Centos安装Kafka(KRaft模式)
1. KRaft引入
Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据。其核心组件包含Producer、Broker、Consumer,以及依赖的Zookeeper集群。其中Zookeeper集群是Kafka用来负责集群元数据的管理、控制器的选举等。
由于重度依赖Zookeeper集群,当Zookeeper集群性能发生抖动时,Kafka的性能也会收到很大的影响。因此,在Kafka发展的过程当中,为了解决这个问题,提供KRaft模式,来取消Kafka对Zookeeper的依赖。
在Kafka引入KRaft新内部功能后,对Zookeeper的依赖将会被取消。在 KRaft 中,一部分 broker 被指定为控制器,这些控制器提供过去由 ZooKeeper 提供的共识服务。所有集群元数据都将存储在 Kafka 的topic中并在内部进行管理。
2. KRaft模式优势
- 更简单的部署和管理。通过只安装和管理一个应用程序,Kafka 现在的运营足迹要小得多,这也使得在边缘的小型设备中更容易利用 Kafka;
- 提高可扩展性。KRaft 的恢复时间比 ZooKeeper 快一个数量级,这使我们能够有效地扩展到单个集群中的数百万个分区。ZooKeeper 的有效限制是数万;
- 更有效的元数据传播。基于日志、事件驱动的元数据传播可以提高 Kafka 的许多核心功能的性能。
3. Kafka部署(单机版)
- jdk安装,略
- scala安装,略
- kafka安装,注意和scala版本对应。
-
下载安装包:
wget https://downloads.apache.org/kafka/3.5.2/kafka_2.12-3.5.2.tgz --no-check-certificate。
注意:kafka_2.12-3.5.2.tgz,2.12对应scala版本;3.5.2对应kafka版本。 -
解压:
tar -zxvf kafka_2.12-3.5.2.tgz -C /export/server/ -
创建数据存储目录:
mkdir /data/kafka_kraft-combined-log -
修改配置文件:
vim kafka_2.12-3.5.2/config/kraft/server.properties# Kafka broker对外公布的监听地址和端口 advertised.listeners=PLAINTEXT://192.168.1.6:9092 # Kafka存储数据的目录 log.dirs=/data/kafka_kraft-combined-log -
格式化存储目录
执行命令:kafka_2.12-3.5.2/bin/kafka-storage.sh random-uuid,得到一个uuid:xxxxx…
执行命令:kafka_2.12-3.5.2/bin/kafka-storage.sh format -t xxxxx -c config/kraft/server.properties,格式化存储目录。格式化之后的存储目录多了以下两个文件:

-
安装完成,开始使用吧。
-
4. Kafka使用
-
单机启动:
kafka_2.12-3.5.2/bin/kafka-server-start.sh -daemon config/kraft/server.properties -
单机停止:
kafka_2.12-3.5.2/bin/kafka-server-stop.sh -
查看进程

-
创建topic:
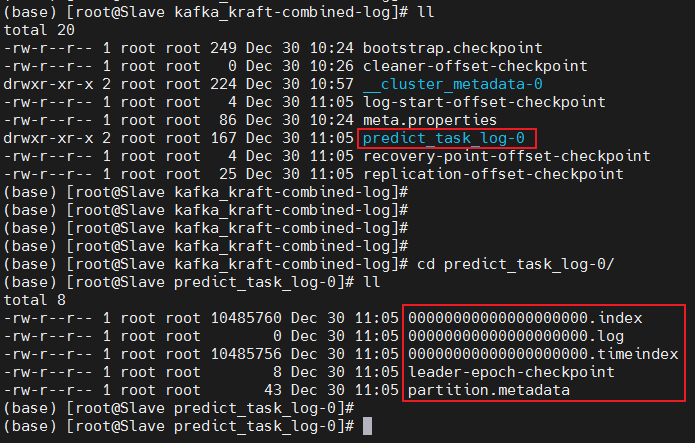
kafka_2.12-3.5.2/bin/kafka-topics.sh --create --topic predict_task_log --bootstrap-server 192.168.1.6:9092创建完topic之后,会在数据存储目录自动新增目录用来存放该topic数据。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Talk | 北京大学博士生汪海洋:通向3D感知大模型的前置方案
- 谷达冠楠:抖音运营工作内容大概有哪些
- 【优化方案】Java 将字符串中的星号替换为0-9中的数字,并返回所有可能的替换结果
- LeetCode 0410.分割数组的最大值:二分
- 【代码随想录算法训练营-第十天】【栈与队列】232.用栈实现队列,225. 用队列实现栈
- 读AI3.0笔记02_起源
- flutter base64图片保存到相册
- devc++添加C++11编译环境
- 医院患者满意度问卷如何设计
- android自定义来电秀UI