Java面试题
目录
- 1. Redis如何做内存优化
- 2. Redis分布式锁的缺点
- 3. 什么是缓存穿透,以及解决方案
- 4. 什么是缓存雪崩,以及解决方案
- 5. 如何保证缓存和数据库数据的一致性
- 6. Jedis和Redisson的区别
- 7. Redis支持的Java客户端有哪些
- 8. Redis和Memecache的区别
- 9. Redis持久化方式
- 10. Redis真的是单线程吗?
- 11. Redis为什么是单线程的?
- 12. Redis的基本操作
- 13. Redis支持的数据类型
- 14. Redis有哪些功能
- 15. Redis使用场景
- 16. RabbitMQ使用场景
- 17. RabbitMQ有哪些重要的角色和组件?
- 18. RabbitMQ中vhost的作用
- 19. MySQL的内连接、左连接、右连接的区别?
- 20. 索引怎么定义,分哪几种?
- 21. 如何优化数据库
- 22. 如何查询重复的数据
- 23. 性别是否适合做索引
- 24. 数据库如何保证主键的唯一性
- 25. MySQL分页
- 26. Float与Double的区别
- 27. Char与Varchar的区别
- 28. ACID
- 29. 获取数据库版本
- 30. Swagger
- 31. easyExcel如何实现
- 32. 如何查询网站在线人数
- 33. SpringBoot如何访问不同的数据库
- 34. 单点登录
- 35. SpringBoot实现分页排序
- 36. SpringBoot的优点
- 37. MyBatis如何防止SQL注入
- 38. MyBatis一级缓存、二级缓存
- 39. mybatis查询多个id
- 40. mybatis中#{}和${}的区别
- 41. Spring中的设计模式
- 42. 如何防止表单的重复提交
- 43. SpringBean的自动装配
- 44. ICO
- 45. AOP【面相切面编程】
- 46. TCP三次握手,四次挥手
- 47. TCP与UDP的区别
- 48. Session的工作原理
- 49. Cookie与Session的区别
- 50. JSP的四种作用域
- 51. forward和redirect区别
- 52. JSP九大内置对象
- 53. JSP与servlet的区别
- 54. 线程池中的线程是怎么创建的
- 55. 如何让Java中的线程彼此同步
- 56. HashMap与HashSet的区别
- 57. 队列和栈是什么,区别?
- 58. 如何确保一个集合不能被修改
- 59. 如何实现数组和List之间的转换
- 60. ArrayList和LinkedList的区别
- 61. HashSet的实现原理
- 62. Set的实现类
- 63. HashMap的实现原理
- 64. HashMap与HashTable的区别
- 65. List与Set的区别
- 66. Collection与Collections的区别
- 67. Java中的容器有哪些:
- 68. 实例化对象的方式
- 69. 举例说明什么情况下更倾向于使用抽象类而不是接口
- 70. Java中什么时候用重载,什么时候用重写
- 71. Java中为什么不允许从静态方法中访问非静态变量
- 72. Java中操作字符串的类
- 73. 常见的异常类
- 74. try-catch-finally中,如果catch中return了,finally还会执行吗?
- 75. final、finally、finalize的区别
- 76. throw和throws的区别
- 77. 为什么要使用克隆,如何实现克隆,深拷贝和浅拷贝的区别
- 78. 什么是Java的序列化,什么时候需要序列化?
- 79. 什么是反射
- 80. Java中IO流的分类
- 81. 接口和抽象类的区别
- 82. String类的常用方法
- 83. 字符串如何反转
- 84. Math方法
- 85. final在Java中的作用
- 86. ==和equals的区别
- 87. JDK和JRE的区别
1. Redis如何做内存优化
- 缩短键值的长度
- 共享对象池【使用整数对象以节省内存】
- 字符串优化
- 编码优化
- 控制Key的数量
2. Redis分布式锁的缺点
Redis分布式锁不能解决超时的问题,分布式锁有一个超时时间,如果超过了这个时间就会出现问题:
- 锁没有被释放
- B锁被A锁释放了
- 数据库事务超时
- 锁过期了,业务还没有被执行完
- Redis主从复制的问题
3. 什么是缓存穿透,以及解决方案
3.1 缓存穿透
一般的缓存系统,会按照Key去缓存查询,如果不存在对应的Value,就会到数据库中查找。
一些恶意的请求会大量请求一些不存在的Key,这样会对后端系统造成很大的压力,这就是缓存穿透。
3.2 解决方案
- 对查询结果为空的情况也进行缓存,缓存时间设置的短一点
- 对一定不存在的Key进行过滤
4. 什么是缓存雪崩,以及解决方案
4.1 缓存雪崩
当缓存服务器重启或者是大量缓存数据集中在某一时间段内失效,这样会对后端系统造成很大的压力,这就是缓存雪崩。
4.2 解决方案
- 在缓存失效后,通过加锁或者队列的方式,控制读数据库和写缓存的线程数。比如:对某一个Key,只允许一个线程查询数据和写缓存,其他线程等待。
- 做二级缓存
- 不同的Key设置不同的过期时间,尽量让缓存的失效时间均匀。
5. 如何保证缓存和数据库数据的一致性
- 淘汰缓存:对于数据比较复杂是,选择淘汰缓存。
- 选择先淘汰缓存,在更新数据库。
- 延时双删策略【设置延时删除的时间】
- 数据库读写分离
6. Jedis和Redisson的区别
- Jedis和Redisson都是Java对Redis操作的封装。
- Jedis只是简单的封装了Redis的API库,相当于Redis的客户端,Jedis相比于Redisson更原生、更灵活。
- Redisson不仅封装了Redis,还封装了更多数据结构的支持,以及锁等功能,相比于Jedis更加强大。
7. Redis支持的Java客户端有哪些
- Jedis
- Redisson【官方推荐使用】
- Lettuce
8. Redis和Memecache的区别
- Redis拥有更多的数据结构和更加丰富的数据操作
- Redis支持Key-Value,常用的数据类型有String、Hash、List、Set、Sorted Set。
- Memecache只支持Key-Value
- 内存使用率:Redsi采用Hash结构来做Key-Value的存储,由于其组合式的压缩,内存利用率高于Memecache。
- 性能对比:Redis单核;Memecache多核
- Redis支持磁盘持久化,Memecache不支持
- Redis支持分布式集群,Memecache不支持
9. Redis持久化方式
- RDB:在不同的时间点,将Redis存储的数据生成快照存储到磁盘等介质上。
- AOF:记录Redis执行过的指令,在下一次Redis启动时,从新执行一遍。
- RDB与AOF可以同时使用,如果Redis重启,会优先使用AOF的方式恢复数据,这是因为AOF方式的数据恢复完整度高。
10. Redis真的是单线程吗?
- Redis6.0之前是单线程,Redis6.0之后开始支持多线程。
11. Redis为什么是单线程的?
- 代码更清晰,逻辑更简单
- 不需要考虑锁的问题,不存在加锁和释放锁的操作,没有因为可能出现死锁而导致的性能问题。
- 不存在多线程之间的切换而消耗CPU
- 无法发挥多核CPU的优化,但是可以多开几个Redis实例来完善。
12. Redis的基本操作
创建Redis连接池
JedisPool pool = new JedisPool(new JedisPoolConfig(), "127.0.0.1");
Jedis jedis - pool.getResource()
存、取值
// 赋值
jedis.set("key", "value");
// 取值
jedis.get("key");
// 删除
jedis.del("key");
// 给Key叠加一个value
jedis.append("key", "value2"); // 此时key的值是value + value2
// 同时给多个Key进行赋值
jedis.mset("key1","value1","key2","value2");
对Map进行操作
Map<String, String> user = new HashMap();
user.put("key1", "value1");
user.put("key2", "value2");
user.put("key3", "value3");
// 赋值
jedis.hmset("user", user);
// 取出user中的key1
List<String> nameMap = jedis.hmget("user", "key1");
// 删除user中一个键值
jedis.hdel("user", "key2");
// 是否存在一个键
jedis.exists("user");
// 取出所有Map中的值
Iterator<String> iter = jedis.hkeys("user").iterator();
while(iter.next()) {
jedis.hmget("user", iter.next())
}
13. Redis支持的数据类型
- String
- Hash
- List
- Set
- Zset
14. Redis有哪些功能
- 基于本机内存的缓存
- 持久化功能
- 哨兵和复制【保证Redis的高可用】
哨兵(Sentinel):可以管理多个Redis服务器,提供监控、提醒、自动故障转移等功能。
复制:备份多个Redis服务器
- 集群
15. Redis使用场景
- Redis基于内存的NoSQL数据库,通过新建线程进行持久化,不影响Redis单线程的读写操作
- 通过List取最新的N条数据
- 模拟类似于Token这种需要设置过期时间的场景
- 发布订阅消息系统
- 定时器、计数器
16. RabbitMQ使用场景
- 解决异步问题:例如:用户注册、发送邮件、短信反馈,使用RabbitMQ消息队列,用户无需等待。
- 服务间耦合:例如:订单系统和库存系统,中间加入RabbitMQ消息队列,当库存出现问题,订单系统依旧可以使用,降低服务之间的耦合度。
- 秒杀系统:利用RabbitMQ的最大值,实现秒杀系统。
17. RabbitMQ有哪些重要的角色和组件?
角色:客户端、RabbitMQ、服务端
组件:
- 连接管理器【connectionFactory】:应用程序与RabbitMQ之间建立连接的管理器。
- 管道【Channel】:消息推送使用的信道。
- 路由键【RoutingKey】:用于把生产者的数据分配到交换机上。
- 交换机【Exchange】:用于接收和分配消息。
- 绑定键【BindKey】:用于把交换机的消息绑定到队列上。
- 队列【Queue】:用于存储生产者消息
18. RabbitMQ中vhost的作用
vhost可以理解为mini版的RabbitMQ,其内部均含有独立的交换机、绑定、队列,最重要的是拥有独立的权限系统,可以做到vhost范围内的用户控制。从RabbitMQ全局考虑,不同的应用可以跑在不同的vhost上,作为不同权限隔离的手段。
19. MySQL的内连接、左连接、右连接的区别?
- 内连接:显示两个表中有联系的所有数据。
- 左连接:以左表为参照,显示所有数据,右表中没有的则以Null显示。
- 右连接:以右表为参照,显示所有数据,左表中没有的则以Null显示。
20. 索引怎么定义,分哪几种?
- b-tree索引:如果不建立索引的情况下,Oracle就自动给每一列都增加一个b-tree索引。
- normal:普通索引
- unique:唯一索引
- bitmap:位图索引,位图索引限定于只有几个枚举值的情况,比如:性别
- 基于函数的索引
21. 如何优化数据库
- 选取合适的字段属性
- 使用join连接代替子查询
- 使用联合union代替手动创建的临时表
- 事务
- 锁定表
- 使用外键
- 使用索引
- 优化SQL查询语句
22. 如何查询重复的数据
查询单个字段重复数据
select 重复字段A, count(*) from 表 group by 重复字段A having count(*) > 1
查询多个字段重复数据
select 重复字段A, 重复字段B, count(*) from 表 group by 重复字段A, 重复字段B having count(*) > 1
23. 性别是否适合做索引
区分度不高的字段不适合做索引,因为索引页是需要开销的,是需要存储的,不过这类字段可以做联合索引的一部分。
24. 数据库如何保证主键的唯一性
- 主键约束
- 唯一性约束
- 唯一性索引
25. MySQL分页
SET @page_size = 10; -- 每页显示10条记录
SET @page_number = 2; -- 第2页
SELECT * FROM your_table
LIMIT @page_size OFFSET (@page_number - 1) * @page_size;
26. Float与Double的区别
- 内存字节:Float:4;Double:8
- 有效数据位数:Float:8;Double:16
- 数据取值范围
- 处理速度:Float > Double
27. Char与Varchar的区别
- char长度固定;varchar长度可变
- char效率高于varchar
- char占用空间高度varchar
- char在查询时需要使用trim
28. ACID
ACID是数据库事务的四大基本要素:原子性、一致性、隔离性、持久性
- 原子性:要么都执行,要么都不执行
- 一致性:事务必须始终保持系统处于一致的状态,不管在任何给定的时间并发事务有多少。
- 隔离性:隔离状态执行事务,是他们好像是系统在给定时间内执行的唯一操作。
- 持久性:一个成功的事务将永久的改变系统的状态
29. 获取数据库版本
select version()
30. Swagger
Swagger是用于生成RestFul Web服务的可视化表示工具,它使文档和服务器可视化更新。
定义好Swagger后,可以调用服务端接口,来查看接口的返回值,验证返回数据的正确性。
31. easyExcel如何实现
新建ExcelModelListener监听类,并继承AnalysisEventListener
package com.zh.oukele.listener;
import com.alibaba.excel.context.AnalysisContext;
import com.alibaba.excel.event.AnalysisEventListener;
import com.zh.oukele.model.ExcelMode;
import java.util.ArrayList;
import java.util.List;
/***
* 监听器
*/
public class ExcelModelListener extends AnalysisEventListener<ExcelMode> {
/**
* 每隔5条存储数据库,实际使用中可以3000条,然后清理list ,方便内存回收
*/
private static final int BATCH_COUNT = 5;
List<ExcelMode> list = new ArrayList<ExcelMode>();
private static int count = 1;
@Override
public void invoke(ExcelMode data, AnalysisContext context) {
System.out.println("解析到一条数据:{ "+ data.toString() +" }");
list.add(data);
count ++;
if (list.size() >= BATCH_COUNT) {
saveData( count );
list.clear();
}
}
@Override
public void doAfterAllAnalysed(AnalysisContext context) {
saveData( count );
System.out.println("所有数据解析完成!");
System.out.println(" count :" + count);
}
/**
* 加上存储数据库
*/
private void saveData(int count) {
System.out.println("{ "+ count +" }条数据,开始存储数据库!" + list.size());
System.out.println("存储数据库成功!");
}
}
32. 如何查询网站在线人数
通过监听session对象的方式实现在线人数的统计和在线人员信息展示,并且让超时的自动销毁
33. SpringBoot如何访问不同的数据库
可以使用druidDataSource创建DataSource,然后通过jdbcTemplate执行SQL
34. 单点登录
用户一次登录可以在多平台使用
实现方式:
- Cookoe作为凭证
- JSONP实现
- 页面重定向
- 独立登录系统
35. SpringBoot实现分页排序
Spring Data Jpa
36. SpringBoot的优点
- 快速构建项目,可选一些必要的组件
- 对主流框架的无配置集成
- 内嵌Tomcat,项目可以独立运行
- 删除繁琐的XML配置文件
- 提高了开发和部署效率
- 提供starter,简化maven配置
37. MyBatis如何防止SQL注入
- 检查变量的数据类型和格式
- 过滤特殊符号
- 绑定变量,使用预编译语句【参数与SQL分离】
38. MyBatis一级缓存、二级缓存
- 一级缓存指的是mybatis中sqlSession对象的缓存,当我们执行查询以后,查询的结果会同时存在sqlSession中,再次查询时,先去sqlSession中找,有直接拿,当sqlSession消失,mybatis的一级缓存也就消失了,当调用sqlSession的修改、增加、删除、commit()、close()等方法时,会清空一级缓存
- 二级缓存指的是mybatis中的sqlSessionFactory对象的缓存,由同一个sqlSessionFactory对象创建的sqlSession共享其缓存,但是其中缓存的是数据,而不是对象,查询流程:一级缓存 > 二级缓存 > 数据库
39. mybatis查询多个id
Page<UserPoJo> getUserListByIds(@Param("ids") List<Integer> ids);
<!--根据id列表批量查询user-->
<select id="getUserListByIds" resultType="com.guor.UserPoJo">
select * from student
where id in
<foreach collection="ids" item="userid" open="(" close=")" separator=",">
#{userid}
</foreach>
</select>
40. mybatis中#{}和${}的区别
- #{}带引号,${}不带引号
- #{}可以防止SQL注入
- ${}常用于数据库表名,order by字句
- 一般能用#{}的不要使用${}
41. Spring中的设计模式
- 工厂模式:指的是根据传入的参数,决定实例化哪个类。Spring中的BeanFactory就是简单的工厂模式,根据传入一个唯一的标识获取Bean对象
- 单例模式:程序只有一个对象的实例,使用内部类与双重验证方式实现的单例是安全的
- 代理模式:AOP
42. 如何防止表单的重复提交
- 通过JavaScript屏蔽提交按钮
- 给数据库增加唯一键的约束
- 利用Session防止表单重复提交
- 使用AOP自定义切入实现
43. SpringBean的自动装配
Spring支持IOC,自动装配不用类实例化,直接从Bean容器中提取
44. ICO
ICO【控制反转】:对象的创建和使用的控制权被转移到了第三方组件或容器中【依赖注入DI】,主要作用是用于解耦
45. AOP【面相切面编程】
在Spring AOP中,可以定义切入点【pointcut】来指定何时增强【advice】,增强可以分为前置增强【before advice】,后置增强【after advice】,异常抛出通知【after throwing advice】,或最终通知【after finally advice】
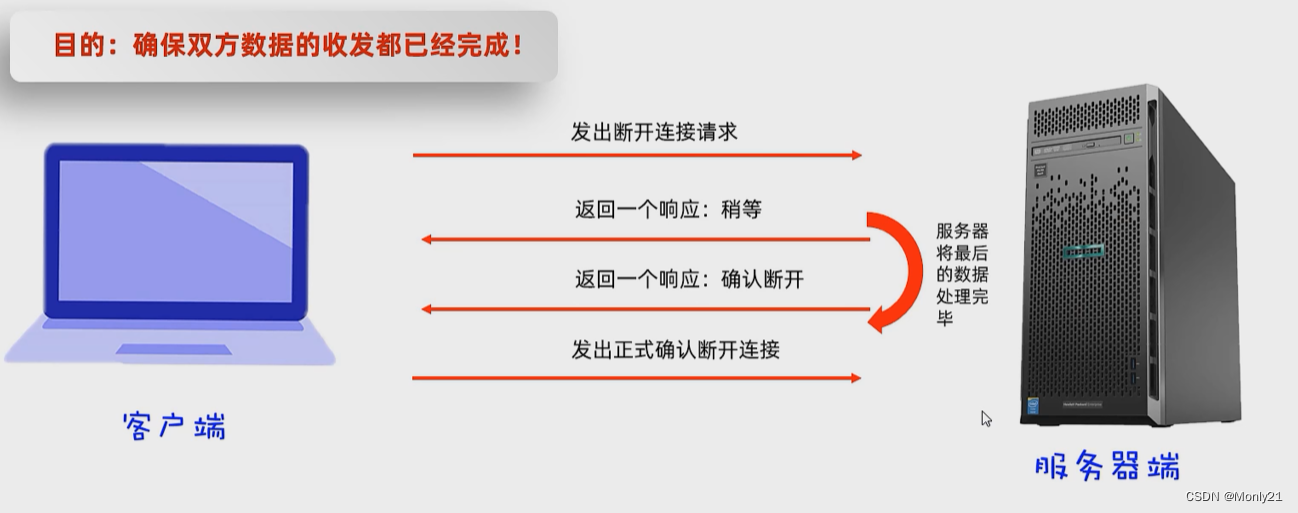
46. TCP三次握手,四次挥手

47. TCP与UDP的区别
- TCP传输控制协议,UDP用户数据表协议
- TCP长连接,UDP无连接
- UDP结构简单,只需要发送,不需要接收
- TCP可靠,保证数据的正确性、顺序性;UDP不可靠,可能丢包
- TCP适用于少量数据,UDP适用于大量数据传输
- TCP速度慢,UDP数据快
48. Session的工作原理
当客户端登录完成以后,会在服务器生成一个Session,服务器将生成的Session返回给浏览器,浏览器将session存储在cookie中,用户再次登录时,会获取对应的cookieid,然后将cookieid发送给服务器请求登录,服务器在内存中查找对应的sessionid,找到完成登录,找不到,返回登录页面
49. Cookie与Session的区别
- 存储位置:cookie浏览器,session服务器
- 存储类型和大小:cookie只能存储ASCII字符串,大小4KB左右;session可以存储任何类型,大小限制于服务器内存
- 安全性:cookie不安全,session安全
- 有效性:cookie可以持久保存,session与会话有关
- 跨域:cookie可以跨域,session不能
50. JSP的四种作用域
application、session、request、page
51. forward和redirect区别
- forward请求转发,redirect重定向
- forward客户端浏览器执行一次,redirect客户端浏览器执行两次
- forward地址栏不变,redirect地址栏改变
52. JSP九大内置对象
- pageContext
- page
- request
- response
- session
- application
- exception
- out
- config
53. JSP与servlet的区别
- servlet是服务器端的Java程序,担当客户端和服务器端的中间层
- JSP本质是一个简化版的servlet,是一种动态页面设计,主要目的:将标识逻辑从servlet中分离
- JVM只能识别Java代码,不能识别JSP,JSP编译后变成了servlet,web容器将JSP代码编译成JVM能够识别的servlet代码
- JSP有内置对象,servlet没有
54. 线程池中的线程是怎么创建的
线程池中的线程是在第一次提交任务时创建。ThreadPoolExecutor
55. 如何让Java中的线程彼此同步
- synchronized
- volatile
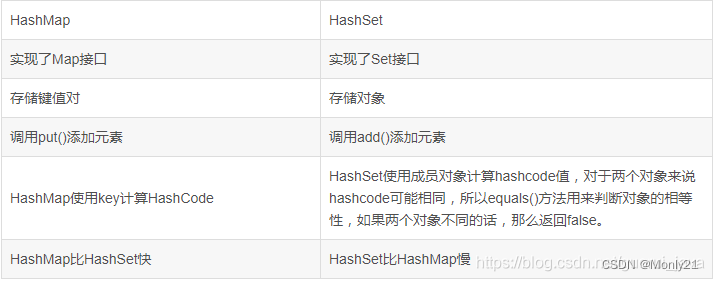
56. HashMap与HashSet的区别
57. 队列和栈是什么,区别?
队列:先进先出,栈先进后出
遍历数据的速度不同:
- 栈只能从头部取数据,先放进去的数据需要遍历整个栈才能得到,而且遍历数据时还需要开辟临时空间,保持数据在遍历之前的一致性
- 队列基于地址指针遍历,既可以从头遍历,也可以从尾部遍历,但是不能同时遍历,无需开辟临时空间,遍历速度快
58. 如何确保一个集合不能被修改
使用Collections包下的unmodifiableMap方法
同理:Collections包也提供了对list和set集合的方法。
Collections.unmodifiableList(List)
Collections.unmodifiableSet(Set)
59. 如何实现数组和List之间的转换
// 数组 ---> List
List<String> list = Arrays.asList(arr)
// List ---> 数组
String[] arr = list.toArray(new String[list.size()])
60. ArrayList和LinkedList的区别
- ArrayList是动态数组结构,查询遍历效率高
- LinkedList是链表结构,增加删除效率高
61. HashSet的实现原理
HashSet是一个HashMap实例,数据结构:数组+链表
HashSet是基于HashMap实现的,HashSet的元素都放在HashMap的key上,而value都是统一的对象PRESENT
HashSet中add方法调用的底层是HashMap中的put方法,put方法要判断插入的值是否存在,而HashSet的add方法,首先判断元素是否存在,如果存在则不插入,不存在则插入,保证HashSet元素的不重复性
通过对象的hashCode和equals方法保证对象的唯一性
62. Set的实现类
- HashSet:无序,不重复,线程不安全,数据结构:hash表
- TreeSet:可排序
- LinkedSet:有序Set集合
63. HashMap的实现原理
HashMap基于Map接口,以键值对的形式存储数据,线程不安全
初始大小16 2N扩容
存储结构:数组+链表+红黑树
64. HashMap与HashTable的区别
- HashMap线程不安全,HashTable线程安全
- HashMap允许键值为Null,HashTable不允许
- HashMap默认容器16 2N扩容,HashTable默认容器11 2N+1扩容
65. List与Set的区别
- List与Set都集成了Collection接口
- List:有序,可重复,支持for循环迭代器遍历,查询效率高
- Set:无序,不重复,只能使用迭代器遍历,增加删除效率高
66. Collection与Collections的区别
- Collection:最基本的集合接口,派生了List和Set,分别定义了两种不同的存储方式
- Collections:包装类,提供了关于集合操作的静态方法,工具类,不能被实例化
67. Java中的容器有哪些:
- Collection
- List:ArrayList、LinkedList、Vector
- Set:HashSet、LinkedHashSet、TreeSet
- Map:HashMap、HashTable、TreeMap
68. 实例化对象的方式
- new一个对象
- clone()克隆一个对象
- 序列化与反序列化
69. 举例说明什么情况下更倾向于使用抽象类而不是接口
接口通常被用来表示附属描述或行为:Runnable、Clonable、Serializable等。
因为类只能被单继承,当使用抽象类来表示行为时,只能继承一个。
在一些对时间要求比较高的应用中,倾向于使用抽象类,他会比接口稍微快一点。
如果希望把一系列的行为都规范在类继承层次内,并且可以更好的在同一个地方进行编码,那么抽象类是更好的选择。
有时,抽象类和接口一起使用,在接口中定义函数,在抽象类中定义默认的实现。
70. Java中什么时候用重载,什么时候用重写
- 重载是多态的集中表现,要以统一的方式处理不同类型数据的时候,可以使用重载
- 重写是建立在继承的关系上的,子类在继承父类的基础上增加新的功能,可以使用重写。
71. Java中为什么不允许从静态方法中访问非静态变量
- 静态变量属于类本身,在类加载的时候就会被分配内存空间,可以使用类名直接访问
- 非静态变量属于类的对象,只有在实例化的时候,才能被分配内存空间
- 静态方法也是属于类本身,在类加载的时候就会被分配内存空间,但是此时没有实例化对象,内存中没有非静态变量,无法被调用
72. Java中操作字符串的类
- String:不可变对象,对String类型进行改变时都会生成一个新的对象
- StringBuilder:线程不安全,效率高,多用于单线程
- StringBuffer :线程安全,效率低【因为加锁的原因】,多用于多线程
不频繁的操作字符串使用String,操作频繁的情况不建议使用String
StringBuilder > StringBuffer > String
73. 常见的异常类
- 空指针异常
- 数组下标越界
- 数据库相关异常
- 打开文件失败时抛出的异常
- IO异常
74. try-catch-finally中,如果catch中return了,finally还会执行吗?
先执行catch抛出异常,在执行finally,最后return返回

75. final、finally、finalize的区别
- final:修饰类、变量、方法,修饰的类不能被继承,修饰的变量不能被重新赋值,修饰的方法不能被重写
- finally:用于抛出异常
- finalize:垃圾回收
76. throw和throws的区别
- throw:作用的方法的内部,由方法体内的语句处理
- throws:作用在方法上,表示抛出异常
77. 为什么要使用克隆,如何实现克隆,深拷贝和浅拷贝的区别
为什么要使用克隆
如果相对一个对象进行复制,又想保留原有的对象进行接下来的操作,这个时候就需要克隆
如何实现克隆
- 实现Cloneable接口,重写clone方法
- 实现Serializable接口,通过对象的序列化和反序列化实现克隆
深克隆和浅克隆的区别
- 浅克隆:仅仅克隆基本数据类型,不克隆引用数据类型
- 深克隆:既可以克隆基本数据类型,也可以克隆引用数据类型
78. 什么是Java的序列化,什么时候需要序列化?
Java序列化
序列化是一种用来处理对象流的机制,将对象的内容流化,将流化的对象传输与网络之间,实现Serialized接口
应用场景
网络传输或将对象保存在本地文件时
79. 什么是反射
反射Reflect,是Java在运行时进行自我观察的能力,通过Class、Constructor、Field、Method四个方法获取一个类的各个组成部分。
对于任意的一个类,可以知道类中有哪些属性和方法。
这种动态的获取类的信息一级动态调用对象的方法的功能叫做反射
案例:AOP面相切面编程
80. Java中IO流的分类
- 按照流划分:输入流【InputStream】和输出流【OutputStream】
- 按照单位划分:字节流【reader】和字符流【writer】
81. 接口和抽象类的区别
- 接口使用interface修饰,抽象类使用abstract修饰
- 接口与抽象类都不能被实例化
- 接口可以多实现,抽象类只能单继承,如果一个类继承了抽象类,必须继承抽象类中的所有抽象方法,否则该类也是抽象类
82. String类的常用方法
- equals:比较是否相等
- length:长度
- contains:包含
- replace:替换
- split:分割
- substring:截取
- indexof:获取字符所在的下标
- trim:去除两端空格
- toUpperCase:转大写
- toLowerCase:转小写
- isEmpty:是否为空
- concat:拼接
83. 字符串如何反转
将String增加到StringBuilder中,调用reverse()方法
84. Math方法
- Math.ceil():向上取整
- Math.floor():向下取整
- Math.round():四舍五入
85. final在Java中的作用
修饰引用
如果引用是基本数据类型,则引用为常量,该值不能被修改
如果 引用是引用数据类型,比如:数组,对象,则值可以修改,但是地址不能修改
如果引用类的成员变量:必须赋值
修饰方法
当使用final修饰方法,该方法将成为最终的方法,不能被子类重写,但是可以继承
修饰类
当使用final修饰类,该类将成为最终的类,不能被继承。比如:String类
86. ==和equals的区别
- == 比较基本数据类型,比较的是值是否相等
- == 比较引用数据类型,比较的是地址是否相等
- equals 不能用于比较基本数据类型
- 如果没有重写equals,equals相当于 ==
- 如果重写了equals,equals比较的是对象的内容
87. JDK和JRE的区别
- JDK:Java的开发工具包
- JRE:Java的运行环境
JDK包含了JRE,JDK中有一个名为JRE的目录,里面包含了两个文件夹bin和lib,bin就是JVM,lib就是JVM工作所需要的类库
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 2024.1.16——统计整数数目
- 点亮AI未来的U盘
- [python]使用pyqt5搭建yolov8钢筋计数一次性钢材计数系统
- 在金属/绝缘体/p-GaN栅极高电子迁移率晶体管中同时实现大的栅压摆幅和增强的阈值电压稳定性
- uni-app微信小程序uni.getLocation获取经度纬度【定位】
- 4-Docker命令之docker load
- 解密SqlServer数据库引擎:揭开数据之谜,探寻SqlServer的秘密力量
- HAL——SPI
- NodeJs 第四章 net、http、https 模块
- 操作系统--内存管理