Redis入门详解(二)—Redis缓存策略、持久化策略、集群相关
1、Redis配置文件解读
????????通过redis客户端使用config get * 命令可以获取配置文件中所有信息(不包含注释起来的信息),我们对其中常用的几个配置进行注释讲解
9) "save" //自动持久化策略,3600 1位一组设置,表示在3600秒内至少有一次修改操作则执行持久化
10) "3600 1 300 100 60 10000"
41) "maxmemory-policy" //缓存淘汰策略,默认为noeviction,直接报错
42) "noeviction"
83) "slaveof" //主从复制
84) ""
93) "maxmemory" //指定redis最大内存限制
94) "0"
99) "rdbcompression" //快照文件是否压缩,默认为压缩
100) "yes"
113) "daemonize"
//默认情况下,redis不是在后台运行的(即会开一个窗口)。如果需要在后台运行,把该项的值更改为yes
114) "no"
231) "appendfilename" //AOF文件名称
232) "appendonly.aof"
261) "databases" //数据库数量,默认为16个
262) "16"
325) "dbfilename" //RDB快照文件名称,使用默认就好
326) "dump.rdb"
343) "appendonly" //AOF持久化策略,默认为关闭,如果需要开启则改为yes
344) "no"
347) "appendfsync"
//AOF频率,写命令执行完先放入AOF缓冲区,然后表示每隔1秒将缓冲区数据写到AOF文件
348) "everysec"
2、Redis缓存的使用原则
????????Redis的出现可以说是为了在面对互联网的海量数据下,为了解决CPU服务压力,维持五福的高可用而出现的技术,因为他基于内存,运行速度快,能够很大程度上分担数据库的压力,并且能够提升效率,从而提升服务器的并发量;
? ? ? ? 当一个请求进行访问时,会先到达redis缓存,如果redis缓存中存在目标数据,则直接返回给客户端,如果缓存中没有则再执行数据库的查询。但是这样也面临一个数据同步的问题,当我们执行某些操作更新了数据库中的某些数据时,这些数据并不会同步给redis,从而导致接下来用户的查询结果数据可能是过期的,因此,在redis的缓存使用上,
? ? ? ? 1、如果是需要频繁修改的数据,我们一般不使用Redis进行缓存(例如商品库存);
? ? ? ? 2、我们需要设置redia缓存的时效性(淘汰策略),因为redis是基于内存的,而内存的空间是有限的,所以其中的数据两不能过大
3、Redis缓存的淘汰策略
????????如果Redis服务器的内存已经全满,现在还需要向Redis中保存新的数据,如何操作,就是缓存淘汰策略可以通过配置文件的maxmemory-policy属性去修改对应的策略????????
- noeviction:返回错误**(默认)**
- allkeys-random:所有数据中随机删除数据
- volatile-random:随机删除就将过期的数据
- volatile-ttl:删除剩余有效时间最少的数据
- allkeys-lru:所有数据中删除上次使用时间最久的数据
- volatile-lru:有过期时间的数据中删除上次使用时间最久的数据
- allkeys-lfu:所有数据中删除使用频率最少的
- volatile-lfu:有过期时间的数据中删除使用频率最少的
?4、Redis缓存穿透、击穿和雪崩的理解
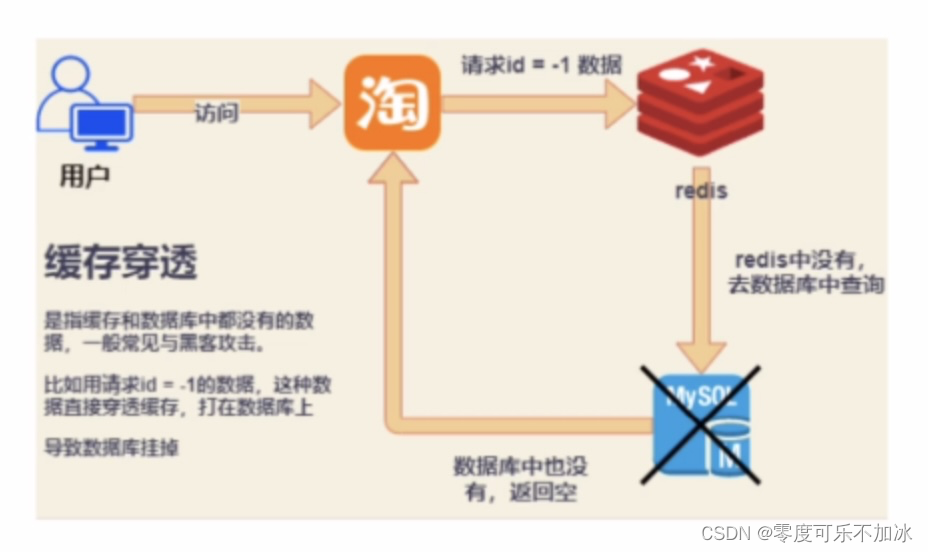
? ? ? ? ①缓存穿透
????????正常业务下,一个请求查询到数据后,我们可以将这个数据保存在Redis,之后的请求都可以直接从Redis查询,就不需要再连接数据库了,如果一个请求查询的数据,数据库中也没有这就是缓存穿透,一般出现缓存穿透就是属于恶意攻击导致了,如图:
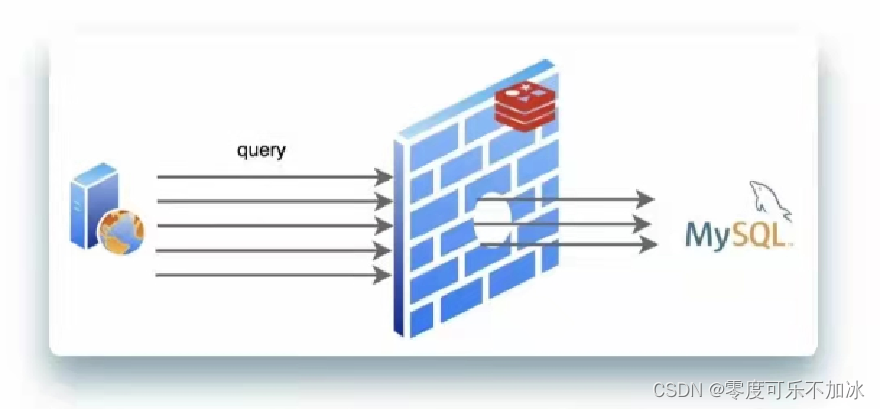
? ? ? ? ②缓存击穿?
????????一个计划在Redis保存的数据,业务查询,查询到的数据Redis中没有,但是数据库中有,这种情况要从数据库中查询后再保存到Redis,这就是缓存击穿;这个情况看似很正常的流程,但如果原本大量访问相同key的时效突然过期了,则这些请求就会同时访问数据库导致服务器有宕机的风险。
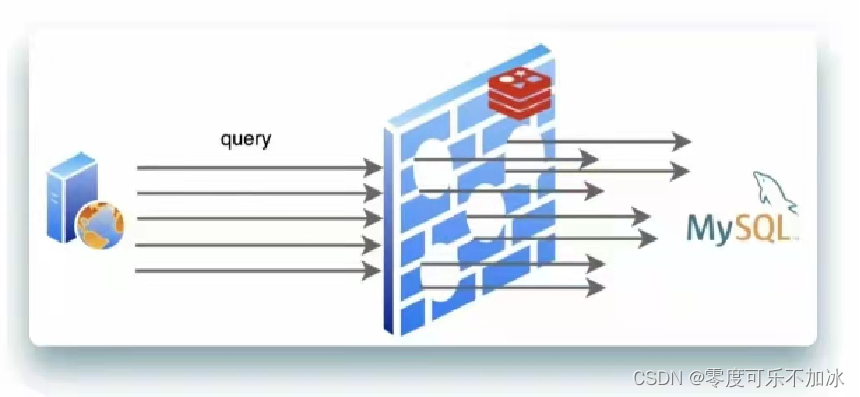
?③缓存雪崩
????????上面讲到击穿现象,同一时间发生少量击穿是正常的,但是如果出现同一时间大量击穿现象就会如下图,造成缓存雪崩的现象,例如当大量的热点key都设置了相同的有效期,则在某一个时间这些key会同时失效,则就造成了大量的不同的请求都涌向了数据库服务器
5、Redis数据安全问题——数据持久化策略
? ? ? ? ①RDB策略?
????????RDB全称Redis Database Backup file(Redis数据备份文件),也被叫做Redis数据快照。简单来说就是把内存中的所有数据都记录到磁盘中。当Redis实例故障重启后,从磁盘读取快照文件,恢复数据。快找文件默认保存在Redis的src目录下的dump.rdb文件中。
RDB持久化策略会在以下四种条件下触发:
- 执行save命令
- 执行bgsave命令
- Redis停机时
- 触发RDB条件时(自动触发),例如
save 3600 1 3600 秒(60分钟)内至少有一次修改则触发保存操作 save 300 100 300 秒(5分钟)内至少有 100 次修改则触发保存操作 save 60 10000 60 秒(1分钟)内至少有 1 万次修改则触发保存操作 - 如果不想触发持久化机制就将配置改为? save" "
? ? ? ? RDB持久化原理
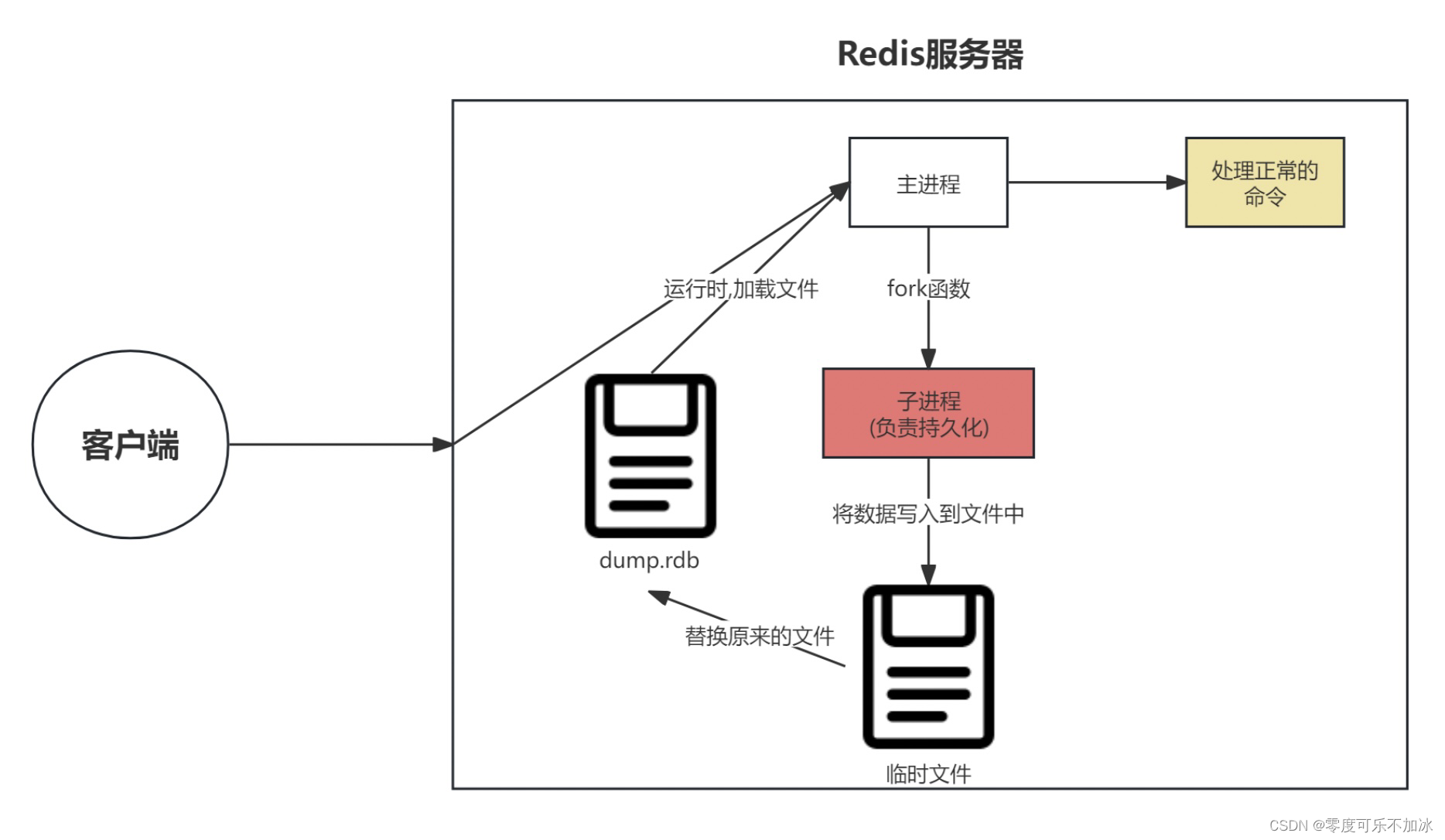
? ? ? ? 当客户端请求访问redis服务器时,首先会有一条主线程,这条主线程就是负责接待来访请求,如果此时触发了持久化机制,主进程就会fork一条子进程(fork就是创建一条新线程的意思),这条子进程所做的事情就是将数据写入到一个临时文件中,如果此时本地已经有一个dump.rdb文件,则会做一个替换操作。
? ? ? ? RDB持久化策略也存在问题,当子进程在将主进程中的文件写入临时文件的过程中如果突然发生问题(例如断点等),则此时正在写入的数据一定都会消失,也就更不会做替换操作
? ? ? ? ②AOF模式?
????????和RDB持久化类似,当开启AOF策略后,在src目录下会出现appendonly.aof持久化文件,AOF策略有三种不同的持久化模式,
表示每执行一次写命令,立即记录到AOF文件 appendfsync always 写命令执行完先放入AOF缓冲区,然后表示每隔1秒将缓冲区数据写到AOF文件,是默认方案 appendfsync everysec 写命令执行完先放入AOF缓冲区,由操作系统决定何时将缓冲区内容写回磁盘 appendfsync no
三种策略对比:

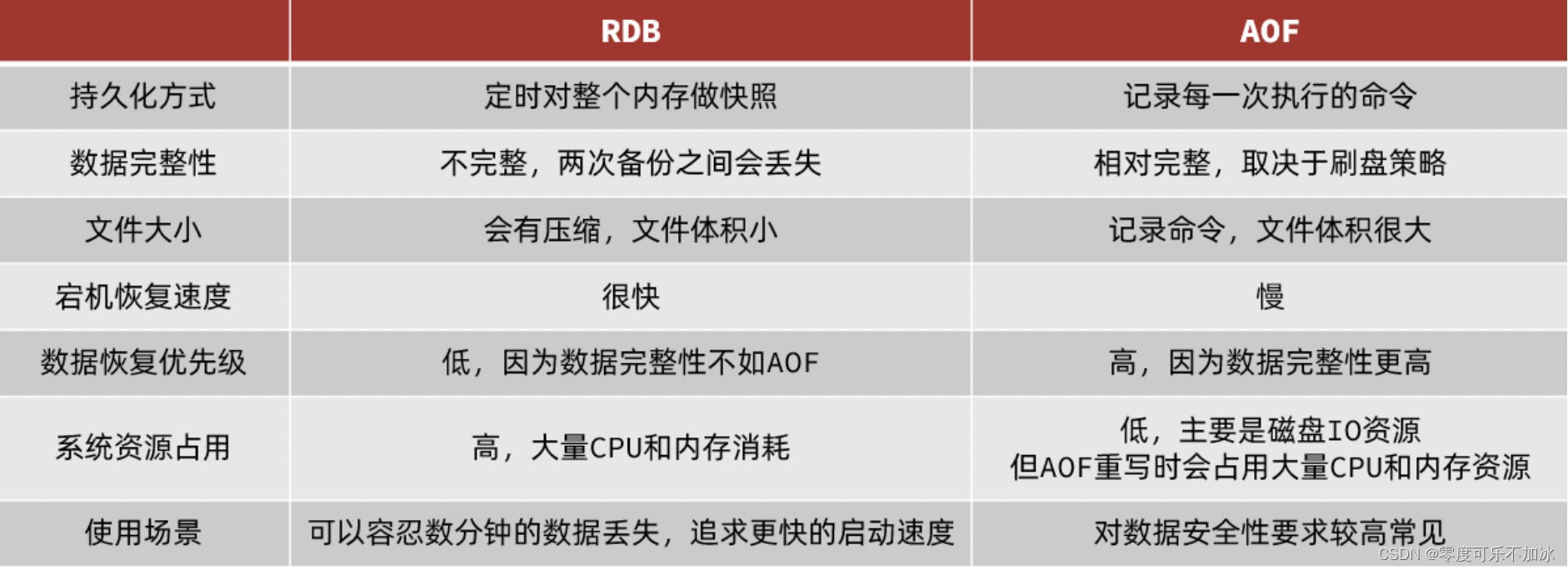
?③RDB策略与AOF策略对比(面试常用,可以截图保存哦!)
简单来说,RDB就是备份结果,AOF是备份过程,他们的对比如下图:
?6、Redis集群
简单理解集群概念:
????????Redis最小状态是一台服务器,这个服务器的运行状态,直接决定Redis是否可用,如果它离线了,整个项目就会无Redis可用,系统会面临崩溃,为了防止这种情况的发生,我们可以准备一台备用机,这个备用机就是从机,那这样的主机和从机搭建起来的结构我们就叫做集群。
①主从复制
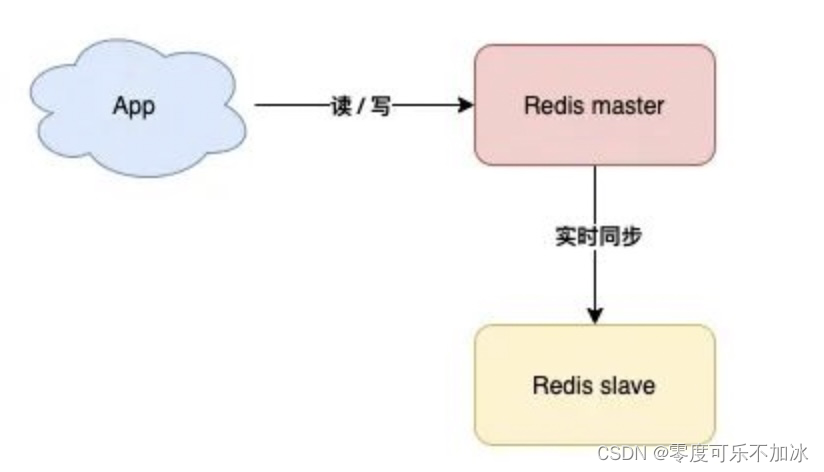
也就是主机(master)工作时,安排一台备用机(slave)实时同步数据,万一主机宕机,我们可以切换到备机运行
缺点:这样的方案,slave节点没有任何实质作用,只要master不宕机它就和没有一样,没有体现价值,因此出现了读写分离。
②读写分离

主机拥有读写的权限,从机拥有读取的权限,这样从机在主机正常工作时也能分担Master的工作了,但是如果master宕机,实际上主备机的切换,实际上还是需要人工介入的,这还是需要时间的,那么如果想实现故障时自动切换,一定是有配置好的固定策略的,因此有了哨兵模式。
③哨兵模式
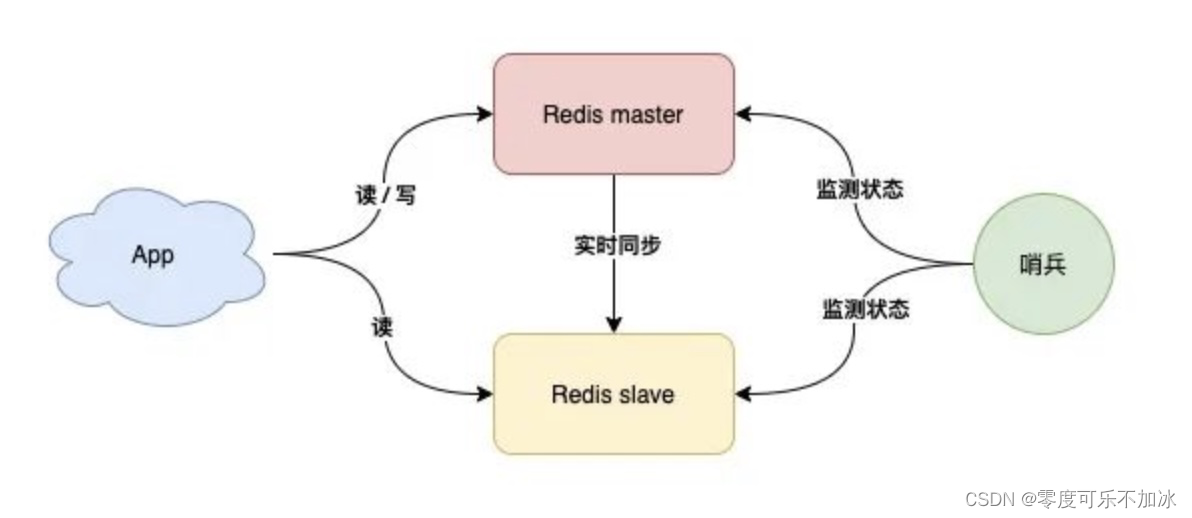
?
????????哨兵节点每隔固定时间向所有节点发送请求,如果正常响应认为该节点正常;如果没有响应,认为该节点出现问题,哨兵能自动切换主备机;如果主机master下线,自动切换到备机运行。
????????但是这样的模式存在问题,如果哨兵判断节点状态时发生了误判,那么就会错误将master下线,降低整体运行性能,因此就有了哨兵集群。
④哨兵集群

哨兵集群中,每个节点都会定时向master和slave发送ping请求,如果ping请求有2个(集群的半数节点)以上的哨兵节点没有收到正常响应,会认为该节点下线
⑤分片集群
当业务不断扩展,并发不断增高时,只有一个节点支持写操作无法满足整体性能要求时,系统性能就会到达瓶颈,这时我们就要部署多个支持写操作的节点,进行分片来提高程序整体性能
——————————————————————————————————————
路漫漫其修远兮,吾将上下而求索~
到此关于Redis的入门部分的讲解就就全部结束啦,写作不易,如果你认为博主写的不错!
请点赞、关注、评论给博主一个鼓励吧,您的鼓励就是博主前进的动力。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- shell脚本算术运算
- Python爬虫之使用代理IP池维护虚拟用户
- 阿里云 ACK One Serverless Argo 助力深势科技构建高效任务平台
- 【Unity】Joystick Pack摇杆插件实现锁四向操作
- 浪涌抑制器的未来发展如何?|深圳比创达电子
- 什么是泛型, 泛型的具体使用
- x-cmd pkg | jq - 命令行 JSON 处理器
- 2024华数杯国际赛B题高质量参考论文+所有小问数据代码+数据集整合
- msvcp140.dll丢失的错误解决办法,msvcp140.dll丢失的原因
- 征集倒计时 | 2023年卓越影响力榜单-第四届中国产业创新奖报名即将截止