01|LangChain系统安装和快速入门
01|LangChain系统安装和快速入门
什么是大语言模型
大语言模型是一种人工智能模型,通常使用深度学习技术,比如神经网络,来理解和生成人类语言。这些模型的“大”在于它们的参数数量非常多,可以达到数十亿甚至更多,这使得它们能够理解和生成高度复杂的语言模式。
你可以将大语言模型想象成一个巨大的预测机器,其训练过程主要基于“猜词”:给定一段文本的开头,它的任务就是预测下一个词是什么。模型会根据大量的训练数据(例如在互联网上爬取的文本),试图理解词语和词组在语言中的用法和含义,以及它们如何组合形成意义。它会通过不断地学习和调整参数,使得自己的预测越来越准确。
语言模型帮我们预测下一个词
比如我们给模型一个句子:“今天的天气真”,模型可能会预测出“好”作为下一个词,因为在它看过的大量训练数据中,“今天的天气真好”是一个常见的句子。这种预测并不只基于词语的统计关系,还包括对上下文的理解,甚至有时能体现出对世界常识的认知,比如它会理解到,人们通常会在天气好的时候进行户外活动。因此也就能够继续生成或者说推理出相关的内容。
但是,大语言模型并不完全理解语言,它们没有人类的情感、意识或理解力。它们只是通过复杂的数学函数学习到的语言模式,一个概率模型来做预测,所以有时候它们会犯错误,或者生成不合理甚至偏离主题的内容。
咱们当然还是主说 LangChain。LangChain 是一个全方位的、基于大语言模型这种预测能力的应用开发工具,它的灵活性和模块化特性使得处理语言模型变得极其简便。不论你在何时何地,都能利用它流畅地调用语言模型,并基于语言模型的“预测”或者说“推理”能力开发新的应用。
LangChain 的标志,我想是1只能说会道的鹦鹉+1个链条
LangChain 的预构建链功能,就像乐高积木一样,无论你是新手还是经验丰富的开发者,都可以选择适合自己的部分快速构建项目。对于希望进行更深入工作的开发者,LangChain 提供的模块化组件则允许你根据自己的需求定制和创建应用中的功能链条。
LangChain 支持 Python 和 JavaScript 两个开发版本,我们这个教程中全部使用 Python 版本进行讲解。
安装 LangChain
LangChain 的基本安装特别简单。
pip install langchain
这是安装 LangChain 的最低要求。这里我要提醒你一点,LangChain 要与各种模型、数据存储库集成,比如说最重要的 OpenAI 的 API 接口,比如说开源大模型库 HuggingFace Hub,再比如说对各种向量数据库的支持。默认情况下,是没有同时安装所需的依赖项。
也就是说,当你 pip install langchain 之后,可能还需要 pip install openai、pip install chroma(一种向量数据库)……
用下面两种方法,我们就可以在安装 LangChain 的方法时,引入大多数的依赖项。
安装 LangChain 时包括常用的开源 LLM(大语言模型) 库:
pip install langchain[llms]
安装完成之后,还需要更新到 LangChain 的最新版本,这样才能使用较新的工具。
pip install --upgrade langchain
如果你想从源代码安装,可以克隆存储库并运行:
pip install -e
我个人觉得非常好的学习渠道也在这儿分享给你。
LangChain 的 GitHub 社区非常活跃,你可以在这里找到大量的教程和最佳实践,也可以和其他开发者分享自己的经验和观点。
LangChain 也提供了详尽的 API 文档,这是你在遇到问题时的重要参考。不过呢,我觉得因为 LangChain 太新了,有时你可能会发现文档中有一些错误。在这种情况下,你可以考虑更新你的版本,或者在官方平台上提交一个问题反馈。
当我遇到问题,我通常会在 LangChain 的 GitHub 开一个 Issue,很快就可以得到解答。
我 Log 的 LangChain Issue 得到了解答
跟着 LangChain 其快速的更新步伐,你就能在这个领域取得显著的进步。
OpenAI API
下面我想说一说 OpenAI 的 API。
关于 ChatGPT 和 GPT-4,我想就没有必要赘言了,网上已经有太多资料了。但是要继续咱们的 LangChain 实战课,你需要对 OpenAI 的 API 有进一步的了解。因为,LangChain 本质上就是对各种大模型提供的 API 的套壳,是为了方便我们使用这些 API,搭建起来的一些框架、模块和接口。
因此,要了解 LangChain 的底层逻辑,需要了解大模型的 API 的基本设计思路。而目前接口最完备的、同时也是最强大的大语言模型,当然是 OpenAI 提供的 GPT 家族模型。

当然,要使用 OpenAI API,你需要先用科学的方法进行注册,并得到一个 API Key。
有了 OpenAI 的账号和 Key,你就可以在面板中看到各种信息,比如模型的费用、使用情况等。下面的图片显示了各种模型的访问数量限制信息。其中,TPM 和 RPM 分别代表 tokens-per-minute、requests-per-minute。也就是说,对于 GPT-4,你通过 API 最多每分钟调用 200 次、传输 40000 个字节。
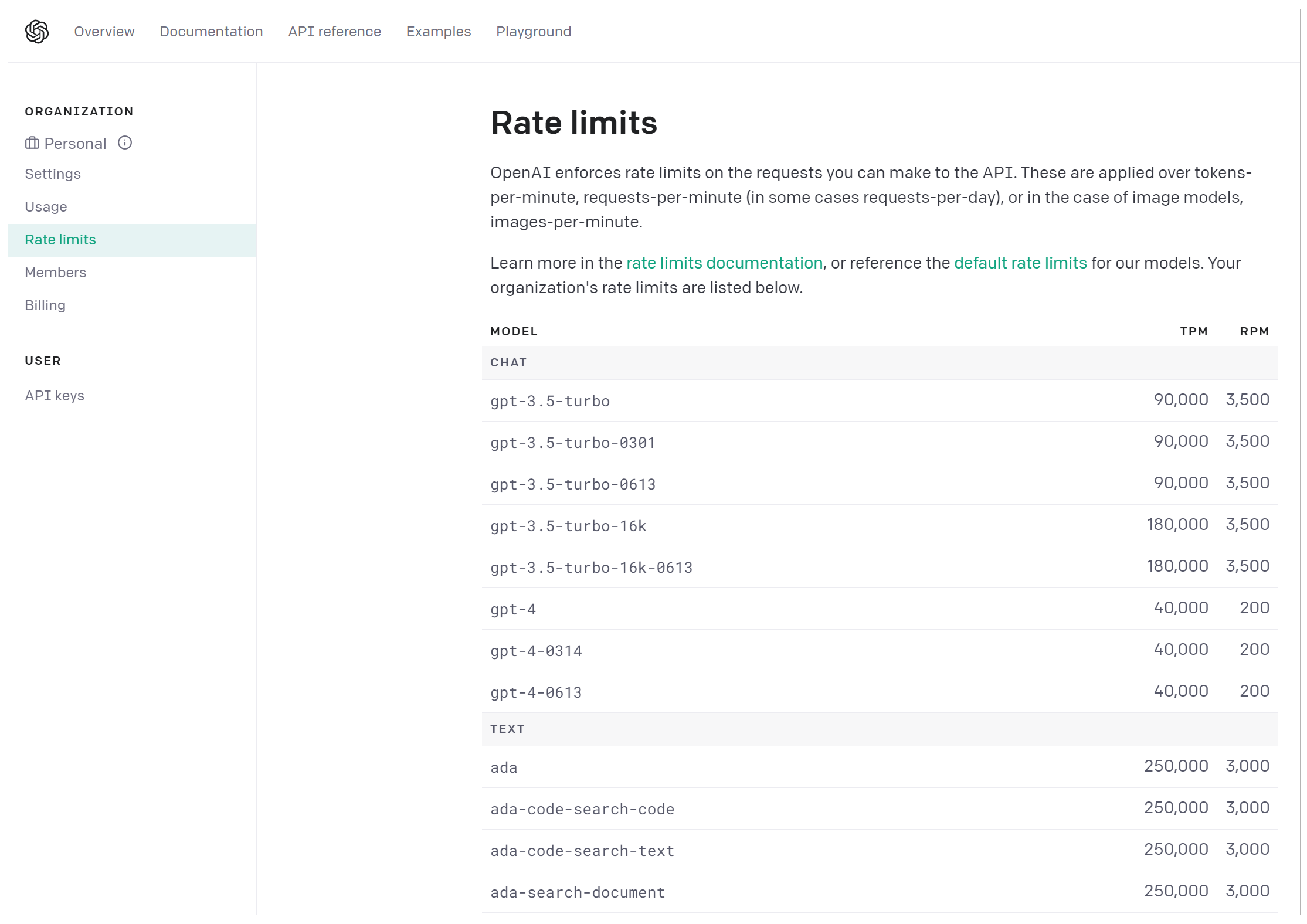
这里,我们需要重点说明的两类模型,就是图中的 Chat Model 和 Text Model。这两类 Model,是大语言模型的代表。当然,OpenAI 还提供 Image、Audio 和其它类型的模型,目前它们不是 LangChain 所支持的重点,模型数量也比较少。
- Chat Model,聊天模型,用于产生人类和 AI 之间的对话,代表模型当然是 gpt-3.5-turbo(也就是 ChatGPT)和 GPT-4。当然,OpenAI 还提供其它的版本,gpt-3.5-turbo-0613 代表 ChatGPT 在 2023 年 6 月 13 号的一个快照,而 gpt-3.5-turbo-16k 则代表这个模型可以接收 16K 长度的 Token,而不是通常的 4K。(注意了,gpt-3.5-turbo-16k 并未开放给我们使用,而且你传输的字节越多,花钱也越多)
- Text Model,文本模型,在 ChatGPT 出来之前,大家都使用这种模型的 API 来调用 GPT-3,文本模型的代表作是 text-davinci-003(基于 GPT3)。而在这个模型家族中,也有专门训练出来做文本嵌入的 text-embedding-ada-002,也有专门做相似度比较的模型,如 text-similarity-curie-001。
上面这两种模型,提供的功能类似,都是接收对话输入(input,也叫 prompt),返回回答文本(output,也叫 response)。但是,它们的调用方式和要求的输入格式是有区别的,这个我们等下还会进一步说明。
下面我们用简单的代码段说明上述两种模型的调用方式。先看比较原始的 Text 模型(GPT3.5 之前的版本)。
调用 Text 模型
第 1 步,先注册好你的 API Key。
第 2 步,用 pip install openai 命令来安装 OpenAI 库。
第 3 步,导入 OpenAI API Key。
导入 API Key 有多种方式,其中之一是通过下面的代码:
import osos.environ["OPENAI_API_KEY"] = '你的Open API Key'
OpenAI 库就会查看名为 OPENAI_API_KEY 的环境变量,并使用它的值作为 API 密钥。
也可以像下面这样先导入 OpenAI 库,然后指定 api_key 的值。
import openaiopenai.api_key = '你的Open API Key'
当然,这种把 Key 直接放在代码里面的方法最不可取,因为你一不小心共享了代码,密钥就被别人看到了,他就可以使用你的 GPT-4 资源!所以,建议你给自己的 OpenAI 账户设个上限,比如每月 10 美元啥的。
所以更好的方法是在操作系统中定义环境变量,比如在 Linux 系统的命令行中使用:
export OPENAI_API_KEY='你的Open API Key'
或者,你也可以考虑把环境变量保存在.env 文件中,使用 python-dotenv 库从文件中读取它,这样也可以降低 API 密钥暴露在代码中的风险。
第 4 步,导入 OpenAI 库。(如果你在上一步导入 OpenAI API Key 时并没有导入 OpenAI 库)
import openai
第 5 步,调用 Text 模型,并返回结果。
response = openai.Completion.create(
model="text-davinci-003",
temperature=0.5,
max_tokens=100,
prompt="请给我的花店起个名")
在使用 OpenAI 的文本生成模型时,你可以通过一些参数来控制输出的内容和样式。这里我总结为了一些常见的参数。

第 6 步,打印输出大模型返回的文字。
print(response.choices[0].text.strip())
当你调用 OpenAI 的 Completion.create 方法时,它会返回一个响应对象,该对象包含了模型生成的输出和其他一些信息。这个响应对象是一个字典结构,包含了多个字段。
在使用 Text 模型(如 text-davinci-003)的情况下,响应对象的主要字段包括:

choices 字段是一个列表,因为在某些情况下,你可以要求模型生成多个可能的输出。每个选择都是一个字典,其中包含以下字段:
- text:模型生成的文本。
- finish_reason:模型停止生成的原因,可能的值包括 stop(遇到了停止标记)、length(达到了最大长度)或 temperature(根据设定的温度参数决定停止)。
所以,response.choices[0].text.strip() 这行代码的含义是:从响应中获取第一个(如果在调用大模型时,没有指定 n 参数,那么就只有唯一的一个响应)选择,然后获取该选择的文本,并移除其前后的空白字符。这通常是你想要的模型的输出。
至此,任务完成,模型的输出如下:
心动花庄、芳华花楼、轩辕花舍、簇烂花街、满园春色
不错。下面,让我们再来调用 Chat 模型(GPT-3.5 和 GPT-4)。
调用 Chat 模型
整体流程上,Chat 模型和 Text 模型的调用是完全一样的,只是输入(prompt)和输出(response)的数据格式有所不同。
示例代码如下:
response = openai.ChatCompletion.create(
model="gpt-4",
messages=[
{"role": "system", "content": "You are a creative AI."},
{"role": "user", "content": "请给我的花店起个名"},
],
temperature=0.8,
max_tokens=60
)
print(response['choices'][0]['message']['content'])
这段代码中,除去刚才已经介绍过的 temperature、max_tokens 等参数之外,有两个专属于 Chat 模型的概念,一个是消息,一个是角色!
先说消息,消息就是传入模型的提示。此处的 messages 参数是一个列表,包含了多个消息。每个消息都有一个 role(可以是 system、user 或 assistant)和 content(消息的内容)。系统消息设定了对话的背景(你是一个很棒的智能助手),然后用户消息提出了具体请求(请给我的花店起个名)。模型的任务是基于这些消息来生成回复。
再说角色,在 OpenAI 的 Chat 模型中,system、user 和 assistant 都是消息的角色。每一种角色都有不同的含义和作用。
- system:系统消息主要用于设定对话的背景或上下文。这可以帮助模型理解它在对话中的角色和任务。例如,你可以通过系统消息来设定一个场景,让模型知道它是在扮演一个医生、律师或者一个知识丰富的 AI 助手。系统消息通常在对话开始时给出。
- user:用户消息是从用户或人类角色发出的。它们通常包含了用户想要模型回答或完成的请求。用户消息可以是一个问题、一段话,或者任何其他用户希望模型响应的内容。
- assistant:助手消息是模型的回复。例如,在你使用 API 发送多轮对话中新的对话请求时,可以通过助手消息提供先前对话的上下文。然而,请注意在对话的最后一条消息应始终为用户消息,因为模型总是要回应最后这条用户消息。
在使用 Chat 模型生成内容后,返回的响应,也就是 response 会包含一个或多个 choices,每个 choices 都包含一个 message。每个 message 也都包含一个 role 和 content。role 可以是 system、user 或 assistant,表示该消息的发送者,content 则包含了消息的实际内容。
一个典型的 response 对象可能如下所示:
{
'id': 'chatcmpl-2nZI6v1cW9E3Jg4w2Xtoql0M3XHfH',
'object': 'chat.completion',
'created': 1677649420,
'model': 'gpt-4',
'usage': {'prompt_tokens': 56, 'completion_tokens': 31, 'total_tokens': 87},
'choices': [
{
'message': {
'role': 'assistant',
'content': '你的花店可以叫做"花香四溢"。'
},
'finish_reason': 'stop',
'index': 0
}
]
}
以下是各个字段的含义:
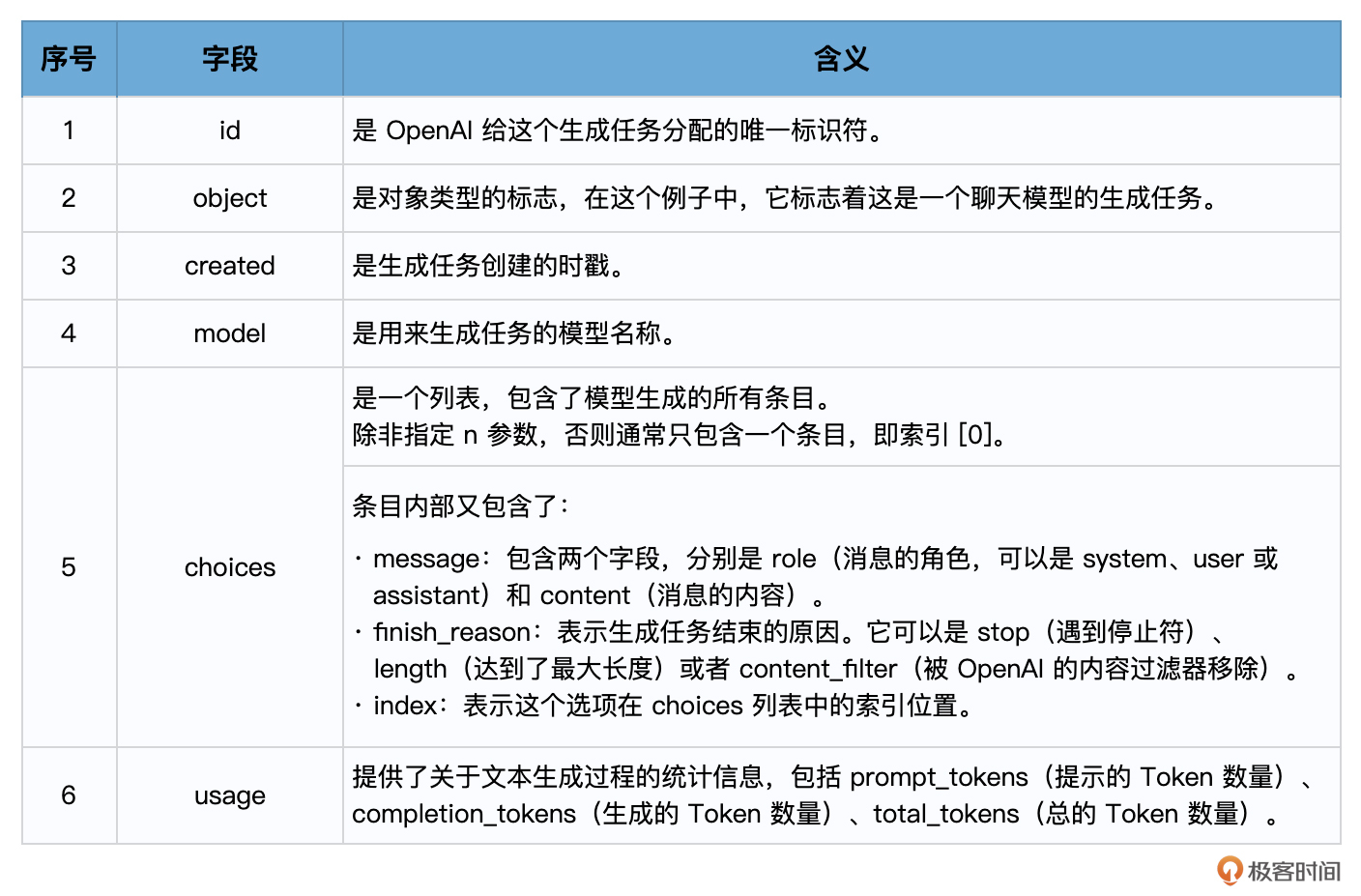
这就是 response 的基本结构,其实它和 Text 模型返回的响应结构也是很相似,只是 choices 字段中的 Text 换成了 Message。你可以通过解析这个对象来获取你需要的信息。例如,要获取模型的回复,可使用 response[‘choices’][0][‘message’][‘content’]。
Chat 模型 vs Text 模型
Chat 模型和 Text 模型都有各自的优点,其适用性取决于具体的应用场景。
相较于 Text 模型,Chat 模型的设计更适合处理对话或者多轮次交互的情况。这是因为它可以接受一个消息列表作为输入,而不仅仅是一个字符串。这个消息列表可以包含 system、user 和 assistant 的历史信息,从而在处理交互式对话时提供更多的上下文信息。
这种设计的主要优点包括:
- 对话历史的管理:通过使用 Chat 模型,你可以更方便地管理对话的历史,并在需要时向模型提供这些历史信息。例如,你可以将过去的用户输入和模型的回复都包含在消息列表中,这样模型在生成新的回复时就可以考虑到这些历史信息。
- 角色模拟:通过 system 角色,你可以设定对话的背景,给模型提供额外的指导信息,从而更好地控制输出的结果。当然在 Text 模型中,你在提示中也可以为 AI 设定角色,作为输入的一部分。
然而,对于简单的单轮文本生成任务,使用 Text 模型可能会更简单、更直接。例如,如果你只需要模型根据一个简单的提示生成一段文本,那么 Text 模型可能更适合。从上面的结果看,Chat 模型给我们输出的文本更完善,是一句完整的话,而 Text 模型输出的是几个名字。这是因为 ChatGPT 经过了对齐(基于人类反馈的强化学习),输出的答案更像是真实聊天场景。
好了,我们对 OpenAI 的 API 调用,理解到这个程度就可以了。毕竟我们主要是通过 LangChain 这个高级封装的框架来访问 Open AI。
通过 LangChain 调用 Text 和 Chat 模型
最后,让我们来使用 LangChain 来调用 OpenAI 的 Text 和 Chat 模型,完成了这两个任务,我们今天的课程就可以结束了!
调用 Text 模型
代码如下:
import os
os.environ["OPENAI_API_KEY"] = '你的Open API Key'
from langchain.llms import OpenAI
llm = OpenAI(
model="text-davinci-003",
temperature=0.8,
max_tokens=60,)
response = llm.predict("请给我的花店起个名")
print(response)
输出:
花之缘、芳华花店、花语心意、花风旖旎、芳草世界、芳色年华
这只是一个对 OpenAI API 的简单封装:先导入 LangChain 的 OpenAI 类,创建一个 LLM(大语言模型)对象,指定使用的模型和一些生成参数。使用创建的 LLM 对象和消息列表调用 OpenAI 类的 call 方法,进行文本生成。生成的结果被存储在 response 变量中。没有什么需要特别解释之处。
调用 Chat 模型
代码如下:
import os
os.environ["OPENAI_API_KEY"] = '你的Open API Key'
from langchain.chat_models import ChatOpenAI
chat = ChatOpenAI(model="gpt-4",
temperature=0.8,
max_tokens=60)
from langchain.schema import (
HumanMessage,
SystemMessage
)
messages = [
SystemMessage(content="你是一个很棒的智能助手"),
HumanMessage(content="请给我的花店起个名")
]
response = chat(messages)
print(response)
这段代码也不难理解,主要是通过导入 LangChain 的 ChatOpenAI 类,创建一个 Chat 模型对象,指定使用的模型和一些生成参数。然后从 LangChain 的 schema 模块中导入 LangChain 的 SystemMessage 和 HumanMessage 类,创建一个消息列表。消息列表中包含了一个系统消息和一个人类消息。你已经知道系统消息通常用来设置一些上下文或者指导 AI 的行为,人类消息则是要求 AI 回应的内容。之后,使用创建的 chat 对象和消息列表调用 ChatOpenAI 类的 call 方法,进行文本生成。生成的结果被存储在 response 变量中。
输出:
content='当然可以,叫做"花语秘境"怎么样?' additional_kwargs={} example=False
从响应内容“当然可以,叫做‘花语秘境’怎么样?”不难看出,GPT-4 的创造力真的是胜过 GPT-3,她给了我们这么有意境的一个店名,比我自己起的“易速鲜花”好多了。
另外,无论是 langchain.llms 中的 OpenAI(Text 模型),还是 langchain.chat_models 中的 ChatOpenAI 中的 ChatOpenAI(Chat 模型),其返回的结果 response 变量的结构,都比直接调用 OpenAI API 来得简单一些。这是因为,LangChain 已经对大语言模型的 output 进行了解析,只保留了响应中最重要的文字部分。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 基于鲸鱼算法优化的BP神经网络实现温度数据预测
- LMDeploy 的量化和部署
- Android开发中如何进行单元测试?
- call_once 单例模式 Singleton / condition_variable 与其使用场景
- linux gdb反汇编定位问题
- 电缆护层保护器维护方法详解
- 光学期刊1
- vue简易瀑布流
- YOLOv8改进 | 2023Neck篇 | 利用Gold-YOLO改进YOLOv8对小目标检测
- Trino: 基于时间片的Split数据处理模型