【Python机器学习系列】建立决策树模型预测心脏疾病(完整实现过程)
发布时间:2023年12月22日
一、问题
?? ?对于表格数据,一套完整的机器学习建模流程如下:

? ? ? 针对不同的数据集,有些步骤不适用即不需要做,其中橘红色框为必要步骤,其余步骤我将单独写文章详细介绍。同时欢迎大家关注翻看我之前的一些相关文章。
【Python机器学习系列】一文彻底搞懂机器学习中表格数据的输入形式(理论+源码)
【Python特征工程系列】利用随机森林模型分析特征重要性(源码)
【Python特征工程系列】8步教你用决策树模型分析特征重要性(源码)
【Python机器学习系列】拟合和回归傻傻分不清?一文带你彻底搞懂它
本文将实现基于心脏疾病数据集建立决策树模型对心脏疾病患者进行分类预测的完整过程。
二、实现过程
导入必要的库
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.utils import shuffle
from sklearn import preprocessing
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
from sklearn.metrics import roc_curve
from sklearn.metrics import auc
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_report1、准备数据
data = pd.read_csv(r'Dataset.csv')
df = pd.DataFrame(data)df:
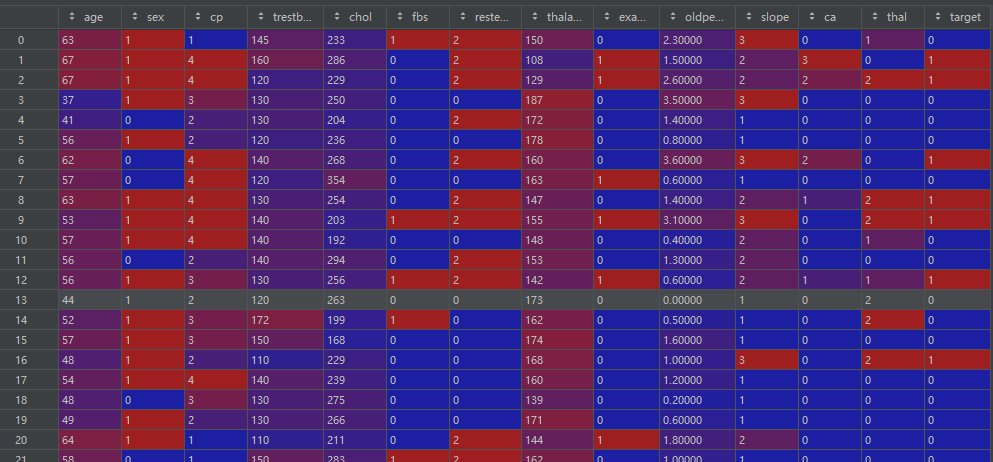
2、数据预处理
2.1 数据基本信息
print(df.head())
print(df.info())
print(df.shape)
print(df.columns)
print(df.dtypes)
cat_cols = [col for col in df.columns if df[col].dtype == "object"] # 类别型变量名
num_cols = [col for col in df.columns if df[col].dtype != "object"] # 数值型变量名2.2 错误数据检测与处理
# (略,这里不适用,单独出文章)2.3 特征编码
# (略,这里不适用,单独出文章)2.4 数据清洗
# (略,这里不适用,单独出文章)2.5 数据探索
# (略,这里不适用,单独出文章)3、提取特征变量和目标变量
target = 'target'
features = df.columns.drop(target)
print(data["target"].value_counts()) # 顺便查看一下样本是否平衡4、归一化
# (略,这里不适用,单独出文章)5、特征重要性分析与筛选
# (略,这里不适用,单独出文章)6、数据集划分
df = shuffle(df)
X_train, X_test, y_train, y_test = train_test_split(df[features], df[target], test_size=0.2, random_state=0)7、模型的构建与训练
model = DecisionTreeClassifier(max_depth=5)
model.fit(X_train, y_train)8、模型特征重要性分析
# (略,这里不适用,单独出文章)9、模型的推理与评价
y_pred = model.predict(X_test)
y_scores = model.predict_proba(X_test)
acc = accuracy_score(y_test, y_pred) # 准确率acc
cm = confusion_matrix(y_test, y_pred) # 混淆矩阵
cr = classification_report(y_test, y_pred) # 分类报告
fpr, tpr, thresholds = roc_curve(y_test, y_scores[:, 1], pos_label=1) # 计算ROC曲线和AUC值,绘制ROC曲线
roc_auc = auc(fpr, tpr)
plt.figure()
plt.plot(fpr, tpr, color='darkorange', lw=2, label='ROC curve (area = %0.2f)' % roc_auc)
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic')
plt.legend(loc="lower right")
plt.show()cm:
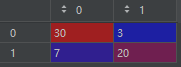
cr:
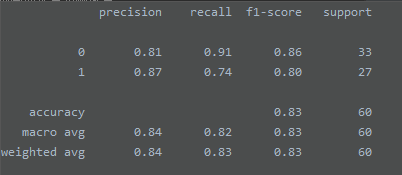
ROC:
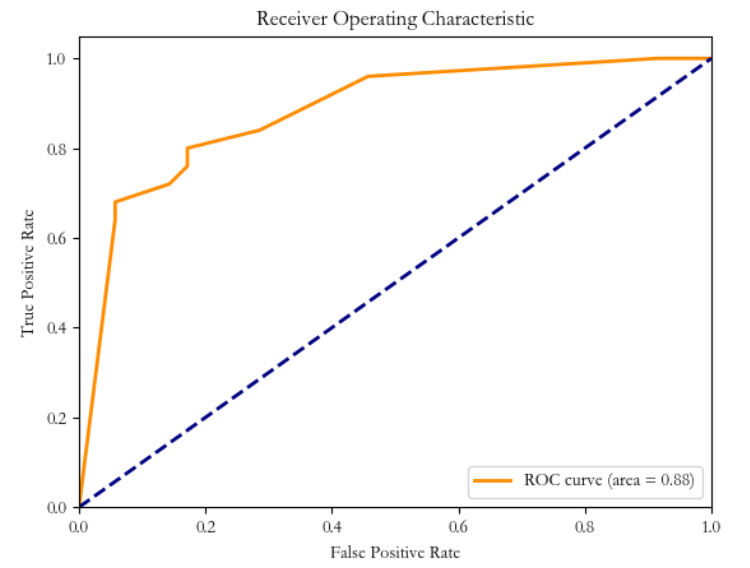
10、模型的优化
# (略,这里不适用,单独出文章)11、模型的持久化(保存)
# (略,这里不适用,单独出文章)12、模型的部署
# (略,这里不适用,单独出文章)本篇内容就到这里,我们下期再见!需要数据集和源码的小伙伴可以关注底部公众号添加作者微信哦!
作者简介:
读研期间发表6篇SCI数据挖掘相关论文,现在某研究院从事数据算法相关科研工作,结合自身科研实践经历不定期分享关于Python、机器学习、深度学习、人工智能系列基础知识与应用案例。致力于只做原创,以最简单的方式理解和学习,关注我一起交流成长。
文章来源:https://blog.csdn.net/sinat_41858359/article/details/135154802
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!