【对比学习+分割】CRIS:CLIP驱动RIS图像分割(CVPR 2022)
论文地址:CRIS: CLIP-Driven Referring Image Segmentation
代码地址:CRIS.pytorch
相关领域: CLIP、RIS、对比学习、多模态
指代图像分割(Referring Image Segmentation,RIS)(这个词是我翻译的感觉很奇怪,后面用RIS代替)旨在根据自然语言表达来标记图像或视频中表示对象实例的像素,也就是根据自然语言描述来实现图像分割。
开放词汇语义分割(Open Vocabulary Semantic Segmentation)是一种新颖的语义分割方法,其特点在于可以识别任意类别的语义区域,而不是仅限于预定义的类别。
摘要
指代图像分割(Referring Image Segmentation,RIS)旨在通过自然语言表达对参考对象进行分割。由于文本和图像之间具有明显的数据属性差异,因此网络能够很好地对齐文本和像素级特征是具有挑战性的。现有的方法使用预训练模型来促进学习,但是数据分别从预训练模型中转移到语言和视觉知识,忽略了多模态对应信息。受CLIP(Contrastive Language-Image Pretraining)在最近取得的进展的启发,本文提出了一个端到端的CLIP驱动的参考图像分割框架(CRIS)。为了有效地传递多模态知识,CRIS采用了视觉语言解码和对比学习来实现文本到像素的对齐。具体而言,我们设计了一个视觉语言解码器,将细粒度的语义信息从文本表示传播到每个像素级激活,从而促进两种模态之间的一致性。此外,我们提出了文本到像素的对比学习,明确强化文本特征与相关的像素级特征相似,与不相关的特征不相似。在三个基准数据集上的实验结果表明,我们提出的框架在没有任何后处理的情况下显著优于最先进的性能。
首图
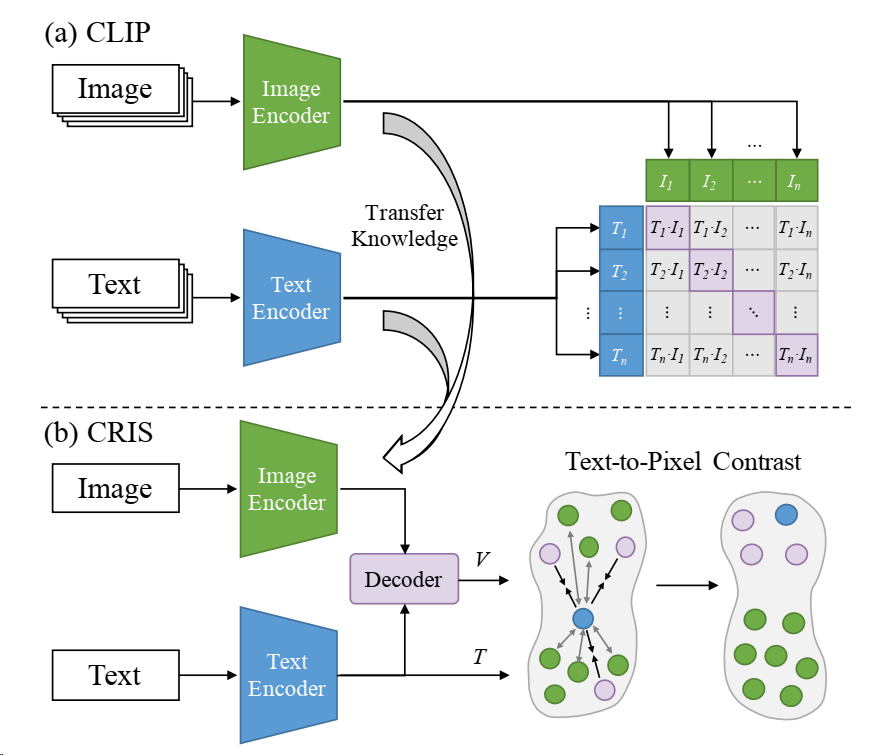
(a) CLIP 训练图像编码器和文本编码器,以预测一批图像 I 和文本 T 的正确配对,这可以捕捉多模态对应信息。 (b) CRIS 为了将CLIP模型从图像级别传递到像素级别的知识,我们提出了一个CLIP驱动的参考图像分割(CRIS)框架。首先,我们设计了一个视觉语言解码器,将细粒度的语义信息从文本特征传播到像素级视觉特征。其次,我们将所有像素级视觉特征V与全局文本特征T相结合,并采用对比学习,拉近文本和相关的像素特征,推远其他不相关的特征。
主图
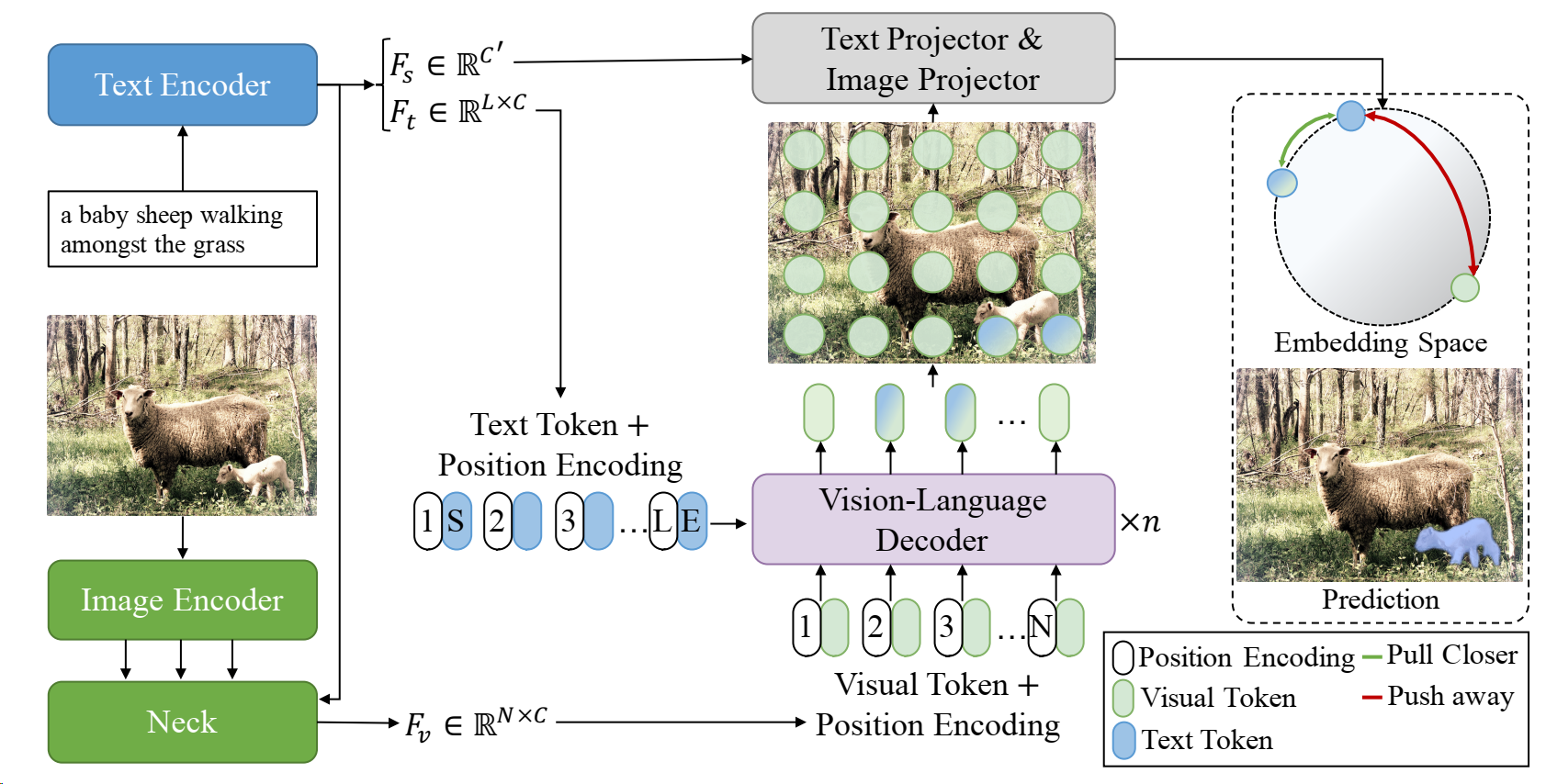
- 介绍了提出的CRIS框架是如何将CLIP的知识转移到RIS,通过利用多模态对应信息实现文本到像素的对齐。
- 首先,我们使用ResNet 和Transformer 分别提取图像和文本特征,然后将它们融合以获得简单的多模态特征。
- 其次,这些特征和文本特征被输入到视觉语言解码器中,以将细粒度的语义信息从文本表示传播到像素级视觉激活。
- 最后,我们使用两个投影器生成最终的预测掩码,并采用文本到像素的对比损失,明确将文本特征与相关的像素级视觉特征对齐。
文本编码器
输入L个token,采用Transformer编码器,输出 F t F_t Ft?大小L*C就是直接编码得到的句子信息,C是dim; F s F_s Fs?是全局信息,dim是C’;
图像编码器
输入图片H×W×3,采用2th-4th stages ResNet编码器,得到特征 F v 2 F_{v2} Fv2?、 F v 3 F_{v3} Fv3?、 F v 4 F_{v4} Fv4?分别是原始图像下采样8、16、32倍的特征,这里的C是通道数。比如 F v 4 F_{v4} Fv4? ∈ R { H/32 × W/32 × C 4 C_4 C4? }。
Cross-modal Neck
采用文本全局特征
F
s
F_s
Fs?和图像
F
v
4
F_{v4}
Fv4?特征融合,Up是上采样。一通融合,最后要的是
F
v
F_v
Fv?,融合公式:
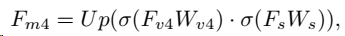
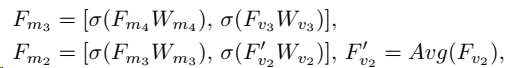
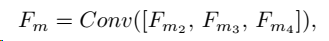
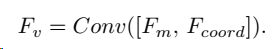
Vision-Language 解码
用了一些自注意力和交叉注意力,整合了逐句的语义特征 F t F_t Ft?和带有全局语义信息的图像 F v F_v Fv?特征,得到了representaion F c F_c Fc?
Text-to-Pixel 对比学习
CLIP缺点:CLIP通过将文本表示与图像级别表示的对齐来学习加强的图像级别视觉表示,但这种知识对于RIS来说并不是最优的,因为它缺乏更精细的视觉概念。
为了解决这个问题,我们设计了一种文本到像素的对比损失,明确将文本特征与相应的像素级视觉特征对齐。如主图所示,采用图像和文本投影器将
F
c
F_c
Fc?和
F
s
F_s
Fs?转换如下:
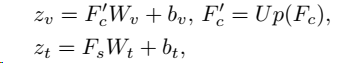
其中
z
t
z_t
zt? ∈
R
D
R^D
RD,
z
v
z_v
zv? ∈
R
N
×
D
R^{N×D}
RN×D,N = H/4 × W/4,Up表示4×上采样。这里注意:对于每个样本,语义特征的维度等于每个像素的特征维度,这样后面就方便算相似度了。
接下来是对比部分:给定映射后的文本特征
z
t
z_t
zt?和映射后的像素级特征
z
v
z_v
zv?,采用对比损失来优化两种模态之间的关系,其中
z
t
z_t
zt?被鼓励与其相应的
z
v
z_v
zv?相似,与其他不相关的
z
v
z_v
zv?不相似。通过点积测量的相似性,文本到像素的对比损失可以表示为:
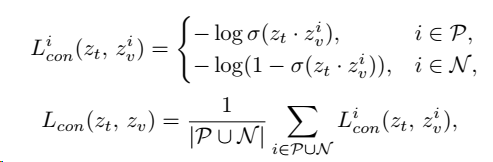
其中P和N表示Ground Truth中类别“1”和“0”。**上面的公式表示针对每个像素和语义特征做计算,下面的公式表示对每个像素的计算值做平均。**最后,为了获得最终的分割结果,我们将σ(
z
t
?
z
v
z_t*z_v
zt??zv?) reshape为H/4 × W/4,并将其上采样回原始图像大小。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!