实例分割模型解析:solo模型
论文链接:https://arxiv.org/abs/1912.04488
代码:https://github.com/WXinlong/SOLO
1.摘要
我们提出了一种新的、极其简单的实例分割方法。与许多其他密集预测任务(例如语义分割)相比,任意数量的实例使得实例分割更具挑战性。为了预测每个实例的掩码,主流方法要么遵循“检测然后分段”策略(例如,Mask R-CNN),要么首先预测嵌入向量,然后使用聚类技术将像素分组到各个实例中。我们认为通过引入“实例类别”的概念,从全新的角度来完成实例分割任务,该概念根据实例的位置和大小为实例中的每个像素分配类别,从而很好地将实例分割转换为单次分类可解决的问题问题。我们展示了一个更简单、更灵活的实例分割框架,具有强大的性能,达到了与 Mask R-CNN 相当的精度,并且在精度上优于最近的单次实例分割器。我们希望这个简单而强大的框架可以作为除实例分割之外的许多实例级识别任务的基线.
2.主要贡献
考虑图像中的对象实例之间的根本区别是什么?大多数情况是两个实例要么具有不同的中心位置,要不具有不同的对象大小。这一结果让人怀疑是否可以通过中心位置和对象大小直接区分实例?SOLO不是利用像素成对关系,而是在训练期间直接使用实例掩码注释进行学习,并且端到端的预测实例掩码,而无需进行分组后再处理。
3.方法
3.1 基本原理
如果对象的中心落入网格单元,则该网格负责
预测语义类别
分割该对象实例
SOLO连接到一个卷积主干,我们使用FPN,它生成不同大小的特征图金字塔,每个级别具有固定数量的通道,
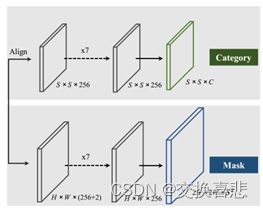
有一张特征图,能够生成S的平方个mask,使用金字塔结构,金字塔中用了5个的话,就有5个S^2个mask出来
FPN的目的是为了检测图像中不同大小的对象
3.2模型结构图
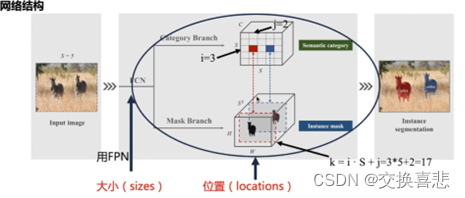
如何解决平移不变性:原始的图移动了的话,对应的mask也得移动,所以它是位置敏感的,怎么把位置的信息加进去呢:
在mask部分加两层,如果原始特征张量的大小为H×W×D,则新张量的大小变为H×W×(D + 2),其中最后两个通道是x-y像素坐标。
要想保证每一个grid都有一个channel对应,S的平方是比较大的,怎么把复杂度降下来:
X-Y解耦
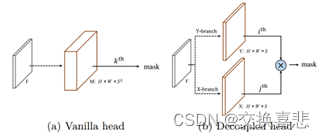
在decoupled solo中,原来的输出张量H×W×S^2
被替换为两个输出向量X∈R(H×W×S)和Y∈R(H×W×S),分别对应两个轴,因此输入空间从H×W×S^2减少到H×W×2S,该对象的掩膜被定义为:
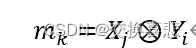
其中xj和yi是X和Y经过sigmoid运算后的第j和第i个通道图。其背后的动机是,像素属于位置类别 (i; j) 的概率是属于第i行和第j列的联合概率,因为水平和垂直位置类别是独立的。
4.总结
在这项工作中,我们开发了一个直接实例分割框架,称为 SOLO。我们的 SOLO 是端到端可训练的,可以以恒定的推理时间将原始输入图像直接映射到所需的实例掩模,从而消除了自下而上方法或边界框检测和 RoI 中的分组后处理的需要采用自上而下的方式进行操作。鉴于 SOLO 的简单性、灵活性和强大的性能,我们希望我们的 SOLO 能够成为许多实例级识别任务的基石。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Packet Tracer - Layer 2 VLAN Security
- 基于大语言模型LangChain框架:知识库问答系统实践
- 【LeetCode】203. 移除链表元素(简单)——代码随想录算法训练营Day03
- Nodejs 第三十二章(数据库)
- 【IEEE独立出版 | 往届均完成检索】2024年第四届消费电子与计算机工程国际学术会议(ICCECE 2024)
- 2024年最值得关注的跨境电商平台盘点,TikTok Shop或成最大趋势
- 跨境电商获客脚本必备功能有哪些?
- 【WPF.NET开发】WPF中的版式
- 在统信UOS操作系统1060上如何部署DNS服务器?01
- ecology-SQL连接类型总结