读论文之StoryGAN
StoryGAN: A Sequential Conditional GAN for Story Visualization
本文参考StoryGAN-CSDN博客
https://blog.csdn.net/Forlogen/article/details/93378325? ? ??????论文阅读:StoryGan - 简书 (jianshu.com)
项目源码:
目录
Abstract
????????我们提出了一个新的任务,称为故事可视化。给定一个多句段落,故事是通过生成一系列图像来可视化的,每个句子一个。与视频生成相比,故事可视化较少关注生成图像(帧)的连续性,而是更多地关注动态场景和字符之间的全局一致性——这是任何单幅图像或视频生成方法尚未解决的挑战。因此,我们提出了一种基于顺序条件 GAN 框架的新故事到图像序列生成模型 StoryGAN。我们的模型是独一无二的,因为它由一个深度上下文编码器组成,该编码器动态跟踪故事流,以及故事和图像级别的两个鉴别器,以提高图像质量和生成序列的一致性。为了评估模型,我们修改了现有数据集以创建 CLEVR-SV 和 Pororo-SV 数据集。根据经验,StoryGAN 在图像质量、上下文一致性指标和人工评估方面优于最先进的模型。
整个StoryGAN可以看做是一个序列化的条件生成对抗网络框架(sequential conditional GAN framework),模型主要包含一个处理故事流的深度上下文编码器(Deep Context Encoder)和两个Discriminator(image level和story level)。
Introduction
学习从自然语言故事中生成有意义且连贯的图像序列是一项具有挑战性的任务,需要对自然语言和图像的理解和推理。我们提出了一种新的故事可视化任务。具体来说,目标是生成一系列图像来描述以多句段落编写的故事,如图 1 所示
 ?
?
下面通过一个简单的例子理解一下上面的两个问题。如下所示,当输入为“Pororo and Crong are fishing together.Crong is looking at the bucket. Pororo has a fish on hisfishing rod.”时,它包含三个句子,那就需要生成三张图像。我们希望将整个故事的描述和当前所关注的句子一个喂给模型的图像生成器时,它可以生成逼真的图像,最后整体来看又可以保持一致性,即人从直观上认为生成的图像序列和故事描述是一致相符的。
这项任务有两个主要挑战。首先,图像序列必须始终如一地连贯地描述整个故事。该任务与文本到图像的生成高度相关 [35, 28, 17, 36, 34],其中图像是基于简短描述生成的。然而,将文本到图像的方法顺序应用于故事不会生成连贯的图像序列,而在故事可视化任务中失败。例如,考虑故事“红色金属圆柱体立方体位于中心。然后在右边添加一个绿色橡胶立方体。”仅第二句话并不能捕捉到整个场景。
第二个挑战是如何显示故事情节的逻辑。具体来说,随着故事的进展,对象的外观和背景中的布局必须以连贯的方式演变。这类似于视频生成。然而,故事可视化和视频生成的不同之处在于:
(i)视频剪辑是连续的,运动转换平滑,因此视频生成模型专注于提取动态特征以保持逼真的运动[32,31]。相比之下,故事可视化的目标是生成一系列关键静态帧,这些帧呈现正确的故事图,其中运动特征不太重要。
(ii) 视频剪辑通常基于简单的句子输入,通常具有静态背景,而复杂的故事要求模型捕捉情节线所需的场景变化。从这个意义上说,故事可视化也可以被视为通过捕捉尖锐的场景变化来实现现实世界长视频生成的关键步骤。为了应对这些挑战,我们提出了一个 StoryGAN 框架,该框架受到生成对抗网络 (GAN) [10] 的启发,这是一个生成器和判别器之间的两人游戏。为了考虑句子输入序列中的上下文信息,StoryGAN 被设计为顺序条件 GAN 模型。
给定一个多句段落(故事),StoryGAN 使用循环神经网络 (RNN) 将先前生成的图像合并到当前句子的图像生成中。上下文信息使用我们的上下文编码器模块提取,包括 GRU 单元的堆栈和我们新提出的 Text2Gist 单元。上下文编码器将当前句子和故事编码向量转换为高维特征向量 (Gist),用于进一步的图像生成。随着故事的进行,Gist 被动态更新以反映故事流中对象和场景的变化。在 Text2Gist 组件中,句子描述被转换为过滤器并适应故事,以便我们可以通过调整过滤器来优化混合过程。动态过滤[18]、注意力模型[34]和元学习[27]也采用了类似的想法。
为了确保生成图像序列之间的一致性,我们采用了两级 GAN 框架。我们使用图像级鉴别器来衡量句子与其生成图像的相关性,并使用故事级鉴别器来衡量生成的图像序列与整个故事之间的全局连贯性。
我们从现有的 CLEVR [19] 和 Pororo [21] 数据集创建了两个数据集,分别用于我们的故事可视化任务,分别称为 CLEVR-SV 和 Pororo-SV。根据经验,与现有的基线相比,StoryGAN 更有效地捕捉了故事的完整图景以及它是如何演变的 [36, 24]。StoryGAN 配备了深度上下文编码器模块和两级鉴别器,显着优于以前的最先进模型,生成一系列更高质量的图像,这些图像与图像质量和全局一致性指标中的故事一致,以及人工评估。
Related Work
变分自动编码器 (VAE) [23]、生成对抗网络 (GAN) [10] 和基于流的生成模型 [7, 8]) 已广泛应用于广泛的生成任务,包括文本到图像生成、视频生成、风格迁移和图像编辑。故事可视化属于生成任务的这种广泛分类,但有几个不同的方面。
与故事可视化任务非常相关的是条件文本到图像转换[28,17,38,35],现在可以生成高分辨率的真实图像[36,34]。文本到图像生成的一个关键任务是理解更长、更复杂的输入文本。例如,这在对话到图像生成中进行了探索,其中输入是一个完整的对话会话,而不是单个句子[29]。另一个相关的任务是文本图像编辑,它根据文本编辑查询编辑输入图像[3,30,4,9]。该任务需要原始图像和输出图像之间的一致性。最后,从文本描述 [20] 在图像中放置预先指定的图像和对象的任务。该任务还将文本与一致的图像相关联,但不需要完整的图像生成过程。
与故事可视化的第二个密切相关的任务是视频生成,特别是文本到视频[24,13]或图像到图像生成[1,31,32]。现有的方法只生成短视频剪辑[13,5,12],没有场景变化。视频生成的最大挑战是如何确保连续视频帧之间的平滑运动转换。现有工作中使用了轨迹、骨架或简单的地标来帮助建模运动特征[12,37,33]。为此,研究人员分别解开运动和背景的动态和静态特征[32,24,31,6]。在我们对故事可视化的建模中,整个故事设置静态特征,每个输入句子编码动态特征。然而,有几个差异:(i)条件视频生成只有一个输入,而我们的任务具有顺序、演化的输入; (ii) 视频剪辑中的运动是连续的,而可视化故事的图像是离散的,并且通常具有不同的场景视图。
文献中还有其他几个相关的任务。例如,从预先收集的训练集而不是图像生成[26]中提取故事图像检索。卡通生成已通过“剪切粘贴”技术进行了探索 [11]。然而,这两种技术都需要大量标记的训练数据。故事可视化的逆向任务是视觉叙事,其中输出是描述一系列输入图像的段落。文本生成模型或强化学习经常被突出显示用于视觉叙事 [16, 25, 15]。
StoryGAN
 ??StoryGAN的整体架构如图2所示。它被实现为顺序GAN模型,该模型由?
??StoryGAN的整体架构如图2所示。它被实现为顺序GAN模型,该模型由?
(i)故事编码器组成,将S编码为低维向量h0;
(ii)基于两层循环神经网络(RNN)的上下文编码器,它将输入句子st及其上下文信息编码为每个时间点t的向量ot(Gist);
(iii)图像生成器,根据每个时间步t的ot生成图像?xt;
(iv)图像鉴别器和指导图像生成过程的故事鉴别器,以确保生成的图像序列?X分别在局部和全局一致。
整体上来看StoryGAN就是一个序列化的生成模型,上图可看做是绿框部分按时间步展开的形式,主要部分为:Story Encoder、Context Enocder、Image Generator、Image Discriminator和Story Discriminator,其中Context Encoder中又包含GRU单元和Text2Gist单元两部分。模型的架构并不难理解,下面就逐个的看一下它们是如何配合完成Story-to-Sequential Images的工作。
?
Story Encoder
Story Encoder在图2的虚线粉色框中给出。按照StackGAN[36]中的条件机制,Story Encoder E(·)学习从故事S到低维嵌入向量h0的随机映射。h0对整个故事进行编码,作为上下文编码器隐藏单元的初始状态。具体来说,Story Encoder 从正态分布 h0 ~ E(S) = N (μ(S), Σ(S)) 中采样嵌入向量 h0,μ(·) 和 Σ(·) 实现为两个神经网络。我们将 Σ(S) = diag(σ2(S))) 限制为对角矩阵以计算可处理性。通过重新参数化技巧,编码的故事 h0 可以写成 h0 =μ(S) + σ2(S) 1 2 S ,其中 S ~ N (0, I)。符号表示元素乘法,平方根也是按元素拍摄的; μ(S) 和 σ2(S) 参数化为具有单个隐藏层的多层感知器 (MLP)。也可以使用卷积网络,具体取决于 S 的结构。将采样的 h0 提供给基于 RNN 的上下文编码器作为初始状态向量。
通过使用随机抽样,Story Encoder 处理原始故事空间中的不连续性问题,因此不仅导致 S 的紧凑语义表示用于故事可视化,而且在生成过程中增加了随机性。编码器的参数通过反向传播与 StoryGAN 的其他模块联合优化。因此,为了在潜在语义空间中强制条件流形的平滑度并避免折叠成单个生成点而不是分布,我们添加了正则化项 [36]、LKL = KL (N (μ(S)、diag(σ2(S))) ||N (0, I))) , (1) 是学习分布和标准高斯分布之间的 Kullback-Leibler (KL) 散度。 ?
?
? ?
? ?
?
Context Encoder
在故事的可视化任务重,角色、动作、背景是经常发生变化的
·如何从上下文信息中捕获到背景的变化
·如何组合新的输入语句和随机噪声来生成图像表示角色间的变化,有时这种变化还很巨大
????????本文提出了一种基于深度RNN的上下文编码器,它由两个隐藏层组成,低一层是标准的GRU单元,另一层是GRU的变体,作者称之为Text2Gist,如下所示:
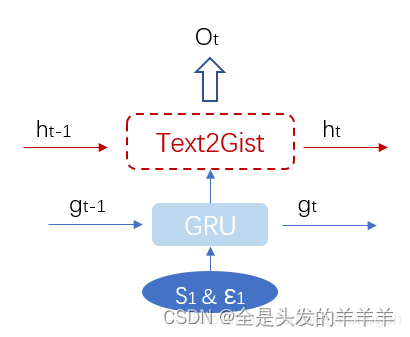 ?
?
其中每一层的公式表达如下所示
 ?
?
?其中gt的初始状态g0是采样自等距高斯分布(isometric Gaussian distribution)。Text2Gist详细的更新公式如下所示:
 ?
?
 ?
?
Discriminators
 ?
?
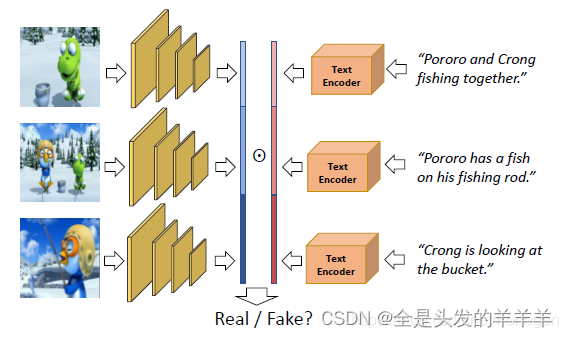 ?
?
? ?
?
Algorithm Outlines
StoryGAN的目标函数为![]() ?
?
 ?
? ?
?
Experiments?
在本节中,我们在一个玩具和一个卡通数据集上评估 StoryGAN 模型。据我们所知,目前还没有关于我们提出的故事可视化任务的工作。故事可视化最接近的替代方法是条件视频生成[24],其中故事被视为单个输入,生成视频来代替图像序列。然而,我们凭经验发现视频生成结果过于模糊,无法与 StoryGAN 相媲美。因此,我们的比较主要归功于我们提出的模型的消融版本。为了公平比较,所有模型在适用时都使用图像生成器、上下文编码器和鉴别器的相同结构。比较的基线模型是: ImageGAN、SVC、SVFN
实验部分的基准模型为ImageGAN、SVC和SVFN,后两个是StoryGAN的某种简化形式(类似于消融研究)
ImageGAN:不使用Story Discriminator, Story Encoder and Context Encoder。每个图像都是独立生成的。然而,为了合理的比较,我们将 st、编码的故事 S 和噪声项作为输入连接起来。否则,模型在任务上失败。这是 StoryGAN 的最简单版本。
SVC: StoryGAN中的Text2Gist单元被编码的故事和描述特征向量的简单级联所取代(如下所示)
 ?
?
SVFN: SVC中的级联被滤波器网络所取代。?
由于没有现有的数据集进行训练,研究人员根据现有的 CLEVR和 Pororo >数据集进行了修改,制作了 CLEVR-SV 和 Pororo-SV 两个数据集。
`CLEVR-SV 数据集
原版的 CLEVR 数据集用于视觉问答任务。研究人员使用如下方法将其改造为 CLEVR-SV:
1. 将一个故事中最多的目标数量限制在 4 个。
2. 目标为金属或橡胶制的物体,有八种颜色和两种尺寸。
3. 目标每次增加一个,直到形成一个由四幅图像序列构成的故事。
4. 研究人员生成了 10000 个图像序列用于训练,以及 3000 个图像序列用于测试。
 ?
?
????????输入 st 是当前对象的属性和由两个实数给出的相对位置,表示其坐标。例如,图 5 左列的第一个图像是从“黄色、大、金属、球体(-2.1、2.4)生成的。”以下对象以相同的方式描述。给定描述,生成的对象的外观应该与基本事实几乎没有变化,并且它们的相对位置应该是相似的。图 5 给出了结果比较。
????????ImageGAN [28] 未能保持“故事”的一致性,当对象数量增加时,它会混合属性。SVC 通过在底部包含故事鉴别器和 GRU 单元来解决这种一致性问题,因为图 5 的第三行在图像序列中具有一致的对象。
????????然而,SVC 按顺序生成不可信的图像。我们假设使用简单的向量连接不能有效地平衡当前描述与整个故事的重要性。
????????SVFN 可以在一定程度上缓解这个问题,但并不完全缓解。
相比之下,StoryGAN 生成比竞争对手更可行的图像。我们将性能改进归因于三个组件:
(i)Text2Gist 单元跟踪故事的进展;
(ii) Story and Image Discriminators在生成过程中保持对象的一致性;
(iii) 使用 Story Encoder 初始化 Text2Gist 单元在第一个生成的图像上产生更好的结果。这一最终点的更多经验证据出现在第 1 节中的卡通数据集中.
 ?
?
为了进一步验证 StoryGAN 模型,我们设计了一个任务来评估模型是否可以通过改变第一句描述来生成一致的图像。具体来说,我们随机替换了第一个对象的描述,同时在生成过程中保持其他三个相同,我们在附录 B 中的补充图 8 中可视化。该比较表明,只有 StoryGAN 可以通过正确利用后面帧中第一个对象的属性来保持故事的一致性,如上所述。在补充图 9 中,我们提供了额外的示例,仅使用 StoryGAN 更改初始属性。无论初始属性如何,StoryGAN 在帧之间是一致的。
 ?
?
我们还比较了生成的图像和ground truth[14]之间的结构相似性指数(SSIM)得分。SSIM最初用于测量失真图像的恢复结果。在这里,它用于确定生成的图像是否与输入描述对齐。表 1 给出了测试集上每种方法的 SSIM 度量。请注意,尽管这是一项生成任务,但使用 SSIM 来衡量结构相似性是合理的,因为给定描述几乎没有变化。在这个任务中,StoryGAN 明显优于其他基线。
其中SSIM 一种衡量两幅图像结构相似度的新指标,其值越大越好,最大为1.
`Pororo-SV 数据集
Pororo 数据集原本用来进行视频问答,每个一秒的视频片段都有超过一个手写描述,40 个视频片段构成一个完整的故事。每个故事有一些问题和答案对。整个数据集有 16K 个时长一秒的视频片段,以及 13 个不同角色,而手写描述平均有 13.6 个词,包括发生了什么,以及视频中是哪个角色。这些视频片段总共组成了 408 个故事。
研究人员将 Pororo 数据集进行了改造。他们将每个视频片段的描述作为故事的文本输入。对于每个视频片段,随机提取一帧画面(采样率为 30Hz)作为真实的图像样本用于训练。五个连续的图像组成一个完整故事。最后,研究人员制作了 15,336 个描述-故事对,其中 13000 个用于训练,剩余的 2336 个用于测试。该数据集被称为 Pororo-SV。
 ?
?
文本编码器使用具有固定预训练参数的通用编码 [2]。根据经验训练新的文本编码器几乎没有性能提升。图6给出了竞争方法的两个可视化故事。文本输入在顶部给出。ImageGAN不生成一致的图像序列;例如,生成的图像从室内随机切换到室外。此外,字符序列(例如 Pororo 的帽子)中字符的外观不一致。SVC 和 SVFN 可以在一定程度上提高一致性,但它们的局限性可以在不满意的第一张图像中看到。相比之下,StoryGAN 的第一个图像比其他基线具有更高的质量,因为使用 Story Encoder 来初始化循环单元。这显示了使用 Story Encoder 的输出作为随机初始化的第一个隐藏状态的优势。
为了探索不同的模型如何代表故事,我们进行了仅更改故事中的字符名称的实验,如图 7 所示。在视觉上,StoryGAN 在图像质量和一致性方面优于其他基线。
此外,我们执行两个不同的定量任务。第一个是确定生成是否能够捕获故事中的相关字符。从数据集中选择了九个最常见的字符。它们的名称和图片在附录 D 中的补充图 9 中提供。接下来,对训练集中的真实图像训练字符图像分类器,并应用于测试集中的真实图像和生成图像。我们将每个图像/故事对的分类准确度(在所有字符计数中仅完全匹配为正确)进行比较,作为生成是否与故事描述一致的指标。分类器在测试集上的表现为 86%,这被认为是任务的上限。请注意,标签中存在特殊性,因为人工生成的标签有时可以包含帧中未显示的字符。此外,分类器是在真实图像上训练的,而不是生成的图像,因此真实图像和生成图像之间的域差距可能会损害性能。然而,这些问题应该平等地损害所有算法,这是一个公平的比较。从下面的结果中,很明显,与基线模型相比,StoryGAN 增加了字符一致性。
 ?
?
 ?
?
Human Evaluation
自动指标不能完全评估 StoryGAN 的性能。因此,我们对 Pororo-SV 上的 Amazon Mechanical Turk 进行了基于成对和排名的人工评估研究。对于这两个任务,我们使用从测试集中采样的 170 个生成的图像序列,每个序列分配给 5 个工作人员以减少人类的方差。每个分配中的选项顺序被打乱以进行公平比较。
我们首先对 StoryGAN 和 ImageGAN 进行了成对比较。对于每个输入故事,工作人员会看到两个生成的图像序列,并要求他们从视觉质量2、一致性和相关性三个方面做出决策4。结果总结在表3中。这些估计上的标准误差很小,表明StoryGAN在这项任务中的表现大大优于ImageGAN。
接下来,我们进行了基于排名的人工评估。对于每个输入故事,工作人员被要求根据四个比较模型生成的图像的整体质量对它们进行排名。结果总结在表4中。StoryGAN获得了最高的平均排名,而ImageGAN表现最差。这些估计几乎没有不确定性,因此我们确信人类平均更喜欢 StoryGAN。
 ?
?
Conclusion
我们将故事可视化任务研究为顺序条件生成问题。所提出的 StoryGAN 模型通过将当前输入句子与上下文信息联合考虑来处理该任务。这是通过在上下文编码器中提出的 Text2Gist 组件实现的。从消融测试中,输入上的两级鉴别器和循环结构有助于确保生成的图像和要可视化的故事之间的一致性,而上下文编码器有效地提供具有局部和全局条件信息的图像生成器。定量和定性评估研究表明,与基线模型相比,StoryGAN 改进了生成。随着图像生成器的改进,故事可视化的质量也会提高。
ps:一些网络配置
本节介绍 StoryGAN 中使用的网络结构。在下文中,“CONV”表示 2D 卷积层,由输出通道号“C”、“内核大小”、“K”、“步长”和填充大小“P”配置。'LINEAR' 是全连接层,输入和输出维度在括号中给出。请注意,Filter Network 包含在 Text2Gist 单元中,该单元将其转换为过滤器。本节将详细介绍这一点
 ?
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 车载打气泵智能应用方案设计
- 常见类型的yaml文件如何编写?--kind: Deployment
- 汇总SqlSugar ORM框架的使用常见的问题以及相应的解决方式
- C++ ++ 和 -- 运算符重载
- JavaScript异常处理详解
- Selenium在vue框架下求生存
- 计算机丢失msvcr120.dll解决办法分享,实测有效
- 力扣面试150题 买卖股票的最佳时机IV
- 06 setup的基本用法
- Pandas实战100例 | 案例 37: 从长格式转换为宽格式