[23] Generative Image Dynamics
发布时间:2023年12月20日
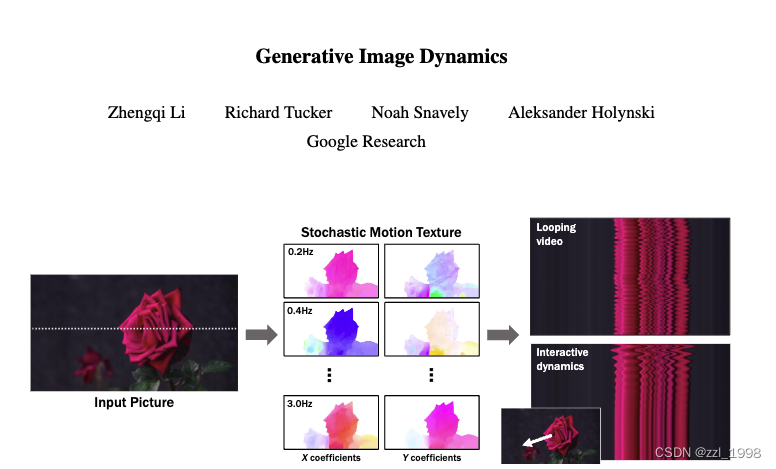
- 动作位移场
:描述图像中任意像素
,从首帧到第
帧的位移变化;
- 动作纹理
:用K个频率,表征任意像素
- 动作位移场:光流;
- 动作纹理:光流的频谱图,对像素点在T时间序列下的位移轨迹做FFT得到;
- 任务目标:给定图片,预测其未来T帧的震荡变化
- 给定图片,预测K个频谱图; -> 动作预测模块
- 给定频谱图,通过逆傅立叶变换得到光流;
- 给定光流,渲染未来T帧。? ? ?-> 渲染模块
目录
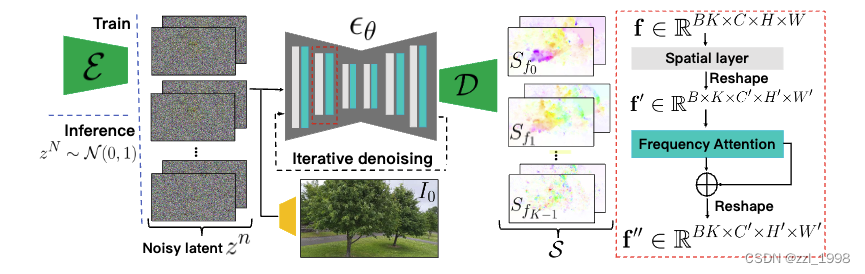
动作预测模块
Latent Diffusion Model:类似Stable Diffusion的VAE结构,降低频谱图分辨率,提高学习效率;
训练过程:以输入图片和频率作为控制信号,学习频谱分布;
频率正则化:考虑到Diffusion的学习值域在[0, 1],因此用傅立叶系数的97%幅值作为正则项;
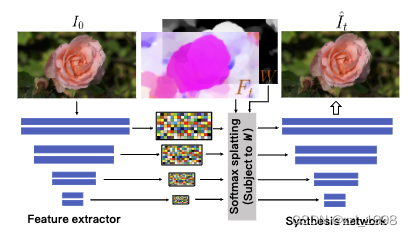
动作渲染模块
- Feature Extractor:基于ResNet-34提取多层图片特征;
- Synthesis Network:类StyleGAN结构
- 根据t时刻光流图warp图片特征;
- warp后的图片特征作为控制信号,生成t时刻渲染图像;
实验
- 准备训练数据:
- 数据:自然震荡视频2631个,包含:树、花、蜡烛等物体;
- 分段:每10帧作为开始帧,每段包含150帧,处理后总共包含130K段;
- 光溜:提取每段首帧到之后149帧的光流;
- 在16张A100上训练6天
- 结果可视化:

- 预测光流可视化

- 消融实验


文章来源:https://blog.csdn.net/qq_40731332/article/details/135080589
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 使用 Kubernetes 部署机器学习模型的优势
- 解决element-ui中的el-select选择器无法显示选中内容的问题
- 缺失msvcr120.dll怎么办,msvcr120.dll一键修复教程
- 代码随想录算法训练营 | day59 单调栈 503.下一个更大元素Ⅱ,42.接雨水
- springboot如何创建全局线程池
- MySQL作业 (4) 数据表综合练习
- Java研学-Servlet3.0文件上传下载
- 米粒图像预处理-图像背景均匀化
- 旧衣回收小程序搭建有什么优势?
- 基于MATLAB编程的BP神经网络土地分类,bp神经网络详细原理