多模态推荐系统综述:三、多模态特征增强
三、多模态特征增强
同一对象的不同模态表示具有独特且共同的语义信息。如果能够区分独特特征和共同特征,那么MRS的推荐性能和泛化能力可以得到显着提高。解耦表征学习(DRL)和对比学习(CL)被用来进行基于交互的特征增强。
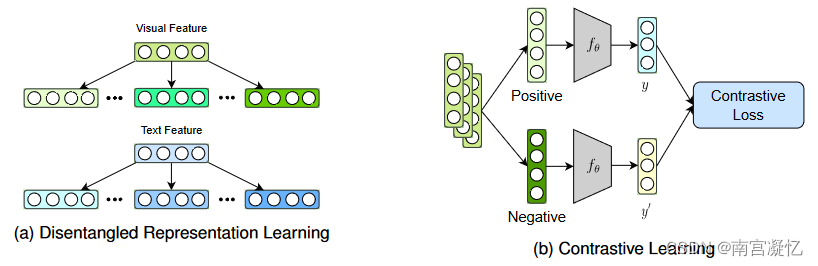
3.1 解耦表征学习DRL
不同模态特征对于用户对项目的特定因素的偏好具有不同的重要性。然而,每种模态中不同因素的表示往往是纠缠在一起的,因此许多研究人员引入分解学习技术来挖掘用户偏好中的细致因素。例如 DICER、MacridVAE、CDR。
DICER: Content-Collaborative Disentanglement Representation Learning for Enhanced Recommendation 2020
从这些协作和基于内容的视角得到的未发现的用户偏好表示可能会由于相互影响而相互纠缠,从而导致次优性能和不稳定的推荐。因此,我们建议从用户行为数据和内容信息中分离表示。具体地说,我们提出了一种新的两级分解生成推荐模型(DICER),该模型支持内容协同分解和特征分解:
对于内容协同分解,DICER根据内容和用户项交互的边际分布对特征进行分解,以确保每种类型的学习特征在统计上是独立的。
对于特征分离,通过对Kullback-Leibler散度的分解,我们从理论上证明了每种类型中提取的特征在粒度级别上是分离的。
此外,DICER利用同时解码内容和用户项交互的联合解码器来确保学习特征的高质量。
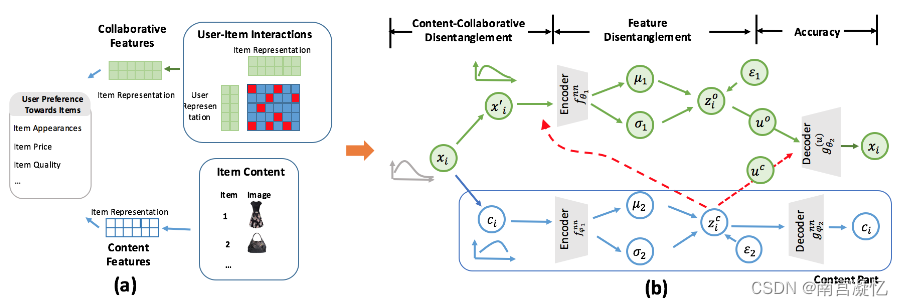
(a)从用户项交互学习的协作特征和从内容信息(如图像)学习的内容特征都可以用于发现用户偏好。
(b)DICER首先将用户隐含反馈xi分解为内容信息ci和内容分解后的协作信息x′i。然后在每种类型(协作或内容)中,我们进一步在粒度级别(特征分离)分离学习的特征,以提高用户和项目表示的能力。
MacridVAE: Learning Disentangled Representations for Recommendation 2019
推荐系统中的用户行为数据是由用户决策过程背后诸多潜在因素的复杂交互驱动的。这些因素是高度纠缠的,并且可以从控制用户意图的高级因素到表征用户在执行意图时的偏好的低级因素。学习表征,发现和理清这些潜在的因素可以带来增强的鲁棒性,可解释性和可控性。然而,从用户行为中学习这些分离的表示是一个挑战,并且在很大程度上被现有文献所忽视。
我们提出宏-微分离变分自动编码器(MacridVAE)来学习基于用户行为的分离表示。我们的方法明确地模拟了宏观和微观因素的分离,并在每个层次上进行分离。通过识别与用户意图相关联的高层概念,并分别学习用户对不同概念的偏好,实现宏观解纠缠。然后,从信息论的角度解释VAEs[27,44]得到的微观解纠缠正则化子得到加强,以迫使每个单独的维度反映一个独立的微观因素。提出了一种波束搜索策略,该策略通过寻找平滑的轨迹来处理稀疏离散观测值和密集连续表示之间的冲突,以研究每个孤立维度的可解释性。
通过学习一组原型,推断出与每个项目相关的用户意图,然后分别捕获用户对不同意图的偏好,实现宏观解纠缠。
通过放大KL散度实现微观解纠缠,从KL散度中可以分离出惩罚总相关性的项,因子为β。
多模态推荐是从复杂的、高度纠缠的多模态数据中发现各种隐藏因素形成的有用信息。
MDR: MULTIMODAL DISENTANGLED REPRESENTATION FOR RECOMMENDATION 2021
MDR提出一个多模态解纠缠推荐能够很好地从不同模态中学习携带互补和标准信息的解纠缠表示。
发现多模态数据中各种隐藏因素形成的有用信息对于提高模型性能和推荐解释性具有重要意义。这些隐藏在多模态数据中的因素以一种复杂的方式高度纠缠,在推荐的表示学习过程中暴露它们的纠缠是一个巨大的挑战。然而,现有的文献只关注单峰数据,没有揭示多峰数据中复杂和纠缠的因素。
本文首次研究了弱监督下的多模态解纠缠推荐问题。提出了一种多模态解纠缠推荐(MDR)模型,该模型能够很好地从不同的模式中学习包含互补信息和公共信息的解纠缠表示,从而提高推荐的准确性和表示的可解释性。
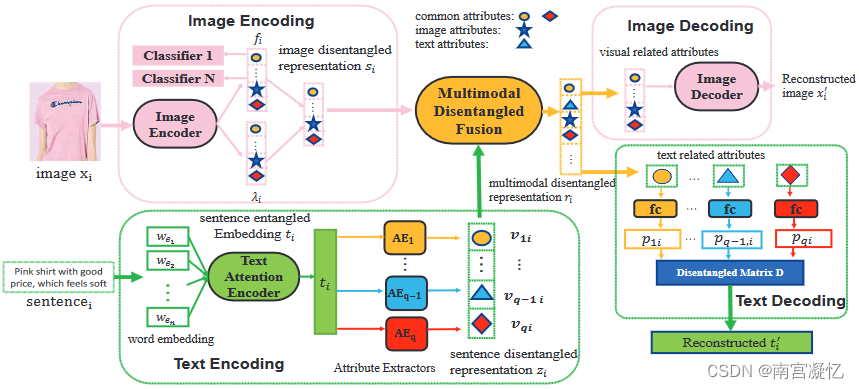
更具体地说,我们采用定制的编码、融合和解码结构以及专门设计的解纠缠方法来获得多模态解纠缠表示。在编码过程中,输入的图像和文本分别用特定的编码器编码成单峰表示。然后对得到的单峰表示进行解纠缠融合,得到多峰表示。
在解码过程中,利用重构损失来保持足够的输入信息,最小化因子间的互信息来保证解纠缠,引入弱监督来进一步提高表示的可解释性。我们利用正则化的信息约束来保证所学习的多模态解纠缠表示的可解释性。
DMRL:Disentangled Multimodal Representation Learning for Recommendation 2022
DMRL考虑了不同模态特征对每个解纠缠因子的不同贡献,以捕获用户偏好。
许多多模态推荐系统被提出来利用与用户或项目(如用户评论和项目图像)相关的丰富边信息来学习更好的用户和项目表示以提高推荐性能。心理学研究表明,用户在组织信息的方式上存在个体差异。因此,对于项目的特定因素(例如外观或质量),不同模式的特征对用户具有不同的重要性。然而,现有的方法忽略了这样一个事实,即不同的模式对用户对项目的各种因素的偏好有不同的贡献。
鉴于此,本文提出了一种新的非纠缠多模态表示学习(DMRL)推荐模型,该模型能够捕获用户对用户偏好建模中各个因素上不同模态的注意。特别地,我们采用了一种非纠缠表示技术,以确保每个模态中不同因素的特征是相互独立的。然后设计一个多模态注意机制来捕获用户对每个因素的模态偏好。根据注意机制得到的估计权重,结合不同模式下用户对目标项目各因素的偏好得分,提出推荐。
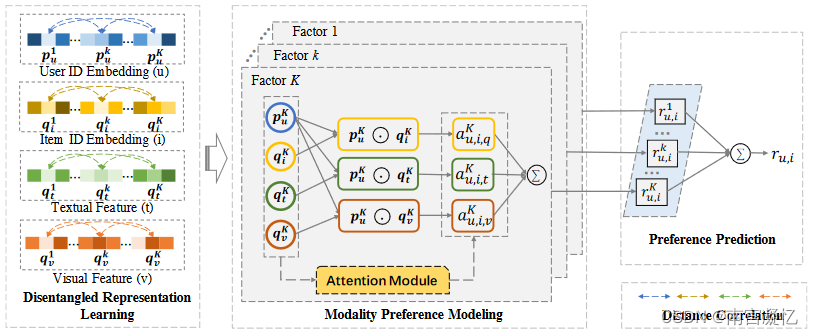
在我们的模型中,用户对一个项目的偏好是通过聚合她对不同因素的所有模态特征的加权偏好来预测的。为了使每个因素具有鲁棒性和独立的表示,我们采用了一种分离表示技术,以确保每个模态中不同因素的特征是相互独立的。
基于不同因素的分离表示,我们设计了一种多模态注意机制来捕捉用户对不同因素的模态偏好。
最后,对于偏好预测,在给定用户和目标项目的情况下,首先估计用户对每个模态中每个因子的偏好得分,然后利用注意机制得到的估计权重将不同模态中所有因子的得分线性组合。为此,该模型基于多模态表示的分离因子,结合用户的个人模态偏好,对用户的个人模态偏好进行分析。
PAMD: Modality Matches Modality: Pretraining Modality-Disentangled Item Representations for Recommendation 2022
PAMD设计了一种分离编码器,在自动保留其模态特征的同时提取其模态共同特征。此外,对比学习保证了分离模态表征之间的一致性和差异性。
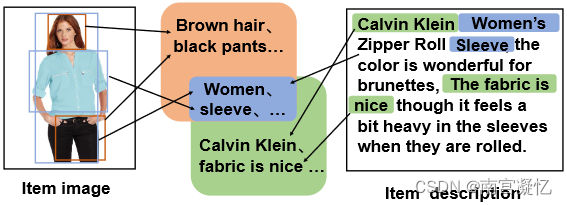
通过实例说明了推荐场景中的模态对齐问题。蓝色背景中的特征是对齐的模态特征,橙色和绿色背景中的特征分别是项目图像和描述的模态特征。
最近的研究表明,结合文本和视觉信息可以有效地解决推荐场景中的稀疏性问题。为了融合这些有用的异构模态信息,对齐这些信息是模态鲁棒特征学习和语义理解的必要前提。然而,现有的研究主要集中在解决跨模式的知识学习问题,而忽略了每个模式的具体特征,这必然会降低推荐性能。为此,我们提出了一个预训练框架PAMD,即预训练模态分离表示模型。
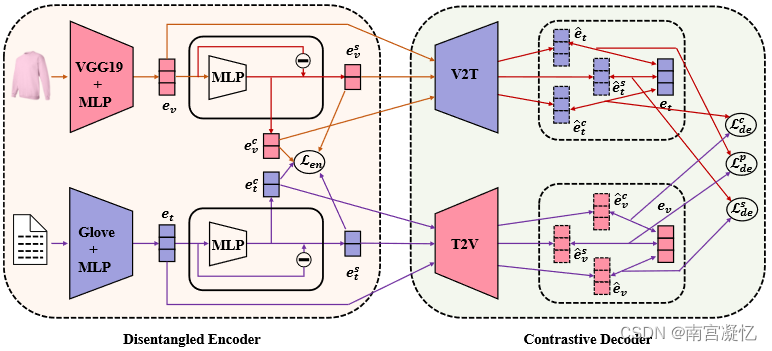
PAMD包含两个部分:一个分离编码器将多模态信息分解为模态公共特征和模态特定特征,另一个具有自监督目标的对比学习以保证这些分解特征之间的精确对齐和分离。
具体地说,考虑到与项目相关的视觉和文本模态,PAMD利用现成的VGG19和Glove分别将模态嵌入到连续嵌入空间中。基于这些原始的异构表示,PAMD首先将它们输入一个分离的编码器,其中每个模态数据被分解为两个表示:一个模态公共表示,跨模态共享语义;一个模态特定表示,包含该模态通道中的独特特征。
在此基础上,进一步设计了对比学习,以确保这些分解表示之间的精确对齐和分离。由于自监督训练的优点,我们的PAMD可以在没有监督信号的情况下自动学习模态分离项表示,并且被证明比现有的最新的推荐模型更有效。
SEM-MacridVAE: Disentangled Representation Learning for Recommendation. 2023
与MacridVAE相比,SEM-MacridVAE在学习用户行为的分离表示时考虑了项目语义信息。
在不同个体的决策过程背后,存在着大量的潜在因素之间的复杂交互作用,这些因素驱动着推荐系统中不同的用户行为模式。这些隐藏在这些不同行为中的因素表现出高度纠缠的模式,从高层次的用户意图到低层次的个人偏好。揭示这些潜在因素的分离有助于增强推荐过程中的鲁棒性、可解释性和可控性。
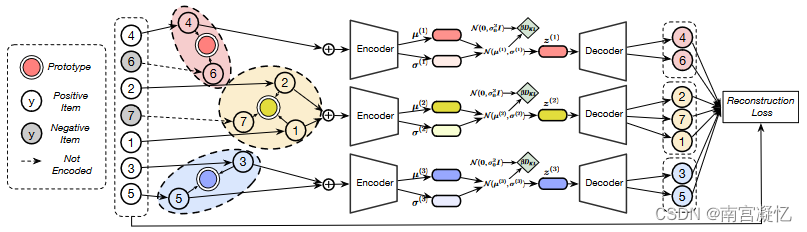
本文提出了一种考虑项目语义信息的宏微观解耦变分自动编码器(SEM-MacridVAE)模型,用于从用户行为中学习解耦表示。我们的SEM-MacridVAE模型通过原型路由机制推断与用户意图(例如,购买一双鞋或一台笔记本电脑)相关的高级概念,以及分别捕获不同概念的个人偏好,从而实现宏观解纠缠。通过源自VAEs的信息论解释的微解纠缠正则化子来保证微解纠缠,该正则化子迫使表示的每个维度独立地反映孤立的低水平因子(例如衬衫的尺寸或颜色)。利用从候选项中提取的包含视觉和分类信号的语义信息,进一步提高了SEM-MacridVAE模型的推荐性能。实验结果表明,我们提出的方法能够实现显著改善的国家最先进的基线。我们还表明,学习的表示是可解释和可控的,有可能导致一个新的范例推荐,其中用户有细粒度控制的一些目标方面的推荐候选人。
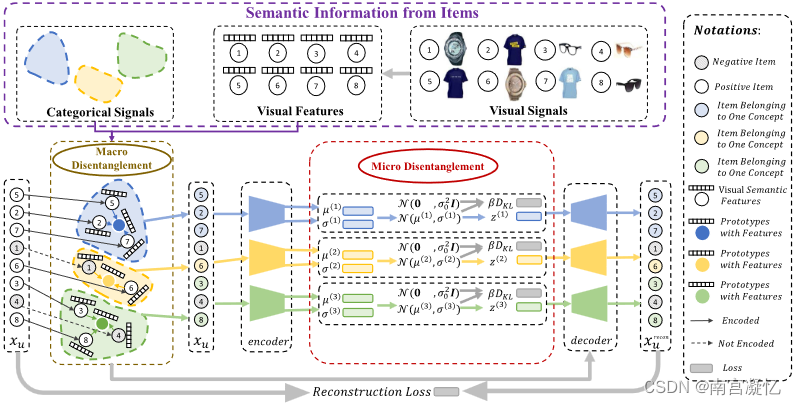
我们提出的SEM-MacridVAE模型的整体框架。通过学习一组原型(宏概念)来实现宏解纠缠,并在此基础上推断出与每个项目相关的用户意图。图中不同的颜色(蓝色、黄色和绿色)表示不同的宏概念,其中每个宏概念(一种颜色)有一个独立的原型、编码器和解码器(颜色相同)。
通过分别捕获目标用户对不同意图的偏好,通过放大KL散度来保证微观分离,其中惩罚总相关性的术语可以用因子b分离。利用从候选项中提取的包含类别和视觉信号的语义信息来进一步提高模型性能。特别地,视觉信号被用来初始化项目因子和原型表示,分类信号被用来监督宏观概念C的学习。
3.2 对比学习
与 DRL 不同,对比学习方法通过数据增强来增强表示,这也有助于处理稀疏问题。CL损失函数主要用于模态对齐和增强正负样本之间的深层特征信息。
MCPTR: Multi-Modal Contrastive Pre-training for Recommendation 2022
MCPTR提出了一种新的CL损失,使得同一项目的不同模态表示具有语义相似性。
对预训练好的多模态嵌入进行微调,建立了现有的推荐模型。如图所示,除了描述文本、图像和评论文本之外,我们还基于交互关系构造了两个同质图。
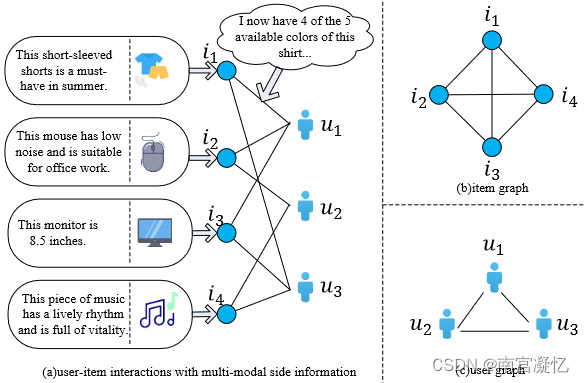
因此,在本文中,我们考虑两种用户模式:评论文本和用户图,三种项目模式:描述文本、图像和项目图。我们分别使用文本编码器、图像编码器和图形编码器来获得每个模态的表示。对于用户,我们提出了模态内聚合和模态间聚合来融合多个模态。模态内融合的目的是融合多个评论文本,模态间融合的目的是获得多模态用户表示。对于项目,我们还应用跨模态聚合来获得多模态项目表示。
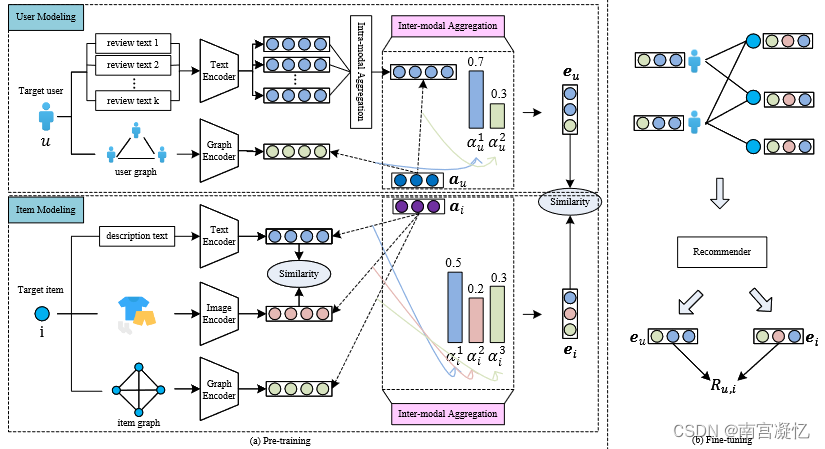
此外,描述文本和图像对于同一项目也是相辅相成的。其中一个可以作为另一个有希望的监督。以上图为例,每个项目的描述是从文本模特的角度表现出来的,图像是从视觉模态的角度表现出来的。这两种模态的语义是相似的。为了有效地捕获这一信号,我们提出了一种自监督对比学习方法,该方法将项目的文本和视觉模式对齐。 在获得用户和项目的多模态表示之后,我们使用二元交叉熵损失函数来捕获它们之间的潜在相关性。
GHMFC: Multimodal Entity Linking with Gated Hierarchical Fusion and Contrastive Training 2022
GHMFC基于图神经网络的实体嵌入表示构造了两个对比学习模块。两个CL损失函数在两个方向上,即文本到图像和图像到文本。
以往知识图中的实体链接方法大多将文本引用链接到相应的实体。然而,当文本太短而无法提供足够的上下文时,它们在处理大量多模态数据方面存在不足。因此,我们设想引入其他模态的有价值信息,并提出了一种基于门控层次多模态融合和对比训练的多模态实体连接方法(GHMFC)。
首先,为了发现细粒度的模态间相关性,GHMFC通过多模态共同注意机制(文本引导的视觉注意和视觉引导的文本注意)提取文本和视觉共同注意的层次特征。前者在文本信息的引导下获得加权的视觉特征。相反,后者在视觉信息的引导下产生加权的文本特征。
然后,利用门控融合方法评估不同模态层次特征的重要性,并将其集成到提及的最终多模态表示中。随后,设计了两种对比损失的对比训练,以学习更多的通用多模态特征并降低噪声。最后,通过计算KGs中引用和实体表示之间的余弦相似度来选择链接实体。
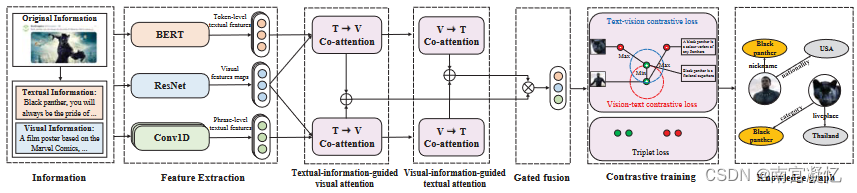
Cross-CBR: Cross-view Contrastive Learning for Bundle Recommendation 2022
Cross-CBR提出了一个CL损失,以从捆绑视图和项目视图对齐图形表示。
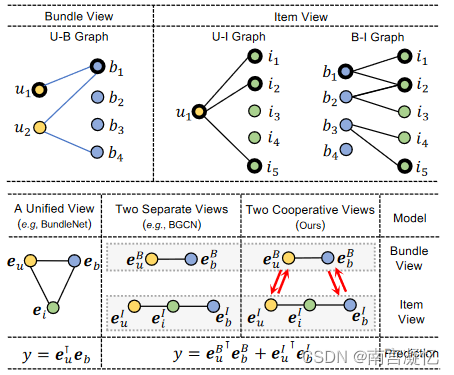
提出了一种简单而有效的束推荐器CrossCBR,通过跨视图对比学习对两个视图之间的协同关联进行建模。
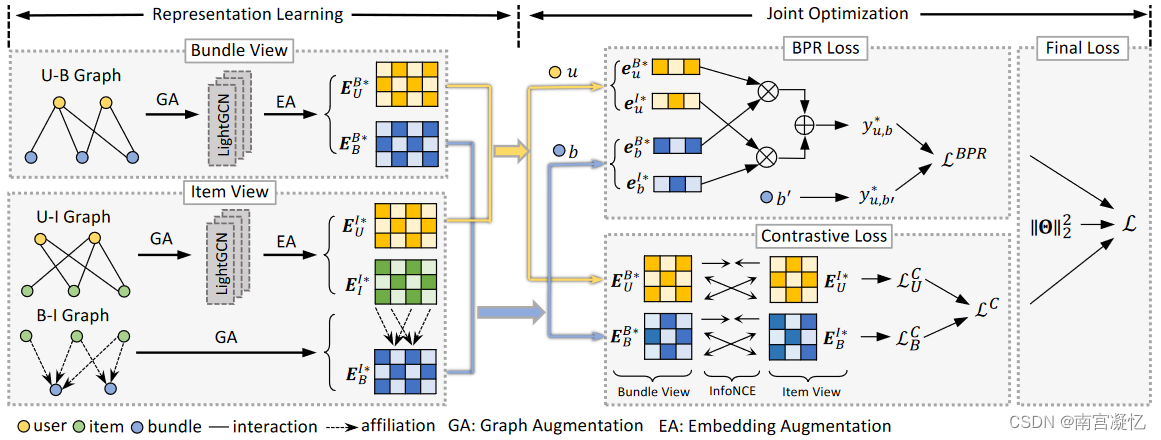
MICRO: Latent Structure Mining with Contrastive Modality Fusion for Multimedia Recommendation 2022
MICRO关注共享模态信息和特定模态信息。
设计了一种新的多模态对比框架,通过使模态感知表示和多模态融合表示紧密结合,实现细粒度多模态融合。
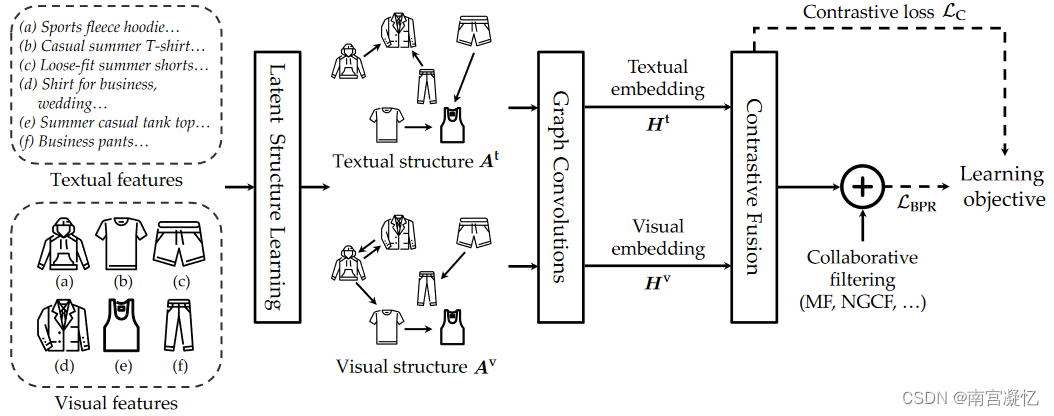
CMCKG: Cross-modal Knowledge Graph Contrastive Learning for Machine Learning Method Recommendation 2022
通过对比损失知识图,从描述属性和结构链接信息中获取实体嵌入。
将描述属性和结构连接信息作为两种模式,通过最大化描述视图和结构视图之间的一致性来学习信息节点表示。
我们将传统的知识图关系分为描述性属性和结构连接,以考虑更多反映实体差异性的描述性信息。
提出了一种跨模态知识图对比学习方法,该方法从不同模态中获取实体特征并相互监督以获得更有效的实体表示。
左边部分说明了描述属性和给定节点的结构连接之间的区别。右侧代表描述和结构观点的跨模态对比学习。
HCGCN: Learning Hybrid Behavior Patterns for Multimedia Recommendation 2022
在HCGCN中,为了加强视觉和文本项目特征映射到同一语义空间,它引用了CLIP,该CLIP采用对比学习,并在一批中最大化正确视觉-文本对的相似度。此外,还针对不同的CL损失函数设置了权重。
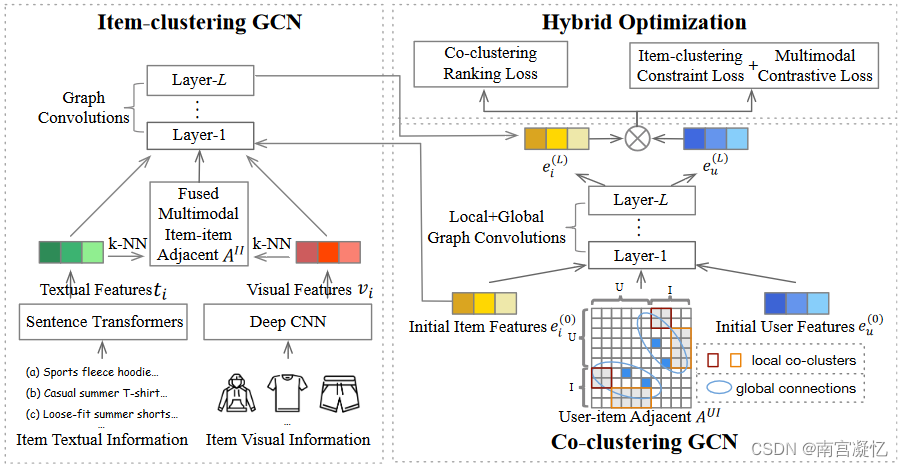
HCGCN 多媒体推荐模型,该模型同时利用用户-物品和物品-物品的语义关系来捕捉不同的用户行为模式,并提供全面的候选物品。
引入了与用户-项目图和项-项目图相对应的共聚类损失和项聚类损失,从而更好地学习隐藏在聚类中的结构信息,指导用户偏好排序。
我们还设计了项目对比损失,以调整和调整多模态特征,从而实现更好的融合。
由于对比学习的核心是挖掘正样本和负样本之间的关系,因此很多模型在推荐场景中采用数据增强方法来构造正样本。
MGMC: Multimodal Graph Meta Contrastive Learning 2021
MGMC设计了一个图增强来增加样本,并引入元学习来增加模型的泛化。
近年来,利用图神经网络(GNNs)进行图对比学习,可以在无监督的情况下学习表示,取得了较好的节点分类精度。然而,尽管在可见类上表现出良好的性能,但这种表示不能推广到只有少量镜头标记样本的不可见新类。为了赋予图的对比学习以泛化能力,本文提出了多模态图元对比学习(MGMC),将多模态元学习与图的对比学习相结合。
一方面,MGMC通过二层元优化来解决少数镜头问题,有效地实现了对未知新类的快速适应。另一方面,通过引入薄膜调制模块,MGMC可以快速推广到具有多模态分布的通用数据集。此外,MGMC采用了最新的图形对比学习方法,不依赖于增广和反例的构造。
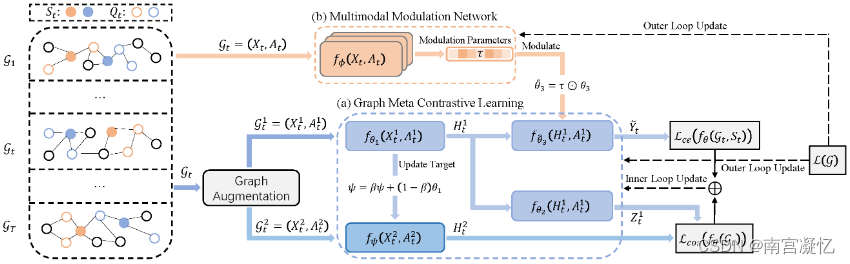
首次将元学习与图对比学习相结合,实现了少镜头节点分类。
不依赖于负样本的图元对比学习范式MGMC。进一步证明了MGMC可以推广到多模态任务,有效地实现对新类的快速适应。
MML: Multimodal Meta-Learning for Cold-Start Sequential Recommendation 2022
MML是一种序列推荐模型,通过构造用户历史采购项目序列的子集来扩展训练数据。
本文研究了具有很短交互序列的新用户随时间而来的冷启动序贯推荐问题。我们将这个问题转化为一个少数镜头学习问题,并采用元学习方法来开发我们的解决方案。对于我们的任务来说,有效知识转移的一个主要障碍是元学习中新旧交互序列之间存在显著的特征差异。
为了解决上述问题,我们提出了一种多模态元学习(MML)方法,将项目的多模态边信息(如文本和图像)融入元学习过程,以稳定和改进冷启动序贯推荐的元学习过程。具体来说,我们设计了一组对应于每种模态的多模态元学习者,其中ID特征用于发展主元学习者,其余的文本和图像特征用于发展辅助元学习者。我们设计了一个自适应的、可学习的融合层来整合基于不同模式的预测,而不是简单地将来自不同元学习者的预测进行组合。
同时,设计了一个冷启动项嵌入生成器,利用多模态边信息对新项的ID嵌入进行预热。
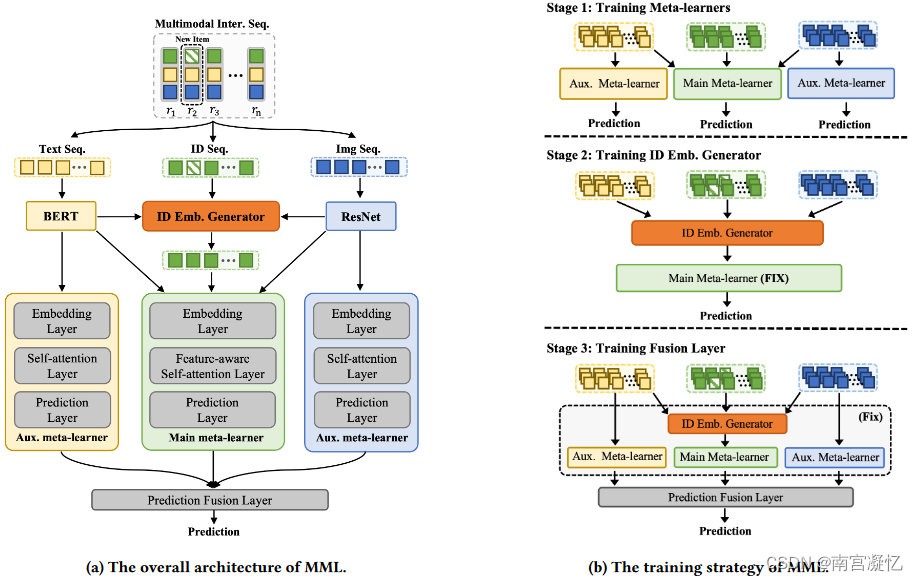
在MAML框架下,本文提出的MML将多模态信息(即关联的文本和图像数据)作为辅助信息融入元学习过程,以减少任务间的差异,提高跨任务知识转移的有效性。具体来说,我们从两个方面利用了项目的多模态信息。
首先,为了减少新老用户序列特征的差异,我们精心设计了一组对应于三种不同模式(ID、文本和图像)的多模态元学习者,通过参考彼此的预测来稳定和改进元训练过程。
其次,考虑到新项目的特征差异,设计了一个冷启动项目嵌入生成器,该生成器利用多模态信息对新项目的ID嵌入进行预热。MML的总体架构如图1(a)所示。
HCGCN: Learning Hybrid Behavior Patterns for Multimedia Recommendation 2022
LHBPMR从图卷积中选择具有类似偏好的项来构造正样本。
设计项目的对比损失,用于调整和对齐多模态特征,以便更好地融合。
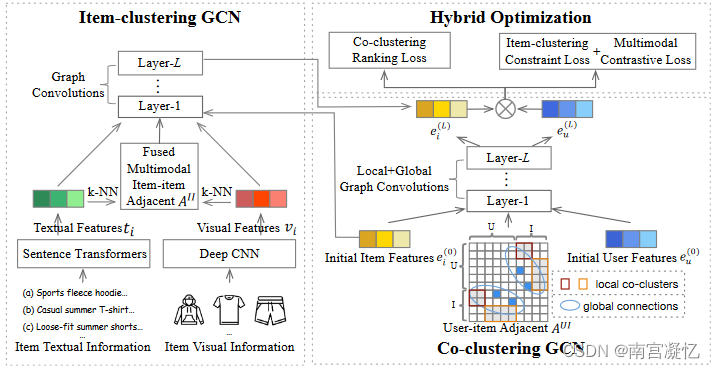
混合聚类图卷积网络(HCGCN)它由三个主要部分组成。首先,视觉和文本编码器将多模态特征映射到公共空间中,并设计一个项目图卷积网络来学习聚类项目关系。其次,引入层次图卷积网络,将局部共聚类用户项语义特征与全局子图消息传递相结合。第三,提出了联合聚类排序损失和项目聚类约束损失,将不同的行为模式明确地融入到用户项目反馈中。为了平衡多模态特征的重要性,我们增加了一个额外的多模态对比损失。
MMGCL:
MMGCL通过模态边缘损失和模态掩蔽构造正样本。
多模态图对比学习(Multi-Modal Graph Contrastive Learning,MMGCL)是一种以自监督学习方式显式增强多模态表示学习的学习方法。特别地,我们设计了两种增强技术来生成用户/项目的多个视图:模态边缘丢失和模态掩蔽。此外,我们还引入了一种新的负采样技术,该技术允许学习模态之间的相关性,并确保每个模态的有效贡献。
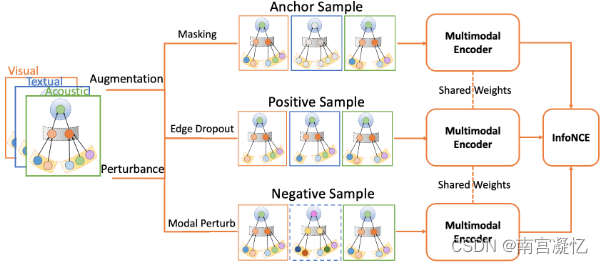
(1)将传统的两两排序任务目标与对比学习目标相结合,提出了一种新的微视频推荐自监督图学习方法。
(2)设计了两种多模态特定增强技术来构造节点的多视图。为了保证每个模态的有效贡献,我们提出了一种通过扰动其中一个模态的有效负采样策略。
Victor: Understanding Chinese Video and Language via Contrastive Multimodal Pre-Training 2021
Victor通过汉语语义构建样本。
对视频和语言理解的神经模型进行预训练仍然是非常困难的,尤其是对中文视频语言数据。首先,现有的视频语言预训练算法主要关注单词和视频帧的共现,而忽略了视频语言内容中其他有价值的语义和结构信息,如序列顺序和时空关系。其次,视频句子对齐与其他代理任务之间存在冲突。第三,缺乏大规模、高质量的中文视频语言数据集(如包含1000万个独特视频),这是预训技术成功的基本条件。
在这项工作中,我们提出了一个新的视频语言理解框架Victor,它代表通过对比多模态预训练的视频语言理解。Victor在对比学习范式下,除了一般的代理任务(如蒙面语言建模)外,还构建了多个新的代理任务,使得模型更加健壮,能够从不同的角度捕获更复杂的多模态语义和结构关系。Victor在一个大规模的中文视频语言数据集上进行训练,包括1000多万个完整的视频和相应的高质量的文本描述。
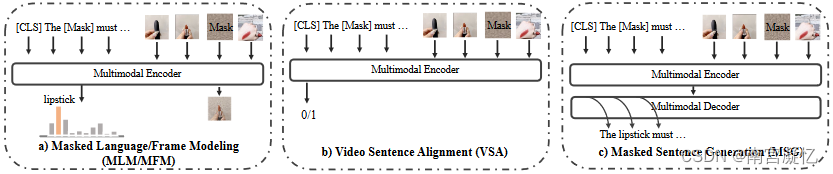
在现有的视频语言预训练方法中广泛使用的一般代理任务。a)屏蔽语言/框架建模(MLM/MFM) b)视频句子对齐(VSA) c)屏蔽语句生成(MSG)
屏蔽句子生成(MSG): 这项任务是传统 MLM 任务的延伸,其中模型不仅要预测屏蔽词,还需要根据视频内容生成连贯的句子。这项任务涉及多模态编码器(对视频和部分文本输入进行编码)和多模态解码器(生成句子的缺失部分)。这对训练为视频内容生成描述或字幕的模型特别有用。

Alivol-10M数据集中的视频示例。
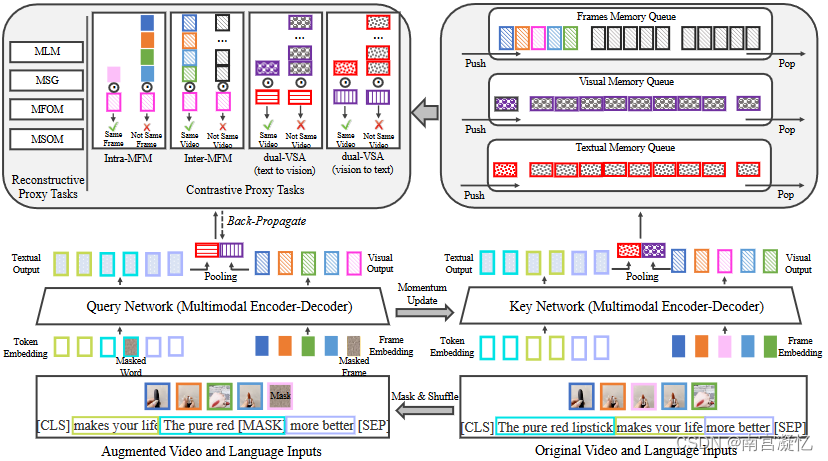
图中相同颜色的正方形表示关联的表示。
Victor(即通过对比多模态预训练来理解视频语言)。具体来说,Victor基于编码器-解码器框架,其主干是变压器的堆叠。编码器部分可用于学习视频和文本的鲁棒多模态表示,以用于分类和跨模态检索等下游判别任务。解码部分强调生成能力,可应用于视频字幕、摘要等下游生成任务。代理任务分为两类:1)重构代理任务和2)对比代理任务。
Victor的重构代理任务包括两个通用任务,即蒙蔽语言建模(MLM)和蒙蔽句子生成(MSG),这两个任务已经在以前的工作中使用过。此外,我们还从序列结构的角度提出了两种新的重构代理任务,即蒙蔽帧序建模(MFOM)和蒙蔽句序建模(MSOM)。目的是从视频帧和句子切分中学习语义序列信息。
对比代理任务包括三个新的任务,即双视频句子对齐(dual-VSA)、帧内屏蔽建模(intra-MFM)和帧间屏蔽建模(interMFM)。我们将典型的VSA扩展到双VSA,以避免强迫模型融合不精确的多模信号。帧内和帧间代理任务的目的是利用视频中的时空监控信号。特别地,帧内MFM侧重于视频中的空间位置,帧间MFM侧重于不同视频之间的时空位置。在这项工作中,我们在对比学习范式下制定了所有的对比代理任务。其基本原理是通过排序损失或噪声对比估计(NCE)损失使正/负查询密钥对相似/不相似。受MoCo启发,我们还构建了一个动态内存队列,以便跨小批量跟踪密钥,从而更好地进行训练。
Combo-Fashion: Fashion Clothes Matching CTR Prediction with Item History 2022
Combo Fashion是一个捆绑式的时尚推荐模型,它构建了一个负向和正向的时尚匹配方案。
作为推荐系统未来发展的基本趋势之一,针对点击率(CTR)预测的服装匹配推荐已经成为一项越来越重要的任务。
与传统的单品推荐不同,建议使用由上衣(例如衬衫)和下装(例如裙子)组成的组合品。在这样一个任务中,这两个单项之间的匹配效果起着至关重要的作用,极大地影响着用户的偏好;然而,以往的CTR预测方法往往忽略了这一点。
针对这一问题,设计了一种新的组合方式算法,该算法通过引入组合项的匹配历史来提取匹配效果,并采用两个级联模块:(1)匹配搜索模块(MSM)分别将常用组合项和不需要的组合项作为正集和负集进行搜索;(ii)匹配预测模块(MPM)采用基于注意的深度模型对候选组合项与正负集之间的精确关系进行建模。此外,从特征、图案和材质三个方面考虑CPM时尚属性,进一步捕捉匹配效果。
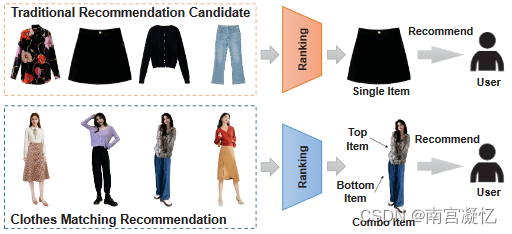
传统框架与服装匹配推荐的比较。
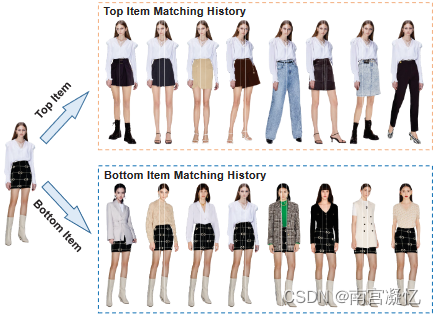
项目匹配历史记录的示例。它包括以前存在的包含顶部/底部项的其他组合项。
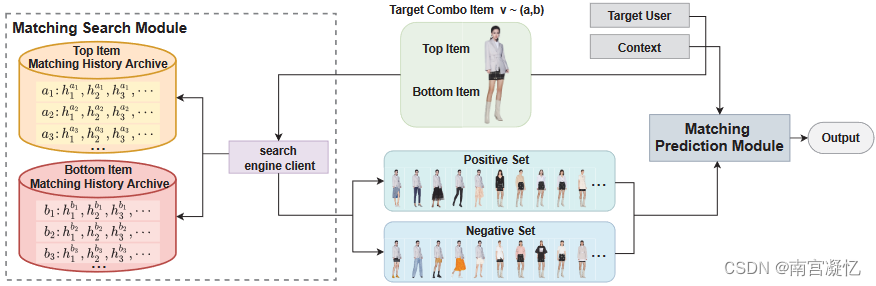
总框架。
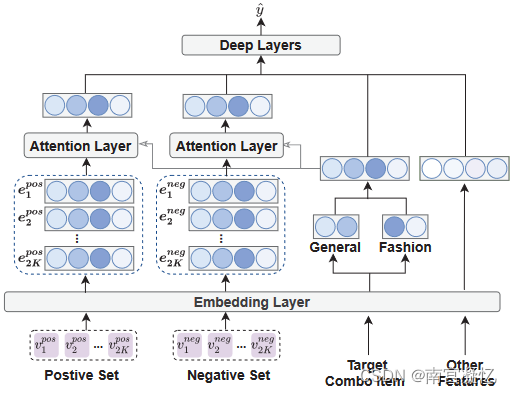
匹配预测模块。
Combo-Fashion分为两个模块,即匹配搜索模块(MSM)和匹配预测模块(MPM)。具体地,MSM从项目匹配历史查询正(常用)和负(不需要)组合项目集;MPM采用基于注意的深度神经网络对这两个搜索集进行挖掘,进一步探索匹配效果并进行最终预测。考虑到时尚的特殊性,我们在除了一般项目特征(id、类别等)之外,还从特征、图案(包括颜色和图形设计)以及有助于捕获匹配效果的材质来描述项目。
QRec: Are Graph Augmentations Necessary? Simple Graph Contrastive Learning for Recommendation 2022
现有的大多数模型都考虑删除多模态数据中不属于用户偏好的信息。QRec则从相反的角度出发,将均匀噪声作为正样本加入到多模态信息中,提高了模型的泛化能力。
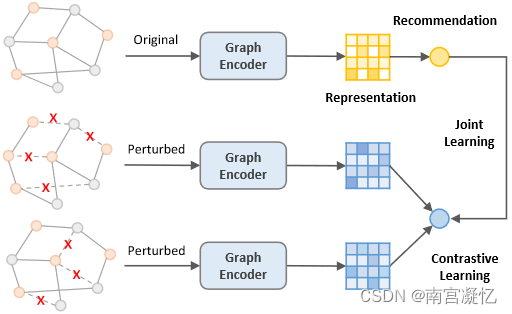
对比学习(CL)从原始数据中提取自监督信号的能力与推荐系统解决数据稀疏性问题的需求相一致,因此近年来在推荐领域取得了丰硕的研究成果。一种典型的基于CL的推荐模型是先对具有结构扰动的用户项二部图进行增广,然后最大化不同增广图之间的节点表示一致性。虽然这个范例被证明是有效的,但是性能提升的基础仍然是一个谜。
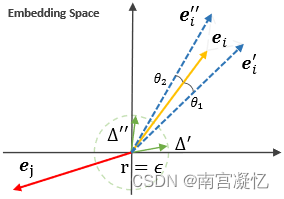
在本文中,我们首先通过实验发现,在基于CL的推荐模型中,CL通过学习更均匀分布的用户/项目表示来进行操作,这可以隐式地减轻受欢迎度偏差。同时,我们揭示了图增广,这被认为是必要的,只是扮演一个微不足道的角色。基于这一发现,我们提出了一种简单的CL方法,该方法抛弃了图增广,而是在嵌入空间中加入均匀噪声来创建对比视图。
UMPR: Recommendation by users’ multimodal preferences for smart city applications. 2020
尽管UMPR没有明确的CL损失函数,但它也构造了一个损失函数来描述视觉正样本和负样本之间的差异。
参考论文
Multimodal Recommender Systems: A Survey
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!