【LMM 005】LLaVA-Interactive:集图像聊天,分割,生成和编辑三种多模态技能于一体的Demo
论文标题:LLaVA-Interactive: An All-in-One Demo for Image Chat, Segmentation, Generation and Editing
论文作者:Wei-Ge Chen, Irina Spiridonova, Jianwei Yang, Jianfeng Gao, Chunyuan Li
作者单位:Microsoft Research, Redmond
论文原文:https://arxiv.org/abs/2311.00571
论文出处:–
论文被引:2(12/31/2023)
论文代码:https://github.com/LLaVA-VL/LLaVA-Interactive-Demo,219 star
项目主页:https://llava-vl.github.io/llava-interactive/
Abstract
LLaVA-Interactive 是多模态人机交互的研究原型。该系统可通过接收用户的多模态输入并生成多模态响应,与人类用户进行多轮对话。重要的是,LLaVA-Interactive 不局限于语言提示,它还启用了视觉提示,以便在交互中与人类意图保持一致。LLaVA-Interactive 的开发极具成本效益,因为该系统结合了预建人工智能模型的三种多模态技能,无需额外的模型训练:LLaVA [13] 的视觉聊天,SEEM [31] 的图像分割以及 GLIGEN [11] 的图像生成和编辑。本文介绍了一系列不同的应用场景,以展示 LLaVA-Interactive 的前景,并激发未来对多模态交互系统的研究。
1 Introduction
大型语言模型(LLM)[17 , 5]的快速发展彻底改变了聊天机器人系统。例如,OpenAI 的 ChatGPT [16] 在人机交互方面展现了前所未有的智能水平。ChatGPT 在语言任务上的成功激励了社区,他们期待将这一成功扩展到多模态领域,最终开发出通用的多模态人工智能智能体(Agent)[9]。GPT-4V [18] 的发布是朝着这一目标迈出的一大步。虽然 GPT-4V 展示了许多令人印象深刻的人工智能技能 [27, 15],但对于开源研究社区来说,仅基于 GPT-4V 构建多模态对话式人工智能智能体(Agent)仍具有挑战性,原因有二。
- i)GPT-4V 主要是一个基于语言的人机交互系统,用户输入的图像主要为文本输入提供视觉上下文,系统只能生成文本回复。
- ii)模型训练和系统架构的细节没有公开。
为了减轻这些挑战,我们提出了 LLaVA-Interactive 这个开源研究原型系统,它可以通过接收用户的多模态输入并生成多模态响应,与人类用户进行多轮对话。LLaVA-Interactive 结合了预建人工智能模型的三种多模态技能,无需额外的模型训练:
- LLaVA 的视觉聊天[13]
- SEEM 的图像分割[30]
- GLIGEN 的图像生成和编辑[11]
我们希望 LLaVA-Interactive 能与 GPT-4V 相辅相成,共同开发未来的多模态人工智能智能体(Agent),因为 LLaVA-Interactive 通过支持更丰富的视觉提示和开放源代码,提供了一个更具扩展性的框架。
- Visual Prompting。LLaVA-Interactive 支持灵活的语言视觉人机交互,允许人类用户使用各种视觉提示,如绘图、拖放或边界框,来表达用户意图,以完成涉及图像分割、生成和编辑的复杂多模态任务。因此,我们发现,与独立的 LMM(如 GPT-4V 或 LLaVA)相比,LLaVA-Interactive 能更好地遵循用户意图,产生更多参与式人机交互体验。
- Open-source。我们公开我们的系统和代码库,以促进社区未来的改进。
在本文的其余部分,第 2 节回顾了相关工作。第 3 节介绍了 LLaVA-Interactive 的界面、工作流程和人工智能技能。第 4 节介绍了使用 LLaVA-Interactive 开发人工智能智能体(Agent)以协助摄影艺术家的案例研究。第 5 节介绍了对 LLaVA-Interactive 的初步评估。
2 Related Works
LMM with Visual Output and Interaction.
现有的大多数 LMM 都是为支持视觉聊天(图像理解和推理)而开发的。
- GILL [8],CM3leon [29],Emu [20],DreamLLM [3],Kosmos-G [19] 和 MGIE [4]中展示了一些使 LMM 支持图像输出(如图像生成/编辑和分割)的探索性研究。NextGPT [26] 将这一想法推广到了视频和音频等其他模态。
- 与通过模型训练实现图像输出不同,另一个研究方向是促使 LLM 工程师使用多模态工具,如 Visual ChatGPT [25],X-GPT [30],MM-REACT [28],VisProg [7] 和 ViperGPT [21],其中具有图像输出的专家视觉模型在推理时被激活,而无需任何模型训练。
这两项研究都证明了 LLM 在图像输出方面的扩展能力。与它们类似,LLaVA-Interactive 也支持图像生成/编辑和分割。LLaVA-Interactive 在两个方面与现有研究不同:
- i)LLaVA-Interactive 的开发成本低,因为它是三个模型推理阶段的协同作用。不需要模型训练,也不需要 LLM 的提示词工程。
- ii)重要的是,LLaVA-Interactive 强调对视觉交互的支持,用户可以在分割和生成/编辑过程中绘制笔画来指定人的意图,这是现有视觉辅助系统所不具备的独特能力。
Unified Multimodal Modeling.
受用于语言任务的单一统一语言模型 ChatGPT 的成功启发,建立一个具有单一多模态基础模型的通用助手以完成更复杂的任务大有可为[9]。虽然针对所有视觉语言任务的统一 LMM 的开发仍处于探索阶段 [30, 10 , 6, 2, 14, 23 , 24],但我们相信这一方向在开启新的应用场景方面大有可为。我们将 LLaVA-Interactive 作为一个演示,展示这一研究方向的潜力,包括连接视觉和语言任务、完成各种域外任务(tasks in the wild)以及提供多模态可提示用户界面[9]。
3 LLaVA-Interactive
Interface.
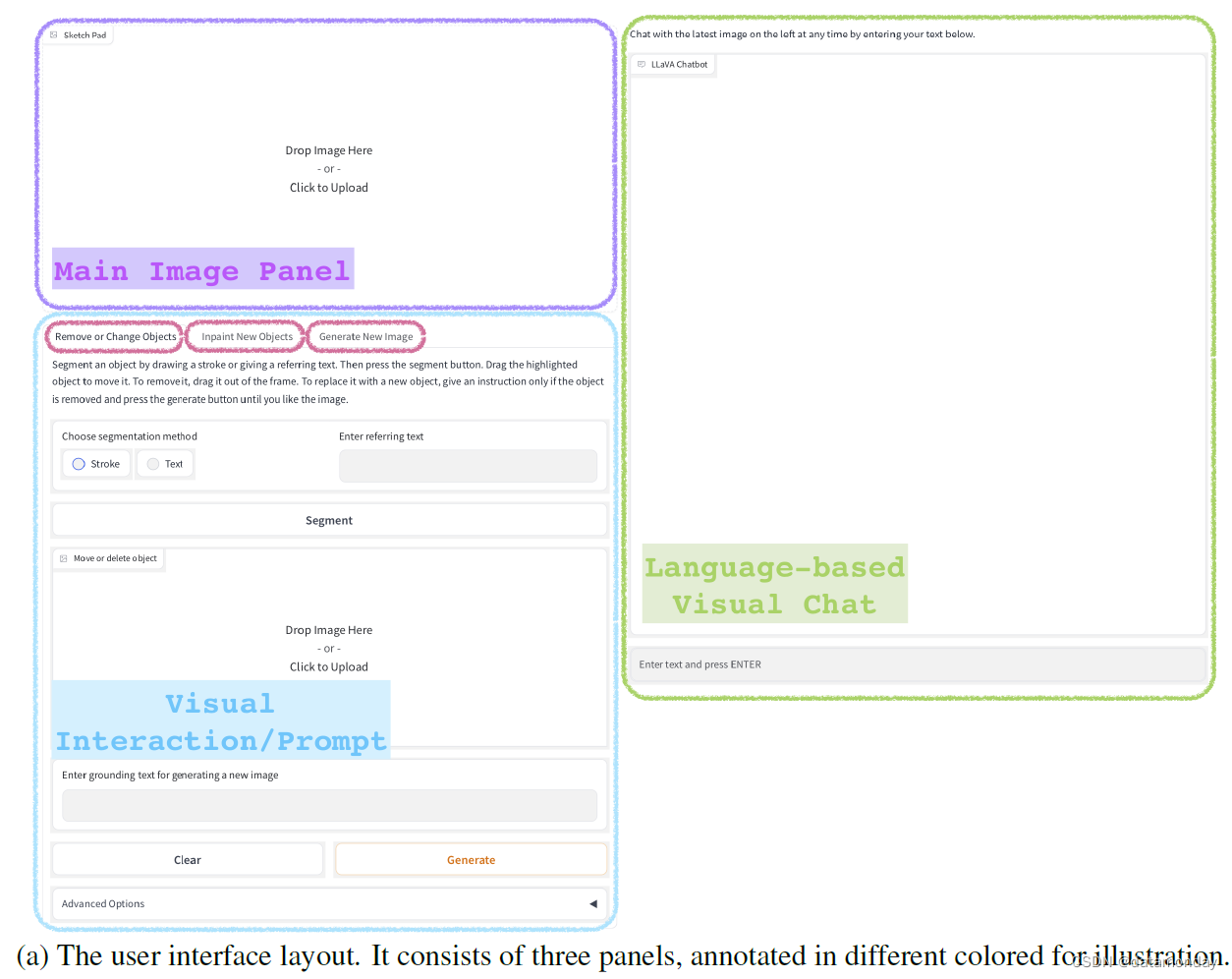

图 1 展示了 LLaVA-Interactive 的用户界面。界面的整体布局如图(a)所示,由三个面板组成,并用不同颜色标注,以方便展示。
- 左上方的紫色面板用于维护最新图像,并在必要时接受用户笔画等视觉提示;
- 右边的绿色面板是基于语言的聊天界面,接受用户关于图像的问题,并用自然语言进行回复。
- 左下方以蓝色标出的部分是视觉交互界面,由三个选项卡组成。每个选项卡都有其独特的功能,并显示在红色圆角矩形内。
为了说明人类如何利用视觉提示与 LLaVA-Interactive 交互,我们在图 1 的子图中为每个选项卡提供了一个示例。
- (b) 删除或更改物体。对于一幅图像,用户在感兴趣的物体上画一条线。单击 “分割” 按钮后,系统将提供物体分割掩码,例如,在本例中,码头在洋红色掩码中突出显示。将掩码从图像中拖出并单击 “生成” 按钮,就会生成删除物体的编辑图像,例如,本例中的码头就被删除了。(要在图像中添加具有精确尺寸和位置的物体,用户可以使用边界框指定物体的空间配置。每幅图对应一个包含笔触的最小尺寸框。物体的语义概念在基础指令中提供(用分号分隔)。单击 “生成” 按钮后,输入图像中就会出现所需的物体,例如,在本例中,湖中添加了一只小船和一只鸭子,天空中添加了一只鸟。
- (d) 生成新图像。要生成具有精确物体空间布局的全新图像,可在 “Sketch Pad” 上使用边界框指定物体布局,并提供图像级标题作为语言指令。点击 “生成” 按钮,一幅包含所需场景布局的新图像就生成了。在本例中,生成的新视觉场景将湖面上的小船和背景中的群山的语义可视化。在任何时候,用户都可以在三个视觉交互选项卡之间轻松切换,以迭代方式满足其预期的视觉创作要求。
Workflow.
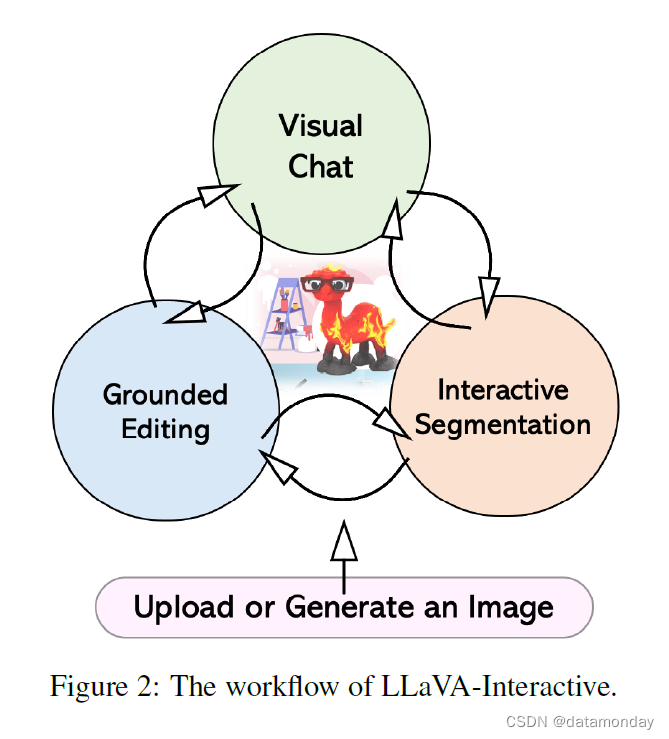
图 2 提供了 LLaVA-Interactive 的工作流程。我们将典型的可视化创建过程描述如下:
- 1)图像输入:首先需要一张图片。用户既可以上传图片,也可以通过提供语言说明和绘制边框来确定物体的空间排列来生成图片。图像准备好后,可以通过三种方法之一进行交互:聊天、分割或编辑。
- 2)视觉聊天:用户可以就图像提出问题,例如寻求修改建议。根据编辑建议,可分别使用步骤 3 或步骤 4 删除或添加物体。
- 3)交互式分割(Interactive Segmentation): 用户可以使用笔触绘图或文本提示创建物体掩码(mask)。要移除掩码,只需将其拖出图像,背景就会自动填充。或者,也可以将掩码移动到不同的位置。要使用新物体替换掩码,可提供掩码的文本提示。
- 4)图像编辑(Grounded Editing):用户可以直接在图像上放置新物体,方法是绘制边界框,并将相应的概念与目标物体关联起来。
- 5)多轮交互: 通过重复步骤 2,3 或 4,用户可以反复完善自己的视觉创作。
Capability Comparisons
LLaVA-Interactive 在 LLaVA 的基础上进行了功能扩展,支持用户绘制笔画和边界框等可视交互,以及可视图像生成/编辑。请参阅下面的功能比较:
3.1 Behind the Scenes: Individual Models
LLaVA-Interactive 是一个一体化演示,它在一个互动会话中连接了三个 LV 模型,用于图像聊天、分割和生成/编辑,可以完成比单个模型更复杂的任务。作为背景介绍,我们将简要介绍各个模型,供对关键技术感兴趣的人参考:
- LLaVA [13]: 大型语言和视觉助手是 GPT-4V 的第一个开源替代方案。它是一个端到端训练的大型多模态模型,结合了 CLIP 视觉编码器和用于通用视觉理解和推理的 Vicuna,模仿 GPT-4V 的精神实现了令人印象深刻的聊天功能。LLaVA-Interactive 中考虑了最近的 LLaVA-1.5 [12]。
- SEEM [31]: 通过多模态提示同时分割所有内容。SEEM 允许用户使用不同类型的提示轻松分割图像,包括视觉提示(点、标记、方框、涂鸦)和语言提示。它还可以使用任何提示组合或通用于自定义提示。
- GLIGEN [11]: Grounded-Language-to-Image Generation 是一个开源模型,它扩展了现有预训练文本到图像扩散模型的功能,使其也能以视觉提示(如边界框)为条件。
3.2 Development Challenges
LLaVA-Interactive 是一个系统级协同演示。它展示了通过利用现有模型检查点创建通用助手/智能体(Agent)的能力,无需额外的模型训练。虽然对人工智能模型的训练要求极低,但在开发 LLaVA-Interactive 的过程中,我们遇到了各种技术挑战。
- 首先,我们在使用 GLIGEN Inpainting 模型时遇到了困难,该模型缺乏填充背景的能力。作为解决方案,我们采用了 LaMA [22] 进行背景填充。
- 其次,我们使用的 Gradio 框架缺乏对用户交互的全面支持,例如拖放功能。为了解决这个问题,我们开发了一个新的 Gradio 图像组件工具,实现了所需的交互功能。
- 此外,整合多个复杂的项目和模型也是一个复杂性挑战,我们通过实验、简化的用户界面布局和高效的数据共享方案解决了这一问题。
- 最后,管理不同的软件包要求和依赖性也是一个挑战,这导致我们需要为不同的模型(如 LaMA)运行不同的网络服务。
4 Case Study: Multimodal Interactive Creation for Photographic Artists
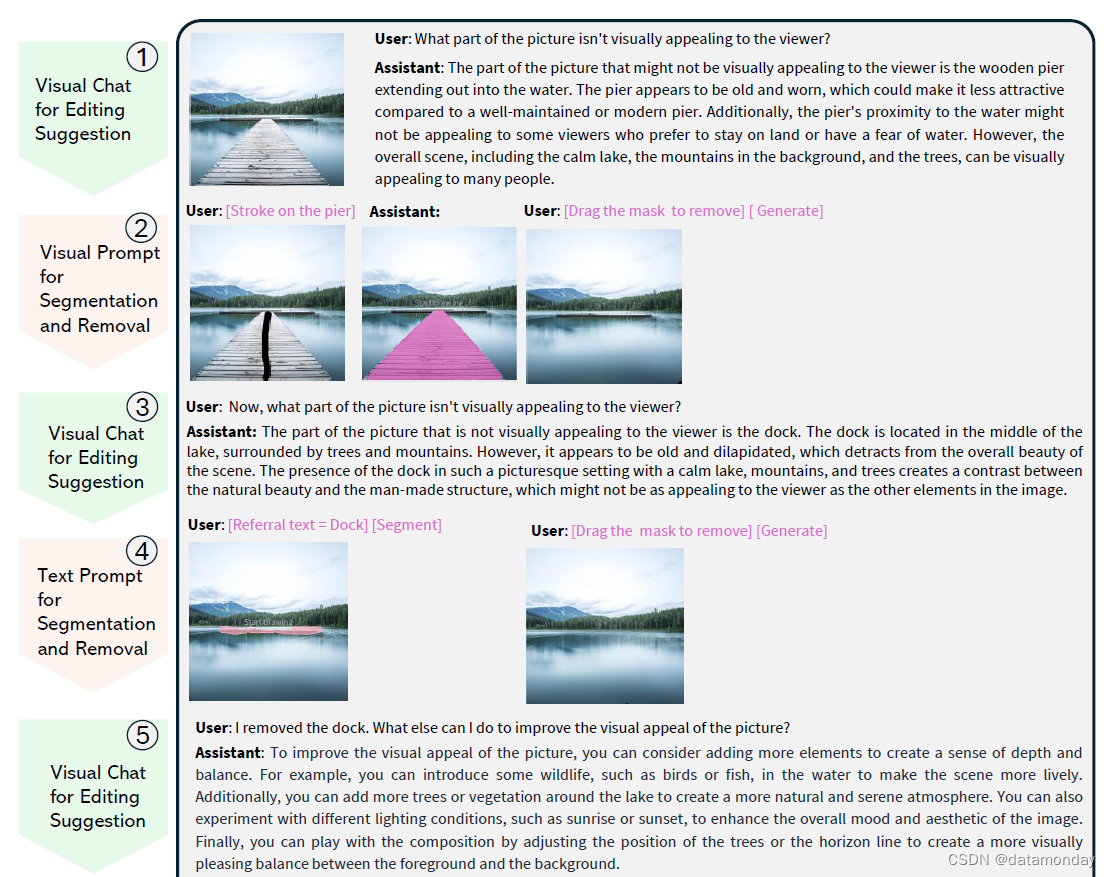

为了说明 LLaVA-Interactive 带来的更佳用户交互体验和应用场景,我们介绍了一个案例研究,重点是将其用作摄影艺术家的通用助手。图 3 展示了一个多轮多模态交互式图像编辑过程。图的左侧显示了每一轮的交互类型和功能,右侧则详细描述了交互过程。用户与助手之间以语言为基础的对话以文本形式呈现,用户的视觉提示以洋红色文本形式显示,图像编辑结果以处理后的图像形式显示。
我们在图 3 中描述了本案例研究的交互过程,该图可作为第 5 节中展示更多应用场景的示例。
-
1 一位用户首先上传了一张湖景图片,并征求改善视觉效果的建议。助手建议删除伸入水中的木质码头。
-
2 根据建议,用户转到 “移除和更改物体” 选项卡,选择 “描边” 模式,在图像的码头上绘制一条描边,然后单击 “分割”。码头的分割蒙版就会显示出来,在本例中以洋红色显示。用户可以进一步将掩码从图像中拖出,然后单击 “生成”,随后就会显示出没有码头的清澈湖面的更新图像。
-
3 根据更新后的图像,用户会进一步询问改善视觉效果的建议。助手建议移除湖中央的小码头。
-
4 根据建议,用户再次打开 “删除和更改物体” 选项卡。这一次,用户使用文本提示模式来分割物体,方法是选择文本,在输入引用文本框中输入 “码头”,然后单击分割按钮。Dock 的分割蒙版以洋红色显示。按照同样的拖动和生成步骤,突出显示的基座将从图像中移除。
-
5 用户希望得到更多改善图片视觉效果的建议,助手推荐了几个具体选项,其中提到了添加日落以增强图片的整体美感。
-
6 用户再次使用文本提示模式选择天空区域。要使用新物体替换选中的掩码,用户在 “输入生成新图像的基础文本” 框中输入 “日落场景”,然后单击 “生成”。一幅天空中有日落的新图像就显示出来了。
-
7 用户询问了进一步的编辑建议,发现夕阳在水面上的倒影可以使图像更吸引人、更逼真。
-
8 通过对水面执行类似的基于文本提示的分割和替换程序,图像的湖面上出现了天空中夕阳的倒影。
-
9 用户询问对最终成品的意见。助手认为这个最终版本可以有效传达自然之美。
5 Preliminary Evaluation with More Application Scenarios
5.1 Iterative Co-Creation of Visual Scene and Description




请参考图 4 和图 5 中的用户助手交互。对于内容创建者来说,从零开始联合创建视觉场景及其相关文本是非常有用的。在这个场景中,用户可以根据文本生成一个宁静、放松的户外场景,并通过画框指定空间布局。图像生成后,用户可以要求助手使用文本对图像进行描述和宣传。一次拍摄生成的视觉图像可能并不完美,可以反复改进,例如,在本例中,可以通过视觉提示去除灰色的海岸并添加一只白色的鹅。对于最终图像,用户可以要求助手制作一首中英文诗歌来宣传图像。必要时,用户还可以询问合成图像是否合理,例如天鹅与船的大小对比。可以看出,LLaVA-Interactive 的文字描述和回应往往与编辑后的图像是一致的。
5.2 Graphic Design for a Halloween Poster



请参考图 6、图 7 和图 8 中的用户辅助交互。为万圣节等节日设计具有视觉吸引力的海报和礼品卡需要富有想象力的概念和引人注目的美感。例如,在制作万圣节海报时,用户可以要求人工智能助手提供一系列创意,然后选择其中一个转化为图像。为了完善生成的图片,用户可以寻求更多建议,例如加入蝙蝠、将稻草人换成幽灵、移除较小的稻草人、添加骷髅、用蜘蛛网代替南瓜等。做出这些调整后,用户可以要求反馈,助手会确认设计有效地抓住了万圣节的精神。
5.3 Fashion Design for Kid’s Clothing


请参考图 9 和图 10 中的用户助手交互。设想有一天,用户看到运动衫背面有设计好的英文文字和图片,并希望在穿运动衫时个性化设计。首先要看运动衫上写了什么以及文字的含义。用户提出相关问题,助手就能正确回答这两个问题。这个简单的应用程序可以广泛用于识别市场上各种衣服上的文字。
通过 LLaVA-Interactive,用户可以按照个性化要求进一步编辑图片,添加蓝色帽子和太阳镜。助手可以对新图片进行评论,说 “设计的卡通熊戴着太阳镜和帽子,可能会吸引喜欢动物或有幽默感的孩子”。这种鼓励性的评论可以增强孩子对自己设计技能的信心。
助手还在评论中提到了城市 “丹佛”,助手猜测这可能是孩子的家乡或他们喜欢去的地方。根据这些评论,用户希望设计一幅新的丹佛市自然风景照片。为此,用户首先删除了小熊,只留下了背景;然后,用户通过指定物体的空间布局 “湖、船、帐篷、雪山” 来创建新的场景。有了新的图像,助手认为这是儿童服装的最佳选择,因为它兼具美感和想象力。
5.4 Food Preparation
Dinner Preparation for a Romantic Date

请参考图 11 中的用户助手交互。人们通常喜欢拍摄美味佳肴的照片。在计划浪漫晚餐时,人们通常会花时间和心思精心制作完美的菜肴,并辅以美酒和鲜花。尽管如此,他们仍然会担心晚餐是否准备充分,或者是否有任何可以改进的地方。
在这种情况下,我们建议使用 LLaVA-Interactive 获得宝贵的意见和建议。助手在表达对晚餐的热情的同时,也会提出一些具体的建议,比如加入沙拉来提升主菜的档次,使用蜡烛来营造温馨的氛围。通过实施这些建议,用户可以修改图像,制定各种虚拟晚餐方案,并提交给助手进行评估。一旦确定了理想的解决方案并得到助理的积极反馈,用户还可以要求就该特定晚餐的适当约会礼仪提供指导。
Food Preparation Recipe



请参考图 12 和图 13 中用户与助手的交互。在另一个例子中,用户可以使用现有的食材准备饭菜,询问必要的食材和烹饪说明。用户还可能决定更改某些元素,例如用大米代替黄油。再次询问同样的问题时,系统会提供最新的配料和烹饪说明列表,并附上修改后的烹饪提示。
5.5 Visual Content Creation and Story Telling
请参考图 14 中的用户辅助交互。视觉叙事的过程通常需要创造力和大量的时间投入,因为它涉及到开发引人注目的图像和富有想象力的文本。有时可能需要对视觉效果进行调整,以确保它们与整个场景相协调。在图 14 中,LLaVA-Interactive 可以为孩子们提供详细的描述和一个神奇的故事。
用户可以要求对图片进行可能的编辑,以获得更加奇思妙想的故事。系统会推荐一些更有趣、更富有想象力的元素,包括发光的蘑菇和超大的乐器。用户可以按照自己的想法,在图像中涂画新的物体,如在左侧第一个人物前面涂画一个生长的蘑菇,为正在打鼓的第四个人物涂画一个超大的鼓。
5.6 Education
Scientific Education.
请参考图 15 和图 16 中的用户辅助交互。为了吸引儿童学习科学概念,使用视觉图像和熟悉的主题(如卡通人物)来呈现信息是非常有效的。例如,生活在西雅图地区的儿童可能会被一幅以太空针塔和恐龙为主题的图片所吸引,该图片以粉色天空为背景,营造出一幅生动活泼的场景。这样的图片会因为其可识别的元素而吸引孩子的兴趣。然后,孩子可能会询问有关霸王龙的信息、粉色天空背后的原因、正午天空的颜色以及为什么会发生变化。此外,还可以将霸王龙换成各种机器人,促使孩子询问它们的功能和概念。通过使用熟悉且具有视觉吸引力的元素,学习科学知识可以成为孩子们的一种愉快体验。
Cartoon Reading Education.
请参考图 17 中的用户辅助交互。要提高解读漫画的能力,关键是要理解图像中的不同细节可以传达不同的含义。例如,在查看一幅社论漫画时,漫画中的一名男子身穿标有 “PRESS” 字样的衣服,并被球和链条捆绑着,助手可能会解释说,这幅图像隐喻了记者在追求真理的过程中遇到的障碍,以及维护其言论自由的意义。但是,如果去掉 “PRESS” 标签,再问同样的问题,回答可能会大相径庭。这幅漫画可能仍然传达了有关该男子所面临的挑战和压力的强烈视觉信息,但如果没有 “PRESS” 标签提供的背景,解释可能会大相径庭。
5.7 Interior Design
Interior Design: Large Living Room.


请参考图 18 和图 19 中的用户辅助交互。室内设计可以通过试错过程逐步完善。最初,用户根据文字描述提示创建图像,并就如何使设计现代化寻求建议。建议可能包括融入极简元素、采用现代风格、添加盆栽植物以及在墙上展示现代艺术品。然后,用户可以通过分割物体来修改设计,并使用笔划和文本提示进行调整。这样,这些新元素就会融合在一起,创造出一个更加舒适、更加新颖的客厅设计。
Interior Design: Small Living Room.


请参考图 20 和图 21 中用户与助手的交互。在另一个客厅设计场景中,助手提供了大量的改进方案。用户利用人工智能的交互式细分能力选择沙发和桌子,将它们更新为现代风格。此外,用户还使用接地的内画技能摆放了一盆植物。用户还可以询问具体的物件,如电视机的位置或更换吸顶灯。根据用户的建议,可以使用分割和内画技能对这些物体进行修改,以达到所需的效果。
5.8 Identification of Unusual and Risky Items
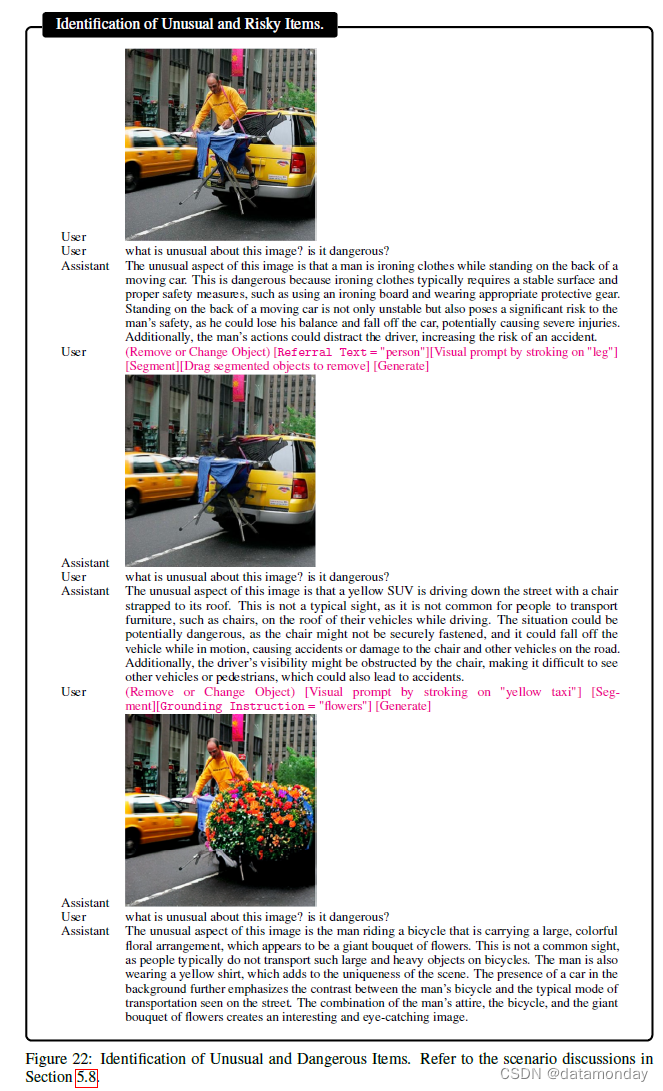
请参考图 22 中的用户助手交互。检测图像中的异常、反常和危险项目是安全和安保的一个重要方面。这一过程通常包括分析图像,以检测任何可能构成风险或偏离常规的物体或图案。我们以广为流传的极端熨烫图像为例,说明这一使用场景。一个典型的问题是报告图像中有哪些不寻常之处。我们会进一步询问潜在的危险。由于使用了底层 LLaVA 模型,LLaVA-Interactive 能够对此做出正确回应。由于行驶中的汽车和正在熨烫衣服的男子同时出现,图像显得很不寻常。我们通过每次移除一个元素来消除这一现象。移除人之后,熨烫活动就不会被报告。取而代之的是,在行驶的汽车上摆放一把椅子成为关键的不寻常元素。将行驶中的出租车换成鲜花,行驶中的汽车就不会被报告。取而代之的是,助手认为该男子骑着一辆自行车,车上载着一大束五颜六色的鲜花,这才是不寻常之处。这是有可能的,因为骑车的人可能躲在花丛后面。这种综合分析方法可以有效地检查视觉场景,识别异常情况。
6 Conclusions and Future Work
在本文中,我们介绍了 LLaVA-Interactive 这一研究演示原型,它展示了具有视觉输入、输出和交互功能的大型多模态模型的实际应用。LLaVA-Interactive 在系统开发中具有成本效益,因为它利用网络服务将三个预先训练好的互补技能多模态模型结合在一起,而不需要额外的模型训练:LLaVA 用于视觉聊天,SEEM 用于交互式图像分割,GLIGEN 用于接地图像生成和编辑。在系统层面,与其他系统相比,LLaVA-Interactive 在输入、输出和交互方面是一个完全的视觉语言多模态系统,尤其是在支持图像分割和生成/编辑的视觉提示方面独树一帜。我们对 LLaVA-Interactive 在各种实际应用场景中的初步评估表明,该系统具有出色的执行新的复杂任务的能力。我们希望这将激发对多模态基础模型的进一步研究。
我们确定了未来研究的几种潜在途径:
- i)LLaVA-Interactive 的能力受限于所使用的预训练模型的性能限制。要提高 LLaVA-Interactive 的特定技能,可以用更优秀的模型变体替换模块,或创建改进的单个模型,如 LLaVA、SEEM 和 GLIGEN。系统开发和单个模型开发可以分离,从而实现即插即用的系统服务方法。我们还希望扩展系统开发框架,纳入更多的功能,如用于图像级编辑的 Instruct Pix2Pix [1]。
- ii)由于 LLaVA-Interactive 是单个模型的复合体,它在每个推理过程中的能力取决于这些模型的现有能力。虽然可以通过迭代激活当前技能来完成更复杂的任务,但每次推理都不会通过在神经网络的隐藏空间内插值而产生新的技能。我们鼓励社会各界开发具有更统一建模的多模态基础模型,让新的能力通过潜在的任务组合出现。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 环信 CocoaPods could not find compatible versions for pod “HyphenateChat“:报错
- 移动硬盘一直插在电脑上有影响吗?好不好
- 基于Java JSP的实习管理系统的设计与实现
- IPQ8074: the leader in high-performance router motherboard chips
- Android Studi安卓读写NDEF智能海报源码
- 我的128天创作纪念日
- 关于eNSP中主机/PC无法ping通防火墙的解决方案
- RabbitMQ-消息延迟
- 手把手教你搭建SOCKS5代理伺服器
- 2017年喜茶数字营销变化