【无标题】
如果企业的数据尚未准备好,那么企业就还没有准备好应用生成式AI。最新研究预测,63个AI用例中每年可以带来2.6万亿至4.4万亿美元的经济效益。七项行动建议将数据用于推动生成式AI实施,以帮助企业实现其生成式AI的规模化价值,包括注重价值、构建数据架构能力、关注数据生命周期关键节点、保护敏感数据、培养数据工程人才、利用生成式人工智能管理数据以及严格跟踪和快速干预。对于CDO和创新领导者来说,这些行动将帮助从试验阶段迈向规模化应用,实现生成式AI的最大商业价值。
企业如何利用数据红利推动生成式AI?
如果企业的数据还没有为生成式AI做好准备,那么企业也没有为生成式AI做好准备。
最新研究估计,生成式 AI 可以在 63 个业务场景用例中增加相当于 2.6 万亿至 4.4 万亿美元的年度经济效益。拉动每一个用例的机会,它将返回数据。企业的数据及其底座基础是生成式AI的决定性因素。
对于大多数首席数字官 (CDO) 来说,这是一个发人深省的命题,尤其是当 72% 的领先企业指出管理数据已经是阻止他们扩展 AI 用例的最大挑战之一时。当今的 CDO 和数据领导者面临的挑战是专注于能够使生成式 AI 为业务创造最大价值的变革。
情况仍在迅速变化,而且几乎没有确定的答案。但在我们与十几家客户就大型生成式 AI 项目进行的合作、与大公司约 25 名CDO的讨论以及我们自己重新配置数据以支持生成式 AI 解决方案的实验中,我们确定了CDO应该考虑的七项行动当他们从实验转向规模化时:
- 让价值成为您的指引。CDO 需要清楚价值在哪里以及需要哪些数据来交付价值。
- 将特定功能构建到数据架构中以支持最广泛的用例。将相关功能(例如矢量数据库和数据预处理和后处理管道)构建到现有数据架构中,特别是支持非结构化数据。
- 聚焦数据生命周期关键点,确保高质量。对从源到消费的数据生命周期制定多种干预措施(包括人工干预和自动化干预),以确保所有材料数据(包括非结构化数据)的质量。
- 保护敏感数据,并准备好在法规出现时迅速采取行动。专注于保护企业专有数据和个人信息,同时积极监控不断变化的监管环境。
- 培养数据工程人才。专注于寻找对实施数据计划至关重要的少数人,并转向更多的数据工程师和更少的数据科学家。
- 使用生成式AI来帮助管理数据。生成式人工智能可以加速现有任务,并改进从数据工程到数据治理和数据分析的整个数据价值链的完成方式。
- 严格跟踪、快速干预。投资于绩效和财务衡量,并密切监控实施情况,以不断提高数据绩效。
1. 让价值成为你的指引
在确定生成式AI的数据策略时,CDO 可能会考虑引用约翰·F·肯尼迪总统的一句话:“不要问你的企业能用生成式AI做什么,而要问你的企业能为生成式AI做什么”。询问生成式AI可以为您的业务做些什么。”?关注价值是一项长期存在的原则,但 CDO 必须特别依赖它来平衡利用生成式AI“做某事”的压力。为了提供对价值的关注,CDO需要对企业生成AI的整体方法的数据影响有一个清晰的认识,这将在三个画像中发挥作用:
- Taker:通过 API 等基本接口使用基础大模型的GPT服务的企业。在这种情况下,CDO 将需要专注于为生成式 AI 模型提供高质量数据,并随后验证输出。
- Shaper:访问基础大模型并根据自己的数据对其进行定制与微调的企业。CDO 需要评估业务的数据管理需要如何发展,以及需要对数据架构进行哪些更改才能实现所需的输出。
- Maker:构建自己的基础定制模型的企业。CDO 将需要制定复杂的数据标签和标签策略,并进行更重大的投资。
CDO 在支持 Shaper 方法方面发挥着最大的作用,因为 Maker 方法目前仅限于那些愿意进行重大投资的大企业,而 Taker 方法本质上是获取商品化的能力。推动 Shaper 方法的一项关键功能是传达交付特定用例所需的权衡,并突出显示最可行的方案。例如,虽然超个性化(hyperpersonalization)是一个很有前途的生成式AI用例,但它需要干净的客户数据、强大的数据保护护栏以及访问多个数据源的管道。CDO 还应该优先考虑能够为业务提供最广泛利益的计划,而不是简单地支持单个用例。
由于 CDO 帮助塑造企业的生成式人工智能方法,因此对价值采取广泛的看法非常重要。尽管生成式AI前景广阔,但它只是更广泛的数据组合的一部分(图表 1)。企业的大部分潜在价值来自传统人工智能、商业智能和机器学习 (ML)。如果 CDO 发现自己 90% 的时间都花在与生成式 AI 相关的计划上,那就是一个危险信号。
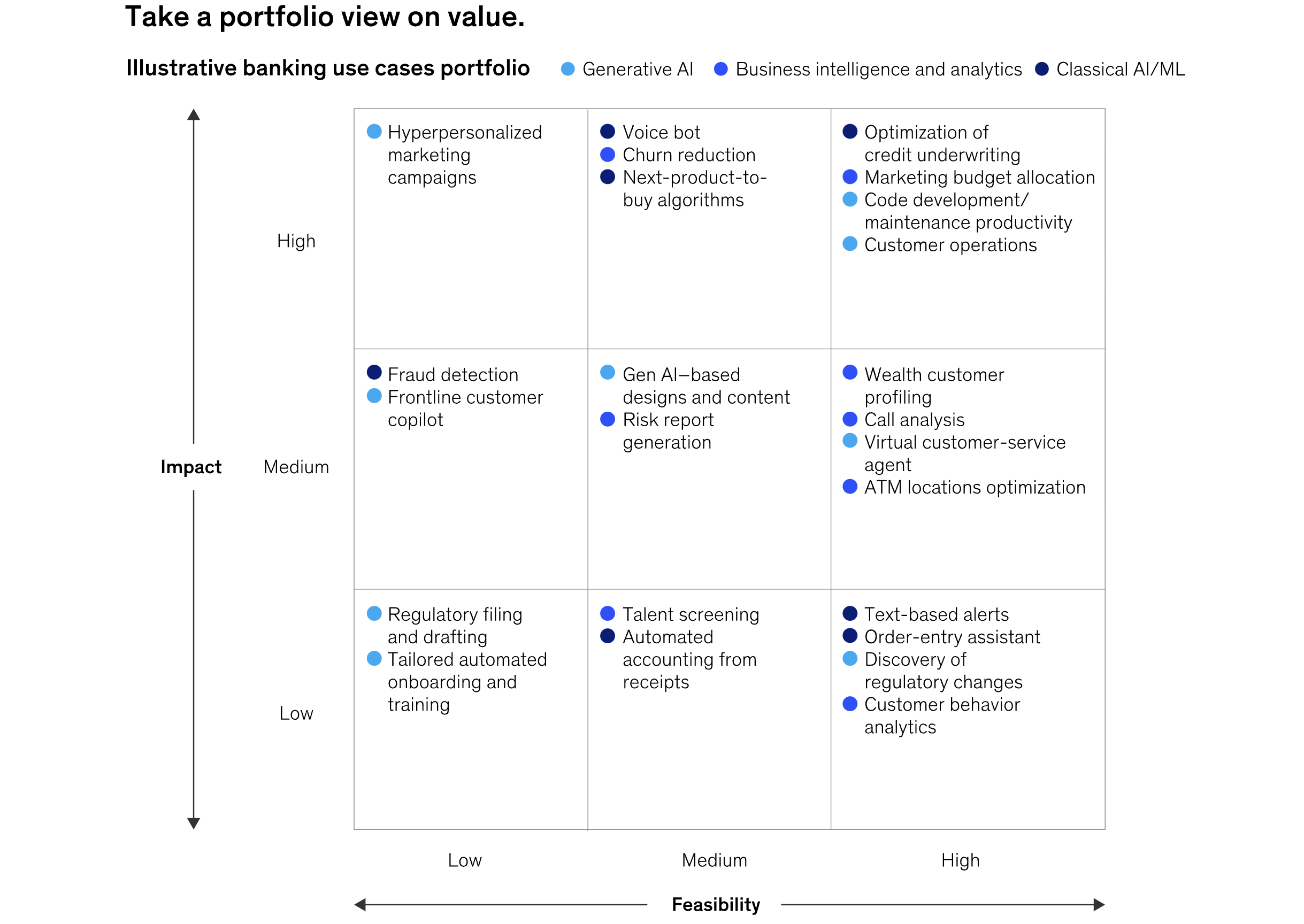
2. 构建数据架构以支持最广泛的用例
数据方面的巨大变化是,由于生成式AI能够处理非结构化数据(例如聊天记录、音频、视频和代码),价值范围变得更大。这是一个重大转变,因为数据组织传统上只能处理结构化数据,例如数据表中的数据。获取这一价值不需要重建数据架构,但想要超越基本接受者原型的 CDO 将需要关注两个明确的优先事项。
首先是修复数据架构的基础。虽然这听起来像是老新闻,但企业以前可能逃脱的系统漏洞将成为生成人工智能的大问题。如果没有强大的数据基础,生成式人工智能的许多优势将根本无法实现。为了确定要关注的数据架构元素,CDO 最好通过确定为最广泛的用例提供最大利益的修复来服务,例如个人身份信息 (PII) 的数据处理协议,因为任何特定于客户的生成式人工智能用例都需要该功能。
第二个优先事项是确定需要对数据架构进行哪些升级才能满足高价值用例的要求。这里的关键问题是如何经济有效地管理和扩展为生成人工智能用例提供动力的数据和信息集成。如果管理不当,则存在大量数据计算活动给系统带来过大压力的巨大风险,或者团队进行一次性集成的风险,这会增加复杂性和技术债务。企业的云配置使这些问题变得更加复杂,这意味着 CDO 必须与 IT 领导层密切合作,以确定计算、网络和服务使用成本。
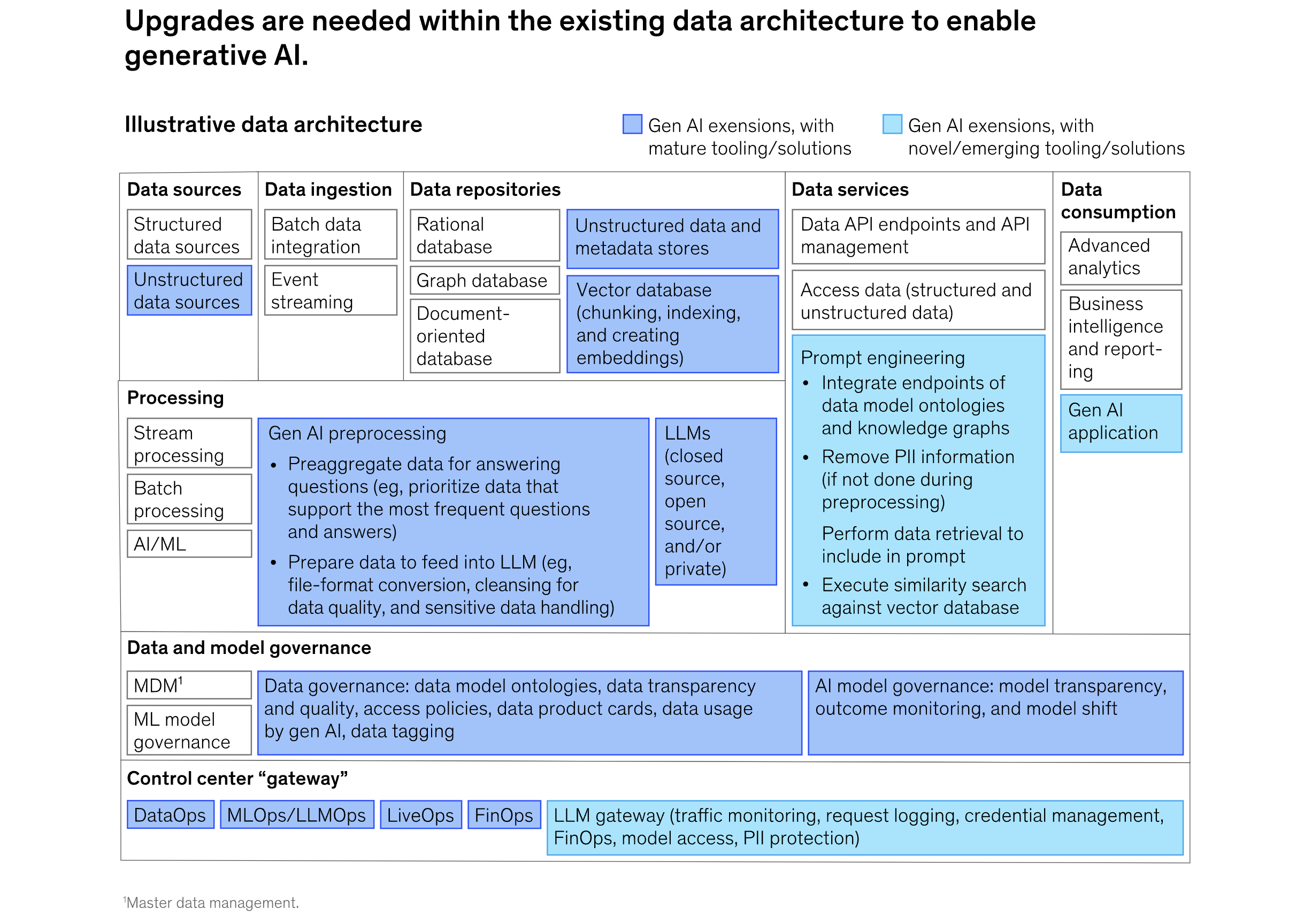
一般来说,CDO 需要优先考虑数据架构的五个关键组件的实施,作为企业技术栈的一部分(图表 2):
- 非结构化数据存储:对于大多数用例,大型语言模型 (LLM) 主要处理非结构化数据。数据领导者需要规划所有非结构化数据源并建立元数据标记标准,以便模型可以处理数据,团队可以找到他们需要的数据。CDO 需要进一步提升数据管道的质量并建立透明度标准,以便轻松跟踪问题的根源并找到正确的数据源。
- 数据预处理:大多数数据都需要进行准备,例如,通过转换文件格式、清理数据质量以及处理敏感数据,以便生成人工智能可以使用这些数据。预处理数据最常用于构建生成人工智能模型的提示。为了提高性能,CDO 需要大规模标准化结构化和非结构化数据的处理,例如访问底层系统的方式,并优先考虑(或“预聚合”)支持最常见问题和答案的数据。
- 矢量数据库:矢量化是一种对内容进行优先级排序并创建“嵌入”(文本含义的数字表示)的方法,以简化对上下文的访问,补充信息生成人工智能需要提供准确的答案。矢量数据库允许生成人工智能模型访问最相关的信息。例如,矢量数据库不提供一千页的 PDF,而是仅提供最相关的页面。在许多情况下,公司不需要构建矢量数据库就可以开始使用生成式人工智能。他们通常可以使用现有的 NoSQL 数据库来启动。
- LLM 集成:更复杂的生成式 AI 使用需要与多个系统交互,这给连接 LLM 带来了重大挑战。多个框架(其中许多是开源的)可以帮助促进这些集成(例如,LangChain 或各种超大规模产品,例如用于 Azure 的 Semantic Kernel、用于 AWS 的 Bedrock 或用于 Google Cloud 的 Vertex AI)。CDO 需要制定选择使用哪些框架的指南,定义可以针对特定目的轻松定制的提示模板,并为法学硕士如何与源数据系统交互建立标准化集成模式。
- 提升语设计:有效的提示语工程(以从生成人工智能模型中得出最佳响应的方式构建问题的过程)依赖于上下文。上下文只能根据结构化和非结构化来源的现有数据和信息来确定。为了提高输出,CDO 需要管理知识图或数据模型和本体(领域中的一组概念,显示其属性以及它们之间的关系)到提示中的集成。由于 CDO 不会拥有整个企业中许多数据存储库的所有权,因此他们需要制定标准并预先限定来源,以确保输入模型的数据遵循特定协议(例如,公开知识图 API 以轻松提供实体和关系) )。
3. 聚焦数据生命周期关键点,确保高质量
数据质量一直是 CDO 的重要问题。但生成式AI型所依赖的数据规模和范围使得“垃圾进/垃圾出”的原则变得更加重要和昂贵,因为训练一个LLM可能要花费数百万美元。与传统机器学习模型相比,在生成式AI模型中查明数据质量问题要困难得多,原因之一是数据太多,而且其中大部分是非结构化的,因此很难使用现有的跟踪工具。
CDO 需要做两件事来确保数据质量:扩展其数据可观测性计划让生成AI应用程序更好地发现质量问题,例如为生成式AI应用程序中包含的非结构化内容设置最低阈值;并在整个数据生命周期中制定干预措施来解决团队发现的问题,主要在四个领域:
- 源数据:扩展数据质量框架,包括与生成人工智能目的相关的措施(例如偏差)。确保结构化和非结构化数据的高质量元数据和标签,并规范对敏感数据的访问(例如,基于角色的基本访问)。
- 预处理:确保数据一致和标准化,并遵守本体和已建立的数据模型。检测异常值并应用标准化。自动化 PII 数据管理,并制定是否应忽略、保留、编辑、隔离、删除、屏蔽或合成数据的指南。
- 提示语:评估、衡量和跟踪提示的质量。在提示中包含结构化和非结构化数据的高质量元数据和沿袭透明度。
- LLM的输出:建立必要的治理程序来识别和解决不正确的输出,并使用“人在循环”来审查和分类输出问题。最终,通过培训员工批判性地评估模型输出并了解输入数据的质量来提升员工的作用。补充自动监控和警报功能,以识别恶意行为。
4. 保护敏感数据,并准备好在法规出现时迅速采取行动
约 71% 的CDO认为生成式 AI 技术正在给企业的数据带来新的安全风险。关于生成式人工智能的安全性和风险已经有很多文章,但 CDO 需要考虑三个特定领域的数据影响:
- 识别企业专有数据的安全风险并确定其优先级。CDO 需要评估与暴露业务数据相关的广泛风险,例如与生成式 AI 模型共享机密和专有代码时潜在的商业秘密暴露风险,并确定最大威胁的优先级。许多现有的数据保护和网络安全治理都可以扩展,以解决特定的生成式AI风险,例如,每当工程师想要与模型共享数据时添加弹出提醒,或者通过运行自动化脚本来确保合规性。
- 管理对 PII 数据的访问。CDO 需要规范在生成人工智能背景下如何检测和处理数据。他们需要建立包含保护工具和人工干预的系统,以确保 PII 数据在数据预处理期间和用于LLM之前被删除。使用合成数据(通过数据制造者)和非敏感标识符会有所帮助。
- 密切跟踪预期的监管激增。生成式AI已成为各国政府迅速制定新法规的催化剂,例如欧盟的人工智能法案,该法案正在制定一系列广泛的新标准,例如让公司发布用于训练LLM的受版权保护的数据摘要。数据领导者必须与企业的风险领导者保持密切联系,以了解新法规及其对数据策略的影响,例如需要“取消训练”使用受监管数据的模型。
5. 培养数据工程人才
随着企业越来越多地采用生成式AI,CDO将不得不关注对人才的影响。一些编码任务将由生成式 AI 工具完成——GitHub 上发布的 41% 的代码是由 AI 编写的。这需要对与生成式AI“副驾驶”一起工作进行专门的培训——麦肯锡最近的一项研究表明,与初级工程师相比,高级工程师与生成式AI副驾驶一起工作的效率更高。数据和AI学院需要纳入针对特定专业水平量身定制的生成式AI培训。
CDO 还需要清楚哪些技能最能支持生成式AI。公司需要能够集成数据集(例如编写将模型连接到数据源的 API)、序列化和组合提示设计、整理大量数据、应用LLM以及使用模型参数的人员。这意味着 CDO 应该更多地关注寻找数据工程师、架构师和后端工程师,而不仅雇佣数据科学家,他们的技能将变得越来越不重要,因为生成式AI允许技术能力不太先进的人使用自然语言来做事基本分析。
短期内,人才供给仍将短缺,预计人才缺口在不久的将来将进一步扩大,为 CDO 建立培训计划提供更多激励。
由于文章篇幅有限,完整请点击:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!