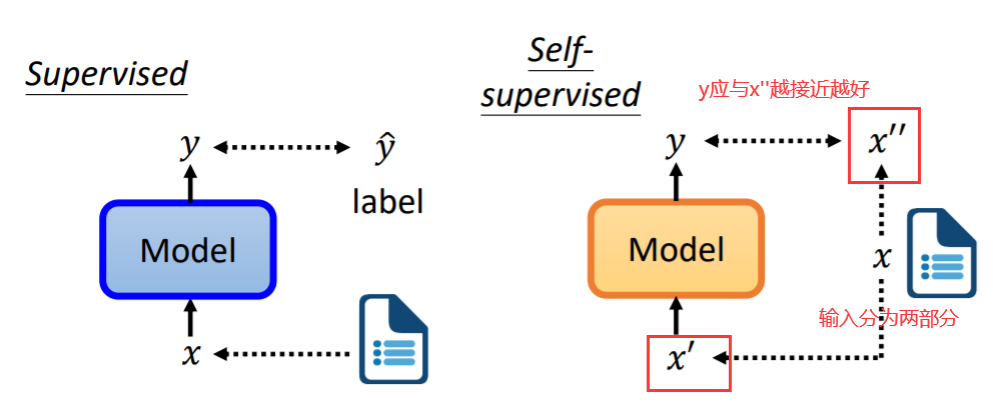
文心、讯飞、ChatGPT大模型横向比较
三种大模型的横向比较分析发现,大模型最终的优异表现依赖于模型规模的突破。
通过比较不同规模的大模型,分析发现大模型的强大生成能力主要源自模型的参数量级的飞跃。尽管方法论上大同小异,但参数量的指数级增长是实现质的飞跃的关键所在。“大力出奇迹”可以说是大模型取得辉煌成就的最本质原因。模型越大,所包含的知识量和拟合复杂分布的能力就越强,也就能产生越逼真的生成结果。
文心一言

文字理解回答能力
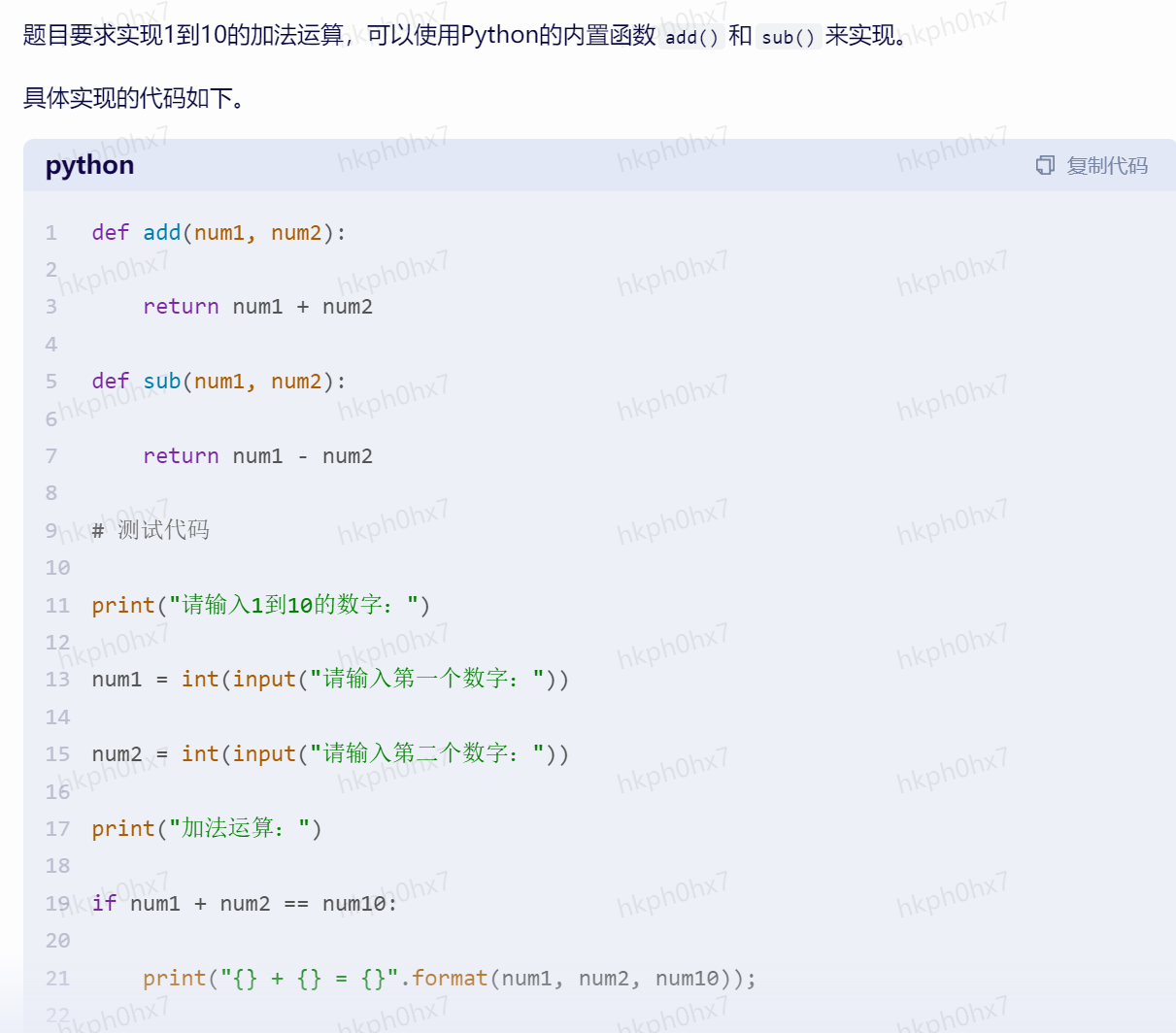
海报设计
假如你是一名海报设计师,需要给浦发银行设计一个宣传海报。
浦发银行要举办 2023上海半程马拉松,活动时间:2023年3月9日到2023年3月31日;活动内容:
活动期间在上马APP或官网,通过支付宝绑定浦发银行借记卡支付报名费,可享受立减60元优惠

社会关系推理
小明的爸爸妈妈结婚,没有邀请小明,小明会生气么?

讯飞星火




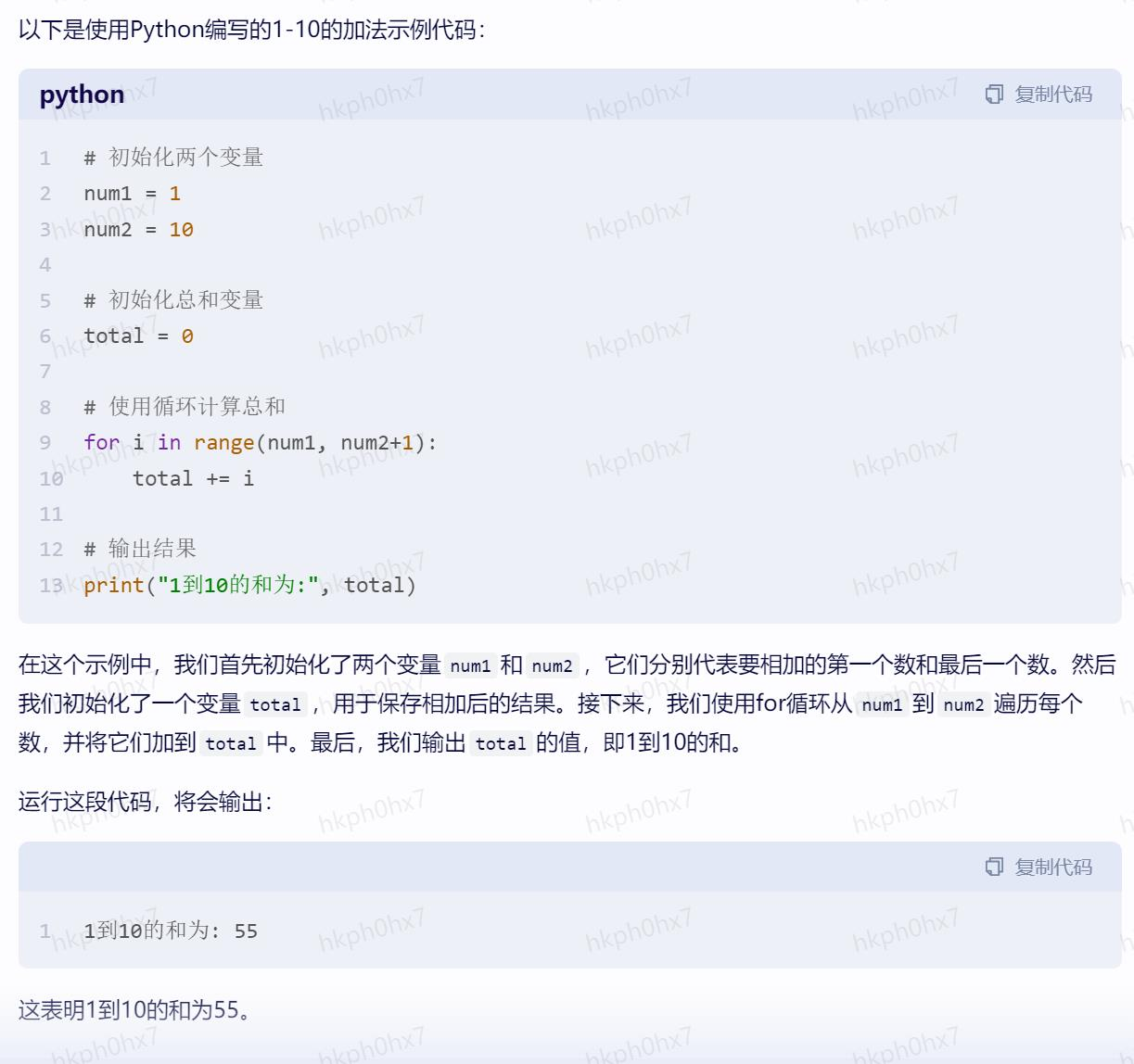
海报设计
假如你是一名海报设计师,需要给浦发银行设计一个宣传海报。
浦发银行要举办 2023上海半程马拉松,活动时间:2023年3月9日到2023年3月31日;活动内容:
活动期间在上马APP或官网,通过支付宝绑定浦发银行借记卡支付报名费,可享受立减60元优惠

社会关系推理
小明的爸爸妈妈结婚,没有邀请小明,小明会生气么?

ChatGPT
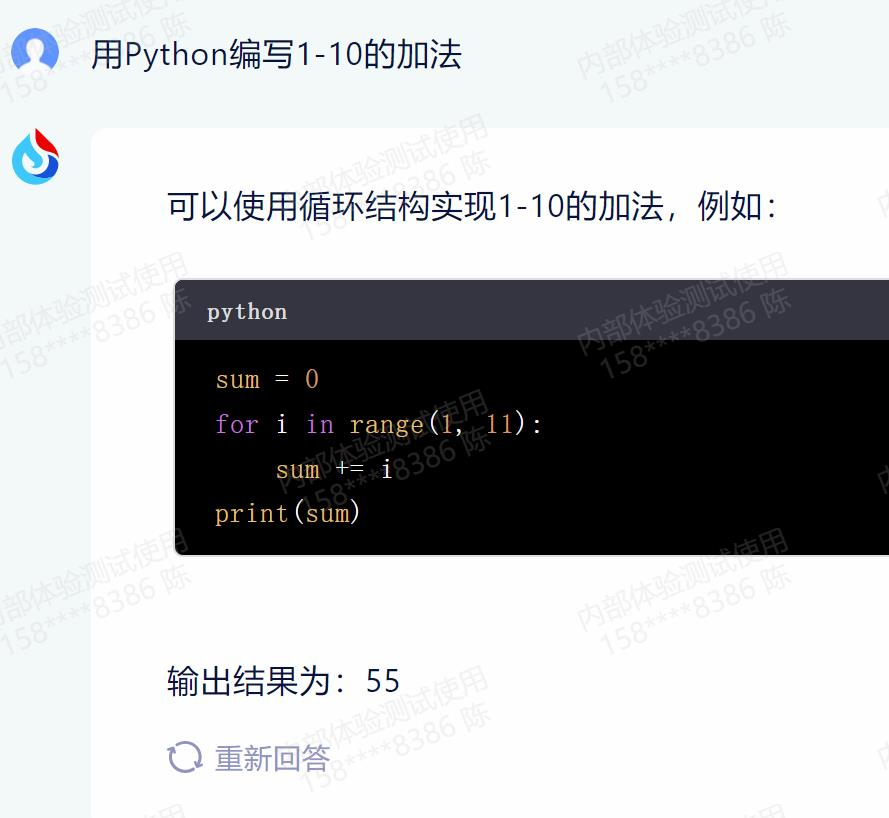
小明的爸爸妈妈结婚,没有邀请小明,小明会生气么?

BERT大模型原理
? 2018年,Google推出了Bert 模型,碾压了以往的所有模型,在各种NLP的建模任务中取得了最佳的成绩 => NLP 领域步入 LLM 时代。
BERT采用完形填空作为预训练:

空格处填什么字,受到上下文影响Bert的预训练 就是从大规模的上亿文本预料中,随机Mask一部分字,形成上面的完形填空题。通过训练,让模型具备从大量的数据中学习复杂的上下文联系的能力。
ERNIE大模型原理
ERNIE 1.0的改进:
基于phrase (比如短语a series of等)的mask策略基于entity (比如人名,位置,组织,产品等名词比如Tsinghua University, J. K. Rowling)的mask 策略相比于BERT 基于字的mask,在ERNIE 当中,由多个字组成的phrase 或者entity 当成统一单元,统一被mask。这样可以潜在的学习到知识的依赖。
ERNIE 2.0
在ERNIE 2.0 中,提出了一个预训练框架,可以在大型数据集合中进行增量训练,即连续学习(Continual Learning)连续学习的目的是在一个模型中顺序训练多个不同的任务,这样可以在学习下个任务中,记住前一个学习任务学习到的结果。
使用连续学习 => 不断积累新的知识

ERNIE 3.0
知识增强的大规模预训练模型结合了自回归网络和自编码网络,这样训练出来的模型就可以通过zero-shot学习、few-shot学习或微调来处理自然语言理解和生成任务用100亿个参数对大规模知识增强模型进行预训练,并在自然语言理解和自然语言生成任务上进行了一系列的实验评估ERNIE 3.0在54项基准测试中以较大的优势胜过最先进的模型,并在SuperGLUE基准测试中取得了第一名。
ERNIE预训练模型:https://github.com/PaddlePaddle/ERNIE
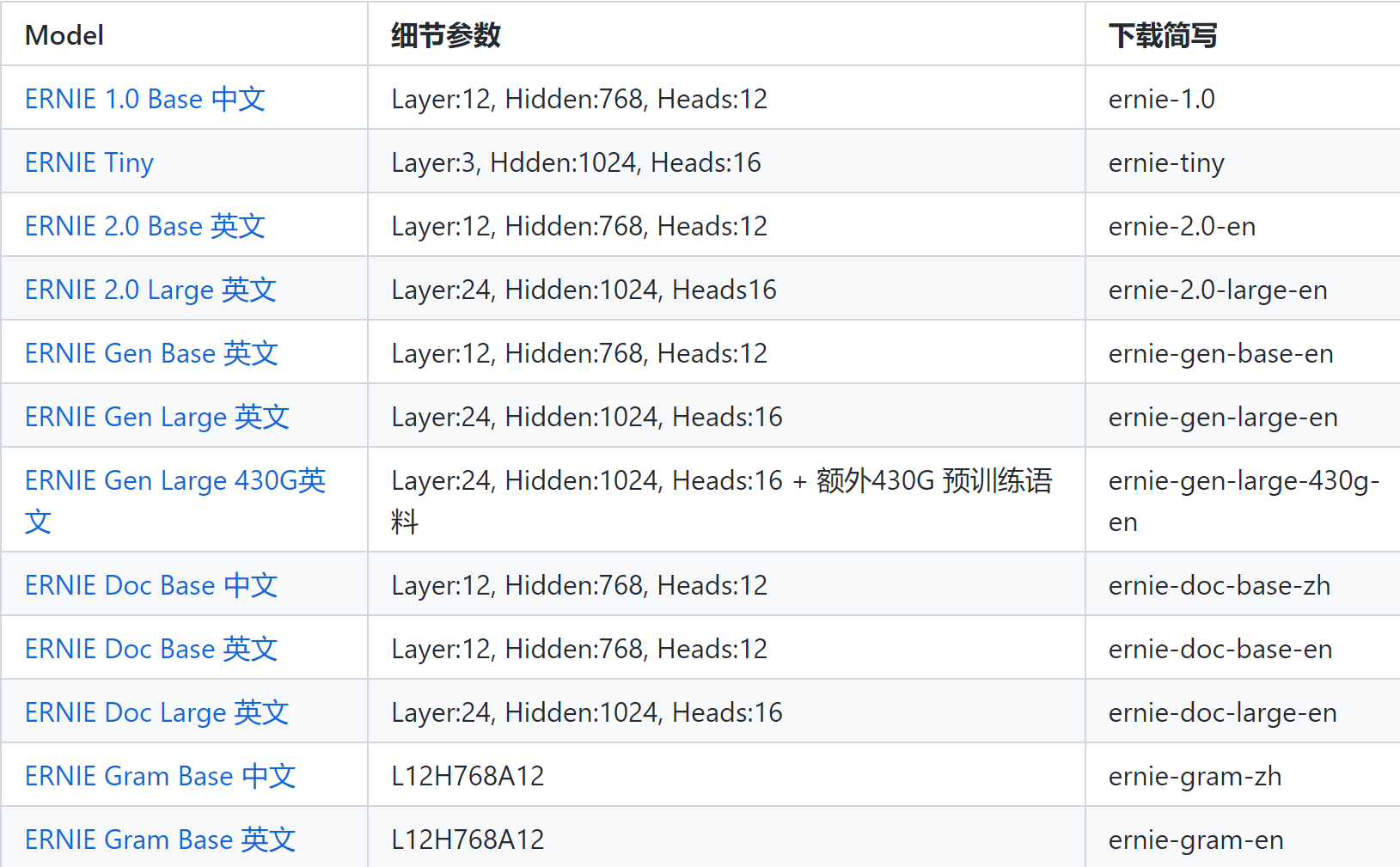
GPT大模型原理
GPT 与 BERT的区别:
? Bert 使用 Encoder 编码器进行训练,适合文本理解
? GPT 使用 Decoder 解码器,更适合文本生成领域
GPT-1 略逊色于 Bert,当时Bert影响力更大
GPT-2 模型:
? Bert霸榜NLP之后,又有很多新模型推出,比如:ERNIE, ALBert, BART, XLNET, T5等。
? Bert预训练主要是完形填空,和预测下一个句子。后来很多模型增加了 多个预训练任务句子打乱顺序再排序、选择题、判断题、改错题、甚至把机器翻译、文本摘要、领域问答都放到了预训练任务中=> 模型类似人脑,多种任务:看新闻,听音乐,读古诗,写文章,做数学题等
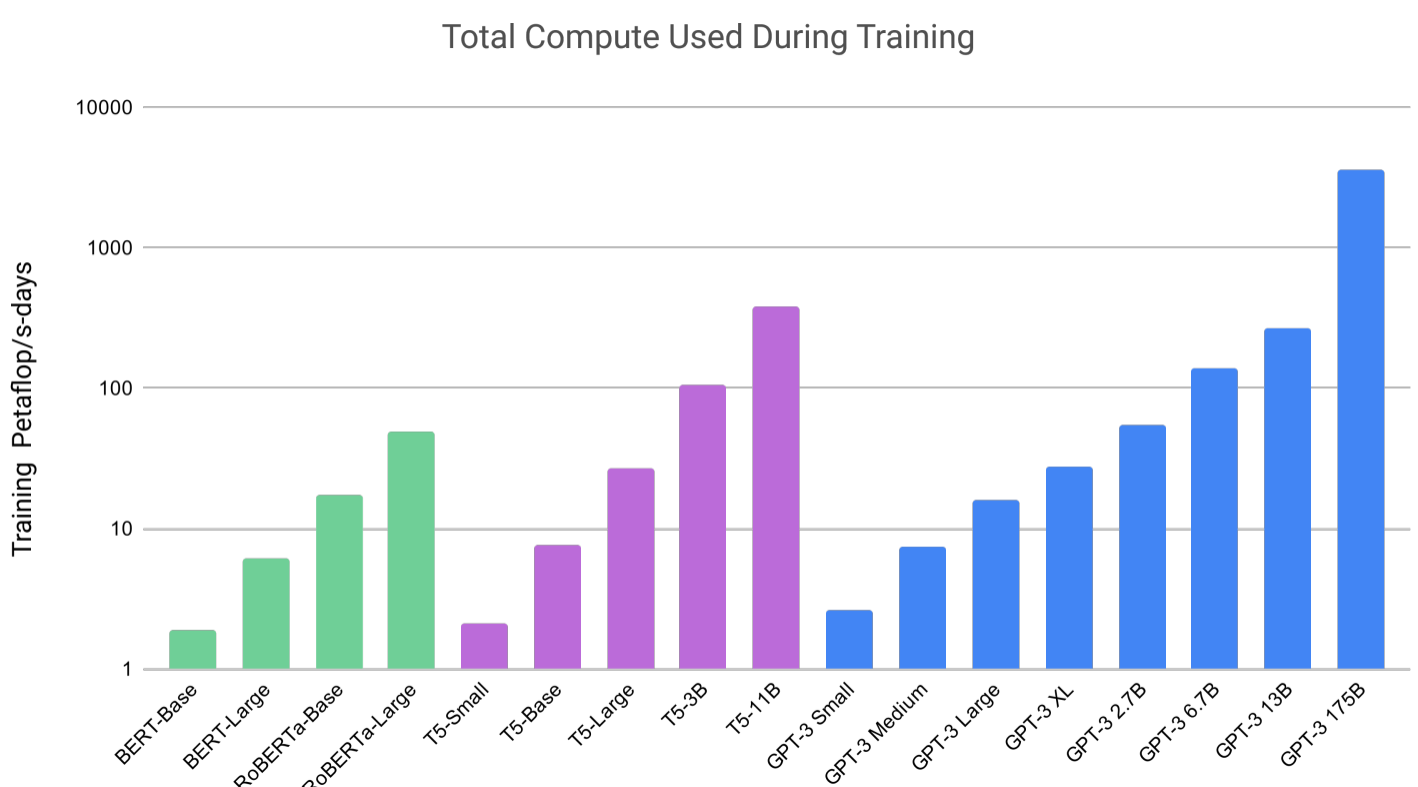
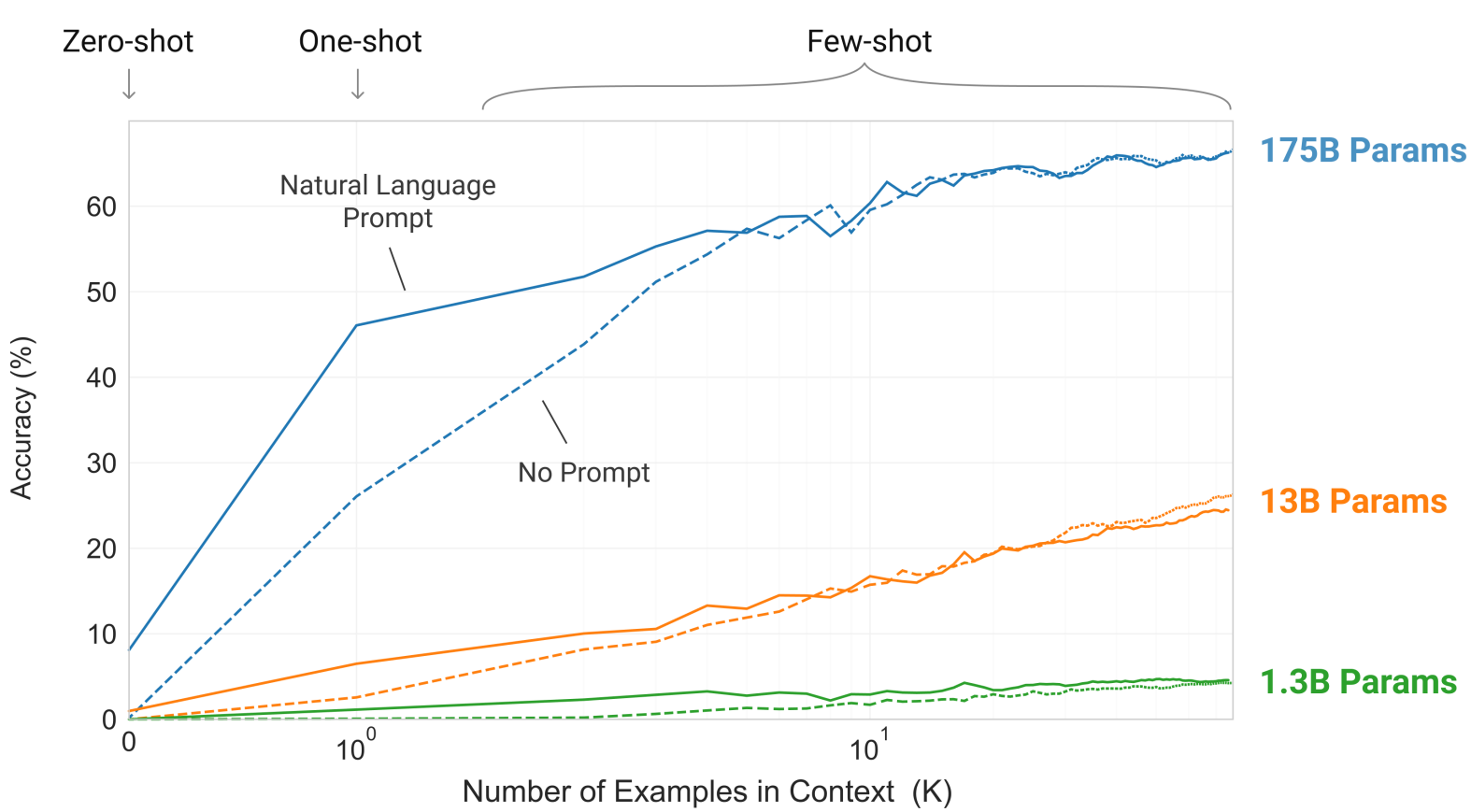
GPT-3 模型:
-
GPT-3模型参数量是1750亿,计算量是 bert-base的1000倍,在NLP多个任务中表现优秀,比如写SQL语句,JavaScript代码。
-
GPT-3的训练覆盖了STEM、人文科学、社会科学、数学、历史、法律等57门学科。难度从初级到高级专业水平不等。在这个基础上1750亿参数的GPT-3模型达到了43.9%准确率,而130亿参数的模型只有25%的准确率
- Prompt引导学习的方式,在超大模型上有很好的效果:只需要给出one-shot 或者few-shot,模型就能照猫画虎地给出正确答案。
这里10多亿参数的大模型是不行的,1000亿以上参数的模型效果好。
我是独立开源软件开发者,SolidUI作者,对于新技术非常感兴趣,专注AI和数据领域,如果对我的文章内容感兴趣,请帮忙关注点赞收藏,谢谢!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- spring Security源码讲解-Sevlet过滤器调用springSecurty过滤器的流程
- 【Java 进阶篇】Jedis 操作 Set 与 SortedSet 详解
- SD-WAN服务简介及挑选服务商指南
- 使用JavaScript实现粘贴上传图片
- Python基础4
- 蓝桥杯省赛无忧 第二章 基础算法 课件21 枚举
- 什么是 .NET? 简介和概述
- 推三返一模式:打破常规,裂变矩阵!
- 比亚迪早在2015年就有800V技术了
- C++ map容器