add additional lines to a file
blockinfile:
path: /path/to/file
block: |
First line in the additional block of text
Second line in the additional block of text
state: present
注意:使用blockinfile模块时,注释块标记插入到块的开头和结尾,以确保幂等性。
# BEGIN ANSIBLE MANAGED BLOCK
First line in the additional block of text
Second line in the additional block of text
# END ANSIBLE MANAGED BLOCK
用户可以使用该模块的marker参数,帮助确保将正确的注释字符或文本用于相关文件。
1.2.5 从受管主机中删除文件
从受管主机中删除文件的基本示例是使用file模块和state: absent参数。state参数对于许多模块是可选的。一些模块也支持其他选项。
- name: Make sure a file does not exist on managed hosts
file:
dest: /path/to/file
state: absent
1.2.6 检索受管主机上的文件状态
stat模块检索文件的事实,类似于Linux中的stat命令。参数提供检索文件属性、确定文件检验和等功能。
stat模块返回一个包含文件状态数据的值的散列字典,允许用户使用单独的变量引用各条信息。
以下示例注册stat模块的结果,然后显示它检查的文件的MD5检验和。
- name: Verify the checksum of a file
stat:
path: /path/to/file
checksum_algorithm: md5
register: result
- debug
msg: "The checksum of the file is {{ result.stat.checksum }}"
有关stat模块返回的值的信息由ansible-doc记录,或者可以注册一个变量并显示其内容以查看可用内容:
- name: Examine all stat output of /etc/passwd
hosts: 172.16.103.129
tasks:
- name: stat /etc/passwd
stat:
path: /etc/passwd
register: results
- name: Display stat results
debug:
var: results
1.2.7 同步控制节点和受管主机之间的文件
synchronize模块是一个围绕rsync工具的打包程序,它简化了playbook中的常见文件管理任务。rsync工具必须同时安装在本机和远程主机上。默认情况下,在使用synchronize模块时,“本地主机”是同步任务所源自的主机(通常是控制节点),而“目标主机”是synchronize连接到的主机。
以下示例将位于Ansible工作目录中的文件同步到受管主机:
- name: synchronize local file to remote files
synchronize:
src: file
dest: /path/to/file
有很多种方法可以使用synchronize模块及其许多参数,包括同步目录。运行ansible-doc synchronize命令查看其他参数和playbook示例。
2. 使用jinja2模板部署自定义文件
2.1 jinja2简介
Ansible将jinja2模板系统用于模板文件。Ansible还使用jinja2语法来引用playbook中的变量。
变量和逻辑表达式置于标记或分隔符之间。例如,jinja2模板将**{% EXPR %}用于表达式或逻辑(如循环),而{{ EXPR }}则用于向最终用户输出表达式或变量的结果。后一标记在呈现时将被替换为一个或多个值,对最终用户可见。使用{# COMMENT #}**语法括起不应出现在最终文件中的注释。
在下例中,第一行中含有不会包含于最终文件中的注释。第二行中引用的变量被替换为所引用的系统事实的值。
{# /etc/hosts line #}
{{ ansible_facts['default_ipv4']['address'] }} {{ ansible_facts['hostname'] }}
2.2 构建jinja2模板
jinja2模板由多个元素组成:数据、变量和表达式。在呈现jinja2模板时,这些变量和表达式被替换为对应的值。模板中使用的变量可以在playbook的vars部分中指定。可以将受管主机的事实用作模板中的变量。
请记住,可以使用ansible system_hostname -i inventory_file -m setup命令来获取与受管主机相关的事实。
下例演示了如何使用变量及Ansible从受管主机检索的事实创建**/etc/ssh/sshd_config的模板。当执行相关的playbook**时,任何事实都将被替换为所配置的受管主机中对应的值。
注意:包含jinja2模板的文件不需要有任何特定的文件扩展名(如.j2)。但是,提供此类文件扩展名会让你更容易记住它是模板文件。
# {{ ansible_managed }}
# DO NOT MAKE LOCAL MODIFICATIONS TO THIS FILE AS THEY WILL BE LOST
Port {{ ssh_port }}
ListenAddress {{ ansible_facts['default_ipv4']['address'] }}
HostKey /etc/ssh/ssh_host_rsa_key
HostKey /etc/ssh/ssh_host_ecdsa_key
HostKey /etc/ssh/ssh_host_ed25519_key
SyslogFacility AUTHPRIV
PermitRootLogin {{ root_allowed }}
AllowGroups {{ groups_allowed }}
AuthorizedKeyFile /etc/.rht_authorized_keys .ssh/authorized_keys
PasswordAuthentication {{ passwords_allowed }}
ChallengeResponseAuthentication no
GSSAPIAuthentication yes
GSSAPICleanupCredentials no
UsePAM yes
X11Forwarding yes
UsePrivilegeSeparation sandbox
AcceptEnv LANG LC_CTYPE LC_NUMERIC LC_TIME LC_COLLATE LC_MONETARY LC_MESSAGES
AcceptEnv LC_PAPER LC_NAME LC_ADDRESS LC_TELEPHONE LC_MEASUREMENT
AcceptEnv LC_IDENTIFICATION LC_ALL LANGUAGE
AcceptEnv XMODIFIERS
Subsystem sftp /usr/libexec/openssh/sftp-server
2.3 部署jinja2模板
jinja2模板是功能强大的工具,可用于自定义要在受管主机上部署的配置文件。创建了适用于配置文件的jinja2模板后,它可以通过template模板部署到受管主机上,该模块支持将控制节点中的本地文件转移到受管主机。
若要使用template模块,请使用下列语法。与src键关联的值指定来源jinja2模板,而与dest键关联的值指定要在目标主机上创建的文件。
tasks:
- name: template render
template:
src: /tmp/j2-template.j2
dest: /tmp/dest-config-file.txt
template模块还允许指定已部署文件的所有者、组、权限和SELINUX上下文,就像file模块一样。它也可以取用validate选项运行任意命令(如visudo -c),在将文件复制到位之前检查该文件的语法是否正确。
有关更多详细信息,请参阅ansible-doc template
2.4 管理模板文件
为避免系统管理员修改Ansible部署的文件,最好在模板顶部包含注释,以指示不应手动编辑该文件。
可使用ansible_managed指令中设置的"Ansible managed"字符串来执行此操作。这不是正常变量,但可以在模板中用作一个变量。ansible_managed指令在ansible.cfg文件中设置:
ansible_managed = Ansible managed
要将ansible_managed字符串包含在jinja2模板内,请使用下列语法:
{{ ansible_managed }}
2.5 控制结构
用户可以在模板文件中使用jinja2控制结构,以减少重复输入,为play中的每个主机动态输入条目,或者有条件地将文本插入到文件中。
2.5.1 使用循环
jinja2使用for语句来提供循环功能。在下例中,user变量替换为users变量中包含的所有值,一行一个值。
{% for user in users %}
{{ user }}
{% endfor %}
以下示例模板使用for语句逐一运行users变量中的所有值,将myuser替换为各个值,但值为root时除外。
{# for statement #}
{% for myuser in users if not myuser == "root" %}
User number {{ loop.index }} - {{ myuser }}
{% endfor %}
loop.index变量扩展至循环当前所处的索引号。它在循环第一次执行时值为1,每一次迭代递增1。
再如,此模板也使用了for语句,并且假定使用的清单文件中已定义了myhosts变量。此变量将包含要管理的主机的列表。使用下列for语句时,文件中将列出清单myhosts组内的所有主机。
{% for myhost in groups['myhosts'] %}
{{ myhost }}
{% endfor %}
举一个更实际的例子,用户可以使用该模板从主机事实动态生成**/etc/hosts**文件。假设playbook如下:
- name: /etc/hosts is up to date
hosts: all
gather_facts: yes
tasks:
- name: Deploy /etc/hosts
template:
src: templates/hosts.j2
dest: /etc/hosts
下述三行templates/hosts.j2模板从all组中的所有主机构造文件。(由于变量名称的长度,模板的中间行非常长。)它迭代组中的每个主机以获得**/etc/hosts**文件的三个事实。
{% for host in groups['all'] %}
{{ hostvars['host']['ansible_facts']['default_ipv4']['address'] }} {{ hostvars['host']['ansible_facts']['fqdn'] }} {{ hostvars['host']['ansible_facts']['hostname'] }}
{% endfor %}
2.5.2 使用条件句
jinja2使用if语句来提供条件控制。如果满足某些条件,这允许用户在已部署的文件中放置一行。
在以下示例中,仅当finished变量的值为True时,才可将result变量的值放入已部署的文件。
{% if finished %}
{{ result }}
{% endif %}
注意,在Ansible模板中我们可以使用jinja2循环和条件,但不能在Ansible Playbook中使用。
2.5.3 变量过滤器
jinja2提供了过滤器,更改模板表达式的输出格式(例如,输出到果JSON)。有适用于YAML和JSON等语言的过滤器。to_json过滤器使用JSON格式化表达式输出,to_yaml过滤器则使用YAML格式化表达式输出。
{{ output | to_json }}
{{ output | to_yaml }}
也有其他过滤器,如to_nice_json和to_nice_yaml过滤器,它们将表达式输出格式化为JSON或YAML等人类可读格式。
{{ output | to_nice_json }}
{{ output | to_nice_yaml }}
from_json和from_yaml过滤器相应要求JSON或YAML格式的字符串,并对它们进行解析。
{{ output | from_json }}
{{ output | from_yaml }}
2.5.4 变量测试
在Ansible Playbook中与when子句一同使用的表达式是jinja2表达式。用于测试返回值的内置Ansible测试包括failed、changed、successded和skipped。以下任务演示了如何在条件表达式内使用测试。
tasks:
...output omitted...
- debug: msg="the execution was aborted"
when: returnvalue is failed
08 管理大项目
1. 利用主机模式选择主机
1.1 引用清单主机
主机模式用于指定要作为play或临时命令的目标的主机。在最简单的形式中,清单中受管主机或主机组的名称就是指定该主机或主机组的主机模式。
在play中,hosts指定要针对其运行play的受管主机。对于临时命令,以命令行参数形式将主机模式提供给ansible命令。
本节中将通篇使用以下示例清单来演示主机模式。
[root@localhost ~]# cat myinventory
web.example.com
data.example.com
[lab]
labhost1.example.com
labhost2.example.com
[test]
test1.example.com
test2.example.com
[datacenter1]
labhost1.example.com
test1.example.com
[datacenter2]
labhost2.example.com
test2.example.com
[datacenter:children]
datacenter1
datacenter2
[new]
172.16.103.129
172.16.103.130
要演示如何解析主机模式,我们将执行Ansible Playbook的playbook.yml,使用不同的主机模式来以此示例清单中受管主机的不同子集作为目标。
1.2 受管主机
最基本的主机模式是单一受管主机名称列在清单中。这将指定该主机是清单中ansible命令要执行操作的唯一主机。
在该playbook运行时,第一个Gathering Facts任务应在与主机模式匹配的所有受管主机上运行。此任务期间的故障可能导致受管主机从play中移除。
如果清单中明确列出了IP地址,而不是主机名,则可以将其用作主机模式。如果IP地址未列在清单中,我们就无法用它来指定主机,即使该IP地址会在DNS中解析到这个主机名。
以下示例演示了如何使用主机模式来引用清单中包含的IP地址。
[root@localhost ~]# vim playbook.yml
---
- hosts: 172.16.103.129
[root@localhost ~]# ansible-playbook playbook.yml
PLAY [172.16.103.129] ***************************************************************
TASK [Gathering Facts] **************************************************************
ok: [172.16.103.129]
PLAY RECAP **************************************************************************
172.16.103.129 : ok=1 changed=0 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
注意:
在清单中通过IP地址引用受管主机存在一个问题,那就是难以记住play或临时命令所针对的主机使用了哪个IP地址。但是,如果没有可解析的主机名,我们可能必须按IP地址指定主机以进行连接。
可以通过设置ansible_host主机变量,在清单中将某一别名指向特定的IP地址。例如,你的清单中可以有一个名为dummy.example的主机,然后通过创建含有以下主机变量的host_vars/dummy.example文件,将使用该名称的连接指向IP地址172.16.103.129:
ansible_host: 172.16.103.129
1.3 使用组指定主机
当组名称用作主机模式时,它指定Ansible将对属于该组的成员的主机执行操作。
---
- hosts: lab
记住,有一个名为all的特别组,它匹配清单中的所有受管主机。
---
- hosts: all
还有一个名为ungrouped的特别组,它包括清单中不属于任何其他组的所有受管主机:
---
- hosts: ungrouped
1.4 使用通配符匹配多个主机
若要达成与all主机模式相同的目标,另一种方法是使用*通配符,它将匹配任意字符串。如果主机模式只是带引号的星号,则清单中的所有主机都将匹配。
---
- hosts: '*'
重要
一些在主机模式中使用的字符对shell也有意义。通过ansible使用主机模式从命令行运行临时命令时,这可能会有问题。建议大家在命令行中使用单引号括起使用的主机模式,防止它们被shell意外扩展。
类似的,如果在Ansible Playbook中使用了任何特殊通配符或列表字符,必须将主机模式放在单引号里,确保能够正确解析主机模式。
---
- hosts: '!test1.example.com,development'
也可使用*字符匹配包含特定子字符串的受管主机或组。
例如,以下通配符主机模式匹配以**.example.com**结尾的所有清单名称:
---
- hosts: '*.example.com'
以下示例使用通配符主机模式来匹配开头为**192.168.2.**的主机或主机组的名称:
---
- hosts: '192.168.2.*'
以下示例使用通配符主机模式来匹配开头为datacenter的主机或主机组的名称。
---
- hosts: 'datacenter*'
重要
通配符主机模式匹配所有清单名称、主机和主机组。它们不区别名称是DNS名、IP地址还是组,这可能会导致一些意外的匹配。
例如,根据示例清单,比较上一示例中指定datacenter主机模式的结果和data主机模式的结果:
---
- hosts: 'data*'
1.5 列表
可以通过逻辑列表来引用清单中的多个条目。主机模式的逗号分隔列表匹配符合任何这些主机模式的所有主机。
如果提供受管主机的逗号分隔列表,则所有这些受管主机都将是目标:
---
- hosts: labhost1.example.com,test2.example.com,192.168.2.2
如果提供组的逗号分隔列表,则属于任何这些组的所有主机都将是目标:
---
- hosts: lab,datacenter1
也可以混合使用受管主机、主机组和通配符,如下所示:
---
- hosts: 'lab,data*,192.168.2.2'
注意
也可以用冒号(:)取代逗号。不过,逗号是首选的分隔符,特别是将IPv6地址用作受管主机名称时。
如果列表中的某一项以与符号(&)开头,则主机必须与该项匹配才能匹配主机模式。它的工作方式类似于逻辑AND。
例如,根据我们的示例清单,以下主机模式将匹配lab组中同时也属于datacenter1组的计算机:
---
- hosts: lab,&datacenter1
我们也可以通过主机模式**&lab,datacenter1或datacenter,&lab指定datacenter1组中的计算机只有在同时也属于lab**组时才匹配。
通过在主机模式的前面使用感叹号(!)表示从列表中排除匹配某一模式的主机。它的工作方式类似于逻辑NOT。
根据示例清单,以下示例匹配datacenter组中定义的所有主机,但test2.example.com除外:
---
- hosts: datacenter,!test2.example.com
也可以使用模式**‘!test2.example.com,datacenter’**来获得相同的结果。
最后一个示例演示了使用匹配测试清单中的所有主机的主机模式,datacenter1组中的受管主机除外。
---
- hosts: all,!datacenter1
2. 管理动态清单
2.1 动态生成清单
前面我们用到的静态清单编写比较容易,对于管理小型基础架构而言也很方便。不过,如果要操作许多台计算机,或者在计算机更替非常快的环境中工作,可能难以让静态清单文件保持最新状态。
大多数大型IT环境中没有系统来跟踪可用的主机以及它们的组织方式。例如,可能有外部目录服务通过Zabbix等监控系统维护,或者位于FreeIPA或Active Directory服务器上。Cobbler等安装服务器或红帽卫星等管理服务可能跟踪部署的裸机系统。类似地,Amazon Web ServicesEC2或OpenStack部署等云服务,或者基于Vmware或红帽虚拟化的虚拟机基础架构可能是有关那些更替的实例和虚拟机的信息来源。
Ansible支持动态清单脚本,这些脚本在每当Ansible执行时从这些类型的来源检索当前的信息,使清单能够实时得到更新。这些脚本是可以执行的程序,能够从一些外部来源收集信息,并以JSON格式输出清单。
动态清单脚本的使用方式与静态清单文本文件一样。清单的位置可以直接在当前的ansible.cfg文件中指定,或者通过**-i**选项指定。如果清单文件可以执行,则它将被视为动态清单程序,Ansible会尝试运行它来生成清单。如果文件不可执行,则它将被视为静态清单。
清单位置可以在ansible.cfg配置文件中通过inventory参数进行配置。默认情况下,它被配置为**/etc/ansible/hosts**。
2.2 开源社区脚本
开源社区向Ansible项目贡献了大量现有的动态清单脚本。它们没有包含在ansible软件包中。这些脚本可从Ansible GigHub网站(https://github.com/ansible/ansible/tree/devel/examples)获取。
2.3 编写动态清单程序
如果使用的目录系统或基础架构没有动态清单脚本,我们可以编写自定义清单程序。可以使用任何编程语言编写自定义程序,但传递适当的选项时必须以JSON格式返回清单信息。
ansible-inventory命令是学习如何以JSON格式编写Ansible清单的有用工具。
要以JSON格式显示清单文件的内容,请运行ansible-inventory --list命令。可以使用**-i**选项指定要处理的清单文件的位置,或仅使用当前Ansible配置设置的默认清单。
以下示例演示了如何使用ansible-inventory命令来处理INI样式的清单文件并以JSON格式输出。
[root@localhost ~]# cat inventory
workstation1.lab.example.com
[webservers]
web1.lab.example.com
web2.lab.example.com
[databases]
db1.lab.example.com
db2.lab.example.com
[root@localhost ~]# ansible-inventory -i inventory --list
如果要自己编写动态清单脚本,可以通过部署动态清单来源[https://docs.ansible.com/ansible/latest/dev_guide/developing_inventory.html]获得更详细的信息。以下是一个简略概要。
脚本以适当的解释器行(例如,#!/usr/bin/python)开头并且可以执行,以便Ansible能够运行它。
在传递–list选项时,脚本必须显示清单中所有主机和组的JSON编码散列/字典。
在最简单的形式中,组可以是一个受管主机列表。在这个清单脚本的JSON编码输出示例中,webservers是一个主机组,该组内含web1.lab.example.com和web2.lab.example.com受管主机。databases主机组的成员有db1.lab.example.com和db2.lab.example.com主机。
[root@localhost ~]# ./inventoryscript --list
{
"webservers": ["web1.lab.example.com","web2.lab.example.com"],
"databases": ["db1.lab.example.com","db2.lab.example.com"]
}
此外,每个组的值可以是JSON散列/字典,含有由每一受管主机、任何子组和可能设置的任何组变量组成的列表。下一示例显示了一个比较复杂的动态清单的JSON编码输出。boston组具有两个子组(backup和ipa)、自己的三个受管主机,以及一个组变量集合(example_host: false)。
{
"webservers": [
"web1.lab.example.com",
"web2.lab.example.com"
],
"boston": {
"children": [
"backup",
"ipa"
],
"vars": {
"example_host": false
},
"hosts": [
"server1.demo.example.com",
"server2.demo.example.com",
"server3.demo.example.com",
]
},
"backup": [
"server4.demo.example.com"
],
"ipa": [
"server5.demo.example.com"
],
"_meta": {
"hostvars": {
"server5.demo.example.com": {
"ntpserver": "ntp.demo.example.com",
"dnsserver": "dns.demo.example.com"
}
}
}
}
该脚本也支持–host managed-host选项。此选项必须显示由与该主机关联的变量组成的JSON散列/字典,或者空白的JSON散列/字典。
[root@localhost ~]# ./inventoryscript --host server5.demo.example.com
{
"ntpserver": "ntp.demo.example.com",
"dnsserver": "dns.demo.example.com"
}
注意
通过–host hostname选项调用时,该脚本必须显示指定主机的变量的JSON散列/字典。如果不提供任何变量,则可能显示空白的JSON散列或字典。
另外,如果–list选项返回名为_meta的顶级元素,则可以在一次脚本调用中返回所有主机变量,从而提升脚本性能。此时,不会进行–host调用。
有关详细信息,请参见部署动态清单来源[https://docs.ansible.com/ansible/latest/dev_guide/developing_inventory.html]。
下面是一个脚本示例:
[root@localhost ~]# vim inventory.py
#!/usr/bin/env python
'''
Example custom dynamic inventory script for Ansible, in Python.
'''
import os
import sys
import argparse
try:
import json
except ImportError:
import simplejson as json
class ExampleInventory(object):
def __init__(self):
self.inventory = {}
self.read_cli_args()
# Called with `--list`.
if self.args.list:
self.inventory = self.example_inventory()
# Called with `--host [hostname]`.
elif self.args.host:
# Not implemented, since we return _meta info `--list`.
self.inventory = self.empty_inventory()
# If no groups or vars are present, return empty inventory.
else:
self.inventory = self.empty_inventory()
print json.dumps(self.inventory);
# Example inventory for testing.
def example_inventory(self):
return {
'group': {
'hosts': ['172.16.103.129', '172.16.103.130'],
'vars': {
'ansible_ssh_user': 'root',
'ansible_ssh_pass': '123456',
'example_variable': 'value'
}
},
'_meta': {
'hostvars': {
'172.16.103.129': {
'host_specific_var': 'foo'
},
'172.16.103.130': {
'host_specific_var': 'bar'
}
}
}
}
# Empty inventory for testing.
def empty_inventory(self):
return {'_meta': {'hostvars': {}}}
# Read the command line args passed to the script.
def read_cli_args(self):
parser = argparse.ArgumentParser()
parser.add_argument('--list', action = 'store_true')
parser.add_argument('--host', action = 'store')
self.args = parser.parse_args()
# Get the inventory.
ExampleInventory()
如何使用这个脚本呢?
chmod +x inventory.py
./inventory.py --list
./inventory.py --host 172.16.103.129
ansible使用这个动态清单来管理主机:
ansible all -i inventory.py -m ping
ansible 172.16.103.129 -i inventory.py -m ping
2.4 管理多个清单
Ansible支持在同一运行中使用多个清单。如果清单的位置是一个目录(不论是由**-i选项设置的、是inventory**参数的值,还是以某种其他方式设置的),将组合该目录中包含的所有清单文件(不论是静态还是动态)来确定清单。该目录中的可执行文件将用于检索动态清单,其他文件则被用作静态清单。
清单文件不应依赖于其他清单文件或脚本来解析。例如,如果静态清单文件指定某一个组应当是另一个组的子级,则它也需要具有该组的占位符条目,即使该组的所有成员都来自动态清单。
[cloud-east]
[servers]
test.demo.example.com
[servers:children]
cloud-east
这可以确保不论清单文件以什么顺序解析,它们在内部都一致。
注意
清单文件的解析顺序不是由文档指定的。目前,如果存在多个清单文件,它们会按照字母顺序进行解析。如果一个清单源依赖于另一个清单源的信息,则它们的加载顺序可能会确定清单文件是按预期工作还是引发错误。因此,务必要确保所有文件都自相一致,从而避免意外的错误。
Ansible会忽略清单目录中以特定后缀结尾的文件。这可以通过在Ansible配置文件中的inventory_ignore_extensions指令来控制。有关更多信息,请参阅Ansible官方文档。
使用动态清单:https://docs.ansible.com/ansible/latest/user_guide/intro_dynamic_inventory.html
开发动态清单:https://docs.ansible.com/ansible/latest/dev_guide/developing_inventory.html
3. 配置并行
3.1 使用分叉在ansible中配置并行
当Ansible处理playbook时,会按顺序运行每个play。确定play的主机列表之后,Ansible将按顺序运行每个任务。通常,所有主机必须在任何主机在play中启动下一个任务之前成功完成任务。
理论上,Ansible可以同时连接到play中的所有主机以执行每项任务。这非常适用于小型主机列表。但如果该play以数百台主机为目标,则可能会给控制节点带来沉重负担。
Ansible所进行的最大同时连接数由Ansible配置文件中的forks参数控制。默认情况下设为5,这可通过以下方式之一来验证。
[root@localhost ~]# grep forks /etc/ansible/ansible.cfg
#forks = 5
[root@localhost ~]# ansible-config dump|grep -i forks
DEFAULT_FORKS(default) = 5
[root@localhost ~]# ansible-config list|grep -i forks
DEFAULT_FORKS:
description: Maximum number of forks Ansible will use to execute tasks on target
- {name: ANSIBLE_FORKS}
- {key: forks, section: defaults}
name: Number of task forks
例如,假设Ansible控制节点配置了5个forks的默认值,并且play具有10个受管主机。Ansible将在前5个受管主机上执行play中的第一个任务,然后在其他5个受管主机上对第一个任务执行第二轮。在所有受管主机上执行第一个任务后,Ansible将继续一次在5受管主机的组中的所有受管主机上执行下一个任务。Ansible将依次对每个任务执行此操作,直到play结束。
forks的默认值设置得非常保守。如果你的控制节点正在管理Linux主机,则大多数任务将在受管主机上运行,并且控制节点的负载较少。在这种情况下,通常可以将forks的值设置得更高,可能接近100,然后性能就会提高。
如果playbook在控制节点上运行很多代码,则应明智地提高forks限值。如果使用Ansible管理网络路由器和交换机,则大多数模块在控制节点上运行而不是在网络设备上运行。由于这会增加控制节点上的负载,因此其支持forks数量增加的能力将显著低于仅管理Linux主机的控制节点。
可以从命令行覆盖Ansible配置文件中forks的默认设置。ansible和ansible-playbook命令均提供-f或–forks选项以指定要使用的forks数量。
3.2 管理滚动更新
通常,当Ansible运行play时,它会确保所有受管主机在启动任何主机进行下一个任务之前已完成每个任务。在所有受管主机完成所有任务后,将运行任何通知的处理程序。
但是,在所有主机上运行所有任务可能会导致意外行为。例如,如果play更新负载均衡Web服务器集群,则可能需要在进行更新时让每个Web服务器停止服务。如果所有服务器都在同一个play中更新,则它们可能全部同时停止服务。
避免此问题的一种方法是使用serial关键字,通过play批量运行主机。在下一批次启动之前,每批主机将在整个play中运行。
在下面的示例中,Ansible一次在两个受管主机上执行play,直至所有受管主机都已更新。Ansible首先在前两个受管主机上执行play中的任务。如果这两个主机中的任何一个或两个都通知了处理程序,则Ansible将根据这两个主机的需要运行处理程序。在这两个受管主机上执行完play时,Ansible会在接下来的两个受管主机上重复该过程。Ansible继续以这种方式运行play,直到所有受管主机都已更新。
---
- name: Rolling update
hosts: webservers
serial: 2
tasks:
- name: latest apache httpd package is installed
yum:
name: httpd
state: latest
notify: restart apache
handlers:
- name: restart apache
service:
name: httpd
state: restarted
假设上一示例中的webservers组包含5个Web服务器,它们位于负载均衡器后面。将serial参数设置为2后,play一次将运行两台Web服务器。因此,5台Web服务器中的大多数服务器将始终可用。
相反,如果不使用serial关键字,将同时在5台Web服务器上执行play和生成的处理程序。这可能会导致服务中断,因为Web服务将在所有Web服务器上同时重新启动。
重要
出于某些目的,每批主机算作在主机子集上运行的完整play。这意味着,如果整个批处理失败,play就会失败,这将导致整个playbook运行失败。
在设置了serial: 2的上一个场景中,如果出现问题并且处理的前2个主机的play失败,则playbook将中止,其余3个主机将不会通过play运行。这是一个有用的功能,因为只有一部分服务器会不可用,使服务降级而不是中断。
serial关键字也可以指定为百分比。此百分比应用于play中的主机总数,以确定滚动更新批处理大小。无论百分比为何,每一工序的主机数始终为1或以上。
4. 包含和导入文件
4.1 管理大型playbook
如果playbook很长或很复杂,我们可以将其分成较小的文件以便于管理。可采用模块化方式将多个playbook组合为一个主要playbook,或者将文件中的任务列表插入play。这样可以更轻松地在不同项目中重用play或任务序列。
4.2 包含或导入文件
Ansible可以使用两种操作将内容带入playbook。可以包含内容,也可以导入内容。
包含内容是一个动态操作。在playbook运行期间,Ansible会在内容到达时处理所包含的内容。
导入内容是一个静态操作。在运行开始之前,Ansible在最初解析playbook时预处理导入的内容。
4.3 导入playbook
import_playbook指令允许将包含play列表的外部文件导入playbook。换句话说,可以把一个或多个额外playbook导入到主playbook中。
由于导入的内容是一个完整的playbook,因此import_playbook功能只能在playbook的顶层使用,不能在play内使用。如果导入多个playbook,则将按顺序导入并运行它们。
导入两个额外playbook的主playbook的简单示例如下所示:
- name: Prepare the web server
import_playbook: web.yml
- name: Prepare the database server
import_playbook: db.yml
还可以使用导入的playbook在主playbook中交替play。
- name: Play 1
hosts: localhost
tasks:
- debug:
msg: Play 1
- name: Import Playbook
import_playbook: play2.yml
在此例中,Play 1首先运行,然后运行从play2.ymlplaybook中导入的play。
4.4 导入和包含任务
可以将任务文件中的任务列表导入或包含在play中。任务文件是包含一个任务平面列表的文件:
[root@localhost ~]# cat webserver_tasks.yml
- name: Installs the httpd package
yum:
name: httpd
state: latest
- name: Starts the httpd service
service:
name: httpd
state: started
4.4.1 导入任务文件
可以使用import_tasks功能将任务文件静态导入playbook内的play中。导入任务文件时,在解析该playbook时将直接插入该文件中的任务。Playbook中的import_tasks的位置控制插入任务的位置以及运行多个导入的顺序。
---
- name: Install web server
hosts: webservers
tasks:
- import_tasks: webserver_tasks.yml
导入任务文件时,在解析该playbook时将直接插入该文件中的任务。由于import_tasks在解析playbook时静态导入任务,因此对其工作方式有一些影响。
- 使用import_tasks功能时,导入时设置的when等条件语句将应用于导入的每个任务
- 无法将循环用于import_tasks功能
- 如果使用变量来指定要导入的文件的名称,则将无法使用主机或组清单变量
4.4.2 包含任务文件
可以使用include_tasks功能将任务文件动态导入playbook内的play中。
---
- name: Install web server
hosts: webservers
tasks:
- include_tasks: webserver_tasks.yml
在play运行并且这部分play到达前,include_tasks功能不会处理playbook中的内容。Playbook内容的处理顺序会影响包含任务功能的工作方式。
- 使用include_tasks功能时,包含时设置的when等条件语句将确定任务是否包含在play中
- 如果运行ansible-playbook --list-tasks以列出playbook中的任务,则不会显示已包含任务文件中的任务。将显示包含任务文件的任务。相比之下,import_tasks功能不会列出导入任务文件的任务,而列出已导入任务文件中的各个任务
- 不能使用ansible-playbook --start-at-task从已包含任务文件中的任务开始执行playbook
- 不能使用notify语句触发已包含任务文件中的处理程序名称。可以在包含整个任务文件的主playbook中触发处理程序,在这种情况下,已包含文件中的所有任务都将运行
4.4.3 任务文件的用例
请参考下面的示例,在这些情景中将任务组作为与playbook独立的外部文件来管理或许有所帮助:
- 如果新服务器需要全面配置,则管理员可以创建不同的任务集合,分别用于创建用户、安装软件包、配置服务、配置特权、设置对共享文件系统的访问权限、强化服务器、安装安全更新,以及安装监控代理等。每一任务集合可通过单独的自包含任务文件进行管理
- 如果服务器由开发人员、系统管理员和数据库管理员统一管理,则每个组织可以编写自己的任务文件,再由系统经理进行审核和集成
- 如果服务器要求特定的配置,它可以整合为按照某一条件来执行的一组任务。换句话说,仅在满足特定标准时才包含任务
- 如果一组服务器需要运行某一项/组任务,则它/它们可以仅在属于特定主机组的服务器上运行
4.4.4 管理任务文件
为方便管理,可以创建专门用于任务文件的目录,并将所有任务文件保存在该目录中。然后playbook就可以从该目录包含或导入任务文件。这样就可以构建复杂的playbook,同时简化其结构和组件的管理。
4.5 为外部play和任务定义变量
使用Ansible的导入和包含功能将外部文件中的play或任务合并到playbook中极大地增强了在Ansible环境中重用任务和playbook的能力。为了最大限度地提高重用可能性,这些任务和play文件应尽可能通用。变量可用于参数化play和任务元素,以扩大任务和play的应用范围。
例如,以下任务文件将安装Web服务所需的软件包,然后启用并启动必要的服务。
---
- name: Install the httpd package
yum:
name: httpd
state: latest
- name: Start the httpd service
service:
name: httpd
enabled: True
state: started
如果如下例所示对软件包和服务元素进行参数化,则任务文件也可用于安装和管理其他软件及其服务,而不仅仅用于Web服务。
---
- name: Install the {{ package }} package
yum:
name: "{{ package }}"
state: latest
- name: Start the {{ service }} service
service:
name: "{{ service }}"
enabled: True
state: started
随后,在将任务文件合并到一个playbook中时,定义用于执行该任务的变量,如下所示:
...output omitted...
tasks:
- name: Import task file and set variables
import_tasks: task.yml
vars:
package: httpd
service: service
Ansible使传递的变量可用于从外部文件导入的任务。
使用相同的技术使play文件更具有可重用性。将play文件合并到playbook中时,传递变量以用于执行该play,如下所示:
...output omitted...
- name: Import play file and set the variable
import_playbook: play.yml
vars:
package: mariadb
09 利用角色简化playbook
1. 描述角色结构
1.1 利用角色构造ansible playbook
随着开发更多的playbook,我们可能会发现有很多机会重复利用以前缩写的playbook中的代码。或许,一个用于为某一应用配置MySQL数据库的play可以改变用途,通过利用不同的主机名、密码和用户来为另一个应用配置MySQL数据库。
但在现实中,这个play可能比较冗长且复杂,有许多包含或导入的文件,以及用于管理各种情况的任务和处理程序。将所有这些代码复制到另一playbook中可能比较困难。
Ansible角色提供了一种方法,让用户能以通用的方式更加轻松地重复利用Ansible代码。我们可以在标准化目录结构中打包所有任务、变量、文件、模板,以及调配基础架构或部署应用所需的其他资源。只需通过复制相关的目录,将角色从一个项目复制到另一个项目。然后,只需从一个play调用该角色就能执行它。
借助编写良好的角色,可以从playbook中向角色传递调整其行为的变量,设置所有站点相关的主机名、IP地址、用户名,或其他在本地需要的具体详细信息。例如,部署数据库服务器的角色可能已编写为支持多个变量,这些变量用于设置主机名、数据库管理员用户和密码,以及需要为安装进行自定义的其他参数。角色的作者也可以确保在选择不在play中设置变量值时,为这些变量设定合理的默认值。
Ansible角色具有下列优点:
- 角色可以分组内容,从而与他人轻松共享代码
- 可以编写角色来定义系统类型的基本要素:Web服务器、数据库服务器、Git存储库,或满足其他用途
- 角色使得较大型项目更容易管理
- 角色可以由不同的管理员并行开发
除了自行编写、使用、重用和共享角色外,还可以从其他来源获取角色。一些角色已包含在rhel-system-roles软件包中,用户也可以从Ansible Galaxy网站获取由社区提供支持的许多角色。
1.2 检查ansible角色结构
Ansible角色由子目录和文件的标准化结构定义。顶级目录定义角色本身的名称。文件整理到子目录中,子目录按照各个文件在角色中的用途进行命名,如tasks和handlers。files和templates子目录中包含由其他YAML文件中的任务引用的文件。
site.yml
webservers.yml
fooservers.yml
roles/
common/
tasks/
handlers/
files/
templates/
vars/
defaults/
meta/
webservers/
tasks/
defaults/
meta/
以下tree命令显示了user.example角色的目录结构:
[root@localhost roles]# tree user.example/
user.example/
├── defaults
│ └── main.yml
├── files
├── handlers
│ └── main.yml
├── meta
│ └── main.yml
├── README.md
├── tasks
│ └── main.yml
├── templates
├── tests
│ ├── inventory
│ └── test.yml
└── vars
└── main.yml
Ansible角色子目录
| 子目录 | 功能 |
|---|---|
| defaults | 此目录中的main.yml文件包含角色变量的默认值,使用角色时可以覆盖这些默认值。 这些变量的优先级较低,应该在play中更改和自定义。 |
| files | 此目录包含由角色任务引用的静态文件。 |
| handlers | 此目录中的main.yml文件包含角色的处理程序定义。 |
| meta | 此目录中的main.yml文件包含与角色相关的信息,如作者、许可证、平台和可选的角色依赖项。 |
| tasks | 此目录中的main.yml文件包含角色的任务定义。 |
| templates | 此目录包含由角色任务引用的Jinja2模板。 |
| tests | 此目录可以包含清单和名为test.yml的playbook,可用于测试角色。 |
| vars | 此目录中的main.yml文件定义角色的变量值。这些变量通常用于角色内部用途。 这些变量的优先级较高,在playbook中使用时不应更改。 |
并非每个角色都拥有所有这些目录。
1.3 定义变量和默认值
角色变量通过在角色目录层次结构中创建含有键值对的vars/main.yml文件来定义。与其他变量一样,这些角色变量在角色YAML文件中引用:{{ VAR_NAME }}。这些变量具有较高的优先级,无法被清单变量覆盖。这些变量旨在供角色的内部功能使用。
默认变量允许为可在play中使用的变量设置默认值,以配置角色或自定义其行为。它们通过在角色目录层次结构中创建含有键值对的defaults/main.yml文件来定义。默认变量具有任何可用变量中最低的优先级。它们很容易被包括清单变量在内的任何其他变量覆盖。这些变量旨在让用户在编写使用该角色的play时可以准确地自定义或控制它将要执行的操作。它们可用于向角色提供所需的信息,以正确地配置或部署某些对象。
在vars/main.yml或defaults/main.yml中定义具体的变量,但不要在两者中都定义。有意要覆盖变量的值时,应使用默认变量。
注意: 角色不应该包含特定于站点的数据。它们绝对不应包含任何机密,如密码或私钥。 这是因为角色应该是通用的,可以重复利用并自由共享。特定于站点的详细信息不应硬编码到角色中。 机密应当通过其他途径提供给角色。这是用户可能要在调用角色时设置角色变量的一个原因。play中设置的角色变量可以提供机密,或指向含有该机密的Ansible Vault加密文件。
1.4 在playbook中使用ansible角色
在playbook中使用角色非常简单。下例演示了调用Ansible角色的一种方式:
---
- hosts: remote.example.com
roles:
- role1
- role2
对于每个指定的角色,角色任务、角色处理程序、角色变量和角色依赖项将按照顺序导入到playbook中。角色中的任何copy、script、template或include_tasks/import_tasks任务都可引用角色中相关的文件、模板或任务文件,且无需相对或绝对路径名称。Ansible将分别在角色的files、templates或tasks子目录中寻找它们。
如果使用roles部分将角色导入到play中,这些角色会在用户为该play定义的任何任务之前运行。
以下示例设置role2的两个角色变量var1和var2的值。使用role2时,任何defaults和vars变量都会被覆盖。
---
- hosts: remote.example.com
roles:
- role: role1
- role: role2
var1: val1
var2: val2
以下是在此情形中用户可能看到的另一种等效的YAML语法:
---
- hosts: remote.example.com
roles:
- role: role1
- { role: role2, var1: val1, var2: val2 }
尽管这种写法更精简,但在某些情况下它更加难以阅读。
重要 正如前面的示例中所示,内嵌设置的角色变量(角色参数)具有非常高的优先级。它们将覆盖大多数其他变量。 务必要谨慎,不要重复使用内嵌设置在play中任何其他位置的任何角色变量的名称,因为角色变量的值将覆盖清单变量和任何play中的vars。
1.5 控制执行顺序
对于playbook中的每个play,任务按照任务列表中的顺序来执行。执行完所有任务后,将执行任务通知的处理程序。
在角色添加到play中后,角色任务将添加到任务列表的开头。如果play中包含第二个角色,其任务列表添加到第一个角色之后。
角色处理程序添加到play中的方式与角色任务添加到play中相同。每个play定义一个处理程序列表。角色处理程序先添加到处理程序列表,后跟play的handlers部分中定义的任何处理程序。
在某些情形中,可能需要在角色之前执行一些play任务。若要支持这样的情形,可以为play配置pre_tasks部分。列在此部分中的所有任务将在执行任何角色之前执行。如果这些任务中有任何一个通知了处理程序,则这些处理程序任务也在角色或普通任务之前执行。
此外,play也支持post_tasks关键字。这些任务在play的普通任务和它们通知的任何处理程序运行之后执行。
以下play演示了一个带有pre_tasks、roles、tasks、post_tasks和handlers的示例。一个play中通常不会同时包含所有这些部分。
- name: Play to illustrate order of execution
hosts: remote.example.com
pre_tasks:
- debug:
msg: 'pre-task'
notify: my handler
roles:
- role1
tasks:
- debug:
msg: 'first task'
notify: my handler
post_tasks:
- debug:
msg: 'post-task'
notify: my handler
handlers:
- name: my handler
debug:
msg: Running my handler
在上例中,每个部分中都执行debug任务来通知my handler处理程序。my handler任务执行了三次:
- 在执行了所有pre_tasks任务后
- 在执行了所有角色任务和tasks部分中的任务后
- 在执行了所有post_tasks后
除了将角色包含在play的roles部分中外,也可以使用普通任务将角色添加到play中。使用include_role模块可以动态包含角色,使用import_role模块则可静态导入角色。
以下playbook演示了如何通过include_role模块来利用任务包含角色。
- name: Execute a role as a task
hosts: remote.example.com
tasks:
- name: A normal task
debug:
msg: 'first task'
- name: A task to include role2 here
include_role: role2
注意 include_role模块是在Ansible 2.3中新增的,而import_role模块则是在Ansible 2.4中新增的。
2. 利用系统角色重用内容
2.1 红帽企业Linux系统角色
自RHEL7.4开始,操作系统随附了多个Ansible角色,作为rhel-system-roles软件包的一部分。在RHEL8中,该软件包可以从AppStream中获取。以下是每个角色的简要描述:
RHEL系统角色
| 名称 | 状态 | 角色描述 |
|---|---|---|
| rhel-system-roles.kdump | 全面支持 | 配置kdump崩溃恢复服务 |
| rhel-system-roles.network | 全面支持 | 配置网络接口 |
| rhel-system-roles.selinux | 全面支持 | 配置和管理SELinux自定义, 包括SELinux模式、文件和端口上下文、 布尔值设置以及SELinux用户 |
| rhel-system-roles.timesync | 全面支持 | 使用网络时间协议或精确时间协议配置时间同步 |
| rhel-system-roles.postfix | 技术预览 | 使用Postfix服务将每个主机配置为邮件传输代理 |
| rhel-system-roles.firewall | 开发中 | 配置主机的防火墙 |
| rhel-system-roles.tuned | 开发中 | 配置tuned服务,以调优系统性能 |
系统角色的目的是在多个版本之间标准化红帽企业Linux子系统的配置。使用系统角色来配置版本6.10及以上的任何红帽企业Linux主机。
2.2 简化配置管理
举例而言,RHEL7的建议时间同步服务为chronyd服务。但在RHEL6中,建议的服务为ntpd服务。在混合了RHEL6和7主机的环境中,管理员必须管理这两个服务的配置文件。
借助RHEL系统角色,管理员不再需要维护这两个服务的配置文件。管理员可以使用rhel-system-roles.timesync角色来配置RHEL6和7主机的时间同步。一个包含角色变量的简化YAML文件可以为这两种类型的主机定义时间同步配置。
2.3 安装RHEL系统角色
RHEL系统角色由rhel-system-roles软件包提供,该软件包可从AppStream流获取。在Ansible控制节点上安装该软件包。
安装RHEL系统角色
yum -y install rhel-system-roles
安装后,RHEL系统角色位于**/usr/share/ansible/roles**目录中:
ls -l /usr/share/ansible/roles/
红帽企业Linux中的默认roles_path在路径中包含**/usr/share/ansible/roles**,因此在playbook引用这些角色时Ansible可以很轻松的找到它们。
注意 如果在当前Ansible配置文件中覆盖了roles_path,设置了环境变量ANSIBLE_ROLES_PATH,或者roles_path中更早列出的目录下存在另一个同名的角色,则Ansible可能无法找到系统角色。
2.4 访问RHEL系统角色的文档
安装后,RHEL系统角色的文档位于**/usr/share/doc/rhel-system-roles-/**目录中。文档按照子系统整理到子目录中:
[root@localhost ~]# ll /usr/share/doc/rhel-system-roles/
total 4
drwxr-xr-x 2 root root 57 Aug 22 15:26 kdump
drwxr-xr-x 2 root root 4096 Aug 22 15:26 network
drwxr-xr-x 2 root root 57 Aug 22 15:26 postfix
drwxr-xr-x 2 root root 93 Aug 22 15:26 selinux
drwxr-xr-x 2 root root 57 Aug 22 15:26 storage
drwxr-xr-x 2 root root 136 Aug 22 15:26 timesync
每个角色的文档目录均包含一个README.md文件。README.md文件含有角色的说明,以及角色用法信息。
README.md文件也会说明影响角色行为的角色变量。通常,README.md文件中含有一个playbook代码片段,用于演示常见配置场景的变量设置。
部分角色文档目录中含有示例playbook。首次使用某一角色时,请查看文档目录中的任何额外示例playbook。
RHEL系统角色的角色文档与Linux系统角色的文档相匹配。使用Web浏览器来访问位于Ansible Galaxy网站https://galaxy.ansible.com/docs/上的角色文档。
2.5 时间同步角色示例
假设需要在服务器上配置NTP时间同步。我们可以自行编写自动化来执行每一个必要的任务。但是,RHEL系统角色中有一个可以执行此操作角色,那就是rhel-system-roles.timesync。
该角色的详细记录位于**/usr/share/doc/rhel-system-roles/timesync目录下的README.md**中。此文件说明了影响角色行为的所有变量,还包含演示了不同时间同步配置的三个playbook代码片段。
为了手动配置NTP服务器,该角色具有一个名为timesync_ntp_servers的变量。此变量取一个要使用的NTP服务器的列表作为值。列表中的每一项均由一个或多个属性构成。两个关键属性如下:
timesync_ntp_servers属性
| 属性 | 用途 |
|---|---|
| hostname | 要与其同步的NTP服务器的主机名。 |
| iburst | 一个布尔值,用于启用或禁用快速初始同步。在角色中默认为no,但通常应该将属性设为yes. |
根据这一信息,以下示例play使用rhel-system-roles.timesync角色将受管主机配置为利用快速初始同步从三个NTP服务器获取时间。此外,还添加了一个任务,以使用timezone模块将主机的时区设为UTC。
- name: Time Synchronization Play
hosts: servers
vars:
timesync_ntp_servers:
- hostname: 0.rhel.pool.ntp.org
iburst: yes
- hostname: 1.rhel.pool.ntp.org
iburst: yes
- hostname: 2.rhel.pool.ntp.org
iburst: yes
timezone: UTC
roles:
- rhel-system-roles.timesync
tasks:
- name: Set timezone
timezone:
name: "{{ timezone }}"
注意 如果要设置不同的时区,可以使用tzselect命令查询其他有效的值。也可以使用timedatectl命令来检查当前的时钟设置。
此示例在play的vars部分中设置角色变量,但更好的做法可能是将它们配置为主机或主机组的清单变量。
例如一个playbook项目具有以下结构:
[root@localhost playbook-project]# tree
.
├── ansible.cfg
├── group_vars
│ └── servers
│ └── timesync.yml
├── inventory
└── timesync_playbook.yml
timesync.yml定义时间同步变量,覆盖清单中servers组内主机的角色默认值。此文件看起来类似于:
timesync_ntp_servers:
- hostname: 0.rhel.pool.ntp.org
iburst: yes
- hostname: 1.rhel.pool.ntp.org
iburst: yes
- hostname: 2.rhel.pool.ntp.org
iburst: yes
timezone: UTC
timesync_playbook.yml的内容简化为:
- name: Time Synchronization Play
hosts: servers
roles:
- rhel-system-roles.timesync
tasks:
- name: Set timezone
timezone:
name: "{{ timezone }}"
该结构可清楚地分隔角色、playbook代码和配置设置。Playbook代码简单易读,应该不需要复杂的重构。角色内容由红帽进行维护并提供支持。所有设置都以清单变量的形式进行处理。
该结构还支持动态的异构环境。具有新的时间同步要求的主机可能会放置到新的主机组中。相应的变量在YAML文件中定义,并放置到相应的group_vars(或host_vars)子目录中。
2.6 SELINUX角色示例
rhel-system-roles.selinux角色可以简化SELinux配置设置的管理。它通过利用SELinux相关的Ansible模块来实施。与自行编写任务相比,使用此角色的优势是它能让用户摆脱编写这些任务的职责。取而代之,用户将为角色提供变量以对其进行配置,且角色中维护的代码将确保应用用户需要的SELinux配置。
此角色可以执行的任务包括:
- 设置enforcing或permissive模式
- 对文件系统层次结构的各部分运行restorecon
- 设置SELinux布尔值
- 永久设置SELinux文件上下文
- 设置SELinux用户映射
2.7 调用SELinux角色
有时候,SELinux角色必须确保重新引导受管主机,以便能够完整应用其更改。但是,它本身从不会重新引导主机。如此一来,用户便可以控制重新引导的处理方式。
其工作方式为,该角色将一个布尔值变量selinux_reboot_required设为True,如果需要重新引导,则失败。你可以使用block/rescure结构来从失败中恢复,具体操作为:如果该变量未设为true,则让play失败,如果值是true,则重新引导受管主机并重新运行该角色。Play中的块看起来应该类似于:
- name: Apply SELinux role
block:
- include_role:
name: rhel-system-roles.selinux
rescue:
- name: Check for failure for other reasons than required reboot
fail:
when: not selinux_reboot_required
- name: Restart managed host
reboot:
- name: Reapply SELinux role to complete changes
include_role:
name: rhel-system-roles.selinux
2.8 配置SELinux角色
用于配置rhel-system-roles.selinux角色的变量的详细记录位于其README.md文件中。以下示例演示了使用此角色的一些方法。
selinux_state变量设置SELinux的运行模式。它可以设为enforcing、permissive或disabled。如果未设置,则不更改模式。
selinux_state: enforcing
selinux_booleans变量取一个要调整的SELinux布尔值的列表作为值。列表中的每一项是变量的散列/字典:布尔值的name、state(它应是on还是off),以及该设置是否应在重新引导后persistent。
本例将httpd_enable_homedirs永久设为on:
selinux_booleans:
- name: 'httpd_enable_homedirs'
state: 'on'
persistent: 'yes'
selinux_fcontext变量取一个要永久设置(或删除)的文件上下文的列表作为值。它的工作方式与selinux fcontent命令非常相似。
以下示例确保策略中包含一条规则,用于将/srv/www下所有文件的默认SELinux类型设为httpd_sys_content_t。
selinux_fcontexts:
- target: '/srv/www(/.*)?'
setype: 'httpd_sys_content_t'
state: 'present'
selinux_restore_dirs变量指定要对其运行restorecon的目录的列表:
selinux_restore_dirs:
- /srv/www
selinux_ports变量取应当具有特定SELinux类型的端口的列表作为值。
selinux_ports:
- ports: '82'
setype: 'http_port_t'
proto: 'tcp'
state: 'present'
3. 创建角色
角色创建流程
在Ansible中创建角色不需要特别的开发工具。创建和使用角色包含三个步骤:
- 创建角色目录结构
- 定义角色内容
- 在playbook中使用角色
3.1 创建角色目录结构
默认情况下,Ansible在Ansible Playbook所在目录的roles子目录中查找角色。这样,用户可以利用playbook和其他支持文件存储角色。
如果Ansible无法在该位置找到角色,它会按照顺序在Ansible配置设置roles_path所指定的目录中查找。此变量包含要搜索的目录的冒号分隔列表。此变量的默认值为:
~/.ansible/roles:/usr/share/ansible/roles:/etc/ansible/roles
这允许用户将角色安装到由多个项目共享的系统上。例如,用户可能将自己的角色安装在自己的主目录下的~/.ansible/roles子目录中,而系统可能将所有用户的角色安装在/usr/share/ansible/roles目录中。
每个角色具有自己的目录,采用标准化的目录结构。例如,以下目录结构包含了定义motd角色的文件。
[root@localhost ~]# tree roles/
roles/
└── motd
├── defaults
│ └── main.yml
├── files
├── handlers
├── meta
│ └── main.yml
├── tasks
│ └── main.yml
└── templates
└── motd.j2
README.md提供人类可读的基本角色描述、有关如何使用该角色的文档和示例,以及其发挥作用所需要满足的任何非Ansible要求。
meta子目录包含一个main.yml文件,该文件指定有关模块的作者、许可证、兼容性和依赖项的信息。
files子目录包含固定内容的文件,而templates子目录则包含使用时可由角色部署的模板。
其他子目录中可以包含main.yml文件,它们定义默认的变量值、处理程序、任务、角色元数据或变量,具体取决于所处的子目录。
如果某一子目录存在但为空,如本例中的handlers,它将被忽略。如果某一角色不使用功能,则其子目录可以完全省略。例如,本例中的vars子目录已被省略。
3.2 创建角色框架
可以使用标准Linux命令创建新角色所需的所有子目录和文件。此外,也可以通过命令行实用程序来自动执行新角色创建过程。
ansible-galaxy命令行工具可用于管理Ansible角色,包括新角色的创建。用户可以运行ansible-galaxy init来创建新角色的目录结构。指定角色的名称作为命令的参数,该命令在当前工作目录中为新角色创建子目录。
[root@localhost playbook-project]# cd roles/
[root@localhost roles]# ansible-galaxy init my_new_role
- Role my_new_role was created successfully
[root@localhost roles]# ls my_new_role/
defaults files handlers meta README.md tasks templates tests vars
3.3 定义角色内容
创建目录结构后,用户必须编写角色的内容。ROLENAME/tasks/main.yml任务文件是一个不错的起点,它是由角色运行的主要任务列表。
下列tasks/main.yml文件管理受管主机上的/etc/motd文件。它使用template模块将名为motd.j2的模板部署到受管主机上。因为template模块是在角色任务而非playbook任务内配置的,所以从角色的templates子目录检索motd.j2模板。
[root@localhost ~]# cat roles/motd/tasks/main.yml
---
# tasks file for motd
- name: deliver motd file
template:
src: motd.j2
dest: /etc/motd
owner: root
group: root
mode: 0444
下列命令显示motd角色的motd.j2模板的内容。它引用了Ansible事实和system_owner变量。
[root@localhost ~]# cat roles/motd/templates/motd.j2
This is the system {{ ansible_facts['hostname'] }}.
Today's date is: {{ ansible_facts['date_time']['date'] }}.
Only use this system with permission.
You can ask {{ system_owner }} for access.
该角色为system_owner变量定义一个默认值。角色目录结构中的defaults/main.yml文件就是设置这个值的位置。
下列defaults/main.yml文件将system_owner变量设置为user@host.example.com。此电子邮件地址将写入到该角色所应用的受管主机上的/etc/motd文件中。
[root@localhost ~]# cat roles/motd/defaults/main.yml
---
system_owner: user@host.example.com
3.4 角色内容开发的推荐做法
角色允许以模块化方式编写playbook。为了最大限度地提高新开发角色的效率,请考虑在角色开发中采用以下推荐做法:
- 在角色自己的版本控制存储库中维护每个角色。Ansible很适合使用基于git的存储库。
- 角色存储库中不应存储敏感信息,如密码或SSH密钥。敏感值应以变量的形式进行参数化,其默认值应不敏感。使用角色的playbook负责通过Ansible Vault变量文件、环境变量或其他ansible-playbook选项定义敏感变量。
- 使用ansible-galaxy init启动角色,然后删除不需要的任何目录和文件。
- 创建并维护README.md和meta/main.yml文件,以记录用户的角色的用途、作者和用法。
- 让角色侧重于特定的用途或功能。可以编写多个角色,而不是让一个角色承担许多任务。
- 经常重用和重构角色。避免为边缘配置创建新的角色。如果现有角色能够完成大部分的所需配置,请重构现有角色以集成新的配置方案。使用集成和回归测试技术来确保角色提供所需的新功能,并且不对现有的playbook造成问题。
3.5 定义角色依赖项
角色依赖项使得角色可以将其他角色作为依赖项包含在内。例如,一个定义文档服务器的角色可能依赖于另一个安装和配置web服务器的角色。依赖关系在角色目录层次结构中的meta/main.yml文件内定义。
以下是一个示例meta/main.yml文件。
dependencies:
- role: apache
port: 8080
- role: postgres
dbname: serverlist
admin_user: felix
默认情况下,角色仅作为依赖项添加到playbook中一次。若有其他角色也将它作为依赖项列出,它不会再次运行。此行为可以被覆盖,将meta/main.yml文件中的allow_duplicates变量设置为yes即可。
重要 限制角色对其他角色的依赖。依赖项使得维护角色变得更加困难,尤其是当它具有许多复杂的依赖项时。
3.6 在playbook中使用角色
要访问角色,可在play的roles:部分引用它。下列playbook引用了motd角色。由于没有指定变量,因此将使用默认变量值应用该角色。
[root@localhost ~]# cat use-motd-role.yml
---
- name: use motd role playbook
hosts: remote.example.com
remote_user: devops
become: true
roles:
- motd
执行该playbook时,因为角色而执行的任务可以通过角色名称前缀来加以识别。
[root@localhost ~]# ansible-playbook -i inventory use-motd-role.yml
上述情形假定motd角色位于roles目录中。
3.7 通过变量更改角色的行为
编写良好的角色利用默认变量来改变角色行为,使之与相关的配置场景相符。这有助于让角色变得更为通用,可在各种不同的上下文中重复利用。
如果通过以下方式定义了相同的变量,则角色的defaults目录中定义的变量的值将被覆盖:
- 在清单文件中定义,作为主机变量或组变量
- 在playbook项目的group_vars或host_vars目录下的YAML文件中定义
- 作为变量嵌套在play的vars关键字中定义
- 在play的roles关键字中包含该角色时作为变量定义
下例演示了如何将motd角色与system_owner角色变量的不同值搭配使用。角色应用到受管主机时,指定的值someone@host.example.com将取代变量引用。
[root@localhost ~]# cat use-motd-role.yml
---
- name: use motd role playbook
hosts: remote.example.com
remote_user: devops
become: true
vars:
system_owner: someone@host.example.com
roles:
- role: motd
以这种方式定义时,system_owner变量将替换同一名称的默认变量的值。嵌套在vars关键字内的任何变量定义不会替换在角色的vars目录中定义的同一变量的值。
下例也演示了如何将motd角色与system_owner角色变量的不同值搭配使用。指定的值someone@host.example.com将替换变量引用,不论是在角色的vars还是defaults目录中定义。
[root@localhost ~]# cat use-motd-role.yml
---
- name: use motd role playbook
hosts: remote.example.com
remote_user: devops
become: true
roles:
- role: motd
system_owner: someone@host.example.com
重要 在play中使用角色变量时,变量的优先顺序可能会让人困惑。 - 几乎任何其他变量都会覆盖角色的默认变量,如清单变量、playvars变量,以及内嵌的角色参数等。 - 较少的变量可以覆盖角色的vars目录中定义的变量。事实、通过include_vars加载的变量、注册的变量和角色参数是其中一些具备这种能力的变量。清单变量和playvars无此能力。这非常重要,因为它有助于避免用户的play意外改变角色的内部功能。 - 不过,正如上述示例中最后一个所示,作为角色参数内嵌声明的变量具有非常高的优先级。它们可以覆盖角色的vars目录中定义的变量。如果某一角色参数的名称与playvars或角色vars中设置的变量或者清单变量或playbook变量的名称相同,该角色参数将覆盖另一个变量。
4 使用ansible galaxy部署角色
4.1 介绍ansible galaxy
Ansible Galaxy [https://galaxy.ansible.com]是一个Ansible内容公共资源库,这些内容由许许多多Ansible管理员和用户编写。它包含数千个Ansible角色,具有可搜索的数据库,可帮助Ansible用户确定或许有助于他们完成管理任务的角色。Ansible Galaxy含有面向新的Ansible用户和角色开发人员的文档和视频链接。
此外,用于从Ansible Galaxy获取和管理角色的ansible-galaxy命令也可用于为您的项目获取和管理自有的git存储库中的角色。
4.1.1 获取Ansible Galaxy帮助
通过Ansible Galaxy网站主页上的Documenttaion标签,可以进入描述如何使用Ansible Galaxy的页面。其中包含了介绍如何从Ansible Galaxy下载和使用角色的内容。该页面也提供关于如何开发角色并上传到Ansible Galaxy的说明。
4.1.2 浏览Ansible Galaxy中的角色
通过Ansible Galaxy网站主页上左侧的Search标签,用户可以访问关于Ansible Galaxy上发布的角色的信息。用户可以使用标记通过角色的名称或通过其他角色属性来搜索Ansible角色。结果按照Best Match分数降序排列,此分数依据角色质量、角色受欢迎程度和搜索条件计算而得。
4.2 Ansible Galaxy命令行工具
4.2.1 从命令行搜索角色
ansible-galaxy search子命令在Ansible Galaxy中搜索角色。如果以参数形式指定了字符串,则可用于按照关键字在Ansible Galaxy中搜索角色。用户可以使用–author、–platforms和–galaxy-tags选项来缩小搜索结果的范围。也可以将这些选项用作主要的搜索键。例如,命令ansible-galaxy search --author geerlingguy将显示由用户geerlingguy提交的所有角色。
结果按照字母顺序显示,而不是Best Match分数降序排列。下例显示了包含redis并且适用于企业Linux(EL)平台的角色的名称。
ansible-galaxy search 'redis' --platforms EL
ansible-galaxy info子命令显示与角色相关的更多详细信息。Ansible Galaxy从多个位置获取这一信息,包括角色的meta/main.yml文件及其GigHub存储库。以下命令显示了Ansible Galaxy提供的geerlingguy.redis角色的相关信息。
ansible-galaxy info geerlingguy.redis
4.2.2 从Ansible Galaxy安装角色
ansible-galaxy install子命令从Ansible Galaxy下载角色,并将它安装到控制节点本地。
默认情况下,角色安装到用户的roles_path下的第一个可写目录中。根据为Ansible设置的默认roles_path,角色通常将安装到用户的~/.ansible/roles目录。默认的roles_path可能会被用户当前Ansible配置文件或环境变量ANSIBLE_ROLES_PATH覆盖,这将影响ansible-galaxy的行为。
用户可以通过使用-p DIRECTORY选项,指定具体的目录来安装角色。
在下例中,ansible-galaxy将geerlingguy.redis角色安装到playbook项目的roles目录中。命令的当前工作目录是/opt/project。
ansible-galaxy install geerlingguy.redis -p roles/
4.2.3 使用要求文件安装角色
可以使用ansible-galaxy,根据某一文本文件中的定义来安装一个角色列表。例如,如果用户的一个playbook需要安装特定的角色,可以在项目目录中创建一个roles/requirements.yml文件来指定所需的角色。此文件充当playbook项目的依赖项清单,使得playbook的开发和调试能与任何支持角色分开进行。
例如,一个用于安装geerlingguy.redis的简单requirements.yml可能类似于如下:
- src: geerlingguy.redis
version: "1.5.0"
src属性指定角色的来源,本例中为来自Ansible Galaxy的geerlingguy.redis角色。version属性是可选的,指定要安装的角色版本,本例中为1.5.0。
重要 应当在requirements.yml文件中指定角色版本,特别是生产环境中的playbook。 如果不指定版本,将会获取角色的最新版本。如果作者对角色做出了更改,并与用户的playbook不兼容,这可能会造成自动化失败或其他问题。
若要使用角色文件来安装角色,可使用-r REQUIREMENTS-FILE选项:
ansible-galaxy install -r roles/requirements.yml -p roles
用户可以使用ansible-galaxy来安装不在Ansible Galaxy中的角色。可以在私有的Git存储库或Web服务器上托管自有的专用或内部角色。下例演示了如何利用各种远程来源配置要求文件。
[root@localhost project]# cat roles/requirements.yml
# from Ansible Galaxy, using the latest version
- src: geerlingguy.redis
# from Ansible Galaxy, overriding the name and using a specific version
- src: geerlingguy.redis
version: "1.5.0"
name: redis_prod
# from any Git-based repository, using HTTPS
- src: https://gitlab.com/guardianproject-ops/ansible-nginx-acme.git
scm: git
version: 56e00a54
name: nginx-acme
# from any Git-based repository, using SSH
- src: git@gitlab.com:guardianproject-ops/ansible-nginx-acme.git
scm: git
version: master
name: nginx-acme-ssh
# from a role tar ball, given a URL
# supports 'http', 'https', or 'file' protocols
- src: file:///opt/local/roles/myrole.tar
name: myrole
src关键字指定Ansible Galaxy角色名称。如果角色没有托管在Ansible Galaxy中,则src关键字将指明角色的URL。
如果角色托管在来源控制存储库中,则需要使用scm属性。ansible-galaxy命令能够从基于git或mercurial的软件存储库下载和安装角色。基于Git的存储库要求scm值为git,而托管在Mercurial存储库中的角色则要求值为hg。如果角色托管在Ansible Galaxy中,或者以tar存档形式托管在Web服务器上,则省略scm关键字。
name关键字用于覆盖角色的本地名称。version关键字用于指定角色的版本。version关键字可以是与严自角色的软件存储库的分支、标记或提交哈希对应的任何值。
若要安装与playbook项目关联的角色,可执行ansible-galaxy install命令:
[root@localhost project]# ansible-galaxy install -r roles/requirements.yml -p roles
4.2.4 管理下载的角色
ansible-galaxy命令也可管理本地的角色,如位于playbook项目的roles目录中的角色。ansible-galaxy list子命令列出本地找到的角色。
ansible-galaxy list
可以使用ansible-galaxy remove子命令本地删除角色。
ansible-galaxy remove nginx-acme-ssh
ansible-galaxy list
在playbook中使用下载并安装的角色的方式与任何其他角色都一样。在roles部分中利用其下载的角色名称来加以引用。如果角色不在项目的roles目录中,则将检查roles_path来查看角色是否安装在了其中一个目录中,将使用第一个匹配项。以下use-role.ymlplaybook引用了redis_prod和geerlingguy.redis角色:
[root@localhost project]# cat use-role.yml
---
- name: use redis_prod for prod machines
hosts: redis_prod_servers
remote_user: devops
become: True
roles:
- redis_prod
- name: use geerlingguy.redis for Dev machines
hosts: redis_dev_servers
remote_user: devops
become: True
roles:
- geerlingguy.redis
资源库,这些内容由许许多多Ansible管理员和用户编写。它包含数千个Ansible角色,具有可搜索的数据库,可帮助Ansible用户确定或许有助于他们完成管理任务的角色。Ansible Galaxy含有面向新的Ansible用户和角色开发人员的文档和视频链接。
[外链图片转存中…(img-Mz5AcyDA-1705028622742)]
此外,用于从Ansible Galaxy获取和管理角色的ansible-galaxy命令也可用于为您的项目获取和管理自有的git存储库中的角色。
4.1.1 获取Ansible Galaxy帮助
通过Ansible Galaxy网站主页上的Documenttaion标签,可以进入描述如何使用Ansible Galaxy的页面。其中包含了介绍如何从Ansible Galaxy下载和使用角色的内容。该页面也提供关于如何开发角色并上传到Ansible Galaxy的说明。
4.1.2 浏览Ansible Galaxy中的角色
通过Ansible Galaxy网站主页上左侧的Search标签,用户可以访问关于Ansible Galaxy上发布的角色的信息。用户可以使用标记通过角色的名称或通过其他角色属性来搜索Ansible角色。结果按照Best Match分数降序排列,此分数依据角色质量、角色受欢迎程度和搜索条件计算而得。
4.2 Ansible Galaxy命令行工具
4.2.1 从命令行搜索角色
ansible-galaxy search子命令在Ansible Galaxy中搜索角色。如果以参数形式指定了字符串,则可用于按照关键字在Ansible Galaxy中搜索角色。用户可以使用–author、–platforms和–galaxy-tags选项来缩小搜索结果的范围。也可以将这些选项用作主要的搜索键。例如,命令ansible-galaxy search --author geerlingguy将显示由用户geerlingguy提交的所有角色。
结果按照字母顺序显示,而不是Best Match分数降序排列。下例显示了包含redis并且适用于企业Linux(EL)平台的角色的名称。
ansible-galaxy search 'redis' --platforms EL
ansible-galaxy info子命令显示与角色相关的更多详细信息。Ansible Galaxy从多个位置获取这一信息,包括角色的meta/main.yml文件及其GigHub存储库。以下命令显示了Ansible Galaxy提供的geerlingguy.redis角色的相关信息。
ansible-galaxy info geerlingguy.redis
4.2.2 从Ansible Galaxy安装角色
ansible-galaxy install子命令从Ansible Galaxy下载角色,并将它安装到控制节点本地。
默认情况下,角色安装到用户的roles_path下的第一个可写目录中。根据为Ansible设置的默认roles_path,角色通常将安装到用户的~/.ansible/roles目录。默认的roles_path可能会被用户当前Ansible配置文件或环境变量ANSIBLE_ROLES_PATH覆盖,这将影响ansible-galaxy的行为。
用户可以通过使用-p DIRECTORY选项,指定具体的目录来安装角色。
在下例中,ansible-galaxy将geerlingguy.redis角色安装到playbook项目的roles目录中。命令的当前工作目录是/opt/project。
ansible-galaxy install geerlingguy.redis -p roles/
4.2.3 使用要求文件安装角色
可以使用ansible-galaxy,根据某一文本文件中的定义来安装一个角色列表。例如,如果用户的一个playbook需要安装特定的角色,可以在项目目录中创建一个roles/requirements.yml文件来指定所需的角色。此文件充当playbook项目的依赖项清单,使得playbook的开发和调试能与任何支持角色分开进行。
例如,一个用于安装geerlingguy.redis的简单requirements.yml可能类似于如下:
- src: geerlingguy.redis
version: "1.5.0"
src属性指定角色的来源,本例中为来自Ansible Galaxy的geerlingguy.redis角色。version属性是可选的,指定要安装的角色版本,本例中为1.5.0。
重要 应当在requirements.yml文件中指定角色版本,特别是生产环境中的playbook。 如果不指定版本,将会获取角色的最新版本。如果作者对角色做出了更改,并与用户的playbook不兼容,这可能会造成自动化失败或其他问题。
若要使用角色文件来安装角色,可使用-r REQUIREMENTS-FILE选项:
ansible-galaxy install -r roles/requirements.yml -p roles
用户可以使用ansible-galaxy来安装不在Ansible Galaxy中的角色。可以在私有的Git存储库或Web服务器上托管自有的专用或内部角色。下例演示了如何利用各种远程来源配置要求文件。
[root@localhost project]# cat roles/requirements.yml
# from Ansible Galaxy, using the latest version
- src: geerlingguy.redis
# from Ansible Galaxy, overriding the name and using a specific version
- src: geerlingguy.redis
version: "1.5.0"
name: redis_prod
# from any Git-based repository, using HTTPS
- src: https://gitlab.com/guardianproject-ops/ansible-nginx-acme.git
scm: git
version: 56e00a54
name: nginx-acme
# from any Git-based repository, using SSH
- src: git@gitlab.com:guardianproject-ops/ansible-nginx-acme.git
scm: git
version: master
name: nginx-acme-ssh
# from a role tar ball, given a URL
# supports 'http', 'https', or 'file' protocols
- src: file:///opt/local/roles/myrole.tar
name: myrole
src关键字指定Ansible Galaxy角色名称。如果角色没有托管在Ansible Galaxy中,则src关键字将指明角色的URL。
如果角色托管在来源控制存储库中,则需要使用scm属性。ansible-galaxy命令能够从基于git或mercurial的软件存储库下载和安装角色。基于Git的存储库要求scm值为git,而托管在Mercurial存储库中的角色则要求值为hg。如果角色托管在Ansible Galaxy中,或者以tar存档形式托管在Web服务器上,则省略scm关键字。
name关键字用于覆盖角色的本地名称。version关键字用于指定角色的版本。version关键字可以是与严自角色的软件存储库的分支、标记或提交哈希对应的任何值。
若要安装与playbook项目关联的角色,可执行ansible-galaxy install命令:
[root@localhost project]# ansible-galaxy install -r roles/requirements.yml -p roles
4.2.4 管理下载的角色
ansible-galaxy命令也可管理本地的角色,如位于playbook项目的roles目录中的角色。ansible-galaxy list子命令列出本地找到的角色。
ansible-galaxy list
可以使用ansible-galaxy remove子命令本地删除角色。
ansible-galaxy remove nginx-acme-ssh
ansible-galaxy list
在playbook中使用下载并安装的角色的方式与任何其他角色都一样。在roles部分中利用其下载的角色名称来加以引用。如果角色不在项目的roles目录中,则将检查roles_path来查看角色是否安装在了其中一个目录中,将使用第一个匹配项。以下use-role.ymlplaybook引用了redis_prod和geerlingguy.redis角色:
[root@localhost project]# cat use-role.yml
---
- name: use redis_prod for prod machines
hosts: redis_prod_servers
remote_user: devops
become: True
roles:
- redis_prod
- name: use geerlingguy.redis for Dev machines
hosts: redis_dev_servers
remote_user: devops
become: True
roles:
- geerlingguy.redis
此playbook使不同版本的geerlingguy.redis角色应用到生产和开发服务器。借助这种方式可以对角色更改进行系统化测试和集成,然后再部署到生产服务器上。如果角色的近期更改造成了问题,则借助版本控制来开发角色,就能回滚到过去某一个稳定的角色版本。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 室内设计3d建模素材网站哪家比较好?
- springboot医院自助服务系统设计与实现-附源码4853
- 实现阿里云MySQL数据库实时同步到AWS的MySQL数据库
- 美国Top科技公司年薪大曝光,OpenAI 600万高居榜首!
- 基于YOLOv8的目标跟踪技术
- 初始py和py开发工具
- SpringMVC获取请求参数
- Charles 修改请求和响应
- 何为算法之时间复杂度
- 书生·浦语:大模型全链路开源体系(二)——InternLM、Lagent、浦语·灵笔Demo调用