MHFormer 论文解读
目录???????
Multi-Hypothesis Transformer 结果
3.Multi-Hypothesis Transformer
3.2?MultiHypothesis?Generation
3.4. SelfHypothesis?Refinement?
3.5. CrossHypothesis?Interaction
Multi-Hypothesis Transformer 结果
MHFormer在Human3.6M 和 MPI-INF-3DHP两个数据集上实现了SOTA效果,比之前最好的效果提升了3%。
Introduction & Related work
多假设
多假设的原因:很多3d姿态都能映射到2d姿态,从2d推断3d姿态时,会有很多个解,这里就称为多假设。
为什么作者提出这个模型?
参考:https://www.cnblogs.com/Nothing-is-easy/p/16006064.html
在视频中的2D到3D的姿态评估,之前的工作要么使用时空图(spatio-tempral graph),要么使用纯粹的基于Transformer的模型,这些方法的共性就是提取2D pose sequence中的时空信息。但是都忽略了一个重要的事实,2D->3D的过程是一个可逆问题,存在多个可行解,即一个2D pose投影到3D上,符合要求的投影可能有多个,这些方法忽略了这个问题,只估计了一个单一的解决方案,这样得到的结果就不够精确。如下图,带一定的自遮挡,以前的方法只预测一个结果,而作者提出的方法预测了多个可行解,这也是作者为什么要提出这个方法的原因。

如图Figure 2 是作者提出的三阶段框架。从生成多个初始化的表示开始,通过作者称之为的self-communication以合成一个更为准确的预测。
第一阶段引入了称之为Multi-Hypothesis Generation(MHG)的模块,对人体关节的内在结构信息进行建模,在空间域生成多个多层次的特征,这些特征包含了从浅到深的不同深度的不同语义信息,可以视为多个假设的初始表征形式。
接下来,作者提出了两个新的模块对时间一致性进行建模,并增强了时序上的coase representations。第二阶段,一个作者称之为Self-Hypothesis Refinement (SHR)的模块用于微调每个单假设的特征,SHR由两个块组成。第一个块是一个多假设自注意块(multi-hypothesis self-attention,MH-SA),对单个假设构建self-hypothesis communication,使信息在每个假设中传递以增强特征。第二个块是hypothesis-mixing multi-layer perceptron (MLP),多假设混合的多层感知器(十分拗口),用于交换每个假设之间的信息。第二阶段的工作是将多个假设聚合成一个中间表示后,又将其分割成几个不同的假设。
虽然SHR对这些假设进行了微调(refine),但是不同假设之间的联系依然不够强,因为MH-SA模块只传递了各自假设的信息,没有实现跨假设信息交互,为了解决这个问题,作者提出了第三个阶段Cross-Hypothesis Interaction (CHI),跨假设交互模块,对多个假设的的特征进行交互。CHI的关键模块是multi-hypothesis cross-attention(MH-CA),多假设的注意力交互模块,该模块捕获多假设之间的相互关系,构建跨假设的信息交互(cross-hypothesis communication),以实现假设之间的信息传递,从而更好地进行交互建模。然后,利用hypothesis-mixing MLP对多个假设进行聚合得到最终地结果。

本文贡献:
(1)提出了一个基于Transformer的新方法MHFormer,用于单目视频的3D?HPE。该模型能够以端到端的方式有效学习多个姿态假设的时空表征。
(2)提出了多假设特征之间的信息交互,既能够实现自假设信息微调,也能够跨假设进行信息交互。
(3)在两个数据集上实现了最先进的效果,比之前好了3%。
3.Multi-Hypothesis Transformer
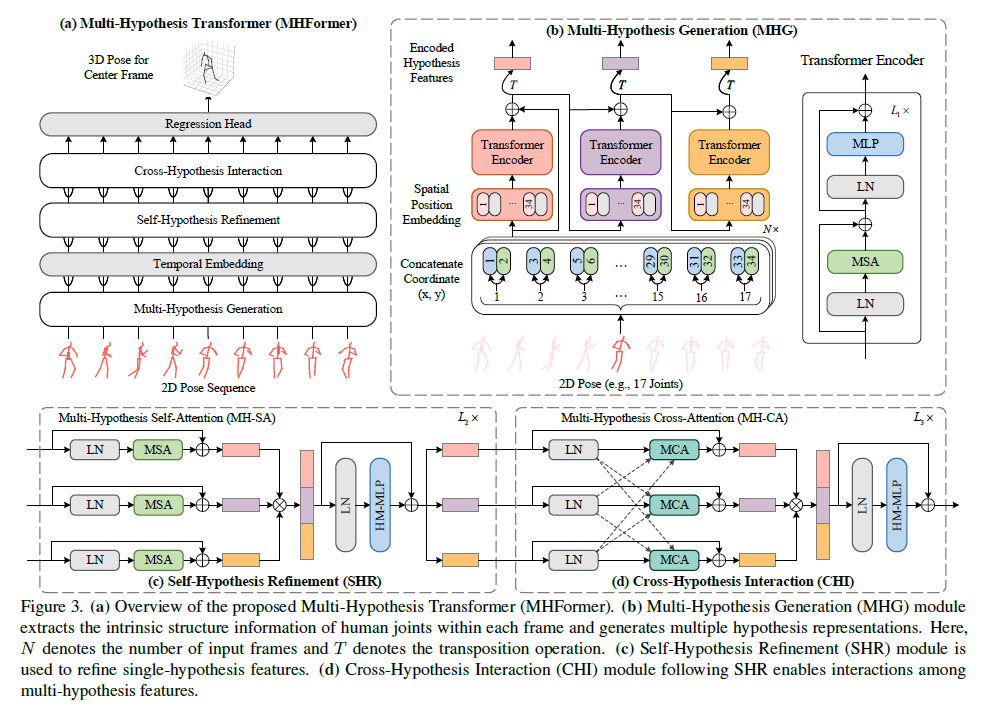
MHFormer整体图如Fig3所示,2D pose sequence由现成的2D pose detector生成。方法目标是通过充分利用多假设特征的时空信息来构建3D pose,方法实现包括三个关键模块:MHG、SHR和CHI,以及两个辅助模块:时序嵌入和回归头。
3.1?Preliminary
本文中,作者使用的架构是基于Transformer的,因为其在长期依赖建模中具有良好表现。本文Transformer的基本组件包含:多头注意力(MSA)和一个多层感知器(MLP)。
MSA?采用点积方式计算注意力分数:

MSA将queries,keys和values分为h个平行输入,输出是将h个注意力头又结合在一起。
MLP?包含两个线性层,分别用于非线性化(GELU激活函数)和特征转换
![]()
3.2?MultiHypothesis?Generation
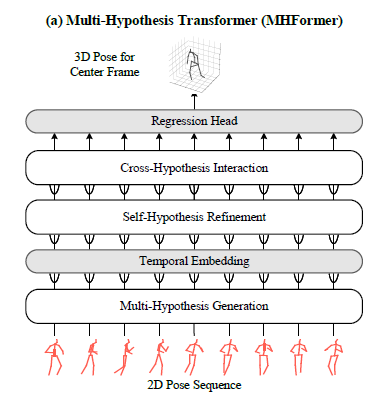
在空间域,作者通过设计一个基于transformer的级联结构来解决可逆问题,这个级联结构能够输出不同潜在空间的多个特征。具体就是引进MHG对人体关节关系进行建模,以及初始化多假设表示。
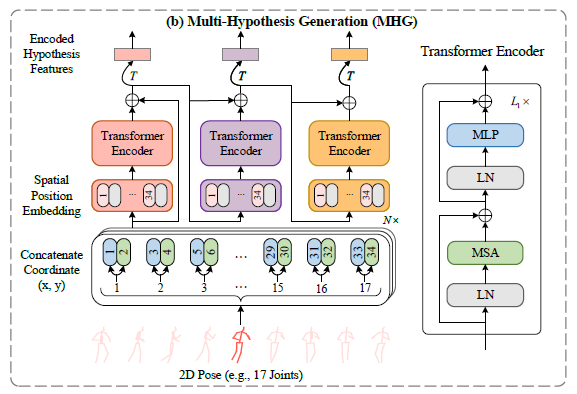
给定一个2D pose sequence,将每一帧的每个关节的坐标作为一个patch,在此基础上加上spatial position embedding,用于保留身体关节的空间信息,之后将这个embedded features 作为MHG的输入,为了梯度传播,这边也应用了残差结构。以上过程可用公式表示为:
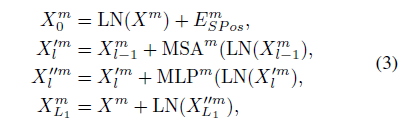
LN()表示LayerNorm。图中可以看到是输出了三个不同的假设表示(presentation),每一个表示经历过的Transformer Encoder层数不一样,即深度不一样,因此包含的信息不一样,也就是三个特征表示是不一样,即作者所谓的在不同潜在空间中包含不同深度的多个假设。
3.3?Temporal Embedding?
MHG更多是在空间上提取信息,时间上的联系是不足的,因此作者在每一帧之间加入了一个Temporal embedding,为后面模块提取时间联系时提供一个强的参考信息。
3.4. SelfHypothesis?Refinement?
在时间域上,作者首先构造了SHR来对单个假设特征表示进行细化/微调(refine),每个SHR层由一个多假设自注意力块(multi-hypothesis self-attention, MH-SA)和一个hypothesis-mixing MLP块。

MH-SA?Transformer模型的核心时MSA,任意两个元素(这里我理解为输入的patch)都可以通过它进行信息交互,进而产生长期依赖。而MH-SA是捕捉单假设中独立的依赖关系,以进行自假设信息交互,也就是说这部分的微调,只和自己有关,从自己身上提取信息后进行微调。公式上可以如下表达:

Hypothesis-Mixing MLP(HM-MLP)?在MH-SA中,多假设被单独处理,而假设之间是没有进行信息交换的,因此在MH-SA之后,作者添加了这个HM-MLP模块。在MH-SA之后,多个假设的特征被连接起来,fed到HM-MLP中进行信息融合,之后将特征沿通道维数均匀划分为不重叠的块,形成(经过多假设信息交互后的)更精细化的假设表示,公式表示为:
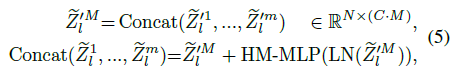
Concat()表示连接操作。经过以上操作,得到的多个假设就包含了其他假设的交互信息了。这边有点不清楚连接后的划分依据是什么?按照个人理解是多个假设特征只是被简单的串联,那么经过MLP层后就发生了信息交互,只需要按照原来连接的地方将一个特征重新拆分成多个假设特征就行了,这样拆分的几个假设特征也就实现了作者所说的假设混合。
3.5. CrossHypothesis?Interaction
然后利用CHI对多假设特征之间的交互进行建模,CHI包括两个模块:multi-hypothesis cross-attention (MH-CA) 和 hypothesis-mixing MLP(HM-MLP)。

MH-CA? MH-SA缺少跨假设之间的连接,这会限制其交互建模。为了捕捉多假设之间的相关性,进行交叉假设交互,作者提出了MH-CA,MH-CA由多个平行的multi-head cross attention(MCA)组成。
MCA用于衡量多个假设特征之间的相关性,与MSA有着相似的结构。下图右侧为MCA的结构图。在MCA中,如果使用相同的keys和values作为输入,会导致更多的块,此处作者采用了一种更有效的策略,通过使用不同的输入来减少参数的数量。对比下图可知,在MSA中是采用相同参数的输入,输入一个特征,输出一个特征,MCA中输入三个不同特征,输出一个特征。

以上实现可表示为公式:

Hypothesis-Mixing MLP(HM-MLP)?这部分操作和3.4HM-MLP基本一致

在最后一层的HM-MLP中,不再进行分配操作,最终将所有假设的特征进行聚合,合成一个单一的假设特征表示ZM。
3.6?Regression Head
经过MHG、temporal embedding、SHR和CHI,输入关节帧X变成了唯一的特征表示ZM,然后在先行输出层上进行回归生成3D pose sequence X~, X~中选择中间帧X^作为最终的预测结果。
3.7?Loss Function
使用标准的平均关节位置误差(MPJPE)损失以端到端方式对整个网络进行训练

4. Experiments
这里就贴一下效果,实现细节翻译一下。
4.2. Implementation Details
作者的实验中,参数采用L1=4 MHG, L2=2 SHR, 和 L3=1 CHI layers。使用pytorch框架在3090单GPU训练20个epochs,优化器为Amsgrad。初始学习率为0.05,每个epoch后收缩系数为0.95,每5个epoch后收缩系数为0.5。2D pose sequence在Human3.6M上采用CPN,MPI-INF-3DHP上使用ground truth。
4.+ results
Human3.6M上的实验效果,protocol1为CPN生成的2D pose sequence作为输入, protocol2为ground truth作为输入,效果都比之前的好:

关于多个假设的对比实验:

MPI-INF-3DHP上的实验效果对比:

Human3.6M上做的消融实验对比,其实就是2D pose sequence输入的不同,以及输入帧数不同时的影响:

消融实验,改变MHG层数和假设数量后的实验结果对比,显示MHG层数最好为4,假设数量最好为3:

消融实验,改变SHR和CHI层数后的实验结果:

消融实验,对比没有多个假设生成对比,以及部分模块有无的对比,说明每个模块都时必要的:

消融实验做了非常多,说明非常重要,不仅仅提出一个新模型就够了,还要实验证明提出的模型不可缺少。
5. Qualitative Results
作者的方法并没有产生多个3D预测结果,但是中间添加了回归层后,可以使中间假设可视化。下图展示了几个定性的结果,作者的方法能够生成不同的貌似合理的3D姿态解,特别是对于具有深度模糊、自遮挡和2D检测器不确定性的模糊身体部位。通过多假设信息聚合得到的最终三维位姿更合理、更准确。

6. Conclusion
贡献:
(1)提出了一个基于Transformer的新方法MHFormer,用于单目视频的3D?HPE。该模型能够以端到端的方式有效学习多个姿态假设的时空表征。
(2)提出了多假设特征之间的信息交互,既能够实现自假设信息微调,也能够跨假设进行信息交互。
(3)在两个数据集上实现了最先进的效果,比之前好了3%。
Limitation:要求相对较大的计算复杂度,因为Transformer卓越的性能是以高计算成本为代价的。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!