logstack 日志技术栈-02-ELK 的缺点?loki 更轻量的解决方案?
ELK/EFK日志系统
如果今天谈论到要部署一套日志系统,相信用户首先会想到的就是经典的ELK架构,或者现在被称为Elastic Stack。
Elastic Stack架构为Elasticsearch + Logstash + Kibana + Beats的组合,其中,Beats负责日志的采集, Logstash负责做日志的聚合和处理,Elasticsearch作为日志的存储和搜索系统,Kibana作为可视化前端展示,整体架构如下图所示:
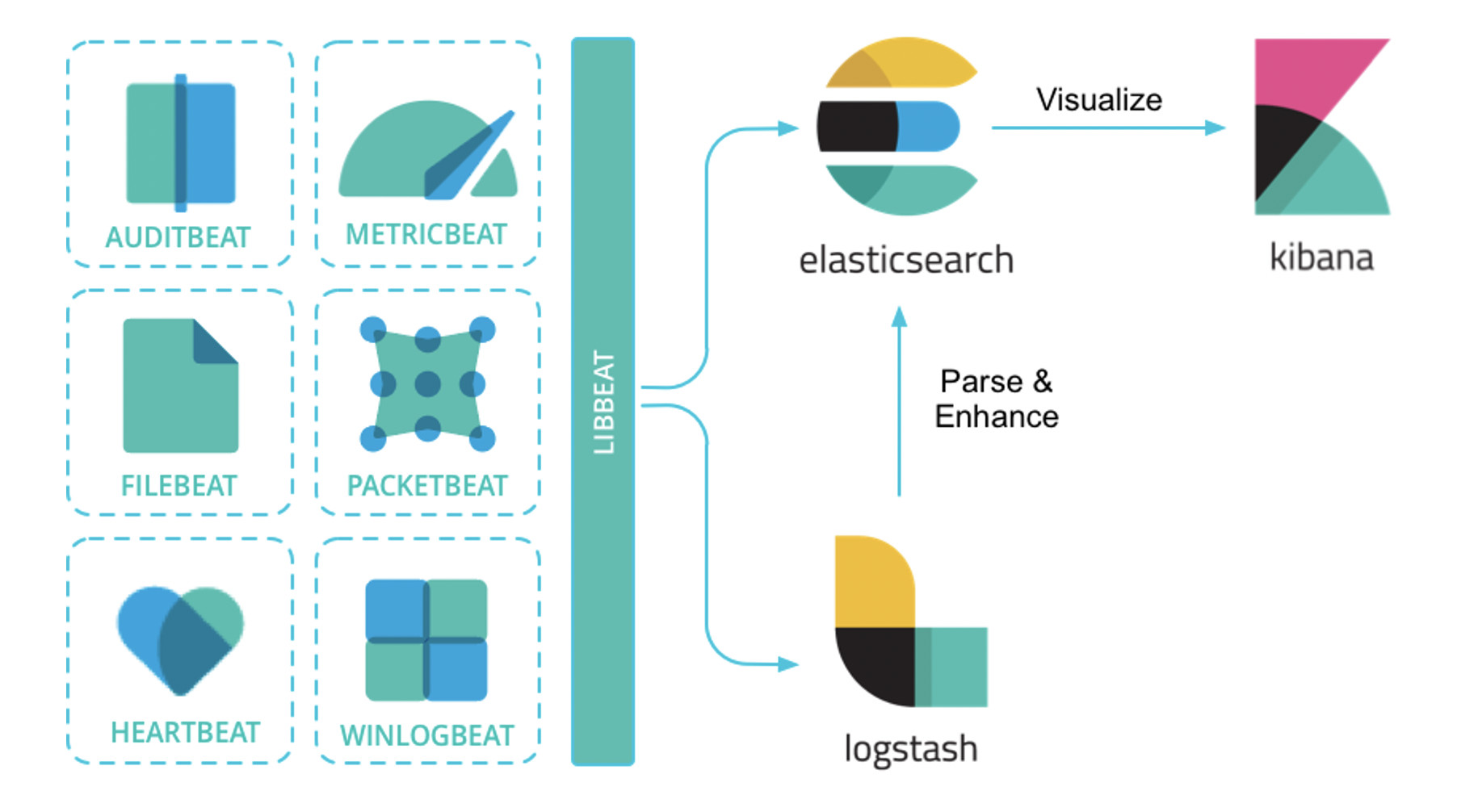
此外,在容器化场景中,尤其是在Kubernetes环境中,用户经常使用的另一套框架是EFK架构。
其中,E还是Elasticsearch,K还是Kibana,其中的F代表Fluent Bit,一个开源多平台的日志处理器和转发器。
Fluent Bit可以让用户从不同的来源收集数据/日志,统一并发送到多个目的地,并且它完全兼容Docker和Kubernetes环境。
既生瑜,何生亮?
ELK 的缺点
最近,在对公司容器云的日志方案进行设计的时候,发现主流的ELK或者EFK比较重,再加上现阶段对于ES复杂的搜索功能很多都用不上最终选择了Grafana开源的Loki日志系统,下面介绍下Loki的背景。
背景和动机
当我们的容器云运行的应用或者某个节点出现问题了,解决思路应该如下:
我们的监控使用的是基于Prometheus体系进行改造的,Prometheus中比较重要的是Metric和Alert,Metric是来说明当前或者历史达到了某个值,Alert设置Metric达到某个特定的基数触发了告警,但是这些信息明显是不够的。
我们都知道,Kubernetes的基本单位是Pod,Pod把日志输出到stdout和stderr,平时有什么问题我们通常在界面或者通过命令查看相关的日志,
举个例子:当我们的某个Pod的内存变得很大,触发了我们的Alert,这个时候管理员,去页面查询确认是哪个Pod有问题,然后要确认Pod内存变大的原因,我们还需要去查询Pod的日志,如果没有日志系统,那么我们就需要到页面或者使用命令进行查询了:
如果,这个时候应用突然挂了,这个时候我们就无法查到相关的日志了,所以需要引入日志系统,统一收集日志,而使用ELK的话,就需要在Kibana和Grafana之间切换,影响用户体验。
所以 ,loki的第一目的就是最小化度量和日志的切换成本,有助于减少异常事件的响应时间和提高用户的体验。
ELK存在的问题
现有的很多日志采集的方案都是采用全文检索对日志进行索引(如ELK方案),优点是功能丰富,允许复杂的操作。
但是,这些方案往往规模复杂,资源占用高,操作苦难。
很多功能往往用不上,大多数查询只关注一定时间范围和一些简单的参数(如host、service等),使用这些解决方案就有点杀鸡用牛刀的感觉了。
因此,Loki的第二个目的是,在查询语言的易操作性和复杂性之间可以达到一个权衡。
成本
全文检索的方案也带来成本问题,简单的说就是全文搜索(如ES)的倒排索引的切分和共享的成本较高。
后来出现了其他不同的设计方案如:OKlog,采用最终一致的、基于网格的分布策略。
这两个设计决策提供了大量的成本降低和非常简单的操作,但是查询不够方便。
因此,Loki的第三个目的是,提高一个更具成本效益的解决方案。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 数据结构:组织和管理数据的艺术
- 防火墙双机热备之镜像模式以及VGMP组监控链路
- NFS权限问题
- 计算机网络 第二章 计算机网络体系结构(习题)
- 第二百五十八回
- axios请求:get和post请求有什么区别,尤其是携带参数区别
- 什么是IO,初级Java怎么更好的理解IO流(上)
- 【AI提示词故事】《启示之星:寻找神殿的探险之旅》
- 想成为黑客?普通人我劝你看这里!(网络安全)
- 【复现】Apache Solr信息泄漏漏洞_24