基于Python电影票房数据爬取分析可视化系统 计算机毕业设计(附源码)?
发布时间:2023年12月30日
毕业设计:2023-2024年计算机专业毕业设计选题汇总(建议收藏)
毕业设计:2023-2024年最新最全计算机专业毕设选题推荐汇总
🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业?。🍅
1、项目介绍
技术栈:
Python语言、Flask框架、MySQL数据库、Echarts可视化、requests爬虫、艺恩电影票房网
电影票房数采集分析可视化系统是一个基于Python语言、Flask框架、MySQL数据库、Echarts可视化和requests爬虫技术的系统。该系统的主要功能是采集艺恩电影票房网HTML页面中的电影票房数据,并进行分析和可视化展示。
2、项目界面
(1)地区票房占有率分析
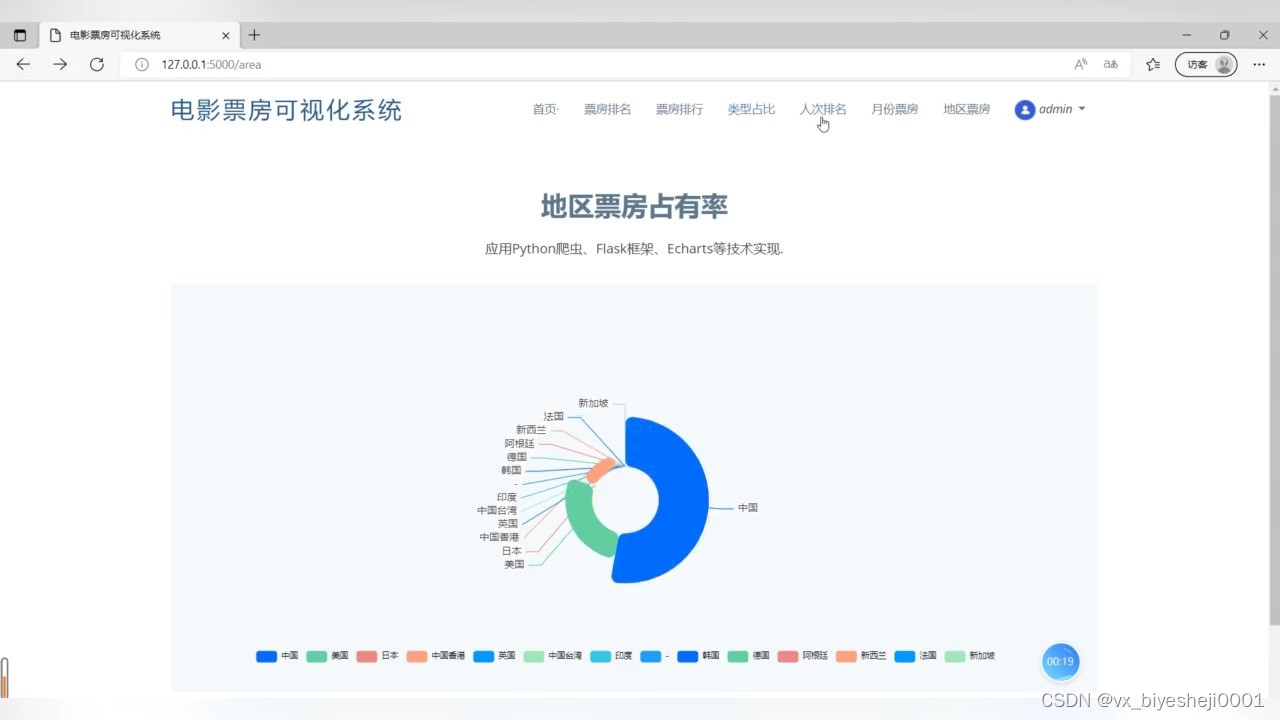
(2)月份票房分析
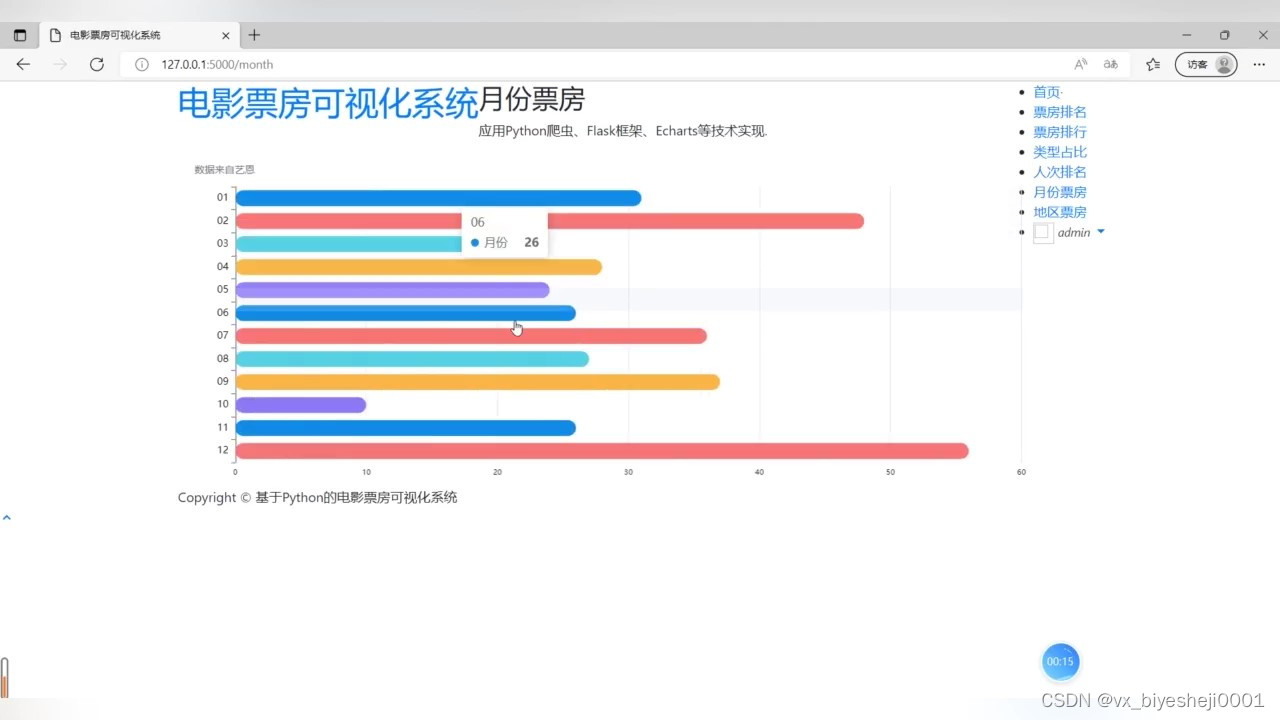
(3)电影类型票房占有率
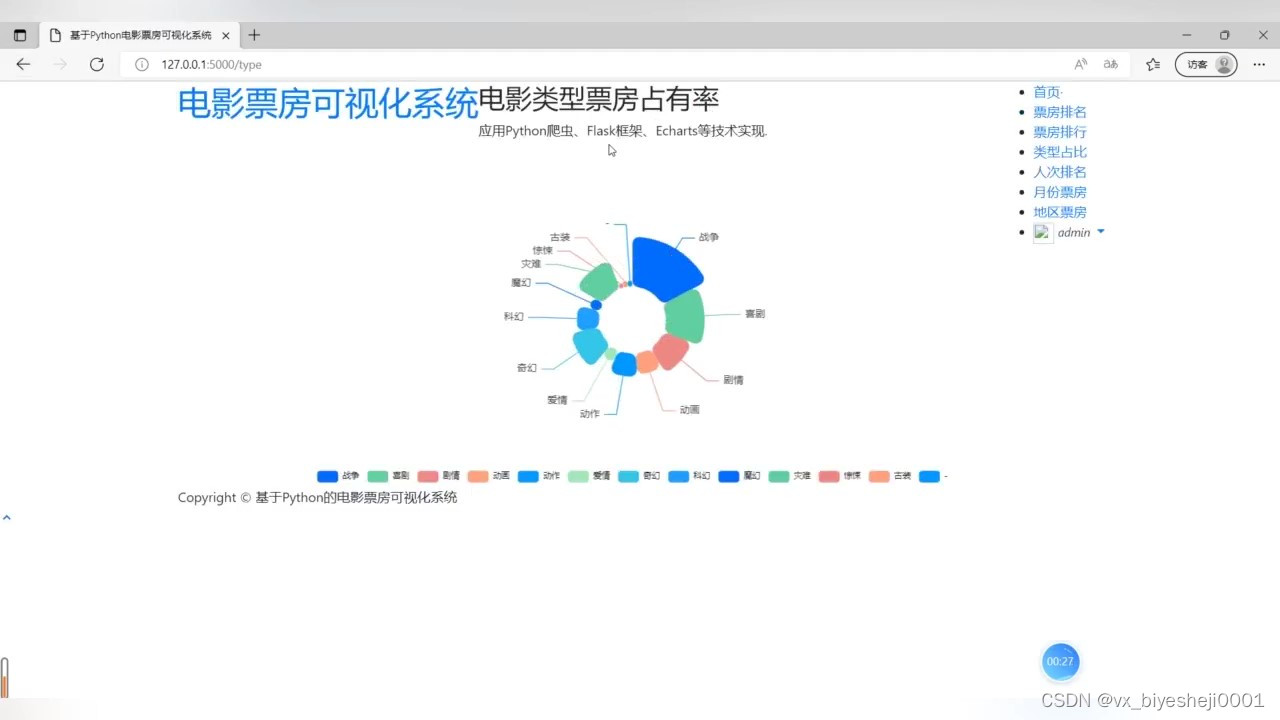
(4)首页展示
(5)实时票房排名
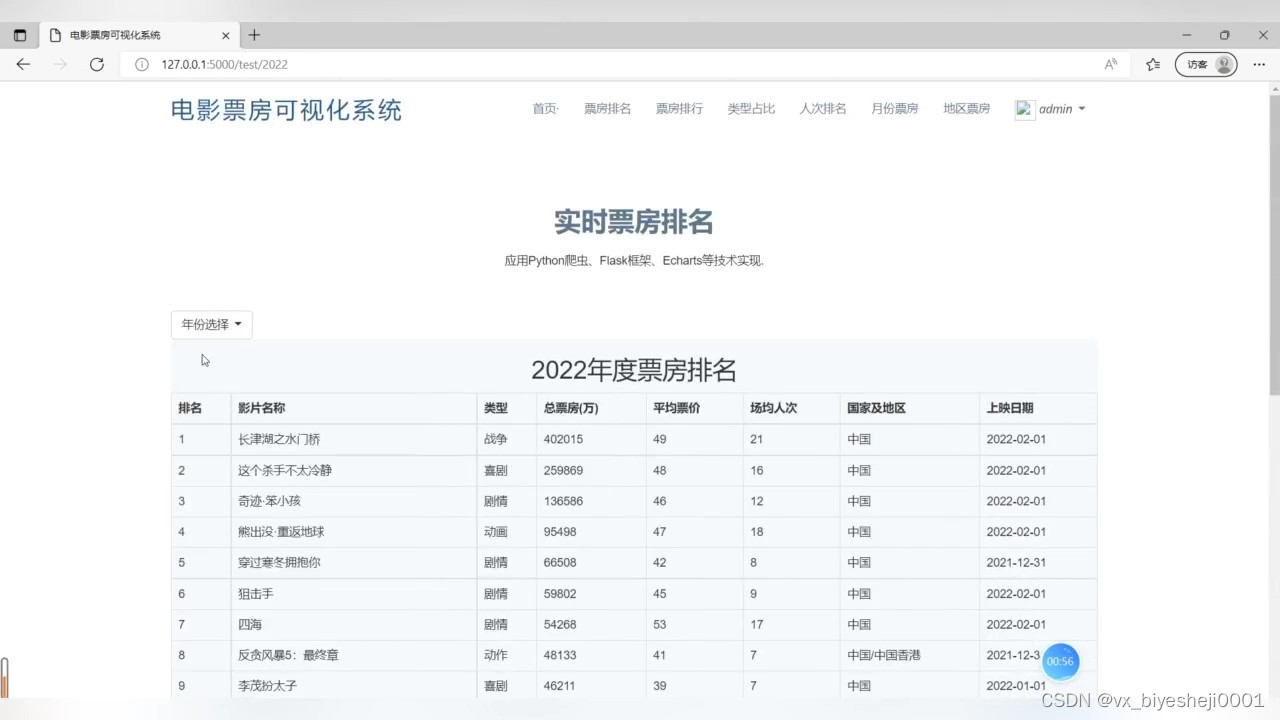
3、项目说明
电影票房数采集分析可视化系统是一个基于Python语言、Flask框架、MySQL数据库、Echarts可视化和requests爬虫技术的系统。该系统的主要功能是采集艺恩电影票房网HTML页面中的电影票房数据,并进行分析和可视化展示。
系统的工作流程如下:首先,通过使用requests爬虫技术,系统会自动从艺恩电影票房网上获取HTML页面。然后,使用Python语言和Flask框架将获取到的HTML页面进行解析和处理,并将数据存储到MySQL数据库中。
在数据库中存储了大量的电影票房数据后,系统可以根据用户需求进行数据分析和可视化展示。通过使用Echarts可视化技术,系统可以生成各种图表,如折线图、柱状图、饼图等,来展示电影票房的变化趋势、不同电影的票房对比等信息。
用户可以通过系统的界面进行操作,选择不同的时间段、地区、电影类型等条件,系统会根据用户的选择生成相应的图表和分析结果。用户还可以进行数据导出和分享,方便与他人进行交流和讨论。
通过该系统,用户可以方便地获取电影票房数据,并进行深入的分析和可视化展示。这对于电影行业的从业者、研究人员以及影迷来说都是一个有价值的工具。同时,由于系统避免了可能在中国是敏感的内容,因此可以放心使用。
4、核心代码
from selenium.webdriver import Chrome
from selenium.webdriver.support.select import Select
import sys
sys.path.append('utils')
import mysqlHelper
import datetime
import time
# 获取列表信息
def getData1(username):
web = Chrome()
web.get("https://www.endata.com.cn/BoxOffice/BO/Year/index.html")
# 找到下拉菜单
sel_list = web.find_element_by_xpath('//*[@id="OptionDate"]')
sel = Select(sel_list)
# 初始化信息列表
movie_id = []
movie_name = []
movie_type = []
movie_sale_number = []
movie_average_sale = []
movie_average_people = []
movie_country = []
movie_online_time = []
movie_year = []
startTime = datetime.datetime.now().strftime('%Y-%m-%d') + ' ' + time.strftime("%H:%M:%S")
for s in range(len(sel.options)):
# 使用index索引逐个选择下拉菜单
sel.select_by_index(s)
time.sleep(2)
# 获取到每一个tr
tr_list = web.find_elements_by_xpath('//*[@id="TableList"]/table/tbody/tr')
for tr in range(len(tr_list)):
# 获取select选中的值
ele_sel = web.find_element_by_xpath('//*[@id="OptionDate"]') # 获取Select元素对像
year = ele_sel.get_attribute('value') # 获取Select选中的值
# 获取每一个tr里的信息
money = tr_list[tr].find_element_by_xpath('./td[4]').text
money = money.replace(',', '')
movie_id.append(tr_list[tr].find_element_by_xpath('./td[1]').text)
movie_name.append(tr_list[tr].find_element_by_xpath('./td[2]').text)
movie_type.append(tr_list[tr].find_element_by_xpath('./td[3]').text)
movie_sale_number.append(money)
movie_average_sale.append(tr_list[tr].find_element_by_xpath('./td[5]').text)
movie_average_people.append(tr_list[tr].find_element_by_xpath('./td[6]').text)
movie_country.append(tr_list[tr].find_element_by_xpath('./td[7]').text)
movie_online_time.append(tr_list[tr].find_element_by_xpath('./td[8]').text)
movie_year.append(year)
print('数据获取完毕。。。')
web.close()
rows = zip(movie_id,movie_name, movie_type, movie_sale_number, movie_average_sale, movie_average_people, movie_country,movie_online_time,movie_year)
mysql = mysqlHelper.get_a_conn()
sql = 'truncate table tb_movie_year'
mysql.fetchall(sql)
for row in rows:
print(row)
sql = 'insert into tb_movie_year (id,movie_name,movie_type,movie_money,movie_price,movie_peo,movie_country,movie_date,movie_year) values("%s","%s","%s","%s","%s","%s","%s","%s","%s")' % row
mysql.execute(sql)
print('数据入库完毕。。。')
# 保存日志
endTime = datetime.datetime.now().strftime('%Y-%m-%d') + ' ' + time.strftime("%H:%M:%S")
url = 'https://www.endata.com.cn/BoxOffice/BO/Year/index.html'
user_name = username
sql = "SELECT count(1) num FROM tb_movie_year"
result = mysql.fetchall(sql)
data_num = result[0].get('num')
sql = 'insert into tbl_data_log (user_name,start_time,end_time,data_num,data_url) values ("%s","%s","%s","%s","%s")' % (user_name,startTime,endTime,data_num,url)
mysql.execute(sql)
if __name__ == '__main__':
getData1("脚本录入")
源码获取:
🍅由于篇幅限制,获取完整文章或源码、代做项目的,查看我的【用户名】、【专栏名称】、【顶部选题链接】就可以找到我啦🍅
感兴趣的可以先收藏起来,点赞、关注不迷路,下方查看👇🏻获取联系方式👇🏻
文章来源:https://blog.csdn.net/vx_biyesheji0001/article/details/135186202
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 新手入门:软件在测试过程中可能出现哪些问题?走,去看看~
- 基于DCT算法的数字水印嵌入、检测和攻击的Matlab代码实现
- 【PostgreSQL】从零开始:(二十一)数据类型-布尔类型
- 如何安装docker
- Python数据验证库之cerberus使用详解
- lv13 内核模块动态添加新功能 6
- STM32中断
- 复旦MBA科创青干营(二期):探索合肥科创企业的创新之路
- 【C++】最少知识原则
- RabbitMQ之消息可靠性投递解读