使用 GPT4 和 ChatGPT 开发应用:第四章到第五章
原文:Developing Apps with GPT-4 and ChatGPT
译者:飞龙
第四章:GPT-4 和 ChatGPT 的高级技术
现在你已经熟悉了 LLM 的基础知识和 OpenAI API,是时候将你的技能提升到下一个水平了。本章涵盖了强大的策略,将使你能够充分利用 ChatGPT 和 GPT-4 的潜力。从提示工程、零-shot 学习和少-shot 学习到为特定任务微调模型,本章将为你提供创建任何你能想象的应用所需的所有知识。
提示工程
在深入研究提示工程之前,让我们简要回顾一下聊天模型的completion函数,因为本节将广泛使用它。为了使代码更紧凑,我们将定义该函数如下:
def chat_completion(prompt, model="gpt-4", temperature=0):
res = openai.ChatCompletion.create(
model=model,
messages=[{"role": "user", "content": prompt}],
temperature=temperature,
)
print(res["choices"][0]["message"]["content"])
该函数接收一个提示,并在终端显示完成的结果。模型和温度是两个可选的特性,默认分别设置为 GPT-4 和 0。
为了演示提示工程,我们将回到示例文本“正如笛卡尔所说,我思故我在”。如果将此输入传递给 GPT-4,模型自然会通过迭代添加最有可能的标记来完成句子:
chat_completion("As Descartes said, I think therefore")
因此,我们得到以下输出消息:
I am. This famous philosophical statement, also known as "Cogito, ergo sum,"
emphasizes the existence of the self through the act of thinking or doubting.
Descartes used this statement as a foundational principle in his philosophy,
arguing that one's own existence is the most certain and indubitable fact
that can be known.
提示工程是一门新兴的学科,专注于制定构建 LLM 的最佳输入的最佳实践,以便尽可能以编程方式产生理想的输出。作为一名 AI 工程师,你必须知道如何与 AI 交互,以获取可利用的结果,如何提出正确的问题,以及如何编写高质量的提示;这些都是我们将在本节中涵盖的所有主题。
应该注意,提示工程可能会影响使用 OpenAI API 的成本。你将支付的金额与你发送和接收的令牌数量成正比。如在第二章中提到的,强烈建议使用max_token参数,以避免账单上的不愉快的惊喜。
还要注意,你应该考虑在openai方法中可以使用的不同参数,因为如果你使用temperature、top_p和max_token等参数,即使使用相同的提示,也可能得到显著不同的结果。
设计有效的提示
通过提示可以执行许多任务。它们包括摘要、文本分类、情感分析和问题回答。在所有这些任务中,通常在提示中定义三个要素:角色、上下文和任务,如图 4-1 所示。

图 4-1。一个有效的提示
这三个要素并非总是必要的,它们的顺序也可以改变,但如果你的提示构造得当,要素定义得当,你应该能够得到良好的结果。请注意,即使在使用这三个要素时,对于复杂的任务,你可能需要使用更高级的技术,如零-shot 学习、少-shot 学习和微调。这些高级技术将在本章后面讨论。
上下文
提示中的第一个基本要素是上下文。当你为 LLM 编写输入文本时,你必须尽可能详细地描述上下文。为了说明这一点,假设你想使用 GPT-4 创建一个应用程序,为午餐建议主菜。接下来,我们将比较在两种不同上下文下获得的结果。第一个上下文将有很少的细节,第二个将有更多的细节。
对于一个简短的输入消息,比如:
chat_completion("Give me a suggestion for the main course for today's lunch.")
我们得到以下输出消息:
Grilled chicken with roasted vegetables and quinoa.
现在,关于输入消息的上下文的更多细节:
prompt = """
Context: I do 2 hours of sport a day. I am vegetarian, and I don't like green
vegetables. I am conscientious about eating healthily.
Task: Give me a suggestion for a main course for today's lunch."""
chat_completion(prompt)
我们得到以下输出消息:
For today's lunch, you can try a Chickpea and Sweet Potato Curry served with
Quinoa. This dish is packed with protein, fiber, and essential nutrients,
while also being vegetarian and not relying on green vegetables. The curry
can be made with chickpeas, sweet potatoes, tomatoes, onions, garlic, and a
blend of spices like turmeric, cumin, and coriander. Cook the quinoa
separately and serve it alongside the curry for a delicious and healthy meal.
在第二个例子中,句子更加详细,因为模型有更多的上下文:它建议了一个富含蛋白质的健康素食菜肴。
上下文指导 GPT 的“思考”,为其回应增加价值。构建具有良好上下文的提示是一个迭代的过程,通常需要试错步骤。有时确定上下文必须包含的要点是有些棘手的。为了确定可能的改进,您可以向 GPT-4 寻求建议。在以下示例中,我们改变了提示:不是要求模型回答我们的问题,而是指示它在努力实现更好的完成时询问上下文的问题。
使用以下输入消息:
prompt = """
Context: I do 2 hours of sport a day. I am vegetarian and I don't like green
vegetables. I am very careful to eat healthily.
Task: Give me a suggestion for a main course for today's lunch?
Do not perform the requested task! Instead, can you ask me questions about the
context so that when I answer, you can perform the requested task more
efficiently?
"""
chat_completion(prompt)
我们从 GPT-4 模型中得到以下问题:
Sure, I have a few questions to help me suggest a suitable main course for you:
1\. What type of sport do you do, and do you have any specific nutritional
requirements related to it?
2\. Are there any other vegetables or ingredients that you particularly enjoy
or dislike?
3\. Do you prefer a hot or cold meal for lunch?
4\. Are you open to trying new recipes or do you prefer sticking to
familiar dishes?
模型提出的问题通常是相关的。根据这些问题,您可以更新提示中的上下文。因此,我们建议您在构建提示时经常使用这个技巧。
任务
任务定义了您对 GPT-4 模型的使用,并且应该明确定义和具体。您应该为任务提供足够的信息,并在提示中使用适当的短语来引导模型达到期望的结果。
在前面的部分中,任务是让模型建议午餐的主菜。我们可以添加细节来澄清我们想要什么。在这里,我们要求模型添加一个表格,其中包含每种食材和所需数量(以克为单位):
prompt = """
Context: I do 2 hours of sport a day. I am vegetarian, and I don't like green
vegetables. I am conscientious about eating healthily.
Task: Give me a suggestion for a main course for today's lunch.
With this suggestion, I also want a table with two columns where each row
contains an ingredient from the main course.
The first column in the table is the name of the ingredient.
The second column of the table is the number of grams of that ingredient needed
for one person. Do not give the recipe for preparing the main course.
"""
chat_completion(prompt)
该模型给出了以下输出:
Suggestion for today's lunch: Stuffed Bell Peppers with Quinoa and Black Beans
| Ingredient | Grams per person |
|---------------------|------------------|
| Bell peppers | 200g |
| Quinoa | 60g |
| Black beans | 75g |
| Onion | 50g |
| Garlic | 5g |
| Olive oil | 10g |
| Tomato sauce | 50g |
| Cumin | 1g |
| Chili powder | 1g |
| Salt | 1g |
| Pepper | 1g |
| Shredded cheese | 30g |
在OpenAI API 示例页面上,有一个包含 48 个 GPT 模型可以执行的任务示例列表,始终与相关提示和演示一起。虽然这些示例使用了 GPT-3 模型和完成端点,但对于聊天端点原则是相同的,这些示例很好地说明了如何向 OpenAI 模型提供任务。我们不会在这里逐个讨论它们,但以下是其中的一些:
语法纠正
纠正句子到标准英语。
提示:
Correct this to standard English: She no went to the market.
为二年级学生总结
将复杂的文本转化为更简单的概念。
提示:
Summarize this for a second-grade student: Jupiter is the fifth planet [...]
TL;DR 总结
TL;DR 代表“太长了;没读”。已经观察到,可以通过简单地在末尾添加T``l;dr来总结一段文本。
提示:
A neutron star [...] atomic nuclei. Tl;dr
Python 转自然语言
用人们能理解的语言解释一段 Python 代码。
提示:
# Python 3
def hello(x):
print('hello '+str(x))
# Explanation of what the code does
计算时间复杂度
找到函数的时间复杂度。
提示:
# Python 3
def hello(x, n):
for i in range(n):
print('hello '+str(x))
# The time complexity of this function is
Python 错误修复程序
修复包含错误的代码。
提示:
### Buggy Python
def hello(x, n):
for i in rang(n):
print('hello '+str(x))
### Fixed Python
SQL 请求
简单的 SQL 查询构建。
提示:
Create a SQL request to find all users who live in California and have
over 1000 credits.
类比制造者
可以对两个单词进行类比。
提示:
Create an analogy for this phrase. Questions are arrows in that:
总结笔记
总结会议记录。
提示:
Convert my shorthand into a first-hand account of the meeting:
Tom: Profits up 50%
Jane: New servers are online
Kjel: Need more time to fix software
角色
在撰写提示时影响模型的最后一种方法是给它一个角色。当然,角色和上下文可以独立使用,但同时使用可以增加您对模型输出的控制。在以下示例中,我们让模型扮演体育营养专家的角色:
prompt = """
Role: You are a nutritionist designing healthy diets for high-performance
athletes. You take into account the nutrition needed for a good recovery.
Context: I do 2 hours of sport a day. I am vegetarian, and I don't like green
vegetables. I am conscientious about eating healthily.
Task: Based on your expertise defined in your role, give me a suggestion for a
main course for today's lunch. With this suggestion, I also want a table with
two columns where each row in the table contains an ingredient from the main
course. The first column in the table is the name of the ingredient.
The second column of the table is the number of grams of that ingredient needed
for one person. Do not give the recipe for preparing the main course.
"""
chat_completion(prompt)
然后我们得到以下结果:
Main Course Suggestion: Quinoa and Chickpea Stuffed Bell Peppers
Ingredient Table:
| Ingredient | Grams per Person |
|---------------------|------------------|
| Quinoa | 60 |
| Chickpeas | 100 |
| Bell Peppers | 200 |
| Olive Oil | 10 |
| Onion | 50 |
| Garlic | 5 |
| Tomato | 100 |
| Feta Cheese | 30 |
| Kalamata Olives | 20 |
| Fresh Basil | 5 |
| Salt | 2 |
| Black Pepper | 1 |
正如您所见,提示可以用来调整 GPT 模型等 LLM 的概率分布集。它们可以被视为指导模型产生特定类型结果的指南。虽然提示设计没有确定的结构,但一个有用的框架是上下文、角色和任务的组合。
重要的是要理解,这只是一种方法,提示可以在不明确定义这些元素的情况下创建。有些提示可能会受益于不同的结构,或者根据您的应用程序的特定需求需要更有创意的方法。因此,这个上下文-角色-任务框架不应限制您的思维,而应该是帮助您在适当时有效地设计提示的工具。
逐步思考
众所周知,GPT-4 不擅长计算。它无法计算 369 × 1,235:
prompt = "How much is 369 * 1235?"
chat_completion(prompt)
我们得到以下答案:454965
正确答案是 455,715。GPT-4 不能解决复杂的数学问题吗?请记住,模型通过预测答案中的每个标记来逐个顺序生成答案,从左边开始。这意味着 GPT-4 首先生成最左边的数字,然后将其作为上下文的一部分来生成下一个数字,依此类推,直到形成完整的答案。这里的挑战是每个数字都是独立于最终正确值的预测。GPT-4 将数字视为标记;没有数学逻辑。
注意
在第五章中,我们将探讨 OpenAI 如何通过插件丰富了 GPT-4。一个例子是用于提供准确数学解决方案的计算器插件。
有一个技巧可以增加语言模型的推理能力。例如,当要求解 369×1235 时,我们可以看到模型试图直接在一次尝试中回答。考虑到你可能也无法在没有铅笔和一张纸的帮助下解决这个乘法。可以通过提示来鼓励模型进行中间推理。就像你用铅笔和纸一样,如果给模型足够的时间来推理,它就可以解决更复杂的问题。
在提示的末尾添加“让我们一步一步地思考”已经被实验证明能够使模型解决更复杂的推理问题。这种技术被称为零射击 CoT 策略,它是由 Kojima 等人在 2022 年发表的科学论文“大型语言模型是零射击推理者”中介绍的。
CoT代表思维链;它在这里指的是使用鼓励模型模仿逐步推理的提示技术。术语零射击意味着模型不依赖于特定任务的示例来执行这种推理;它准备好根据其一般训练来处理新任务。与需要模型看到任务示例的少量学习等技术不同(我们将很快讨论),零射击学习试图在不需要特定任务示例的情况下进行泛化。
正如我们将看到的,通过将这个句子添加到提示中,模型开始通过将问题分解为子问题来进行推理。因此,它可能需要时间来推理,从而能够找到以前只能在一次尝试中无法解决的问题的解决方案。让我们看看如果我们改变我们的输入提示会发生什么:
prompt = "How much is 369 * 1235 ? Let's think step by step."
chat_completion(prompt)
我们得到了以下输出:
Step 1: Multiply 369 by 5 (the last digit of 1235).
369 * 5 = 1845
Step 2: Multiply 369 by 30 (the second last digit of 1235 is 3, so multiply by
3 and add a 0 at the end).
369 * 30 = 11070
Step 3: Multiply 369 by 200 (the third digit of 1235 is 2, so multiply by 2 and
add two 0s at the end).
369 * 200 = 73800
Step 4: Multiply 369 by 1000 (the first digit of 1235 is 1, so multiply by 1 and
add three 0s at the end).
369 * 1000 = 369000
Step 5: Add the results from steps 1 to 4.
1845 + 11070 + 73800 + 369000 = 455715
So, 369 * 1235 = 455,715.
模型的方法发生了显著的转变。它现在将主要问题分解为更小、更易管理的步骤,而不是试图直接解决问题。
警告
尽管提示模型“一步一步地思考”是至关重要的,但您仍然需要仔细评估其响应,因为 GPT-4 并非万无一失。对于像 3695×123548 这样更复杂的计算,即使使用这个技巧,LLM 也无法找到正确的解决方案。
当然,很难从一个例子中判断这个技巧是否普遍有效,或者我们只是幸运。在各种数学问题的基准测试中,实证实验证明这个技巧显著提高了 GPT 模型的准确性。尽管这个技巧对大多数数学问题都有效,但并不适用于所有情况。《大型语言模型是零射击推理者》的作者发现,它对多步算术问题、涉及符号推理的问题、涉及策略的问题以及其他涉及推理的问题最有益。它并不适用于常识问题。
实施少量学习
少样本学习,由 Brown 等人在《语言模型是少样本学习者》中介绍,指的是 LLM 仅凭少量示例就能概括和产生有价值的结果的能力。通过少样本学习,您可以给出您希望模型执行的任务的几个示例,如图 4-2 所示。这些示例指导模型处理所需的输出格式。

图 4-2。包含几个示例的提示
在这个例子中,我们要求 LLM 将特定单词转换为表情符号。很难想象要在提示中放入什么指令来执行这个任务。但是通过少样本学习,这很容易。给它一些示例,模型将自动尝试复制它们。
prompt="""I go home --> go my dog is sad --> my is I run fast --> run I love my wife --> my wifethe girl plays with the ball --> the with the The boy writes a letter to a girl --> """chat_completion(prompt)
从前面的例子中,我们得到以下消息作为输出:
The a to a
少样本学习技术提供了具有期望输出的输入示例。然后,在最后一行,我们提供了我们想要完成的提示。这个提示与之前的示例的形式相同。自然地,语言模型将根据给定示例的模式执行完成操作。
我们可以看到,仅凭几个示例,模型就可以复制指令。通过利用 LLM 在训练阶段获得的广泛知识,它们可以快速适应并根据仅有的几个示例生成准确的答案。
注意
少样本学习是 LLM 的一个强大方面,因为它使它们能够高度灵活和适应,只需要有限的额外信息就能执行各种任务。
当您在提示中提供示例时,确保上下文清晰和相关是至关重要的。清晰的示例可以提高模型匹配所需输出格式并执行解决问题的能力。相反,不充分或含糊的示例可能导致意外或不正确的结果。因此,仔细编写示例并确保它们传达正确的信息可以显著影响模型执行任务的准确性。
引导 LLM 的另一种方法是一样本学习。顾名思义,在这种情况下,您只提供一个示例来帮助模型执行任务。尽管这种方法提供的指导比少样本学习少,但对于更简单的任务或者 LLM 已经对主题有相当多的背景知识的情况下,它可能是有效的。一样本学习的优势在于简单、更快的提示生成以及更低的计算成本和因此更低的 API 成本。然而,对于复杂的任务或需要更深入理解期望结果的情况,少样本学习可能是更适合的方法,以确保准确的结果。
提示
提示工程已成为一个热门话题,您会发现许多在线资源来深入研究这个主题。例如,这个GitHub 存储库包含了由 70 多个不同用户贡献的有效提示列表。
虽然本节探讨了各种可以单独使用的提示工程技术,请注意您可以结合这些技术以获得更好的结果。作为开发人员,您的工作是找到特定问题的最有效提示。请记住,提示工程是一个反复试验的迭代过程。
提高提示效果
我们已经看到了几种提示工程技术,可以影响 GPT 模型的行为,以获得满足我们需求的更好结果。我们将以一些在编写 GPT 模型提示时可以在不同情况下使用的技巧和窍门结束本节。
指导模型提出更多问题
以询问模型是否理解问题并指示模型提出更多问题来结束提示是一种有效的技术,如果你正在构建基于聊天机器人的解决方案。你可以在提示的末尾添加这样的文本:
Did you understand my request clearly? If you do not fully understand my request,
ask me questions about the context so that when I answer, you can
perform the requested task more efficiently.
格式化输出
有时候你会希望在更长的过程中使用 LLM 输出:在这种情况下,输出格式很重要。例如,如果你想要 JSON 输出,模型往往会在 JSON 块之前和之后写入输出。如果你在提示中添加“输出必须被 json.loads 接受”,那么它往往会工作得更好。这种技巧可以在许多情况下使用。
例如,使用这个脚本:
prompt = """
Give a JSON output with 5 names of animals. The output must be accepted
by json.loads.
"""
chat_completion(prompt, model='gpt-4')
我们得到了以下的 JSON 代码块:
{
"animals": [
"lion",
"tiger",
"elephant",
"giraffe",
"zebra"
]
}
重复指令
经验表明,重复指令会产生良好的结果,特别是当提示很长时。思路是多次在提示中添加相同的指令,但每次都用不同的方式表达。
这也可以通过负面提示来实现。
使用负面提示
在文本生成的背景下使用负面提示是一种指导模型的方式,指定你不希望在输出中看到的内容。它们作为约束或指导,用于过滤出某些类型的响应。当任务复杂时,这种技术特别有用:当任务以不同方式多次重复时,模型往往更精确地遵循指令。
继续上一个例子,我们可以通过添加“不要在 json 之前或之后添加任何内容。”来坚持输出格式的负面提示。
在第三章中的第三个项目中,我们使用了负面提示:
Extract the keywords from the following question: {user_question}. Do not answer
anything else, only the keywords.
如果没有这个提示的补充,模型往往不会遵循指令。
添加长度约束
长度约束通常是一个好主意:如果你只期望得到一个单词的答案或 10 个句子,就把它添加到你的提示中。这就是我们在第三章中在第一个项目中所做的:我们指定了“长度:100 个单词”来生成一篇合适的新闻文章。在第四个项目中,我们的提示也有一个长度指令:“如果你可以回答问题:ANSWER,如果你需要更多信息:MORE,如果你无法回答:OTHER。只回答一个”“单词”。如果没有最后一句,模型会倾向于形成句子,而不是遵循指令。
微调
OpenAI 提供了许多现成的 GPT 模型。虽然这些模型在各种任务上表现出色,但对特定任务或情境进行微调可以进一步提高它们的性能。
入门
假设你想为你的公司创建一个电子邮件回复生成器。由于你的公司在特定行业中使用特定词汇,你希望生成的电子邮件回复保留你当前的写作风格。有两种策略可以做到这一点:要么你可以使用之前介绍的提示工程技术来强制模型输出你想要的文本,要么你可以对现有模型进行微调。本节探讨了第二种技术。
对于这个例子,你必须收集大量包含有关你特定业务领域的数据的电子邮件,客户的询问以及对这些询问的回复。然后,你可以使用这些数据对现有模型进行微调,以学习你公司特定的语言模式和词汇。微调后的模型本质上是从 OpenAI 提供的原始模型中构建的新模型,其中模型的内部权重被调整以适应你的特定问题,使得新模型在类似于它在微调数据集中看到的示例的任务上提高了准确性。通过微调现有的 LLM,可以创建一个高度定制和专门针对你特定业务中使用的语言模式和词汇的电子邮件回复生成器。
图 4-3 说明了微调过程,其中使用特定领域的数据集来更新现有 GPT 模型的内部权重。目标是使新的微调模型在特定领域比原始 GPT 模型做出更好的预测。应该强调的是这是一个新模型。这个新模型在 OpenAI 服务器上:与以前一样,您必须使用 OpenAI 的 API 来使用它,因为它无法在本地访问。

图 4-3。微调过程
注意
即使您使用自己的特定数据对 LLM 进行了微调,新模型仍然保留在 OpenAI 的服务器上。您将通过 OpenAI 的 API 与其进行交互,而不是在本地。
为特定领域的需求调整 GPT 基础模型
目前,微调仅适用于davinci、curie、babbage和ada基础模型。每个模型在准确性和所需资源之间都有一个权衡。作为开发者,您可以为您的应用程序选择最合适的模型:较小的模型,如ada和babbage,可能对于简单任务或资源有限的应用程序来说更快速和更具成本效益,而较大的模型curie和davinci提供了更先进的语言处理和生成能力,使它们成为更复杂任务的理想选择,其中更高的准确性至关重要。
这些是不属于 InstructGPT 模型系列的原始模型。例如,它们没有从人类在循环中进行强化学习阶段中受益。通过微调这些基础模型,例如根据自定义数据集调整其内部权重,您可以将它们定制为特定任务或领域。尽管它们没有 InstructGPT 系列的处理和推理能力,但它们通过利用其预训练的语言处理和生成能力为构建专门应用程序提供了坚实的基础。
注意
对于微调,您必须使用基础模型;不可能使用指导模型。
微调与少样本学习
微调是一种重新训练现有模型的过程,以改善其性能并使其答案更准确。在微调中,您更新模型的内部参数。正如我们之前所看到的,少样本学习通过其输入提示向模型提供有限数量的良好示例,从而引导模型基于这些少量示例产生期望的结果。通过少样本学习,模型的内部参数不会被修改。
微调和少样本学习都可以用来增强 GPT 模型。微调产生了一个高度专业化的模型,可以为特定任务提供更准确和上下文相关的结果。这使其成为在大量数据可用的情况下的理想选择。这种定制确保生成的内容更符合目标领域的特定语言模式、词汇和语气。
少样本学习是一种更灵活和数据高效的方法,因为它不需要重新训练模型。当只有有限的示例可用或需要快速适应不同任务时,这种技术是有益的。少样本学习允许开发者快速原型设计和尝试各种任务,使其成为许多用例的多功能和实用选择。选择两种方法之间的另一个重要标准是,使用和训练使用微调的模型更昂贵。
微调方法通常需要大量数据。可用示例的缺乏经常限制了这种类型技术的使用。为了让您了解微调所需的数据量,您可以假设对于相对简单的任务或仅需要进行轻微调整时,您可以通过几百个输入提示及其相应的期望完成示例来获得良好的微调结果。这种方法适用于预训练的 GPT 模型在任务上表现良好,但需要轻微调整以更好地与目标领域对齐的情况。然而,对于更复杂的任务或在您的应用程序需要更多定制的情况下,您的模型可能需要使用成千上万个示例进行训练。例如,这可以对应我们之前提出的用例,即自动回复符合您写作风格的电子邮件。您还可以针对非常专业的任务进行微调,这种情况下,您的模型可能需要数十万甚至数百万个示例。这种微调规模可以带来显著的性能改进,并更好地适应特定领域。
注意
迁移学习将从一个领域学到的知识应用到不同但相关的环境中。因此,您有时可能会听到与微调相关的迁移学习术语。
使用 OpenAI API 进行微调
本节将指导您如何使用 OpenAI API 调整 LLM 的过程。我们将解释如何准备您的数据,上传数据集,并使用 API 创建一个经过微调的模型。
准备您的数据
要更新 LLM 模型,需要提供一个包含示例的数据集。数据集应该是一个 JSONL 文件,其中每一行对应一个提示和完成的配对:
{"prompt": "<prompt text>", "completion": "<completion text>"}
{"prompt": "<prompt text>", "completion": "<completion text>"}
{"prompt": "<prompt text>", "completion": "<completion text>"}
…
JSONL 文件是一个文本文件,每行代表一个单独的 JSON 对象。您可以使用它来高效地存储大量数据。OpenAI 提供了一个工具,帮助您生成这个训练文件。该工具可以接受各种文件格式作为输入(CSV、TSV、XLSX、JSON 或 JSONL),只要它们包含提示和完成列/键,并且输出一个准备好发送进行微调过程的训练 JSONL 文件。该工具还会验证并提供建议,以改善您的数据质量。
在您的终端中使用以下代码行运行此工具:
$ openai tools fine_tunes.prepare_data -f <LOCAL_FILE>
该应用程序将提出一系列建议,以改善最终文件的结果;您可以接受或拒绝这些建议。您还可以指定选项-q,自动接受所有建议。
注意
当您执行pip install openai时,此openai工具已安装并在您的终端中可用。
如果您有足够的数据,该工具将询问是否有必要将数据分成训练集和验证集。这是一种推荐的做法。算法将使用训练数据在微调过程中修改模型的参数。验证集可以衡量模型在未用于更新参数的数据集上的性能。
对 LLM 进行微调有赖于使用高质量的示例,最好由专家审查。在使用预先存在的数据集进行微调时,确保数据经过筛查,排除冒犯性或不准确的内容,或者如果数据集太大无法手动审核所有条目,则检查随机样本。
使您的数据可用
一旦您准备好带有训练示例的数据集,您需要将其上传到 OpenAI 服务器。OpenAI API 提供了不同的功能来操作文件。以下是最重要的功能:
上传文件:
openai.File.create(
file=open("out_openai_completion_prepared.jsonl", "rb"),
purpose='fine-tune'
)
- 有两个必填参数:
file和purpose。将purpose设置为fine-tune。这将验证用于微调的下载文件格式。此函数的输出是一个字典,您可以从中检索id字段中的file_id。目前,总文件大小可达 1GB。如需更多,请联系 OpenAI。
删除文件:
openai.File.delete("file-z5mGg(...)")
- 一个参数是必需的:
file_id。
列出所有上传的文件:
openai.File.list()
- 例如,在开始微调过程时,检索文件的 ID 可能会有所帮助。
创建一个经过精细调整的模型
对上传的文件进行微调是一个简单的过程。端点openai.FineTune.create()在 OpenAI 服务器上创建一个作业,以从给定数据集中细化指定的模型。此函数的响应包含排队作业的详细信息,包括作业的状态、fine_tune_id和过程结束时模型的名称。
主要输入参数在表 4-1 中描述。
表 4-1。openai.FineTune.create()的参数
| 字段名称 | 类型 | 描述 |
|---|---|---|
training_file | 字符串 | 这是包含上传文件的file_id的唯一必填参数。您的数据集必须格式化为 JSONL 文件。每个训练示例都是一个具有prompt和completion键的 JSON 对象。 |
model | 字符串 | 这指定了用于微调的基础模型。您可以选择ada、babbage、curie、davinci或先前调整的模型。默认的基础模型是curie。 |
validation_file | 字符串 | 这包含具有验证数据的上传文件的file_id。如果提供此文件,数据将用于在微调过程中定期生成验证指标。 |
suffix | 字符串 | 这是一个最多 40 个字符的字符串,添加到您的自定义模型名称中。 |
列出微调作业
可以通过以下函数在 OpenAI 服务器上获取所有微调作业的列表:
openai.FineTune.list()
结果是一个包含所有精细调整模型信息的字典。
取消微调作业
可以通过以下函数立即中断在 OpenAI 服务器上运行的作业:
openai.FineTune.cancel()
此功能只有一个必填参数:fine_tune_id。fine_tune_id参数是一个以ft-开头的字符串;例如,ft-Re12otqdRaJ(...) 。它是在使用openai.FineTune.?cre?ate()函数创建作业后获得的。如果您丢失了fine_tune_id,可以使用openai.FineTune.list()来检索它。
微调应用
微调提供了一种强大的方式来增强各种应用程序中模型的性能。本节将介绍几种已经有效部署微调的用例。从这些例子中获得灵感!也许您在您的用例中有相同类型的问题。再次提醒,微调比基于提示工程的其他技术更昂贵,因此在大多数情况下并不是必需的。但是当需要时,这种技术可以显著改善您的结果。
法律文件分析
在这种情况下,LLM 用于处理法律文件并提取有价值的信息。这些文件通常使用特定行话编写,这使得非专业人士难以理解这些类型的文本。我们已经在第一章中看到,当在统一律师考试上进行测试时,GPT-4 的得分位于 90 分位数。在这种情况下,微调可以使模型专门针对特定领域和/或允许其协助非专业人士参与法律流程。通过在特定主题的法律语料库上对 LLM 进行微调,或者针对特定类型的最终用户,模型可以更好地处理法律语言的复杂性,并更擅长执行与特定类型最终用户相关的任务。
通过使用大量数据对 LLM 进行微调,以分析法律文件,可以显著提高模型在这些任务中的性能,使其能够更好地处理通常超出提示工程技术能力范围的法律语言的细微差别。
自动代码审查
在这种用例中,微调可以帮助模型分析并提出开发人员编写的代码的改进建议。这需要在包含代码片段和注释的数据集上训练模型,使模型能够处理特定语言的语法、语义和最佳实践。请注意,这个用例类似于 GitHub 的 Copilot 工具,该工具旨在通过实时提供代码和整个函数的建议来帮助开发人员编写代码。您可以使用微调来训练模型执行特定任务,如代码审查,并为自己的代码构建一个符合特定标准或专门用于特定编程框架的项目。
作为这种用例的输入文件的一个例子,您的 JSONL 文件可以包含代码和相应的审查评论对。这将帮助模型学习如何提供准确和相关的代码质量反馈。JSONL 文件的一行可能是这样的:
{"prompt": "Review the following Python code:
'def sum(a, b): return a + b\nresult = sum(5, '5')'",
"completion": "Type error: The 'sum' function is adding an integer and a string.
Consider converting the string to an integer using int() before passing it
to the function."}
财务文件摘要
在财务文件合成中,经过微调的 LLM 可以生成财务文件的简洁准确摘要,如收益报告、财务报表和分析报告。通过在与财务记录明确相关的数据集上微调语言模型,生成的模型可以更准确地理解这些文件的术语和上下文。例如,该模型可以将央行利率上调的详细报告压缩成简洁而富有信息的摘要。
要调整现有模型以获得更好的财务文件摘要,您需要已经有大量样本摘要。然后,您需要向模型提供一个包含财务文件及其理想摘要对的 JSONL 文件。例如:
{"prompt": "The central bank announced a 0.25% increase in the benchmark
interest rate, citing concerns about inflationary pressures. This move is
expected to affect borrowing costs for consumers and businesses.",
"completion": "Bank increases rate 0.25% for inflation worry. May affect people,
business borrowing costs."}
技术文件翻译
使用微调来翻译技术文件可以显著提高基础模型的性能,与少量样本学习相比。主要原因是技术文件通常包含专业词汇和复杂的句子结构,少量样本学习无法有效处理。基础模型是未经调整的 GPT-3 模型,如 InstructGPT-3 模型,使用强化学习和人类反馈技术。要使用它们,需要进行微调。要调整现有的基础模型,您需要准备一个包含训练数据的 JSONL 文件。对于技术文件翻译的用例,该文件的内容将包括将技术文本翻译成目标语言的内容。
针对利基主题的新闻文章生成
在这种用例中,经过微调的模型可以为高度专业化的主题生成高质量、引人入胜和与上下文相关的新闻文章,这些主题基础模型可能没有足够的数据来准确生成。与所有其他用例一样,您需要创建一个训练数据集,以使您的模型专门用于撰写文章。为此,您需要准备许多关于特定利基主题的文章。这些数据将用于创建包含提示-完成对的 JSONL 文件。以下是一个小例子:
{"prompt": "Write an introductory article about a new environmentally friendly
cryptocurrency: 'EcoCoin: The Green Cryptocurrency Taking
the Market by Storm'",
"completion": "As concerns over the environmental impact of cryptocurrency
mining (...) mining process and commitment to sustainability."}
为电子邮件营销活动生成和微调合成数据
在这个例子中,我们将为电子邮件营销机构制作一个文本生成工具,利用定向内容为企业创建个性化的电子邮件营销活动。这些电子邮件旨在吸引受众并推广产品或服务。
假设我们的机构有一个支付处理行业的客户,他们要求帮助他们运行直接电子邮件营销活动,为电子商务提供新的支付服务。电子邮件营销机构决定为这个项目使用微调技术。我们的电子邮件营销机构将需要大量数据来进行微调。
在我们的情况下,我们需要为演示目的合成生成数据,正如您将在下一小节中看到的。通常,最好的结果是使用人类专家的数据,但在某些情况下,合成数据生成可能是一个有用的解决方案。
创建合成数据集
在以下示例中,我们从 GPT-3.5 Turbo 创建人工数据。为此,我们将在提示中指定要将促销句子发送给特定商家以销售电子商务服务。商家的特征是活动领域、商店所在城市和商店的大小。我们通过将提示发送到之前定义的chat_completion函数中的 GPT-3.5 Turbo 来获得促销句子。
我们通过定义三个列表来开始我们的脚本,分别对应于商店类型、商店所在的城市和商店的大小:
l_sector = ['Grocery Stores', 'Restaurants', 'Fast Food Restaurants',
'Pharmacies', 'Service Stations (Fuel)', 'Electronics Stores']
l_city = ['Brussels', 'Paris', 'Berlin']
l_size = ['small', 'medium', 'large']
然后我们在一个字符串中定义第一个提示。在此提示中,角色、上下文和任务都很明确,因为它们是使用本章前面描述的提示工程技术构建的。在此字符串中,大括号中的三个值将在代码中稍后替换为相应的值。这个第一个提示用于生成合成数据:
f_prompt = """
Role: You are an expert content writer with extensive direct marketing
experience. You have strong writing skills, creativity, adaptability to
different tones and styles, and a deep understanding of audience needs and
preferences for effective direct campaigns.
Context: You have to write a short message in no more than 2 sentences for a
direct marketing campaign to sell a new e-commerce payment service to stores.
The target stores have the following three characteristics:
- The sector of activity: {sector} `- The city where the stores are located:` `{city}`
`- The size of the stores:` `{size}` ``Task: Write a short message for the direct marketing campaign. Use the skills`
`defined in your role to write this message! It is important that the message`
`you create takes into account the product you are selling and the`
`characteristics of the store you are writing to.`
`"""``
以下提示仅包含三个变量的值,用逗号分隔。它不用于创建合成数据;仅用于微调:
f_sub_prompt = "{sector}, {city}, {size}"
然后是代码的主要部分,它迭代我们之前定义的三个值列表。我们可以看到循环中的代码块很简单。我们用两个提示的大括号中的值替换为适当的值。变量prompt与函数chat_completion一起使用,以生成保存在response_txt中的广告。然后将sub_prompt和response_txt变量添加到out_openai_completion.csv文件中,这是我们微调的训练集。
df = pd.DataFrame()
for sector in l_sector:
for city in l_city:
for size in l_size:
for i in range(3): ## 3 times each
prompt = f_prompt.format(sector=sector, city=city, size=size)
sub_prompt = f_sub_prompt.format(
sector=sector, city=city, size=size
)
response_txt = chat_completion(
prompt, model="gpt-3.5-turbo", temperature=1
)
new_row = {"prompt": sub_prompt, "completion": response_txt}
new_row = pd.DataFrame([new_row])
df = pd.concat([df, new_row], axis=0, ignore_index=True)
df.to_csv("out_openai_completion.csv", index=False)
请注意,对于每种特征组合,我们生成三个示例。为了最大化模型的创造力,我们将温度设置为1。在此脚本结束时,我们有一个存储在out_openai_completion.csv文件中的 Pandas 表。它包含 162 个观察结果,其中有两列包含提示和相应的完成。这个文件的前两行如下:
"Grocery Stores, Brussels, small",Introducing our new e-commerce payment service -
the perfect solution for small Brussels-based grocery stores to easily and
securely process online transactions. "Grocery Stores, Brussels, small",
Looking for a hassle-free payment solution for your small grocery store in
Brussels? Our new e-commerce payment service is here to simplify your
transactions and increase your revenue. Try it now!
现在我们可以调用工具从out_openai_completion.csv生成训练文件,如下所示:
$ openai tools fine_tunes.prepare_data -f out_openai_completion.csv
正如您在以下代码行中所看到的,这个工具提出了改进我们提示-完成对的建议。在文本的结尾,它甚至提供了如何继续微调过程以及在微调过程完成后如何使用模型进行预测的建议。
Analyzing...
- Based on your file extension, your file is formatted as a CSV file
- Your file contains 162 prompt-completion pairs
- Your data does not contain a common separator at the end of your prompts.
Having a separator string appended to the end of the prompt makes it clearer
to the fine-tuned model where the completion should begin. See
https://platform.openai.com/docs/guides/fine-tuning/preparing-your-dataset
for more detail and examples. If you intend to do open-ended generation,
then you should leave the prompts empty
- Your data does not contain a common ending at the end of your completions.
Having a common ending string appended to the end of the completion makes it
clearer to the fine-tuned model where the completion should end. See
https://oreil.ly/MOff7 for more detail and examples.
- The completion should start with a whitespace character (` `). This tends to
produce better results due to the tokenization we use. See
https://oreil.ly/MOff7 for more details
Based on the analysis we will perform the following actions:
- [Necessary] Your format `CSV` will be converted to `JSONL`
- [Recommended] Add a suffix separator ` ->` to all prompts [Y/n]: Y
- [Recommended] Add a suffix ending `\n` to all completions [Y/n]: Y
- [Recommended] Add a whitespace character to the beginning of the completion
[Y/n]: Y
Your data will be written to a new JSONL file. Proceed [Y/n]: Y
Wrote modified file to `out_openai_completion_prepared.jsonl`
Feel free to take a look!
Now use that file when fine-tuning:
> openai api fine_tunes.create -t "out_openai_completion_prepared.jsonl"
After you’ve fine-tuned a model, remember that your prompt has to end with the
indicator string ` ->` for the model to start generating completions, rather
than continuing with the prompt. Make sure to include `stop=["\n"]` so that the
generated texts ends at the expected place.
Once your model starts training, it'll approximately take 4.67 minutes to train
a `curie` model, and less for `ada` and `babbage`. Queue will approximately
take half an hour per job ahead of you.
在此过程结束时,将会有一个名为out_openai_completion_prepared.jsonl的新文件可供使用,并准备好发送到 OpenAI 服务器以运行微调过程。
请注意,如函数消息中所解释的,提示已被修改,末尾添加了字符串->,并且所有完成都添加了以\n结尾的后缀。### 使用合成数据集微调模型
以下代码上传文件并进行微调。在此示例中,我们将使用davinci作为基础模型,生成的模型名称将以direct_marketing作为后缀:
ft_file = openai.File.create(
file=open("out_openai_completion_prepared.jsonl", "rb"), purpose="fine-tune"
)
openai.FineTune.create(
training_file=ft_file["id"], model="davinci", suffix="direct_marketing"
)
这将启动davinci模型的更新过程,使用我们的数据。这个微调过程可能需要一些时间,但完成后,您将拥有一个适合您任务的新模型。微调所需的时间主要取决于数据集中的示例数量、示例中的标记数量以及您选择的基础模型。为了让您了解微调所需的时间,我们的示例中不到五分钟就完成了。但是,我们也看到一些情况下微调需要超过 30 分钟:
$ openai api fine_tunes.create -t out_openai_completion_prepared.jsonl \
-m davinci --suffix "direct_marketing"
Upload progress: 100%|| 40.8k/40.8k [00:00<00:00, 65.5Mit/s]
Uploaded file from out_openai_completion_prepared.jsonl: file-z5mGg(...)
Created fine-tune: ft-mMsm(...)
Streaming events until fine-tuning is complete...
(Ctrl-C will interrupt the stream, but not cancel the fine-tune)
[] Created fine-tune: ft-mMsm(...)
[] Fine-tune costs $0.84
[] Fine-tune enqueued. Queue number: 0
[] Fine-tune started
[] Completed epoch 1/4
[] Completed epoch 2/4
[] Completed epoch 3/4
[] Completed epoch 4/4
警告
正如终端中的消息所解释的那样,您可以通过在命令行中键入 Ctrl+C 来断开与 OpenAI 服务器的连接,但这不会中断微调过程。
要重新连接到服务器并获取正在运行的微调作业的状态,可以使用以下命令fine_tunes.follow,其中fine_tune_id是微调作业的 ID:
$ openai api fine_tunes.follow -i ***fine_tune_id***
当您创建工作时,会得到此 ID。在我们之前的示例中,我们的fine_tune_id是ft-mMsm(...) 。如果您丢失了fine_tune_id,可以通过以下方式显示所有模型:
$ openai api fine_tunes.list
要立即取消微调作业,请使用此命令:
$ openai api fine_tunes.cancel -i ***fine_tune_id***
要删除微调作业,请使用此命令:
$ openai api fine_tunes.delete -i ***fine_tune_id***
使用微调模型进行文本完成
构建新模型后,可以通过不同的方式访问它以进行新的完成。测试它的最简单方法可能是通过游乐场。要在此工具中访问您的模型,可以在游乐场界面右侧的下拉菜单中搜索它们(请参见图 4-4)。所有您微调的模型都在此列表的底部。选择模型后,可以使用它进行预测。

图 4-4。在游乐场中使用微调模型
我们在以下示例中使用了微调的 LLM,输入提示为Hotel, New York, small ->。没有进一步的说明,模型自动生成了一则广告,以出售纽约的小型酒店的电子商务支付服务。
我们已经使用了一个仅包含 162 个示例的小数据集获得了出色的结果。对于微调任务,通常建议有几百个实例,最好是几千个。此外,我们的训练集是通过合成生成的,理想情况下应该由营销专家编写。
要将其与 OpenAI API 一起使用,我们按照以前的方式进行,使用openai.Completion.?cre?ate(),只是需要使用我们的新模型的名称作为输入参数。不要忘记以->结束所有提示,并将\n设置为停用词:
openai.Completion.create(
model="davinci:ft-book:direct-marketing-2023-05-01-15-20-35",
prompt="Hotel, New York, small ->",
max_tokens=100,
temperature=0,
stop="\n"
)
我们得到了以下答案:
<OpenAIObject text_completion id=cmpl-7BTkrdo(...) at 0x7f2(4ca5c220> JSON: {
"choices": [
{
"finish_reason": "stop",
"index": 0,
"logprobs": null,
"text": " \"Upgrade your hotel's payment system with our new e-commerce \
service, designed for small businesses.
}
],
"created": 1682970309,
"id": "cmpl-7BTkrdo(...)",
"model": "davinci:ft-book:direct-marketing-2023-05-01-15-20-35",
"object": "text_completion",
"usage": {
"completion_tokens": 37,
"prompt_tokens": 8,
"total_tokens": 45
}
}
正如我们所展示的,微调可以使 Python 开发人员根据其独特的业务需求定制 LLM,特别是在我们的电子邮件营销示例等动态领域。这是一种定制语言模型的强大方法,可以帮助您更好地为客户服务并推动业务增长。 ##微调成本
使用微调模型是昂贵的。首先,您必须为培训付费,一旦模型准备就绪,每次预测都会比使用 OpenAI 提供的基本模型多一点。
价格可能会有所变化,但在撰写本文时,看起来像是表 4-2。
表 4-2。撰写本书时微调模型的定价
| 模型 | 培训 | 用法 |
|---|---|---|
ada | 每 1,000 个标记 0.0004 美元 | 每 1,000 个标记 0.0016 美元 |
babbage | 每 1,000 个标记 0.0006 美元 | 每 1,000 个标记 0.0024 美元 |
curie | 每 1,000 个标记 0.0030 美元 | 每 1,000 个标记 0.0120 美元 |
davinci | 每 1,000 个标记 0.0300 美元 | 每 1,000 个标记 0.1200 美元 |
作为比较,gpt-3.5-turbo模型的价格为每 1,000 个标记 0.002 美元。如前所述,gpt-3.5-turbo具有最佳的性价比。
要获取最新价格,请访问OpenAI 定价页面。 #摘要
本章讨论了解锁 GPT-4 和 ChatGPT 的全部潜力的高级技术,并提供了关键的可操作的要点,以改进使用 LLM 开发应用程序。
开发人员可以通过了解 prompt 工程、零-shot 学习、few-shot 学习和微调来创建更有效和有针对性的应用程序。我们探讨了如何通过考虑上下文、任务和角色来创建有效的提示,从而实现与模型更精确的交互。通过逐步推理,开发人员可以鼓励模型更有效地推理和处理复杂任务。此外,我们讨论了 few-shot 学习提供的灵活性和适应性,突出了其数据高效的特性和快速适应不同任务的能力。
表 4-3 提供了所有这些技术的快速摘要,何时使用它们以及它们的比较。
表 4-3。不同技术的比较
| 零-shot 学习 | few-shot 学习 | prompt 工程技巧 | 微调 | |
|---|---|---|---|---|
| 定义 | 预测没有先前示例的未见任务 | 提示包括输入和期望的输出示例 | 可包括上下文、角色和任务的详细提示,或者“逐步思考”等技巧 | 模型在更小、更具体的数据集上进一步训练;使用的提示很简单 |
| 用例 | 简单任务 | 定义明确但复杂的任务,通常具有特定的输出格式 | 创造性、复杂的任务 | 高度复杂的任务 |
| 数据 | 不需要额外的示例数据 | 需要一些示例 | 数据量取决于 prompt 工程技术 | 需要大型训练数据集 |
| 定价 | 使用:每个令牌(输入+输出)的定价 | 使用:每个令牌(输入+输出)的定价;可能导致长提示 | 使用:每个令牌(输入+输出)的定价,可能导致长提示 | 训练:使用:每个令牌(输入+输出)的定价,与 GPT-3.5 Turbo 相比,fine-tuned davinci大约贵 80 倍。这意味着如果其他技术导致提示长度增加 80 倍,经济上更倾向于进行微调。 |
| 结论 | 默认使用 | 如果零-shot 学习不起作用,因为输出需要特定的话,使用 few-shot 学习。 | 如果零-shot 学习不起作用,因为任务太复杂,尝试 prompt 工程。 | 如果您有一个非常具体和大型的数据集,其他解决方案效果不够好,这应该作为最后的手段。 |
为了确保构建 LLM 应用程序的成功,开发人员应该尝试其他技术,并评估模型的响应是否准确和相关。此外,开发人员应该意识到 LLM 的计算限制,并相应地调整他们的提示以获得更好的结果。通过整合这些先进技术并不断完善他们的方法,开发人员可以创建功能强大和创新的应用程序,释放 GPT-4 和 ChatGPT 的真正潜力。
在下一章中,您将发现将 LLM 功能集成到您的应用程序中的另外两种方法:插件和 LangChain 框架。这些工具使开发人员能够创建创新的应用程序,访问最新信息,并简化集成 LLM 的应用程序的开发。我们还将提供关于 LLM 未来及其对应用程序开发的影响的见解。
第五章:通过 LangChain 框架和插件提升 LLM 功能
本章探讨了 LangChain 框架和 GPT-4 插件的世界。我们将看看 LangChain 如何实现与不同语言模型的交互,以及插件在扩展 GPT-4 功能方面的重要性。这些高级知识将对依赖 LLM 的复杂、尖端应用程序的开发至关重要。
LangChain 框架
LangChain 是一个专门用于开发 LLM 驱动应用程序的新框架。您会发现,集成 LangChain 的代码比第三章中提供的示例更加优雅。该框架还提供了许多额外的可能性。
使用pip install langchain可以快速轻松地安装 LangChain。
警告
在撰写本文时,LangChain 仍处于 beta 版本 0.0.2XX,几乎每天都会发布新版本。功能可能会发生变化,因此我们建议在使用该框架时谨慎操作。
LangChain 的关键功能被分为模块,如图 5-1 所示。
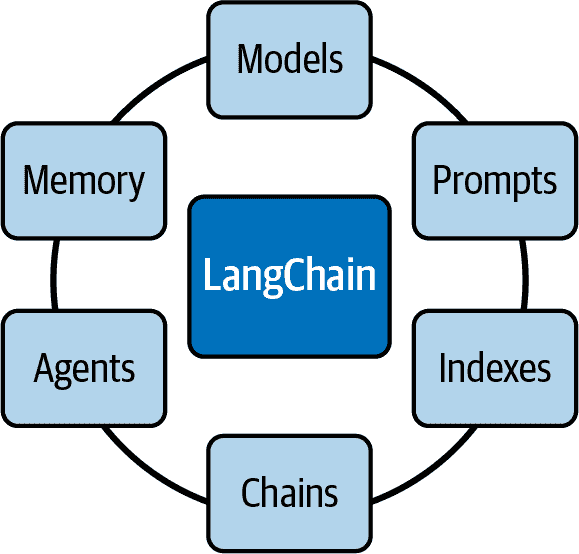
图 5-1。LangChain 模块
以下是这些模块的简要描述:
模型
模型模块是 LangChain 提供的标准接口,通过它可以与各种 LLM 进行交互。该框架支持来自各种提供商的不同模型类型集成,包括 OpenAI、Hugging Face、Cohere、GPT4All 等。
提示
提示正在成为编程 LLM 的新标准。提示模块包括许多用于提示管理的工具。
索引
该模块允许您将 LLM 与您的数据结合起来。
链
通过这个模块,LangChain 提供了链接口,允许您创建一个调用序列,结合多个模型或提示。
代理
代理模块介绍了代理接口。代理是一个可以处理用户输入、做出决策并选择适当工具来完成任务的组件。它是迭代工作的,采取行动直到达到解决方案。
内存
内存模块允许您在链或代理调用之间保持状态。默认情况下,链和代理是无状态的,这意味着它们独立处理每个传入请求,就像 LLM 一样。
LangChain 是不同 LLM 的通用接口;您可以在其文档页面上查看所有的集成。OpenAI 和许多其他 LLM 提供商都在这个集成列表中。这些集成大多需要它们的 API 密钥来建立连接。对于 OpenAI 模型,您可以像我们在第二章中看到的那样进行设置,将密钥设置在OPENAI_API_KEY环境变量中。
动态提示
展示 LangChain 工作原理的最简单方法是向您呈现一个简单的脚本。在这个例子中,使用 OpenAI 和 LangChain 来完成一个简单的文本补全:
from langchain.chat_models import ChatOpenAI
from langchain import PromptTemplate, LLMChain
template = """Question: {question} `Let's think step by step.`
`Answer: """`
`prompt` `=` `PromptTemplate``(``template``=``template``,` `input_variables``=``[``"question"``])`
`llm` `=` `ChatOpenAI``(``model_name``=``"gpt-4"``)`
`llm_chain` `=` `LLMChain``(``prompt``=``prompt``,` `llm``=``llm``)`
`question` `=` `""" What is the population of the capital of the country where the`
`Olympic Games were held in 2016? """`
`llm_chain``.``run``(``question``)`
输出如下:
Step 1: Identify the country where the Olympic Games were held in 2016.
Answer: The 2016 Olympic Games were held in Brazil.
Step 2: Identify the capital of Brazil.
Answer: The capital of Brazil is Brasília.
Step 3: Find the population of Brasília.
Answer: As of 2021, the estimated population of Brasília is around 3.1 million.
So, the population of the capital of the country where the Olympic Games were
held in 2016 is around 3.1 million. Note that this is an estimate and may
vary slightly.'
PromptTemplate负责构建模型的输入。因此,它是生成提示的可重复方式。它包含一个称为模板的输入文本字符串,其中的值可以通过input_variables指定。在我们的示例中,我们定义的提示自动将“让我们逐步思考”部分添加到问题中。
本例中使用的 LLM 是 GPT-4;目前,默认模型是gpt-3.5-turbo。该模型通过ChatOpenAI()函数放置在变量llm中。该函数假定 OpenAI API 密钥设置在环境变量OPENAI_API_KEY中,就像在前几章的示例中一样。
函数LLMChain()将提示和模型组合在一起,形成一个包含这两个元素的链。最后,我们需要调用run()函数来请求使用输入问题完成。当执行run()函数时,LLMChain使用提供的输入键值(如果可用,还使用内存键值)格式化提示模板,将格式化的字符串传递给 LLM,最后返回 LLM 输出。我们可以看到,模型通过应用“让我们一步一步地思考”规则自动回答问题。
正如您所看到的,动态提示是复杂应用和更好的提示管理的一个简单但非常有价值的功能。## 代理和工具
代理和工具是 LangChain 框架的关键功能:它们可以使您的应用程序变得非常强大。它们使您能够通过使 LLMs 执行操作并与各种功能集成来解决复杂问题。
工具是围绕一个函数的特定抽象,使语言模型更容易与之交互。代理可以使用工具与世界进行交互。具体而言,工具的接口具有单个文本输入和单个文本输出。LangChain 中有许多预定义的工具。这些工具包括 Google 搜索、维基百科搜索、Python REPL、计算器、世界天气预报 API 等。要获取完整的工具列表,请查看 LangChain 提供的工具页面的文档。您还可以构建自定义工具并将其加载到您正在使用的代理中:这使得代理非常灵活和强大。
正如我们在第四章中所学到的,“让我们一步一步地思考”在提示中,可以在某种程度上增加模型的推理能力。将这个句子添加到提示中,要求模型花更多时间来回答问题。
在本节中,我们介绍了一个适用于需要一系列中间步骤的应用程序的代理。代理安排这些步骤,并可以访问各种工具,决定使用哪个工具以有效地回答用户的查询。在某种程度上,就像“让我们一步一步地思考”一样,代理将有更多的时间来规划其行动,从而能够完成更复杂的任务。
代理的高级伪代码如下:
-
代理从用户那里接收一些输入。
-
代理决定使用什么工具(如果有的话)以及输入到该工具的文本。
-
然后,该工具使用该输入文本进行调用,并从该工具接收一个输出文本。
-
工具的输出被馈送到代理的上下文中。
-
步骤 2 到 4 重复进行,直到代理决定不再需要使用工具,然后直接回应用户。
您可能会注意到,这似乎接近我们在第三章中所做的事情,例如可以回答问题并执行操作的个人助理的示例。LangChain 代理允许您开发这种行为……但更加强大。
为了更好地说明代理如何在 LangChain 中使用工具,图 5-2 提供了对交互的视觉演示。
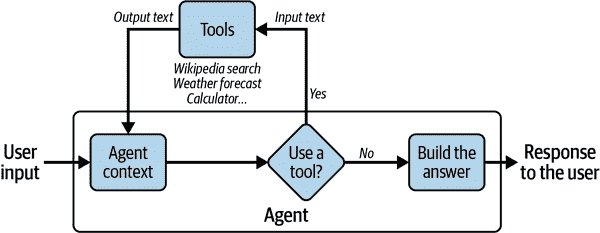
图 5-2. LangChain 中代理和工具的交互
对于这一部分,我们希望能够回答以下问题:2016 年奥运会举办国家的首都人口的平方根是多少?这个问题并没有真正的兴趣,但它很好地演示了 LangChain 代理和工具如何为 LLMs 增加推理能力。
如果我们直接向 GPT-3.5 Turbo 提出这个问题,我们会得到以下回答:
The capital of the country where the Olympic Games were held in 2016 is Rio de
Janeiro, Brazil. The population of Rio de Janeiro is approximately 6.32 million
people as of 2021\. Taking the square root of this population, we get
approximately 2,513.29\. Therefore, the square root of the population of
the capital of the country where the Olympic Games were held in 2016 is
approximately 2,513.29.
这个答案在两个层面上是错误的:巴西的首都是巴西利亚,而不是里约热内卢,632 万的平方根是 2513.96。通过添加“逐步思考”或使用其他提示工程技术,我们可能能够获得更好的结果,但由于模型在推理和数学运算方面的困难,仍然很难相信结果。使用 LangChain 可以更好地保证准确性。
以下代码给出了一个简单的例子,说明了代理如何在 LangChain 中使用两个工具:维基百科和计算器。在通过load_tools()函数创建工具之后,使用initialize_agent()函数创建代理。代理的推理需要 LLM;在这里,使用了 GPT-3.5 Turbo。参数zero-shot-react-description定义了代理在每一步选择工具的方式。通过将verbose值设置为true,我们可以查看代理的推理,并理解它是如何得出最终决定的:
from langchain.chat_models import ChatOpenAI
from langchain.agents import load_tools, initialize_agent, AgentType
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
tools = load_tools(["wikipedia", "llm-math"], llm=llm)
agent = initialize_agent(
tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True
)
question = """What is the square root of the population of the capital of the
Country where the Olympic Games were held in 2016?"""
agent.run(question)
注意
要运行维基百科工具,需要安装相应的 Python 包wikipedia。可以使用pip install wikipedia来完成。
正如你所看到的,代理决定查询维基百科关于 2016 年夏季奥运会的信息:
> Entering new chain...
I need to find the country where the Olympic Games were held in 2016 and then find
the population of its capital city. Then I can take the square root of that population.
Action: Wikipedia
Action Input: "2016 Summer Olympics"
Observation: Page: 2016 Summer Olympics
[...]
输出的下几行包含了维基百科关于奥运会的摘录。接下来,代理使用了维基百科工具两次:
Thought:I need to search for the capital city of Brazil.
Action: Wikipedia
Action Input: "Capital of Brazil"
Observation: Page: Capitals of Brazil
Summary: The current capital of Brazil, since its construction in 1960, is
Brasilia. [...]
Thought: I have found the capital city of Brazil, which is Brasilia. Now I need
to find the population of Brasilia.
Action: Wikipedia
Action Input: "Population of Brasilia"
Observation: Page: Brasilia
[...]
作为下一步,代理使用了计算器工具:
Thought: I have found the population of Brasilia, but I need to calculate the
square root of that population.
Action: Calculator
Action Input: Square root of the population of Brasilia (population: found in
previous observation)
Observation: Answer: 1587.051038876822
最后:
Thought:I now know the final answer
Final Answer: The square root of the population of the capital of the country
where the Olympic Games were held in 2016 is approximately 1587.
> Finished chain.
正如你所看到的,代理展示了复杂的推理能力:在得出最终答案之前,它完成了四个不同的步骤。LangChain 框架允许开发人员只需几行代码就能实现这种推理能力。
提示
虽然可以使用多个 LLM 作为代理,而 GPT-4 是其中最昂贵的,但我们经验上发现对于复杂问题,使用 GPT-4 可以获得更好的结果;我们观察到当使用较小的模型进行代理推理时,结果可能很快变得不一致。您可能还会因为模型无法以预期格式回答而收到错误。
记忆
在某些应用中,记住以前的交互在短期和长期内都是至关重要的。使用 LangChain,您可以轻松地向链和代理添加状态以管理记忆。构建聊天机器人是这种能力最常见的例子。您可以使用ConversationChain很快地完成这个过程,基本上只需几行代码就可以将语言模型转化为聊天工具。
以下代码使用text-ada-001模型制作了一个聊天机器人。这是一个能够执行基本任务的小型模型。然而,它是 GPT-3 系列中最快的模型,成本最低。这个模型从未被微调成为聊天机器人,但我们可以看到,只需两行代码,我们就可以使用 LangChain 来使用这个简单的完成模型进行聊天:
from langchain import OpenAI, ConversationChain
chatbot_llm = OpenAI(model_name='text-ada-001')
chatbot = ConversationChain(llm=chatbot_llm , verbose=True)
chatbot.predict(input='Hello')
在上述代码的最后一行,我们执行了predict(input='Hello')。这导致聊天机器人被要求回复我们的Hello消息。正如你所看到的,模型的回答是:
> Entering new ConversationChain chain...
Prompt after formatting:
The following is a friendly conversation between a human and an AI. The AI is
talkative and provides lots of specific details from its context. If the AI
does not know the answer to a question, it truthfully says it does not know.
Current conversation:
Human: Hello
AI:
> Finished chain.
' Hello! How can I help you?'
由于在ConversationChain中使用了verbose=True,我们可以查看 LangChain 使用的完整提示。当我们执行predict(input='Hello')时,LLMtext-ada-001接收到的不仅仅是'Hello'消息,而是一个完整的提示,位于> Entering new ConversationChain chain…和> Finished chain标签之间。
如果我们继续对话,你会发现这个函数会在提示中保留对话历史。如果我们问“我可以问你一个问题吗?你是人工智能吗?”对话的历史也会出现在提示中:
> Entering new ConversationChain chain...
Prompt after formatting:
The following [...] does not know.
Current conversation:
Human: Hello
AI: Hello! How can I help you?
Human: Can I ask you a question? Are you an AI?
AI:
> Finished chain.
'\n\nYes, I am an AI.'
ConversationChain对象使用提示工程技术和记忆技术,将任何进行文本完成的 LLM 转化为聊天工具。
警告
即使这个 LangChain 功能允许所有语言模型具有聊天功能,但这个解决方案并不像gpt-3.5-turbo和gpt-4这样强大,后者已经专门针对聊天进行了优化。此外,OpenAI 已宣布废弃text-ada-001。
嵌入
将语言模型与您自己的文本数据相结合是个性化应用程序中使用的模型知识的强大方式。其原理与第三章中讨论的相同:第一步是信息检索,指的是获取用户的查询并返回最相关的文档。然后将文档发送到模型的输入上下文中,要求其回答查询。本节展示了如何使用 LangChain 和嵌入来轻松实现这一点。
LangChain 中一个重要的模块是document_loaders。使用这个模块,您可以快速将文本数据从不同的来源加载到您的应用程序中。例如,您的应用程序可以加载 CSV 文件、电子邮件、PowerPoint 文档、Evernote 笔记、Facebook 聊天、HTML 页面、PDF 文档以及许多其他格式。完整的加载器列表可在官方文档中找到。每个加载器都非常容易设置。本示例重用了探险者指南:塞尔达传说:荒野之息的 PDF。
如果 PDF 文件在当前工作目录中,以下代码加载其内容并按页面进行划分:
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader("ExplorersGuide.pdf")
pages = loader.load_and_split()
注意
要使用 PDF 加载程序,需要安装 Python 的pypdf包。可以使用pip install pypdf来完成。
要进行信息检索,需要嵌入每个加载的页面。正如我们在第二章中讨论的那样,嵌入是信息检索中使用的一种技术,用于将非数值概念(如单词、标记和句子)转换为数值向量。嵌入使模型能够有效地处理这些概念之间的关系。使用 OpenAI 的嵌入端点,开发人员可以获得输入文本的数值向量表示,而 LangChain 有一个包装器来调用这些嵌入:
from langchain.embeddings import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
注意
要使用OpenAIEmbeddings,请使用pip install tiktoken安装tiktoken Python 包。
索引保存页面的嵌入并使搜索变得容易。LangChain 以向量数据库为中心。可以在许多向量数据库中进行选择;完整的列表可在官方文档中找到。以下代码片段使用了FAISS 向量数据库,这是 Meta 的基础 AI 研究小组主要开发的相似性搜索库:
from langchain.vectorstores import FAISS
db = FAISS.from_documents(pages, embeddings)
注意
要使用 FAISS,需要使用pip install faiss-cpu安装faiss-cpu Python 包。
为了更好地说明 PDF 文档的内容是如何转换为嵌入页面并存储在 FAISS 向量数据库中的,图 5-3 以可视化方式总结了这个过程。

图 5-3. 从 PDF 文档创建和保存嵌入
现在可以轻松搜索相似之处了:
q = "What is Link's traditional outfit color?"
db.similarity_search(q)[0]
从前面的代码中,我们得到以下内容:
Document(page_content='While Link’s traditional green `tunic` `is` `certainly` `an` `iconic` `look``,` `his`
`wardrobe` `has` `expanded` `[``...``]` `Dress` `for` `Success``',` ``metadata``=``{``'source'``:` `'ExplorersGuide.pdf'``,` `'page'``:` `35``})``
``问题的答案是林克的传统服装颜色是绿色,我们可以看到答案在所选内容中。输出显示答案在ExplorersGuide.pdf的第 35 页。请记住,Python 从零开始计数;因此,如果返回到探险者指南:塞尔达传说:荒野之息的原始 PDF 文件,解决方案在第 36 页(而不是第 35 页)。
图 5-4 显示了信息检索过程如何使用查询的嵌入和向量数据库来识别与查询最相似的页面。

图 5-4。信息检索寻找与查询最相似的页面
您可能希望将您的嵌入式信息集成到您的聊天机器人中,以便在回答您的问题时使用它检索到的信息。同样,在 LangChain 中,这只需要几行代码就可以轻松完成。我们使用RetrievalQA,它以 LLM 和向量数据库作为输入。然后我们以通常的方式向获得的对象提问:
from langchain.chains import RetrievalQA
from langchain import OpenAI
llm = OpenAI()
chain = RetrievalQA.from_llm(llm=llm, retriever=db.as_retriever())
q = "What is Link's traditional outfit color?"
chain(q, return_only_outputs=True)
我们得到了以下答案:
{'result': " Link's traditional outfit color is green."}
图 5-5 展示了RetrievalQA如何使用信息检索来回答用户的问题。正如我们在这个图中看到的,“创建上下文”将信息检索系统找到的页面和用户的初始查询组合在一起。然后将这个丰富的上下文发送给语言模型,语言模型可以使用上下文中添加的额外信息来正确回答用户的问题。

图 5-5。为了回答用户的问题,检索到的信息被添加到 LLM 的上下文中
您可能会想知道为什么在将信息从文档发送到语言模型的上下文之前需要进行信息检索。事实上,当前的语言模型无法考虑到具有数百页的大文件。因此,如果输入数据太大,我们会对其进行预过滤。这就是信息检索过程的任务。在不久的将来,随着输入上下文的增加,可能会出现一些情况,使用信息检索技术可能不是技术上必要的。
GPT-4 插件
虽然语言模型,包括 GPT-4,在各种任务中都证明了其帮助性,但它们也存在固有的局限性。例如,这些模型只能从它们所训练的数据中学习,这些数据通常已经过时或不适用于特定的应用。此外,它们的能力仅限于文本生成。我们也看到 LLMs 无法完成一些任务,比如复杂的计算。
本节重点介绍了 GPT-4 的一个突破性功能:插件(请注意,GPT-3.5 模型无法访问插件功能)。在 AI 的发展过程中,插件已经成为一种重新定义与 LLMs 交互的新型变革工具。插件的目标是为 LLM 提供更广泛的功能,使模型能够访问实时信息,执行复杂的数学计算,并利用第三方服务。
我们在第一章](ch01.html#gpt_4_and_chatgpt_essentials)中看到,该模型无法执行复杂的计算,比如 3,695 × 123,548。在[图 5-6 中,我们激活了计算器插件,我们可以看到当模型需要进行计算时,模型会自动调用计算器,从而使其找到正确的解决方案。
通过迭代部署方法,OpenAI 逐步向 GPT-4 添加插件,这使 OpenAI 能够考虑插件的实际用途以及可能引入的安全性和定制化挑战。虽然自 2023 年 5 月以来,所有付费用户都可以使用插件,但在撰写本文时,尚未为所有开发人员提供创建新插件的功能。

图 5-6。GPT-4 使用计算器插件
OpenAI 的目标是创建一个生态系统,插件可以帮助塑造人工智能与人类互动的未来动态。今天,一家严肃的企业没有自己的网站是不可想象的,但也许很快,每家公司都需要有自己的插件。事实上,一些早期的插件已经由 Expedia、FiscalNote、Instacart、KAYAK、Klarna、Milo、OpenTable、Shopify 和 Zapier 等公司推出。
除了其主要功能外,插件还以多种方式扩展了 GPT-4 的功能。在某种程度上,插件与“LangChain 框架”中讨论的代理和工具存在一些相似之处。例如,插件可以使 LLM 检索实时信息,如体育比分和股票价格,从知识库中提取数据,如公司文件,并根据用户的需求执行任务,如预订航班或订餐。两者都旨在帮助 AI 访问最新信息并进行计算。然而,GPT-4 中的插件更专注于第三方服务,而不是 LangChain 的工具。
本节通过探索 OpenAI 网站上提供的示例的关键点,介绍了创建插件的基本概念。我们将以待办事项定义插件的示例为例。插件仍处于有限的测试版阶段,因此我们在撰写本书时鼓励读者访问OpenAI 参考页面获取最新信息。还要注意,在测试版阶段,用户必须在 ChatGPT 的用户界面中手动启用他们的插件,作为开发者,您最多可以与 100 名用户分享您的插件。
概述
作为插件开发者,您必须创建一个 API,并将其与两个描述性文件关联起来:一个插件清单和一个 OpenAPI 规范。当用户开始与 GPT-4 进行交互时,如果安装了您的插件,OpenAI 会向 GPT 发送一个隐藏的消息。这条消息简要介绍了您的插件,包括其描述、端点和示例。
然后,模型变成了一个智能的 API 调用者。当用户询问有关您的插件的问题时,模型可以调用您的插件 API。调用插件的决定是基于 API 规范和自然语言描述您的 API 应该在何种情况下使用。一旦模型决定调用您的插件,它会将 API 结果合并到其上下文中,以向用户提供响应。因此,插件的 API 响应必须返回原始数据,而不是自然语言响应。这使得 GPT 可以根据返回的数据生成自己的自然语言响应。
例如,如果用户问“我应该在纽约住在哪里?”,模型可以使用酒店预订插件,然后将插件的 API 响应与其语言生成能力结合起来,提供既信息丰富又用户友好的答案。
API
以下是在OpenAI 的 GitHub上提供的待办事项定义插件的简化代码示例:
import json
import quart
import quart_cors
from quart import request
app = quart_cors.cors(
quart.Quart(__name__), allow_origin="https://chat.openai.com"
)
# Keep track of todo's. Does not persist if Python session is restarted.
_TODOS = {}
@app.post("/todos/<string:username>")
async def add_todo(username):
request = await quart.request.get_json(force=True)
if username not in _TODOS:
_TODOS[username] = []
_TODOS[username].append(request["todo"])
return quart.Response(response="OK", status=200)
@app.get("/todos/<string:username>")
async def get_todos(username):
return quart.Response(
response=json.dumps(_TODOS.get(username, [])), status=200
)
@app.get("/.well-known/ai-plugin.json")
async def plugin_manifest():
host = request.headers["Host"]
with open("./.well-known/ai-plugin.json") as f:
text = f.read()
return quart.Response(text, mimetype="text/json")
@app.get("/openapi.yaml")
async def openapi_spec():
host = request.headers["Host"]
with open("openapi.yaml") as f:
text = f.read()
return quart.Response(text, mimetype="text/yaml")
def main():
app.run(debug=True, host="0.0.0.0", port=5003)
if __name__ == "__main__":
main()
这段 Python 代码是一个管理待办事项列表的简单插件的示例。首先,变量app使用quart_cors.cors()进行初始化。这行代码创建了一个新的 Quart 应用程序,并配置它以允许来自https://chat.openai.com的跨域资源共享(CORS)。Quart 是一个 Python Web 微框架,Quart-CORS 是一个允许对 CORS 进行控制的扩展。这个设置允许插件与指定 URL 上托管的 ChatGPT 应用程序进行交互。
然后,代码定义了几个 HTTP 路由,对应于待办事项插件的不同功能:add_todo函数,关联一个POST请求,以及get_todos函数,关联一个GET请求。
接下来,定义了两个额外的端点:plugin_manifest和openapi_spec。这些端点提供了插件的清单文件和 OpenAPI 规范,这对于 GPT-4 和插件之间的交互至关重要。这些文件包含了关于插件及其 API 的详细信息,GPT-4 使用这些信息来了解何时以及如何使用插件。
插件清单
每个插件都需要在 API 的域上有一个 ai-plugin.json 文件。例如,如果您的公司在 thecompany.com 上提供服务,您必须在 https://thecompany.com/.well-known 上托管此文件。在安装插件时,OpenAI 将在 /.well-known/ai-plugin.json 中查找此文件。没有这个文件,插件就无法安装。
以下是所需的 ai-plugin.json 文件的最小定义:
{
"schema_version": "v1",
"name_for_human": "TODO Plugin",
"name_for_model": "todo",
"description_for_human": "Plugin for managing a TODO list. \
You can add, remove and view your TODOs.",
"description_for_model": "Plugin for managing a TODO list. \
You can add, remove and view your TODOs.",
"auth": {
"type": "none"
},
"api": {
"type": "openapi",
"url": "http://localhost:3333/openapi.yaml",
"is_user_authenticated": false
},
"logo_url": "http://localhost:3333/logo.png",
"contact_email": "support@thecompany.com",
"legal_info_url": "http://www.thecompany.com/legal"
}
字段在 表 5-1 中详细说明。
表 5-1. ai-plugin.json 文件 中所需字段的描述
| 字段名称 | 类型 | 描述 |
|---|---|---|
name_for_model | String | 模型用于了解您的插件的简称。它只能包含字母和数字,且不得超过 50 个字符。 |
name_for_human | String | 人们看到的名称。它可以是您公司的全名,但必须少于 20 个字符。 |
description_for_human | String | 您的插件功能的简单解释。供人们阅读,应少于 100 个字符。 |
description_for_model | String | 详细的解释,帮助 AI 理解您的插件。因此,向模型解释插件的目的至关重要。描述可以长达 8,000 个字符。 |
logo_url | String | 您的插件标志的 URL。标志理想情况下应为 512 × 512 像素。 |
contact_email | String | 人们可以使用的电子邮件地址,如果他们需要帮助。 |
legal_info_url | String | 一个网址,让用户找到有关您的插件的更多详细信息。 |
OpenAPI 规范
创建插件的下一步是使用 API 规范创建 openapi.yaml 文件。此文件必须遵循 OpenAPI 标准(参见 “理解 OpenAPI 规范”)。GPT 模型只通过此 API 规范文件和清单文件中详细的信息来了解您的 API。
以下是待办事项清单定义插件的 openapi.yaml 文件的第一行的示例:
openapi: 3.0.1
info:
title: TODO Plugin
description: A plugin that allows the user to create and manage a TODO list
using ChatGPT. If you do not know the user's username, ask them first before
making queries to the plugin. Otherwise, use the username "global".
version: 'v1'
servers:
- url: http://localhost:5003
paths:
/todos/{username}:
get:
operationId: getTodos
summary: Get the list of todos
parameters:
- in: path
name: username
schema:
type: string
required: true
description: The name of the user.
responses:
"200":
description: OK
content:
application/json:
schema:
$ref: '#/components/schemas/getTodosResponse'
[...]
将 OpenAPI 规范视为足够自身理解和使用您的 API 的描述性文档。在 GPT-4 中进行搜索时,信息部分中的描述用于确定插件与用户搜索的相关性。其余的 OpenAPI 规范遵循标准的 OpenAPI 格式。许多工具可以根据您现有的 API 代码或反之自动生成 OpenAPI 规范。
描述
当用户的请求可能受益于插件时,模型会启动对 OpenAPI 规范中的端点描述以及清单文件中的 description_for_model 属性的扫描。您的目标是创建最合适的响应,这通常涉及测试不同的请求和描述。
OpenAPI 文档应提供有关 API 的广泛信息,例如可用函数及其各自的参数。它还应包含特定于属性的“描述”字段,提供有价值的、自然书写的解释,说明每个函数的作用以及查询字段期望的信息类型。这些描述指导模型最合适地使用 API。
这个过程中的一个关键元素是 description_for_model 属性。这为您提供了一种方式来告知模型如何使用插件。创建简洁、清晰和描述性的说明是非常推荐的。
然而,在编写这些描述时遵循某些最佳实践是必不可少的:
-
不要试图影响 GPT 的情绪、个性或确切的响应。
-
避免指示 GPT 使用特定的插件,除非用户明确请求该类别的服务。
-
不要指定 GPT 使用插件的特定触发器,因为它被设计为自主确定何时使用插件是合适的。
简而言之,开发 GPT-4 插件涉及创建 API,指定其在 OpenAPI 规范中的行为,并在清单文件中描述插件及其用法。通过这种设置,GPT-4 可以有效地充当智能 API 调用者,扩展其能力超越文本生成。
总结
LangChain 框架和 GPT-4 插件代表了最大程度发挥 LLM 潜力的重大进步。
LangChain 凭借其强大的工具和模块套件,已成为 LLM 领域的中心框架。它在集成不同模型、管理提示、组合数据、排序链、处理代理和使用内存管理方面的多功能性为开发人员和人工智能爱好者打开了新的途径。第三章中的示例证明了使用 ChatGPT 和 GPT-4 模型从头开始编写复杂指令的限制。请记住,LangChain 的真正潜力在于创造性地利用这些功能来解决复杂任务,并将通用语言模型转化为功能强大、细粒度的应用程序。
GPT-4 插件是语言模型和实时可用的上下文信息之间的桥梁。本章表明,开发插件需要一个结构良好的 API 和描述性文件。因此,在这些文件中提供详细和自然的描述是必不可少的。这将帮助 GPT-4 充分利用您的 API。
LangChain 和 GPT-4 插件的激动人心世界证明了人工智能和 LLM 领域迅速发展的景象。本章提供的见解只是这些工具变革潜力的一小部分。
结论
本书为您提供了利用 LLM 的力量并将其应用于现实世界应用所需的基础和高级知识。我们涵盖了从基本原理和 API 集成到高级提示工程和微调的一切,引导您朝着使用 OpenAI 的 GPT-4 和 ChatGPT 模型的实际用例。我们以详细介绍 LangChain 框架和插件如何使您能够释放 LLM 的力量并构建真正创新的应用程序来结束了本书。
现在,您拥有了工具,可以在 AI 领域进一步开拓,开发利用这些先进语言模型的强大应用程序。但请记住,AI 领域不断发展,因此必须密切关注进展并相应地进行调整。这次进入 LLM 世界的旅程只是开始,您的探索不应该止步于此。我们鼓励您利用新知识探索人工智能技术的未来。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 银行数据仓库体系实践(3)--数据架构
- 二分查找--二分查找算法(朴素二分模板)
- JS字符串方法
- 出现频率高达70%软件测试面试题及答案!——看完面试官:是你面试我还是我面试你啊!
- 设置5台SSH互免的虚拟机服务器配置
- 大数据开发之Hive(查询、分区表和分桶表、函数)
- MTP和MPO电缆之间的区别及其使用方法
- 数组对象,名字相同的对象进行合并
- 从“单打独斗”到“同舟共集”,集群如何成为项目研发、IT和老板的最佳拍档?
- WordPress回收站自动清空时间?如何关闭回收站或设置自动清理天数?