Prometheus 14 点实践经验分享
这是 2017 年的 promcon 的分享,原文地址在这里,作者 Julius Volz,今天偶然看到,虽然已经过去 6 年,有些实践经验还是非常值得学习。做个意译,加入一些自己的理解,分享给大家。
埋点方面
1. 所有模块都要埋点
我印象中 Google 有个规范,所有的服务模块,都需要通过 HTTP?/varz?接口暴露监控指标,即便是一个纯后端的 RPC 服务,也要暴露一个这样的 HTTP 接口。当然,实操的话,应该是通过框架来统一埋点,但是统一埋点只能埋入一些通用的指标,如果涉及一些自身业务逻辑相关的,还是需要自行埋点。
2. 借鉴 USE 方法论
USE 方法论,即 Utilization、Saturation、Errors 三个维度,即资源的使用率、饱和度、错误。这三个维度,可以用来衡量一个资源是否健康,如果有一个维度不健康,就需要考虑扩容或者优化。USE 方法论提出者是著名大神?Brendan Gregg,他的博客里有很多关于性能优化的文章,非常值得一读。
3. 借鉴 RED 方法论
RED 方法论,即 Request rate、Error rate、Duration,托生自 Google 的四个黄金指标,主要用来衡量微服务的健康度,RED 方法论的原文在?这里。
4. 指标命名要有规范
Prometheus 的指标命名,其实是没有约束的,也没有单位的概念,但通常会有一些约定,要尽量遵守,比如:
_seconds?_milliseconds?等作为时间指标的后缀_total?作为 counter 类型指标的后缀- 更多的约定可以参考?Metric and label naming | Prometheus
5. 注意标签基数爆炸
在 Prometheus 生态里,一个时间线的唯一标识是一个 labelset,即多个标签的组合(指标名称其实也是一个特殊标签,标签 Key 是?__name__)。比如?disk_free{host="10.1.2.3", fstype="ext4", path="/data"}?唯一标识了一个时间线。其中?disk_free?是指标名称,实际底层处理的时候,会处理成:{__name__="disk_free", host="10.1.2.3", fstype="ext4", path="/data"},所以说标签集合是唯一标识一个时间线的。如果任一标签变化,就会当成一个新的时间线。一些高基数的信息,就不适合作为标签,比如:
- 用户访问的来源 IP
- 用户的 ID
- 用户请求的 TraceID
6. 统计失败+总量而不要统计失败+成功量
考虑下面两个 counter 指标:
- failures_total
- successes_total
如果要计算失败率,可以这么写:
rate(failures_total[5m])
/
(rate(successes_total[5m]) + rate(failures_total[5m]))
写起来相对复杂一些,如果我们统计失败+总量:
- failures_total
- requests_total
失败率的计算就会变简单:
rate(failures_total[5m]) / rate(requests_total[5m])
7. 使用默认值提前初始化指标
假设有这么一个指标:ops_total{optype="<type>"},显然,这是想统计不同类型的操作的次数,但是如果某个类型的操作一次都没有发生,那么这个指标就不会出现在 Prometheus 的时间序列里,但你可能在 Grafana 图表和相关告警规则中用到了这样的语句:sum(rate(ops_total{optype="create"}[5m])),如果 create 一次都没有发生,那就没法工作了。一般我们建议,代码埋点的时候要做初始化,比如下面的 Go 语言例子,把已知的操作类型都初始化一下:
for _, val := range opLabelValues {
// Note: No ".Inc()" at the end.
ops.WithLabelValues(val)
}
当然,填充默认值的这种方式并非总能奏效。比如?http_requests_total{status="<status>"}?这样的指标,status=~"5.."?过滤器查不到数据时会破坏整个 promql,此时有个比较 tricky 的方法是使用 or 语法:
<expression> or up{job="myjob"} * 0
更多信息可参考这个文章。
8. 避免使用无法识别的额外信息标签
比如机器的指标,disk_usage_bytes,如果某个机器部署了服务A,你可能会想这么打标签:disk_usage_bytes{service="a"},但是如果后面这个机器改变了用途,不再部署服务A,而是部署服务B,这个磁盘使用的指标就会变成?disk_usage_bytes{service="b"},而这,由于标签变化,就会导致 Prometheus 会认为这是一个新的时间线,而不是原来的时间线,导致时间线数据不连续。
那怎么办?可以使用 group_left 附加额外标签的方式,具体可以参考这个文章。
关于告警
Rob Ewaschuk 有一篇广为流传的文章:My Philosophy on Alerting,推荐大家 Google 一下阅读一下。
9. 告警症状而非原因
原因类指标可以放到仪表盘上用于后续问题根因排查,症状类指标,通常反映的是上层用户的感受,啥是症状类指标?比如:
- 某个关键服务延迟高,或错误率高
- 某个磁盘即将在未来 4h 内写满
10. 注意 target 缺失告警
比如下面这个告警规则:
ALERT HighErrorRate
IF rate(errors_total{job="myjob"}[5m]) > 10
FOR 5m
看起来挺好的,但是如果你的 target down 掉了或者压根没有被 Prometheus 发现,上面的表达式查不到数据,自然就不会告警。建议,对于关键指标,要一并配置 up 和 absent:
ALERT MyJobInstanceDown
IF up{job="myjob"} == 0
FOR 5m
ALERT MyJobAbsent
IF absent(up{job="myjob"})
FOR 5m
11. 告警规则通常要配置持续时长
比如下面的告警规则,没有配置持续时长:
ALERT InstanceDown
IF up == 0
如果有一次抓取失败,就会告警,但实际上可能是网络抖动,实际的 target 是健康的,所以建议配置持续时长:
ALERT InstanceDown
IF up == 0
FOR 5m
12. 注意保留关键标签
举例:
Don't:
ALERT HighErrorRate
IF sum(rate(...)) > x
Do (at least):
ALERT HighErrorRate
IF sum by(job) (rate(...)) > x
读者可以在即时查询里体验一下,sum 之后,如果不加 by 的逻辑,所有便签就都没了,告警事件发出来信息太少,所以一般建议把关键标签放到 by 后面分组统计。
关于查询
13. 查询表达式通常要过滤到job颗粒度
不同的 job 可能有相同的指标名字,为了避免冲突,尽量把 job 作为过滤条件:
Don't: rate(http_request_errors_total[5m])
Do: rate(http_request_errors_total{job="api"}[5m])
14. 注意?rate()?和?sum()?的顺序
对于 counter 类型的指标,如果服务重启,指标会被重置,从 0 开始重新上报,rate()?函数可以修正这种情况,比如:
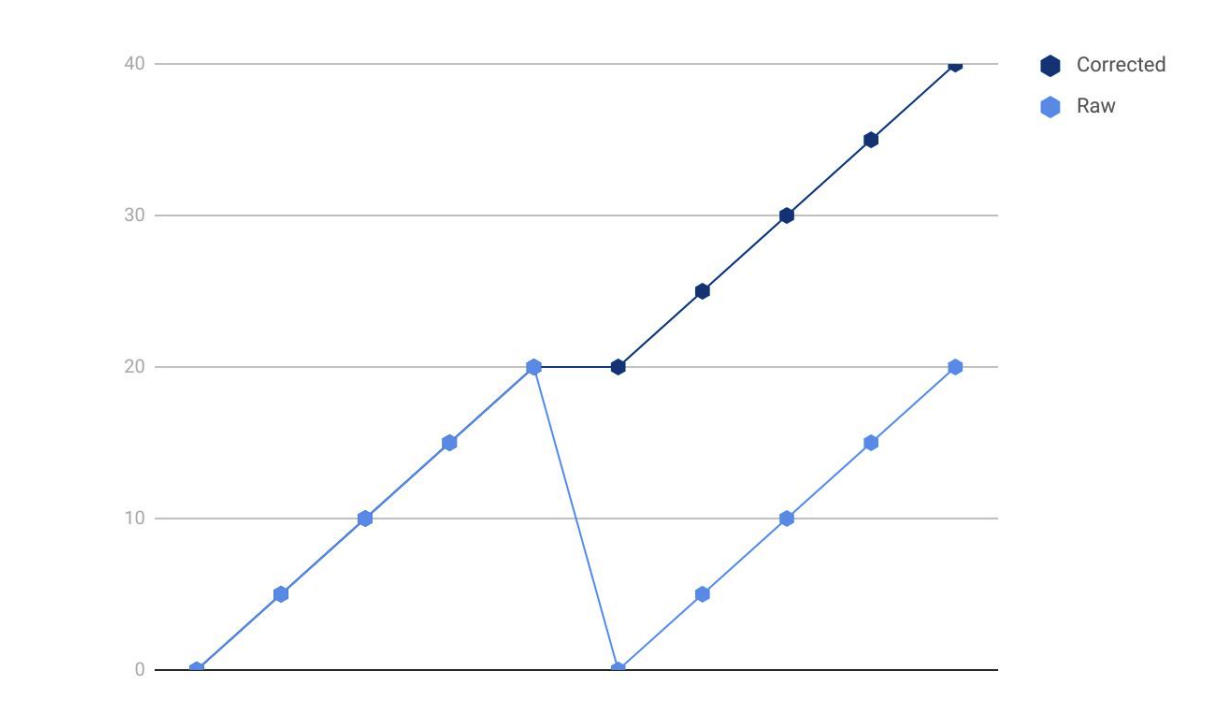
正常来讲,应该先求?rate(),再求?sum(),如果弄反了,就麻烦了,比如下面的例子:
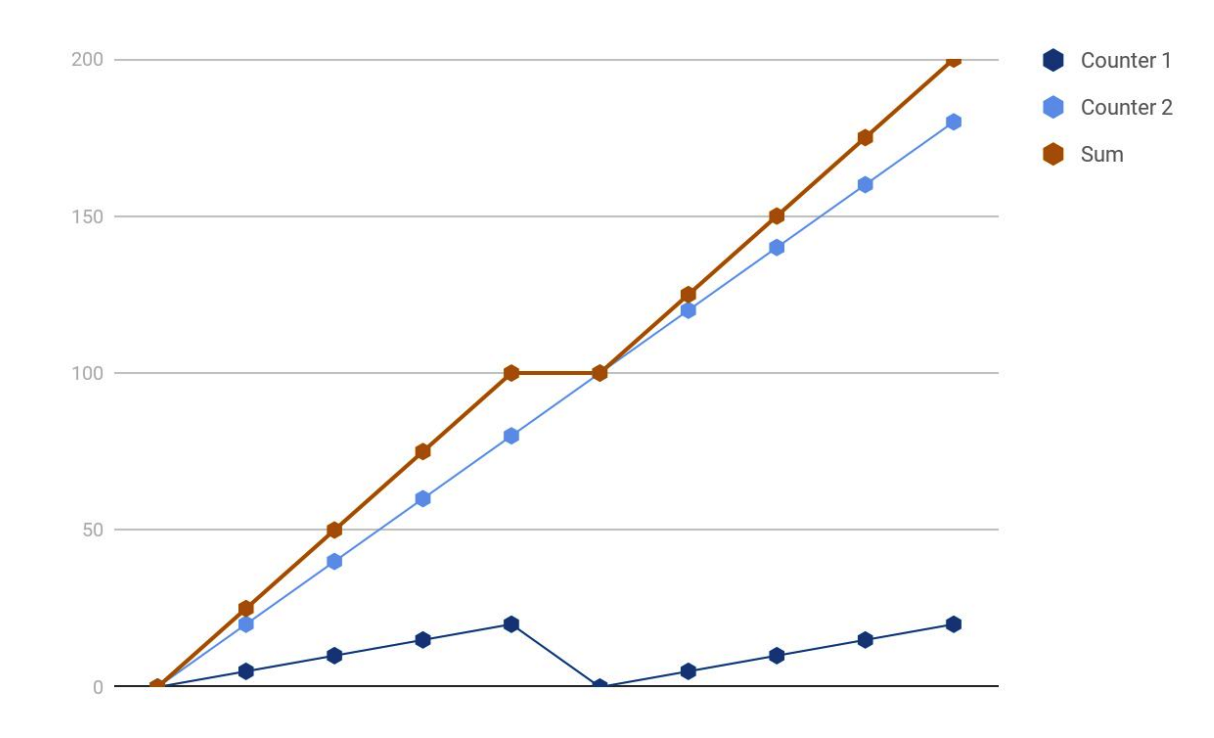
译者注:要想玩转 Prometheus,其实还是有门槛的,但是大部分公司首先会把人力投入到自己的赚钱业务上,监控或者可观测性系统,这种偏辅助类的基础设施,没有精力搞,巧了,我们创业就是提供可观测性平台和服务,如果您对我们放心,欢迎联系我们,我们会提供一流的服务。
译者:秦晓辉,Open-Falcon、Nightingale、Categraf 等开源项目创始研发人员,极客时间专栏《运维监控系统实战笔记》作者,目前在创业,提供可观测性产品,微信 picobyte,欢迎加好友交流,加好友请备注公司。
微信公众号不好贴外部链接,更好的阅读体验可以访问:Prometheus 14 点实践经验分享 - 快猫星云
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 学习Go语言Web框架Gee总结--中间件Middleware(五)
- UE5 C++(十七)— 射线检测
- 华为机试真题实战应用【算法代码篇】-分割数组的最大差值(附python、C++和JAVA代码实现)
- 系统安全的加固
- 力扣白嫖日记(sql)
- c#按照时间进行数据存储(不用数据库)
- 如何在iOS手机上查看应用日志
- 【Leetcode 2645】构造有效字符串的最小插入数 —— 动态规划
- ROS-arbotix安装
- ARM 串口通信点灯