中国科学院大学2023杨力祥老师操作系统高级教程思考题(2)
国科大操作系统高级教程思考题,参考书是《Linux内核设计的艺术-图解Linux操作系统架构设计与实现原理(第二版)》杨老师上课讲的特别棒,该文章供自己学习使用,参考往年学长学姐的文章
前三次思考题请参考:
中国科学院大学2023杨力祥老师操作系统高级教程思考题(1)
第四次思考题
1、getblk函数中,申请空闲缓冲块的标准就是b_count为0,而申请到之后,为什么在wait_on_buffer(bh)后又执行if(bh->b_count)来判断b_count是否为0?
P114
wait_on_buffer(bh)内包含睡眠函数,虽然此时已经找到比较合适的空闲缓冲块,但是可能在睡眠阶段该缓冲区被其他任务所占用,因此必须重新搜索,判断是否被修改,修改则写盘等待解锁。判断若被占用则重新repeat,继续执行if(bh->b_count)
2、b_dirt已经被置为1的缓冲块,同步前能够被进程继续读、写?给出代码证据。
同步前能够被进程继续读、写
b_uptodate设置为1后,内核就可以支持进程共享该缓冲块的数据了,读写都可以,读操作不会改变缓冲块的内容,所以不影响数据,而执行写操作后,就改变了缓冲块的内容,就要将b_dirt标志设置为1。由于此前缓冲块中的数据已经用硬盘数据块更新了,所以后续的同步未被改写的部分不受影响,同步是不更改缓冲块中数据的,所以b_uptodate仍为1。即进程在b_dirt置为1时,仍能对缓冲区数据进行读写。
证据代码:
//代码路径:fs/blk_dev.c:
int block_write(int dev, long * pos, char * buf, int count) //块设备文件内容写入缓冲块
{
…
offset= 0;
*pos += chars;
written += chars;
count -= chars;
while (chars-->0)
*(p + +)= get_fs_byte(buf + +);
bh->b_dirt= 1;
brelse(bh);
…
}
//代码路径:fs/file_dev.c:
int file_write(struct m_inode * inode, struct file * filp, char * buf, int count)
//普通文件内容写入缓冲块
{
…
c= pos % BLOCK_SIZE;
p= c + bh->b_data;
bh->b_dirt= 1;
c= BLOCK_SIZE-c;
if (c > count-i) c= count-i;
pos += c;
if (pos > inode->i_size) {
inode->i_size= pos;
inode->i_dirt= 1;
}
i += c;
while (c-->0)
*(p + +)= get_fs_byte(buf + +);
…
}
//代码路径:fs/file_dev.c:
static struct buffer_head * add_entry(struct m_inode * dir,
const char * name, int namelen, struct dir_entry ** res_dir)//目录文件需要加载
//目录项,用到写缓冲块
3、wait_on_buffer函数中为什么不用if()而是用while()?
因为可能存在一种情况是,很多进程都在等待一个缓冲块。在缓冲块同步完毕,唤醒各等待进程到轮转到某一进程的过程中,很有可能此时的缓冲块又被其它进程所占用,并被加上了锁。此时如果用if(),则此进程会从之前被挂起的地方继续执行,不会再判断是否缓冲块已被占用而直接使用,就会出现错误;而如果用while(),则此进程会再次确认缓冲块是否已被占用,在确认未被占用后,才会使用,这样就不会发生之前那样的错误。
4、分析ll_rw_block(READ,bh)读硬盘块数据到缓冲区的整个流程(包括借助中断形成的类递归),叙述这些代码实现的功能。
void ll_rw_block(int rw, struct buffer_head * bh)
{
unsigned int major;
// 获取缓冲块头部指向的设备的主设备号
if ((major=MAJOR(bh->b_dev)) >= NR_BLK_DEV ||
!(blk_dev[major].request_fn)) {
// 如果主设备号无效或设备没有请求函数,则打印错误信息
printk("Trying to read nonexistent block-device\n\r");
return; // 并返回,不执行任何操作
}
// 提交块设备的读写请求
make_request(major,rw,bh);
}
static void make_request(int major,int rw, struct buffer_head * bh)
{
struct request * req;
int rw_ahead;
/* WRITEA/READA is special case - it is not really needed, so if the */
/* buffer is locked, we just forget about it, else it's a normal read */
if (rw_ahead = (rw == READA || rw == WRITEA)) {
if (bh->b_lock)
return;
if (rw == READA)
rw = READ;
else
rw = WRITE;
}
if (rw!=READ && rw!=WRITE)
panic("Bad block dev command, must be R/W/RA/WA");
lock_buffer(bh);
if ((rw == WRITE && !bh->b_dirt) || (rw == READ && bh->b_uptodate)) {
unlock_buffer(bh);
return;
}
repeat:
/* we don't allow the write-requests to fill up the queue completely:
* we want some room for reads: they take precedence. The last third
* of the requests are only for reads.
*/
if (rw == READ)
req = request+NR_REQUEST;
else
req = request+((NR_REQUEST*2)/3);
/* find an empty request */
while (--req >= request)
if (req->dev<0)
break;
/* if none found, sleep on new requests: check for rw_ahead */
if (req < request) {
if (rw_ahead) {
unlock_buffer(bh);
return;
}
sleep_on(&wait_for_request);
goto repeat;
}
/* fill up the request-info, and add it to the queue */
req->dev = bh->b_dev;
req->cmd = rw;
req->errors=0;
req->sector = bh->b_blocknr<<1;
req->nr_sectors = 2;
req->buffer = bh->b_data;
req->waiting = NULL;
req->bh = bh;
req->next = NULL;
add_request(major+blk_dev,req);
}
ll_rw_block 调用序列
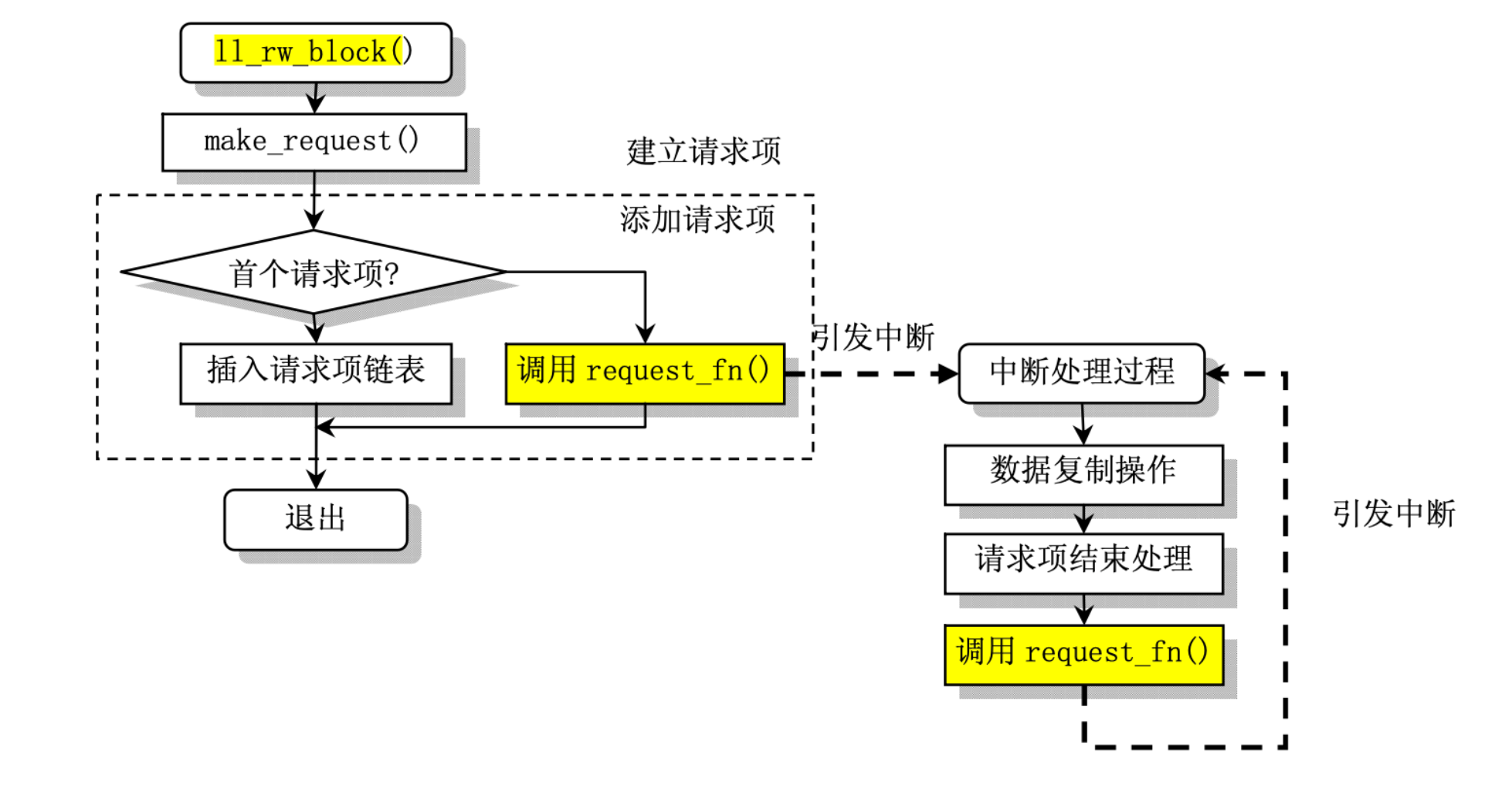
当程序需要读取硬盘上的一个逻辑块时,就会向缓冲区管理程序提出申请,而程序的进程则进入睡 眠等待状态。缓冲区管理程序首先在缓冲区中寻找以前是否已经读取过这块数据。如果缓冲区中已经有 了,就直接将对应的缓冲区块头指针返回给程序并唤醒该程序进程。若缓冲区中不存在所要求的数据块, 则缓冲管理程序就会调用本章中的低级块读写函数 ll_rw_block(),向相应的块设备驱动程序发出一个读 数据块的操作请求。该函数就会为此创建一个请求结构项,并插入请求队列中。为了提供读写磁盘的效 率,减小磁头移动的距离,在插入请求项时使用了电梯移动算法。
当对应的块设备的请求项队列空时,表明此刻该块设备不忙。于是内核就会立刻向该块设备的控制 器发出读数据命令。当块设备的控制器将数据读入到指定的缓冲块中后,就会发出中断请求信号,并调 用相应的读命令后处理函数,处理继续读扇区操作或者结束本次请求项的过程。例如对相应块设备进行 关闭操作和设置该缓冲块数据已经更新标志,最后唤醒等待该块数据的进程。
5、分析包括安装根文件系统、安装文件系统、打开文件、读文件在内的文件操作。
①安装根文件系统:
根文件系统挂在super_block[8]上。加载根文件系统最重要的标志就是把根文件系统的根i节点挂在super_block[8]中根设备对应的超级块上。
可以说,加载根文件系统有三个主要步骤:
1)复制根设备的超级块到super_block[8]中,将根设备中的根i节点挂在super_block[8]中对应根设备的超级块上。
2)将驻留缓冲区中16个缓冲块的根设备逻辑块位图、i节点位图分别挂接在super_block[8]中根设备超级块的s_zmap[8]、 s_imap[8]上。
3)将当前进程的pwd、root指针指向根设备的根i节点。
安装完成后总体效果图:

②安装文件系统:
安装文件系统就是在根文件系统的基础上,把硬盘中的文件系统安装在根文件系统上,使操作系统也具备以文件的形式与硬盘进行数据交互的能力。
安装文件系统分为三步:
1)将硬盘上的超级块读取出来,并载入系统中的super_block[8]中。
2)将虚拟盘上指定的i节点读出,并将此i节点加载到系统中的inode_table[32]中。
3)将硬盘上的超级块挂接到inode_table[32]中指定的i节点上。
硬盘的文件系统安装成功后,整体结构关系如图:

③打开文件、读文件
第一步,将用户进程task_struct中的*filp[20]与内核中的file_table[64]进行挂接。
第二步,以用户给定的路径名“/mnt/user/user1/user2/hello.txt”为线索,找到hello.txt文件的i节点。
第三步,将hello.txt对应的i节点在file_table[64]中进行登记。具体的操作是在进程中调用open( )函数实现打开文件,该函数最终映射到sys_open( )系统调用函数执行。
打开文件关系示意图:

读文件:
从用户进程打开的文件中读取数据,读文件由read函数完成。
6、在创建进程、从硬盘加载程序、执行这个程序的过程中,sys_fork、do_execve、do_no_page分别起了什么作用?
sys_fork 用于进程的创建,do_execve 用于加载并执行新的程序,而 do_no_page 用于处理程序执行过程中的缺页异常,确保所需的内存页面被正确加载。(关于证据请翻看《linux内核完全注释》P120、P153、P415、P422、P444、P455)
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- How to Use the Man Command
- Python算法例25 落单的数Ⅲ
- 在spring boot项目引入mybatis plus后的的案例实践
- LeetCode刷题---逆波兰表达式求值
- 基于Flask的高并发部署方案
- Android布局字体大小不根据用户设置字体大小变化而变化
- metagpt学习实践
- vue项目报错RangeError: Maximum call stack size exceeded
- 关于java循环结构for
- 【JS笔记】JavaScript语法 《基础+重点》 知识内容,快速上手(二)