VCoder:大语言模型的眼睛
简介
VCoder的一个视觉编码器,能够帮助MLLM更好地理解和分析图像内容。提高模型在识别图像中的对象、理解图像场景方面的能力。
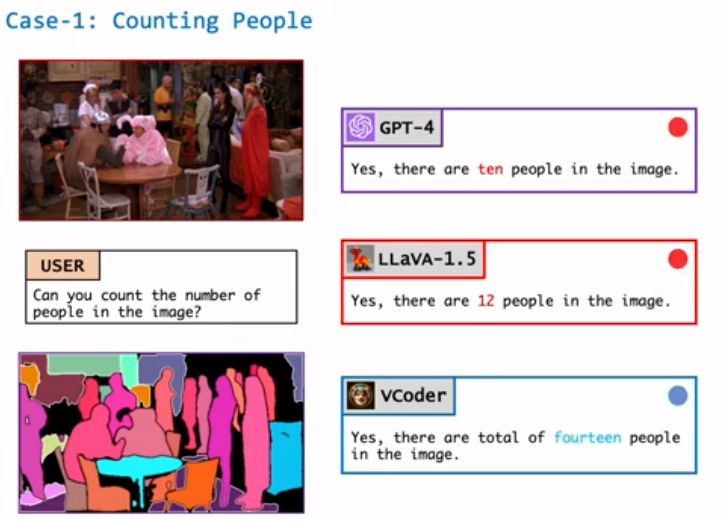
它可以帮助模型显示图片中不同物体的轮廓或深度图(显示物体距离相机的远近)。还能更准确的理解图片中的物体是什么,甚至能数出图片中有多少人。
功能介绍
1、增强视觉感知能力:VCoder通过提供额外的视觉编码器,帮助MLLM更好地理解和分析图像内容。
2、处理特殊类型的图像:VCoder能够处理分割图和深度图等特殊类型的图像。分割图可以帮助模型识别和理解图像中不同物体的边界和形状,而深度图则提供了物体距离相机远近的信息。
3、改善对象感知任务:VCoder通过提供额外的感知模态输入(如分割图或深度图)显著提高了MLLMs的对象感知能力。这包括更准确地识别和计数图像中的对象。
实验结果
VCoder与开源的多模态LLMs(如MiniGPT-4、InstructBLIP、LLaVA-1.5和CogVLM)进行了比较,并在COST验证集上进行了测试。
VCoder在对象识别任务中表现最佳,特别是在对象计数和识别方面优于基线模型。
在处理复杂场景中的对象计数和识别任务时,VCoder展示了更高的准确性,尤其是在场景中有许多实体时。
对比GPT-4V:实验表明,GPT-4V在所有对象识别任务中的表现一致,但在与VCoder的比较中,GPT-4V在对象级感知方面落后于VCoder。
项目及演示:https://praeclarumjj3.github.io/vcoder/
论文:https://arxiv.org/abs/2312.14233
GitHub:https://github.com/SHI-Labs/VCoder
在线演示:https://huggingface.co/spaces/shi-labs/VCoder
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 解锁Redis Stream新境界:高级用法大揭秘【二】
- Vue中el与data的两种写法
- 自动化生产线-采用工业机器人比人工有哪些优势?
- win10录屏文件在哪?这里告诉你答案
- nginx配置后不生效的问题
- ChatGPT使用注意事项有哪些?
- 【DevOps 工具链】软件版本号命名规范 - 3种规则(读这一篇就够了)
- Redis缓存八大模式,项目应用选型?这篇文章就够了
- 如何停止一个运行中的Docker容器
- 05. BI - 金融行业中 Fintech 的应用场景