MIT6.5840-2023-Lab2C: Raft-Persistence
发布时间:2023年12月17日
前置知识
见上一篇 Lab2A。
实验内容
实现 RAFT,分为四个 part:leader election、log、persistence、log compaction。
实验环境
OS:WSL-Ubuntu-18.04
golang:go1.17.6 linux/amd64
Part 2C: persistence
大部分的bug都与这张图有关。如果前两次lab通过了千次以上测试,这边应该问题不大。注意rpc前后的状态判断。
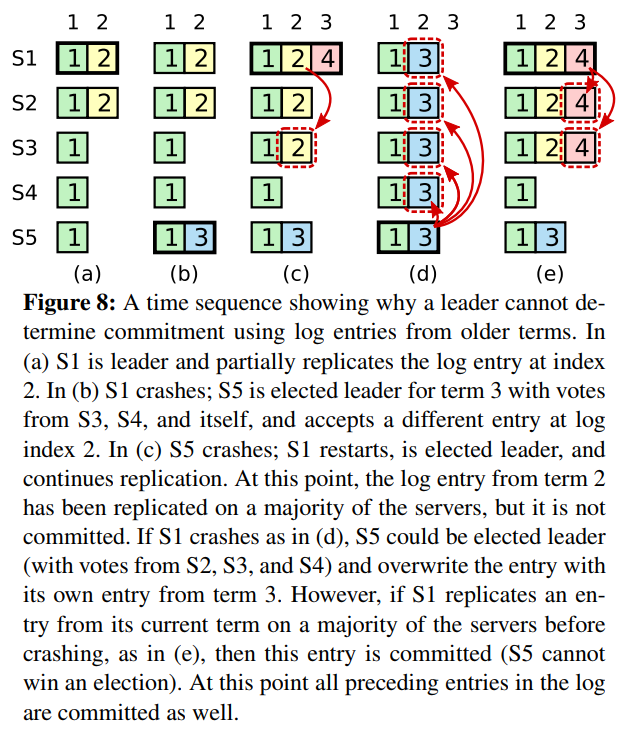
实现持久化,重启后能快速恢复。真正的实现将在每次更改时在磁盘写下 raft 的持久状态,并在重新启动后从磁盘中读取状态。lab 实现时在 Persister 中存储和恢复。currentTerm、votedFor、log[]
persist 和 readPersist:通过 labgob实现。
// save Raft's persistent state to stable storage,
// where it can later be retrieved after a crash and restart.
// see paper's Figure 2 for a description of what should be persistent.
// before you've implemented snapshots, you should pass nil as the
// second argument to persister.Save().
// after you've implemented snapshots, pass the current snapshot
// (or nil if there's not yet a snapshot).
func (rf *Raft) persist() {
// Your code here (2C).
// Example:
w := new(bytes.Buffer)
e := labgob.NewEncoder(w)
e.Encode(rf.currentTerm)
e.Encode(rf.votedFor)
e.Encode(rf.log)
raftstate := w.Bytes()
rf.persister.Save(raftstate, nil)
}
// restore previously persisted state.
func (rf *Raft) readPersist(data []byte) {
if data == nil || len(data) < 1 { // bootstrap without any state?
return
}
// Your code here (2C).
// Example:
r := bytes.NewBuffer(data)
d := labgob.NewDecoder(r)
var currentTerm, votedFor int
var logs []Entry
if d.Decode(¤tTerm) != nil ||
d.Decode(&votedFor) != nil ||
d.Decode(&logs) != nil {
log.Println("decode fail")
} else {
rf.currentTerm = currentTerm
rf.votedFor = votedFor
rf.log = logs
log.Println("restore success")
}
}
优化:避免 leader 每次只往前移动一位;若日志很长的话在一段时间内无法达到冲突位置。若 leader 发送心跳时接收到的回复是 false,leader 会减小发送的 AppendEntriesArgs 中的 rf.nextIndex,但是这种每次仅减小 1 的方案无法在有限的时间内确定跟其他服务器发生冲突的下标位置。
func (rf *Raft) AppendEntries(args *AppendEntriesArgs, reply *AppendEntriesReply) {
// Your code here (2A, 2B).
rf.mu.Lock()
defer rf.mu.Unlock()
if args.Term > rf.currentTerm { // all server
rf.state = Follower
rf.currentTerm = args.Term
rf.votedFor = -1
rf.persist()
}
if args.Term < rf.currentTerm {
reply.Success = false
reply.Term = rf.currentTerm
} else if len(rf.log)-1 < args.PrevLogIndex ||
rf.log[args.PrevLogIndex].Term != args.PrevLogTerm {
log.Println(rf.me, "mismatch", "len(rf.log)", len(rf.log), "args.PrevLogIndex", args.PrevLogIndex)
reply.Success = false
reply.Term = rf.currentTerm
timeout := time.Duration(250+rand.Intn(300)) * time.Millisecond
rf.expiryTime = time.Now().Add(timeout)
if args.PrevLogIndex > len(rf.log)-1 {
reply.ConflictIndex = len(rf.log)
reply.ConflictTerm = -1
} else {
reply.ConflictTerm = rf.log[args.PrevLogIndex].Term
reply.ConflictIndex = 1
for i := args.PrevLogIndex - 1; i >= 0; i-- {
if rf.log[i].Term != reply.ConflictTerm {
reply.ConflictIndex += i
break
}
}
}
} else {
reply.Success = true
reply.Term = rf.currentTerm
timeout := time.Duration(250+rand.Intn(300)) * time.Millisecond
rf.expiryTime = time.Now().Add(timeout)
// // delete
// rf.log = rf.log[:args.PrevLogIndex+1]
// // append
// rf.log = append(rf.log, args.Entries...)
insertIndex := args.PrevLogIndex + 1
argsLogIndex := 0
for {
if insertIndex >= len(rf.log) ||
argsLogIndex >= len(args.Entries) ||
rf.log[insertIndex].Term != args.Entries[argsLogIndex].Term {
break
}
insertIndex++
argsLogIndex++
}
// for _, e := range rf.log {
// log.Print(e)
// }
// for _, e := range args.Entries {
// log.Print(e)
// }
if argsLogIndex < len(args.Entries) {
rf.log = append(rf.log[:insertIndex], args.Entries[argsLogIndex:]...)
rf.persist()
}
if args.LeaderCommit > rf.commitIndex {
rf.commitIndex = int(math.Min(float64(args.LeaderCommit), float64(len(rf.log)-1)))
log.Println(rf.me, "follower update commitIndex", "args.LeaderCommit", args.LeaderCommit, "len(rf.log)", len(rf.log), "rf.commitIndex", rf.commitIndex)
}
}
}
// 修改前
// if args.PrevLogIndex > 0 {
// rf.nextIndex[i] = args.PrevLogIndex
// }
// 修改后
if reply.ConflictTerm >= 0 {
lastIndex := -1
for i := len(rf.log) - 1; i >= 0; i-- {
if rf.log[i].Term == reply.ConflictTerm {
lastIndex = i
break
}
}
if lastIndex >= 0 {
rf.nextIndex[i] = lastIndex + 1
} else {
rf.nextIndex[i] = reply.ConflictIndex
}
} else {
rf.nextIndex[i] = reply.ConflictIndex
}
实验结果

文章来源:https://blog.csdn.net/qq_43680965/article/details/134973681
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【ARM 嵌入式 编译系列 2.2 -- GCC 编译参数学习 assembler-with-cpp 使用介绍】
- 分享3种常用的前端埋点方式
- 信息学奥赛一本通1015:计算并联电阻的阻值
- Spring之事务
- WPF+Halcon 培训项目实战(6):目标匹配助手
- 目标检测YOLO系列从入门到精通技术详解100篇-【目标检测】机器视觉(基础篇)(十四)
- 阿里云服务器CPU内存配置怎么选择?
- 《WebKit 技术内幕》之九(4): JavaScript引擎
- adb wifi 远程调试 安卓手机 命令
- Appium —— 初识移动APP自动化测试框架Appium