基于深度学习的安全帽检测识别系统(含UI界面、yolov5、Python代码、数据集)

项目介绍
项目中所用到的算法模型和数据集等信息如下:
算法模型:
? ? yolov5
? ? yolov5主要包含以下几种创新:
? ? ? ? 1. 添加注意力机制(SE、CBAM、CA等)
? ? ? ? 2. 修改可变形卷积(DySnake-主干c3替换、DySnake-所有c3替换)
数据集:
? ? 网上下载的数据集,大约5000张左右,详细介绍见数据集介绍部分。
以上是本套代码的整体算法架构和对目标检测模型的修改说明,这些模型修改可以为您的 毕设、作业等提供创新点和增强模型性能的功能 。
如果要是需要更换其他的检测模型,请私信。
注:本项目提供所用到的所有资源,包含 环境安装包、训练代码、测试代码、数据集、视频文件、 界面UI文件等。
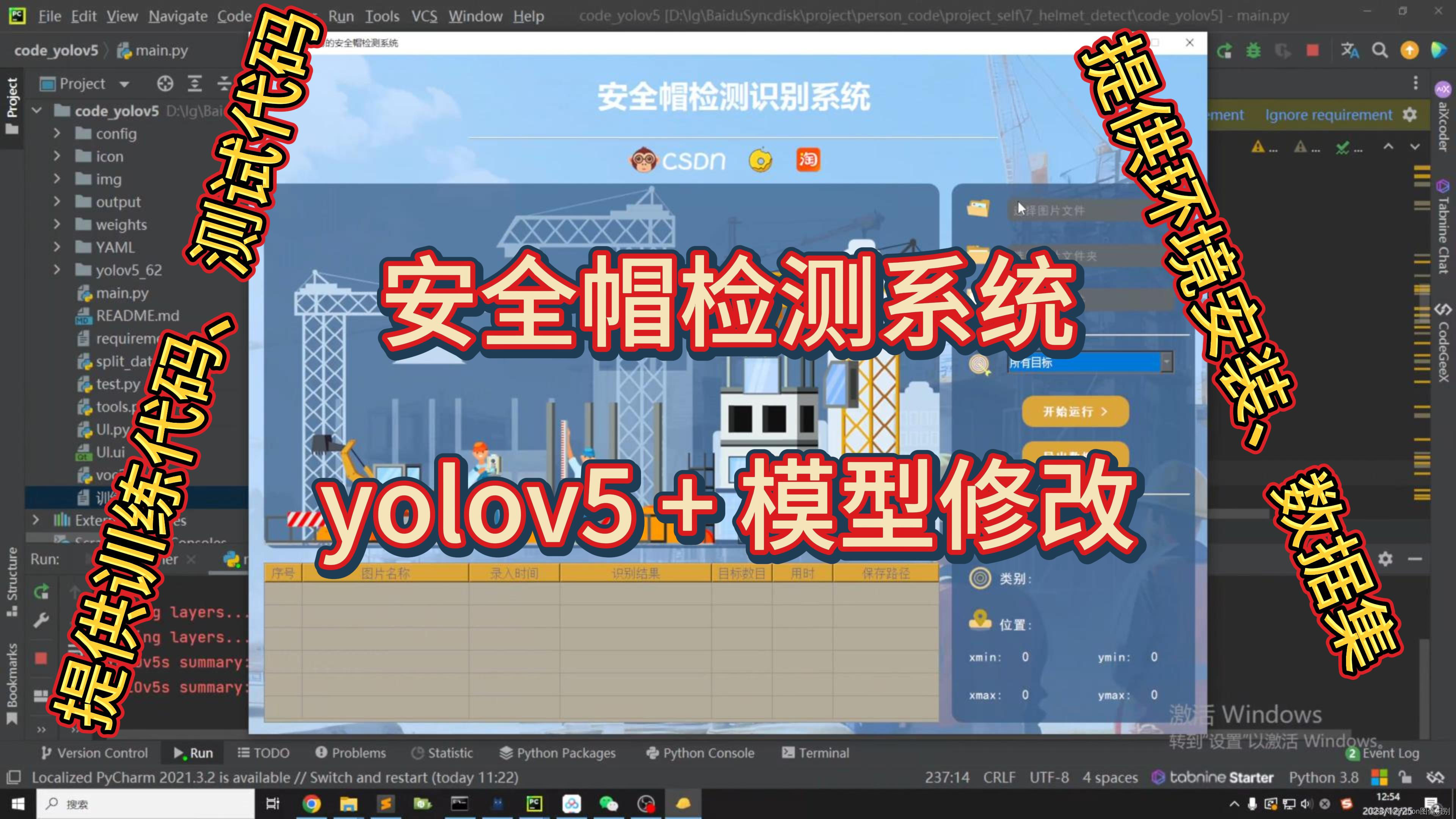
项目简介
在本文中,我们将详细介绍如何利用深度学习中的YOLOv5算法来实现对是否佩戴安全帽的检测,并结合PyQt5设计了一个简约而强大的系统UI界面。通过该界面,您可以轻松选择自己的视频文件或图片文件进行检测,并且还能够根据需要替换训练好的yolov5模型,以适应不同的数据检测需求。
我们的系统界面不仅外观优美,而且具备出色的检测精度和强大的功能。它支持多目标实时检测,并允许您自由选择感兴趣的检测目标。
本博文提供了完整的Python程序代码和使用教程,非常适合新入门者参考学习。您可以通过文末的下载链接获取完整的代码资源文件。以下是本博文的目录大致内容:
目录
效果展示:
功能:
1. 支持单张图片识别
2. 支持遍历文件夹识别
3. 支持识别视频文件
4. 支持结果导出(xls、csv两种格式)
5. 支持切换检测到的目标
🌟一、环境安装
本项目提供所有需要的环境安装包(python、pycharm、cuda、torch等),可以直接按照视频讲解进行安装。具体的安装流程见此视频:视频链接
环境安装视频是以车牌项目为例进行讲解的,但是可以适用于任何项目。
视频快进到 3:18 - 21:17,这段时间讲解的是环境安装,可直接快进到此处观看。
环境安装包可通过百度网盘下载:
链接:https://pan.baidu.com/s/17SZHeVZrpXsi513D-6KmQw?pwd=a0gi
提取码:a0gi
–来自百度网盘超级会员V6的分享
上面这个方法,是比较便捷的安装方式(省去了安装细节),按照我的视频步骤和提供的安装包安装即可,如果要是想要多学一点东西,可以按照下面的安装方式走一遍,会更加熟悉。
环境安装方法2:
追求快速安装环境的,只看上面即可!!!
下面列出了5个步骤,是完全从0开始安装(可以理解为是一台新电脑,没有任何环境),如果某些步骤已经安装过的可以跳过。下面的安装步骤带有详细的视频讲解和参考博客,一步一步来即可。另外视频中讲解的安装方法是通用的,可用于任何项目。
按照上面的步骤安装完环境后,就可以直接运行程序,看到效果了。
🌟二、数据集介绍
我们使用的数据集是从网上下载的,其中大多数场景都是实际的工地作业场景。该数据集共有约5000张图像,包含两个类别:helmet(佩戴安全帽)和head(未佩戴安全帽)。这些数据已经转换为YOLO格式,并且已经按照train、val和test的划分进行了准备,因此可以直接拿来使用。
这个数据集采集了各种不同的场景,如建筑工地、工厂车间等,并包含了不同角度、光照条件和人员密集度的图像。这样的多样性使得模型能够在各种真实环境中进行准确的安全帽检测。
为了方便使用,数据集已经进行了标注,并且按照训练集、验证集和测试集的划分进行了组织。您可以直接使用这些数据集进行模型的训练和评估。
下面是一些数据集图片的截图,展示了不同场景下的安全帽和未佩戴安全帽的示例图像,以帮助您更好地了解数据集的内容和质量。

🌟三、 目标检测介绍
yolov5相关介绍
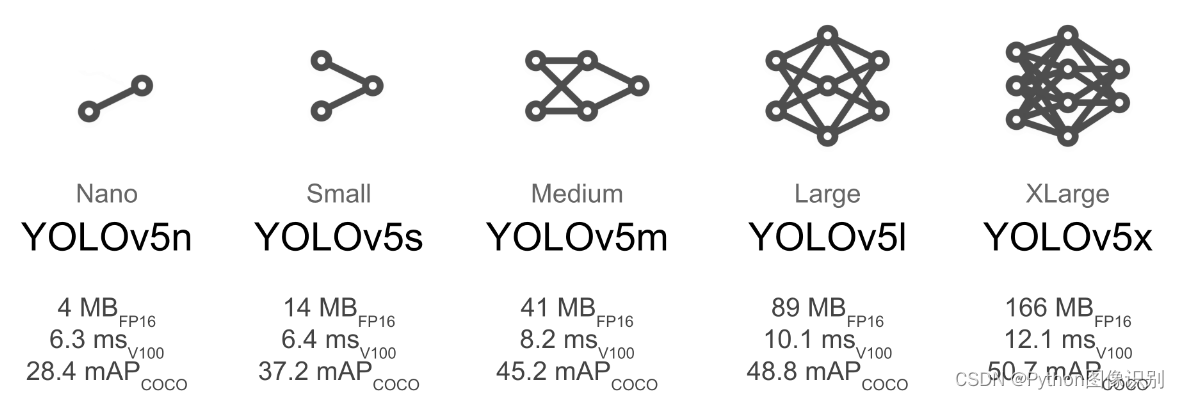
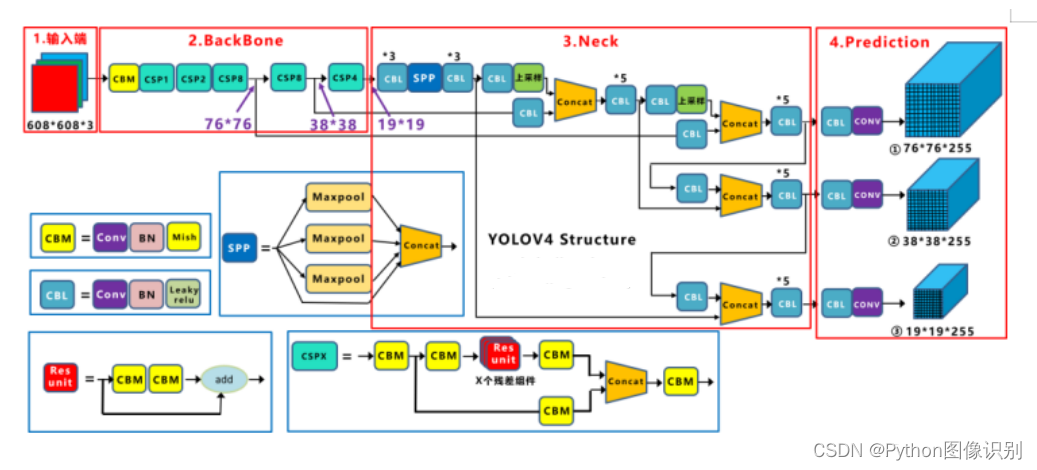
1. YOLOv5的网络结构
YOLOV5有YOLOv5n,YOLOv5s,YOLOv5m,YOLOV5l、YOLO5x五个版本。这个模型的结构基本一样,不同的是deth_multiole模型深度和width_multiole模型宽度这两个参数。就和我们买衣服的尺码大小排序一样,YOLOV5n网络是YOLOV5系列中深度最小,特征图的宽度最小的网络。其他的三种都是在此基础上不断加深,不断加宽。不过最常用的一般都是yolov5s模型。
yolov5s 网络架构如下:
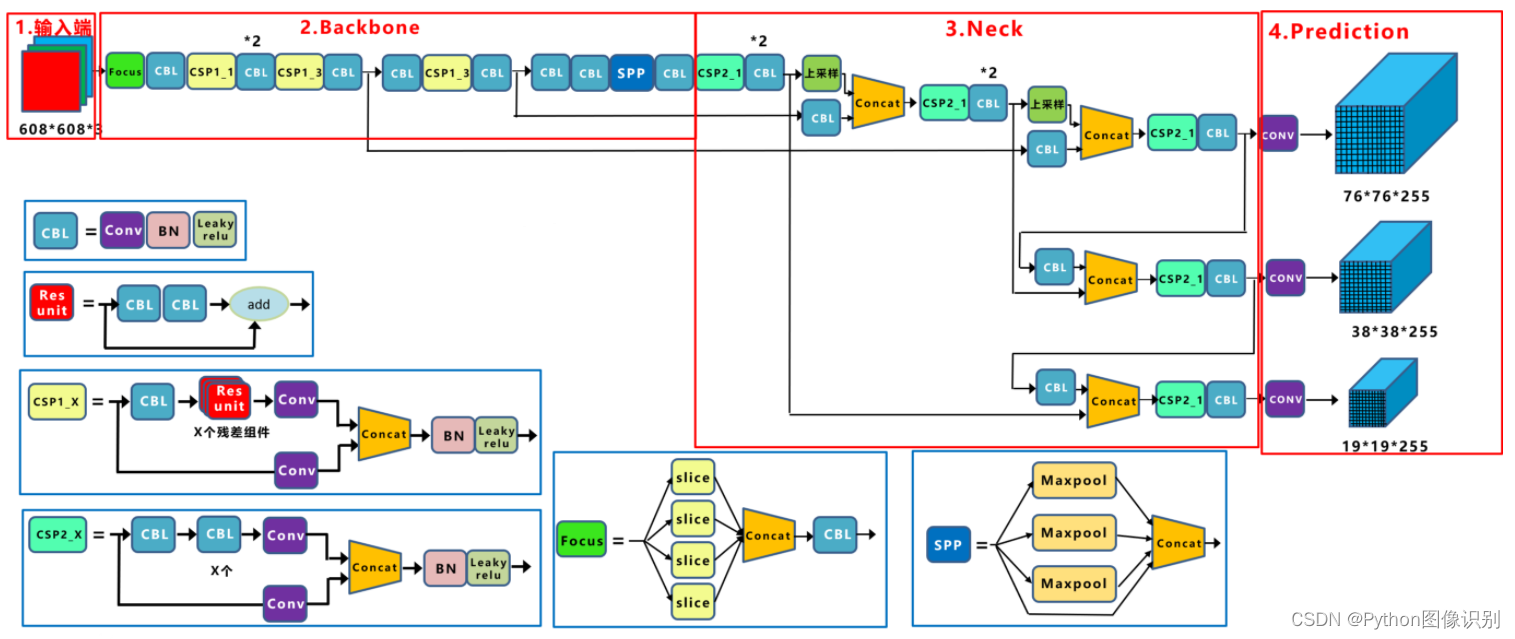
(1)输入端: Mosaic数据增强、自适应锚框计算、自适应图片缩放
(2)Backbone: Focus结构、CSP结构
(3)Neck: FPN+PAN结构
(4)Prediction: GIOU_Loss
基本组件:
- Focus: 基本上就是YOLO v2的passthrough.
- CBL: 由Conv+Bn+Leaky_relu激活函数三者组成
- CSP1 X: 借鉴CSPNet网络结构,由三个卷积层和X个Res unint模块Concate组成
- CSP2 X: 不再用Res unint模块,而是改为CBL。
- SPP: 采用1x1,5x5,9x9,13x13的最大池化的方式,进行多尺度融合
2. 输入端
(1)Mosaic数据增强
YOLO5在输入端采用了 Mosaic数据增强 ,Mosaic 数据增强算法将多张图片按照一定比例组合成一张图片,使模型在更小的范围内识别目标。Mosaic 数据增算法参考 CutMix数增强算法。CutMix数据增强算法使用两张图片进行拼接,而 Mosaic 数据增强算法一般使用四张进行拼接,但两者的算法原理是非常相似的。

Mosaic数据增强的主要步骤为:
(1) 随机选取图片拼接基准点坐标 (xc,yc),另随机选取四张图片。
(2)四张图片根据基准点,分别经过尺寸调整和比例缩放后,放置在指定尺寸的大图的左上,右上,左下,右下位置。
(3) 根据每张图片的尺寸变换方式,将映射关系对应到图片标签上。
(4)依据指定的横纵坐标,对大图进行拼接。处理超过边界的检测框坐标。
采用Mosaic数据增强的方式有几个优点:
(1)丰富数据集: 随机使用4张图像,随机缩放后随机拼接,增加很多小目标,大大增加了数据多样性
(2)增强模型鲁棒性: 混合四张具有不同语义信息的图片,可以让模型检测超出常规语境的目标.
(3)加强批归一化层(Batch Normalization) 的效果: 当模型设置 BN 操作后,训练时会尽可能增大批样本总量 (BatchSize),因为BI 原理为计算每一个特征层的均值和方差,如果批样本总量越大,那么 BN 计算的均值和方差就越接近于整个数据集的均值和方差,效果越好。
(4)Mosaic 数据增强算法有利于提升小目标检测性能: Mosaic 数据增强图像由四张原始图像拼接而成,这样每张图像会有更大概率有含小目标,从而提升了模型的检测能力。
(2) 自适应锚框计算
**之前我们学的 YOLOV3、YOLv4,对于不同的数据集,都会计算先验框 anchor。**然后在训练时,网络会在 anchor 的基础上进行预测,输出预测框,再和标签框进行对比,最后就进行梯度的反向传播。
在YOLOV3、YOLOV4 中,训练不同的数据集时,是使用单独的脚本进行初始锚框的计算,在 YOLOV5 中,则是将此功能嵌入到整个训练代码里中。所以在每次训练开始之前,它都会根据不同的数据集来自适应计算 anchor。
自适应的计算具体过程:
? ①获取数据集中所有目标的宽和高
?②将每张图片中按照等比例缩放的方式到 resize 指定大小,这里保证宽高中的最大值符合指定大小。
?③将 bboxes 从相对坐标改成绝对坐标,这里乘以的是缩放后的宽高。
?④筛选 bboxes,保留宽高都大于等于两个像素的 bboxes.
?⑤使用 k-means 聚类三方得到n个 anchors,与YOLOv3、YOLOv4 操作一样
?⑥使用遗传算法随机对 anchors 的宽高进行变异。倘若变异后的效果好,就将变异后的结果赋值给 anchors;如果变异后效果变差就跳过,默认变异1000次。这里是使用 anchor fitness 方法计算得到的适应度 fitness,然后再进行评估。
(3)自适应图片缩放
在常用的目标检测算法中,不同的图片长宽也不相同,因此常用的方式是将原始图片统一缩放到一个标准尺寸,在送入检测网络中。
比如yolo算法中常用416416,608608等尺寸,比如对下面800*600的图像进行缩放。

但yolov5代码中对此进行了改进,也是yolov5推理速度能够很快的一个不错的trick。
作者认为,在项目实际使用时,很多图片的长宽比不同,因此缩放填充后,两端的黑边大小都不同,而如果填充的比较多,则存在信息冗余,影响推理速度。
因此在yolov5的代码中datasets.py的letterbox函数进行了修改,对原始图像自适应的添加最少的黑边。

图像高度上两端的黑边变少了,在推理时,计算量也会减少,即目标检测速度会得到提升。
通过这种简单的改进,推理速度得到了37%的提升,可以说效果很明显。
3. Backbone
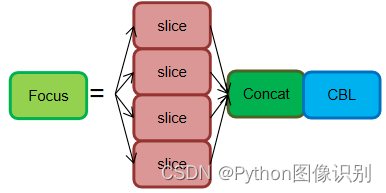
(1)Focus结构
Focus模块在YOLOV5中是图片进入Backbone前,对图片进行切片操作,具体操作是在一张图片中每隔一个像素拿到一个值,类似于邻近下采样,这样就拿到了四张图片,四张图片互补,长得差不多,但是没有信息丢失,这样一来,将W、H信息就集中到了通道空间,输入通道扩充了4倍,即拼接起来的图片相对于原先的RGB三通道模式变成了12个通道,最后将得到的新图片再经过卷积操作,最终得到了没有信息丢失情况下的二倍下采样特征图。
以YOLOV5s为例,原始的640 x 640 x 3的图像输入Focus结构,采用切片操作,先变成320 * 320 12的特征图,再经过一次卷积操作
最终变成320 x 320 x 32的特征图
切片操作如下:
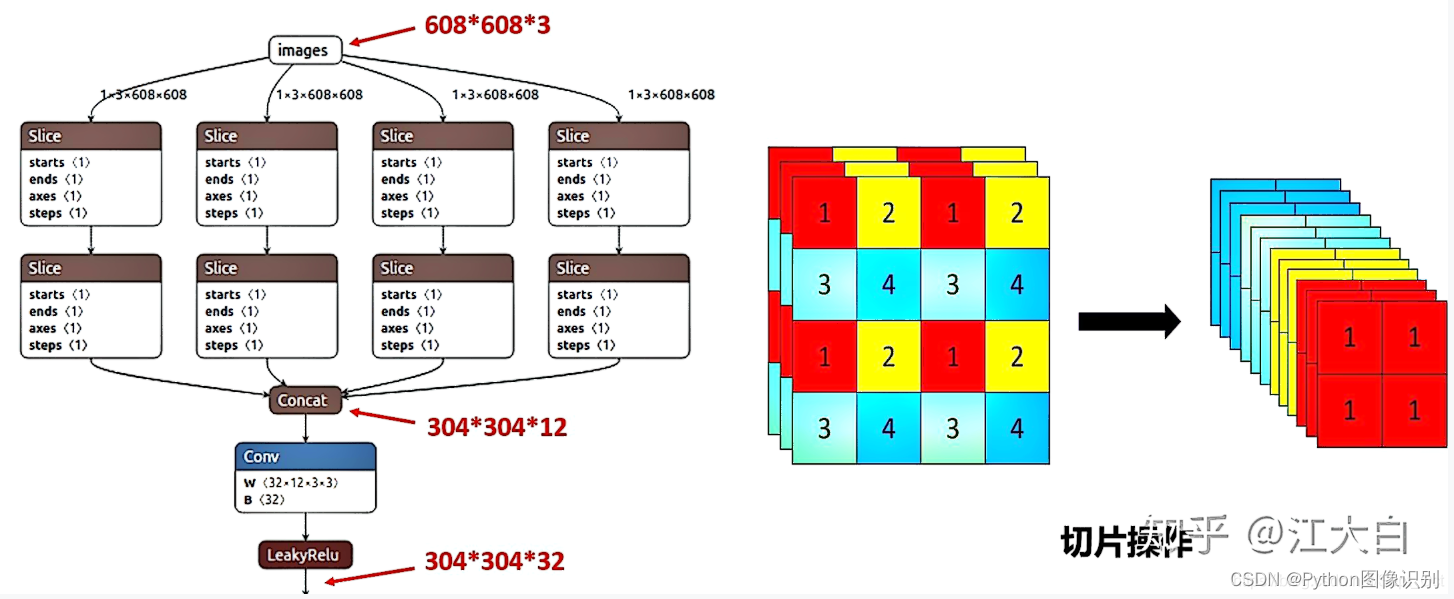
作用: 可以使信息不丢失的情况下提高计算力
不足: Focus 对某些设备不支持目不友好,开销很大,另外切片对不产的话模型就崩了
后期改进: 在新版中,YOLOV5 将Focus 模块替换成了一 6x6 的券积层、两者的计算量是等价的,但是对工一些 GPU 设备,使用6x 6 的卷积会更加高效。
(2)CSP结构
yolov4网络结构中,借鉴了CSPNet的设计思路,在主干网络中设计了CSP结构。
yolov5与yolov4不同点在于,yolov4中只有主干网络使用了CSP结构。 而yolov5中设计了两种CSP结构,以yolov5s网络为例,CSP1_X结构应用于Backbone主干网络,另一种CSP2_X结构则应用于Neck中。
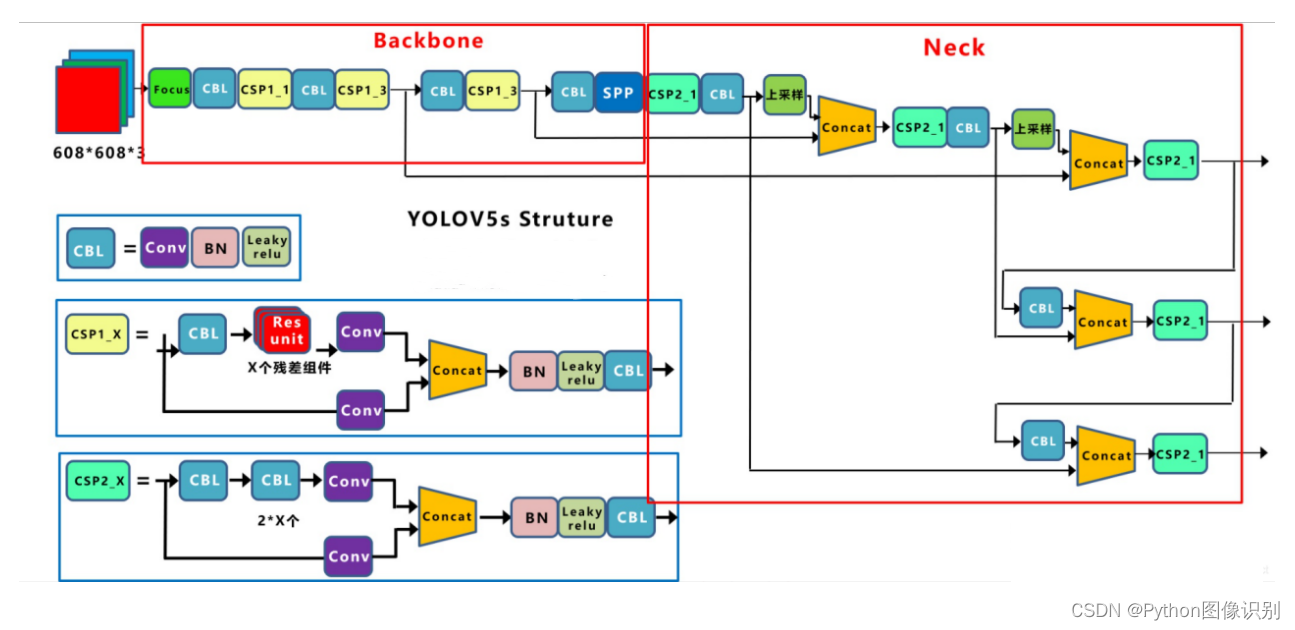
4. Neck
YOLOv5现在的Neck和YOLOV4中一样,都采用FPN+PAN的结构。但是在它的基础上做了-些改进操作: YOLOV4的Neck结构中,采用的都是普通的卷积操作,而YOLOV5的Neck中,采用CSPNet设计的CSP2结构,从而加强了网络特征融合能力。
结构如下图所示,FPN层自顶向下传达强语义特征,而PAN塔自底向上传达定位特征:
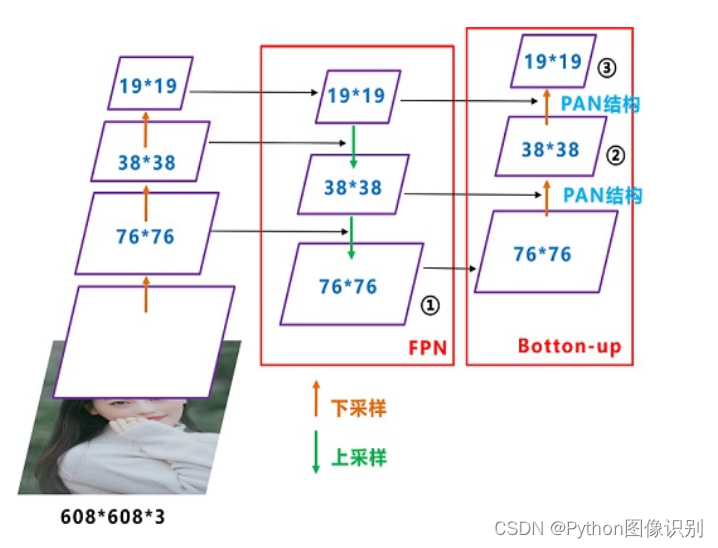
5. Head
(1) NMS非极大值抑制
NMS 的本质是搜索局部极大值,抑制非极大值元素.
非极大值抑制,主要就是用来抑制检测时几余的框。因为在目标检测中,在同一目标的位置上会产生大量的候选框,这些候选框相互之间可能会有重叠,所以我们需要利用非极大值抑制找到最佳的目标边界框,消除几余的边界框。
算法流程:
? 1.对所有预测框的置信度降序排序
? 2.选出置信度最高的预测框,确认其为正确预测,并计算他与其他预测框的 IOU
? 3.根据步骤2中计算的IOU 去除重鲁度高的,IOU > threshold 值就直接删除
? 4.剩下的预测框返回第1步,直到没有剩下的为止
SoftNMS:
当两个目标靠的非常近时,置信度低的会被置信度高的框所抑制,那么当两个目标靠的十分近的时候就只会识别出一个 BBox。为了解决这个问题,可以使用 softNMS。
它的基本思想是用稍低一点的分数来代替原有的分数,而不是像 NMS 一直接置零。

6、训练策略
(1) 多尺度训练 (Multi-scale training) 如果网络的输入是416 x 416。那么训练的时候就会从 0.5 x 416 到 1.5 x 416 中任意取值但所取的值都是32的整数倍。
(2) 训练开始前使用 warmup 进行训练 在模型预训练阶段,先使用较小的学习率训练一些epochs或者steps (如4个 epoch 或10000step ) 再修改为预先设置的学习率进行训练。
(3) 使用了 cosine 学习率下降策略 (Cosine LR scheduler)
(4)采用了 EMA 更新权重(Exponential Moving Average) 相当于训练时给参数赋予一个动量,这样更新起来就会更加平滑
(5) 使用了 amp 进行混合精度训练 (Mixed precision) 能够减少显存的占用并且加快训练速度,但是需要 GPU 支持
四、 yolov5训练步骤
此代码的训练步骤极其简单,不需要修改代码,直接通过cmd就可以命令运行,命令都已写好,直接复制即可,命令如下图:
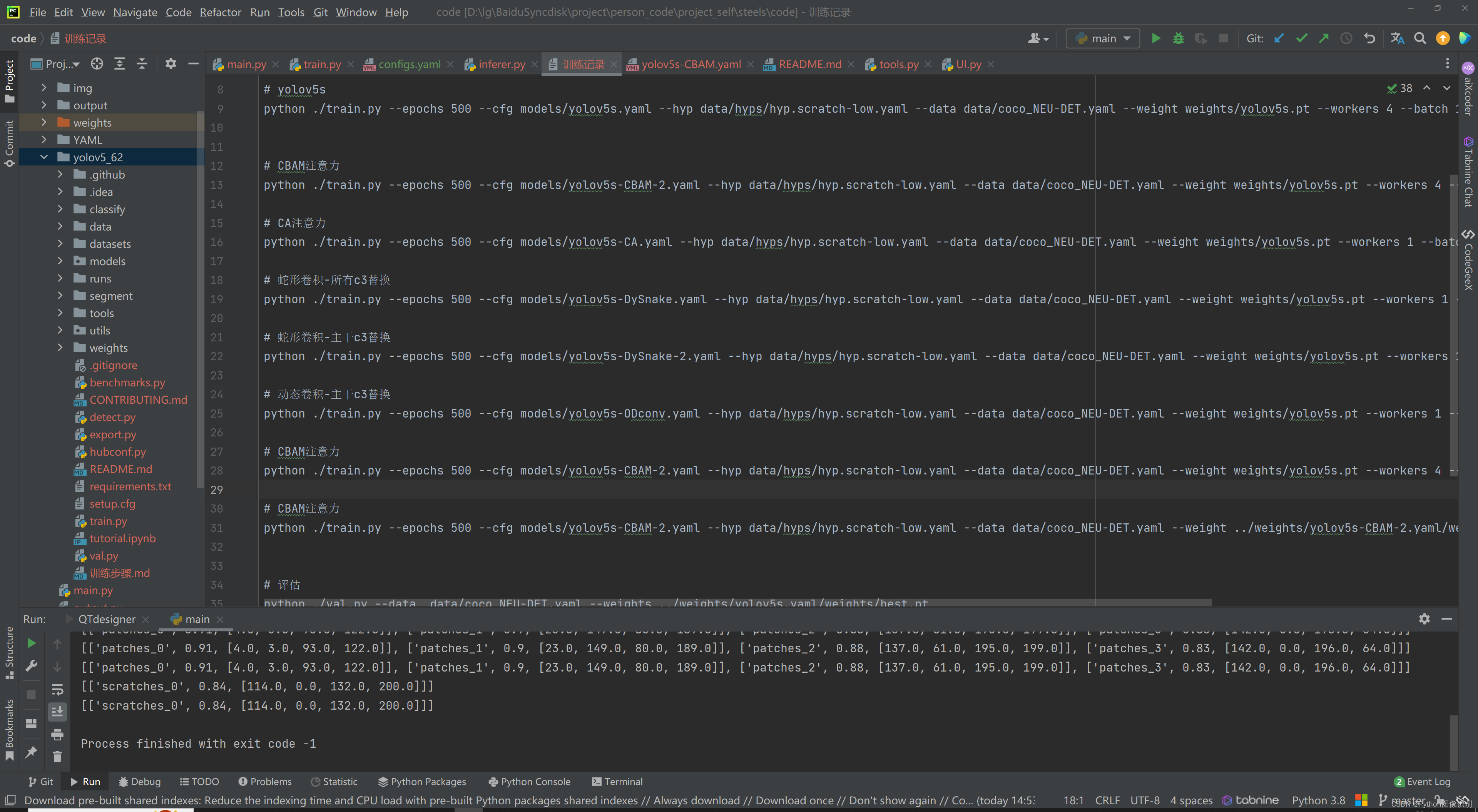
下面这条命令是 训练 添加 CBAM 注意力机制的命令,复制下来,直接就可以运行,看到训练效果(需要将coco_NEU-DET.yaml修改为自己的数据集的yaml文件 VOC_helmet.yaml,这个在代码里都已给写好了,无需自己修改)。
python ./train.py --epochs 500 --cfg models/yolov5s-CBAM-2.yaml --hyp data/hyps/hyp.scratch-low.yaml --data data/coco_NEU-DET.yaml --weight weights/yolov5s.pt --workers 4 --batch 16
执行完上述命令后,即可完成训练,训练过程如下:
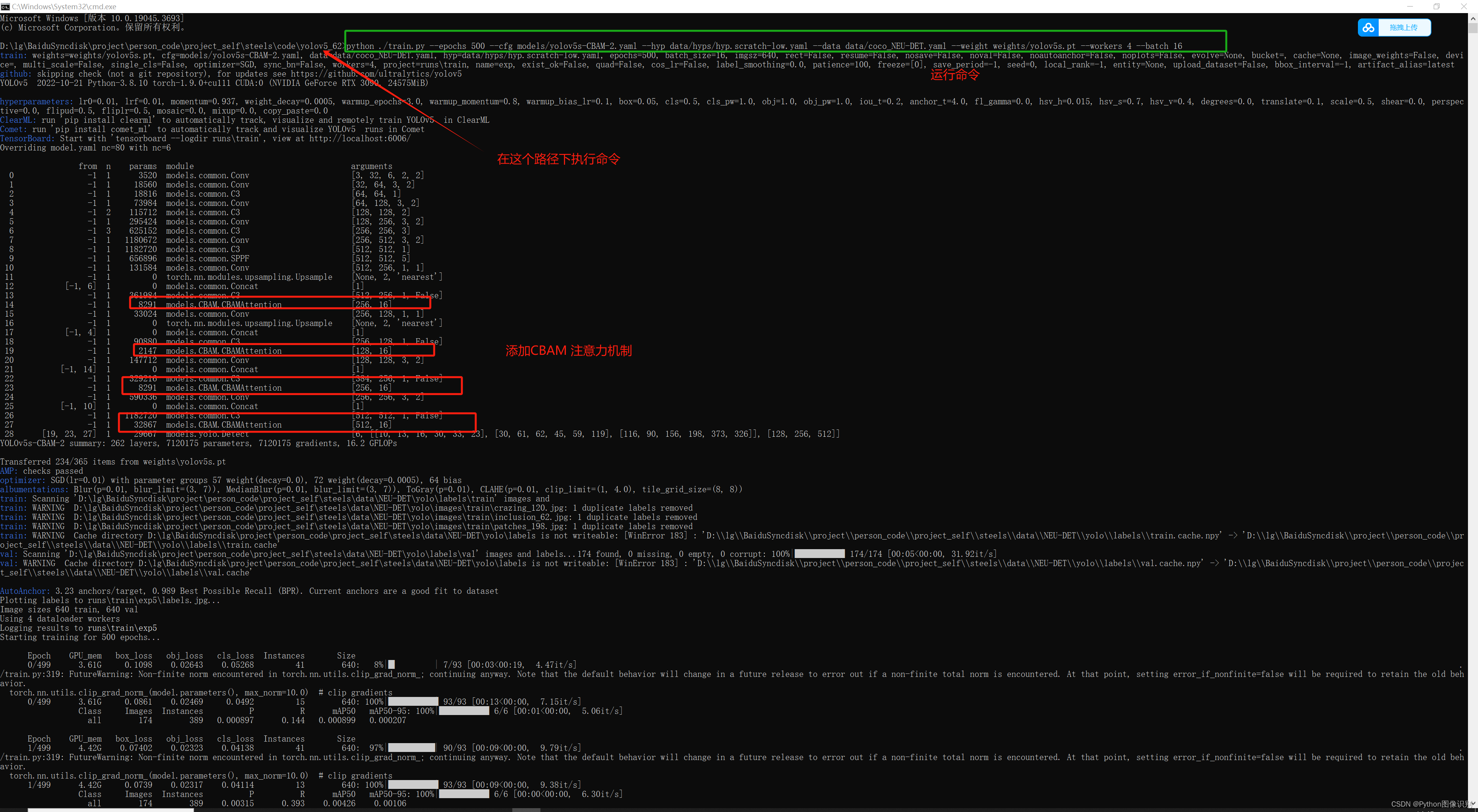
下面是对命令中各个参数的详细解释说明:
-
python: 这是Python解释器的命令行执行器,用于执行后续的Python脚本。 -
./train.py: 这是要执行的Python脚本文件的路径和名称,它是用于训练目标检测模型的脚本。 -
--epochs 500: 这是训练的总轮数(epochs),指定为500,表示训练将运行500个轮次。 -
--cfg models/yolov5s-CBAM-2.yaml: 这是YOLOv5模型的配置文件的路径和名称,它指定了模型的结构和参数设置。 -
--hyp data/hyps/hyp.scratch-low.yaml: 这是超参数文件的路径和名称,它包含了训练过程中的各种超参数设置,如学习率、权重衰减等。 -
--data data/coco_NEU-DET.yaml: 这是数据集的配置文件的路径和名称,它指定了训练数据集的相关信息,如类别标签、图像路径等。 -
--weight weights/yolov5s.pt: 这是预训练权重文件的路径和名称,用于加载已经训练好的模型权重以便继续训练或进行迁移学习。 -
--workers 4: 这是用于数据加载的工作进程数,指定为4,表示使用4个工作进程来加速数据加载。 -
--batch 16: 这是每个批次的样本数,指定为16,表示每个训练批次将包含16个样本。
通过运行上面这个命令,您将使用YOLOv5模型对目标检测任务进行训练,训练500个轮次,使用指定的配置文件、超参数文件、数据集配置文件和预训练权重。同时,使用4个工作进程来加速数据加载,并且每个训练批次包含16个样本。
五、 yolov5评估步骤
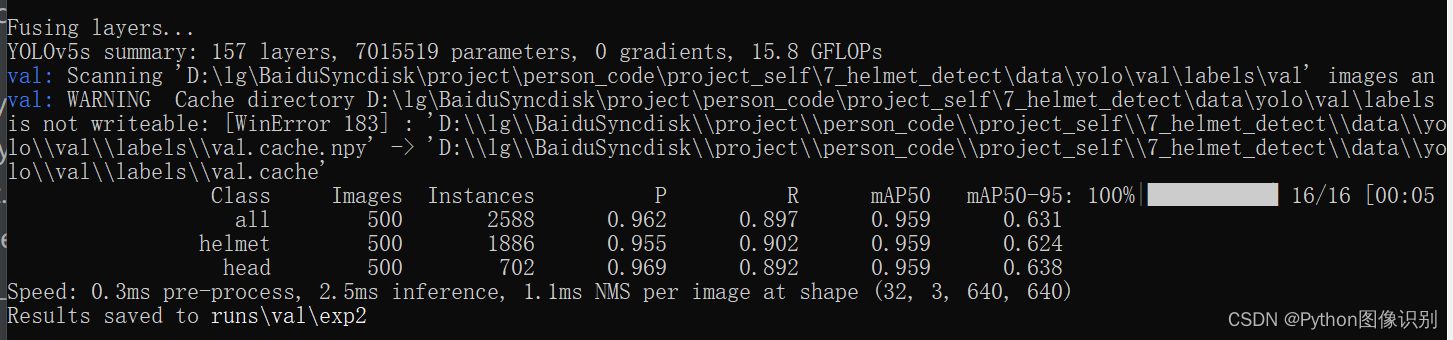
评估步骤同训练步骤一样,执行1行语句即可,注意--weights需要变为自己想要测试的模型路径。
python ./val.py --data data/VOC_helmet.yaml --weights ../weights/yolov5s.yaml/weights/best.pt
评估结果如下:
六、 训练结果
我们每次训练后,会在 run/train 文件夹下出现一系列的文件,如下图所示:
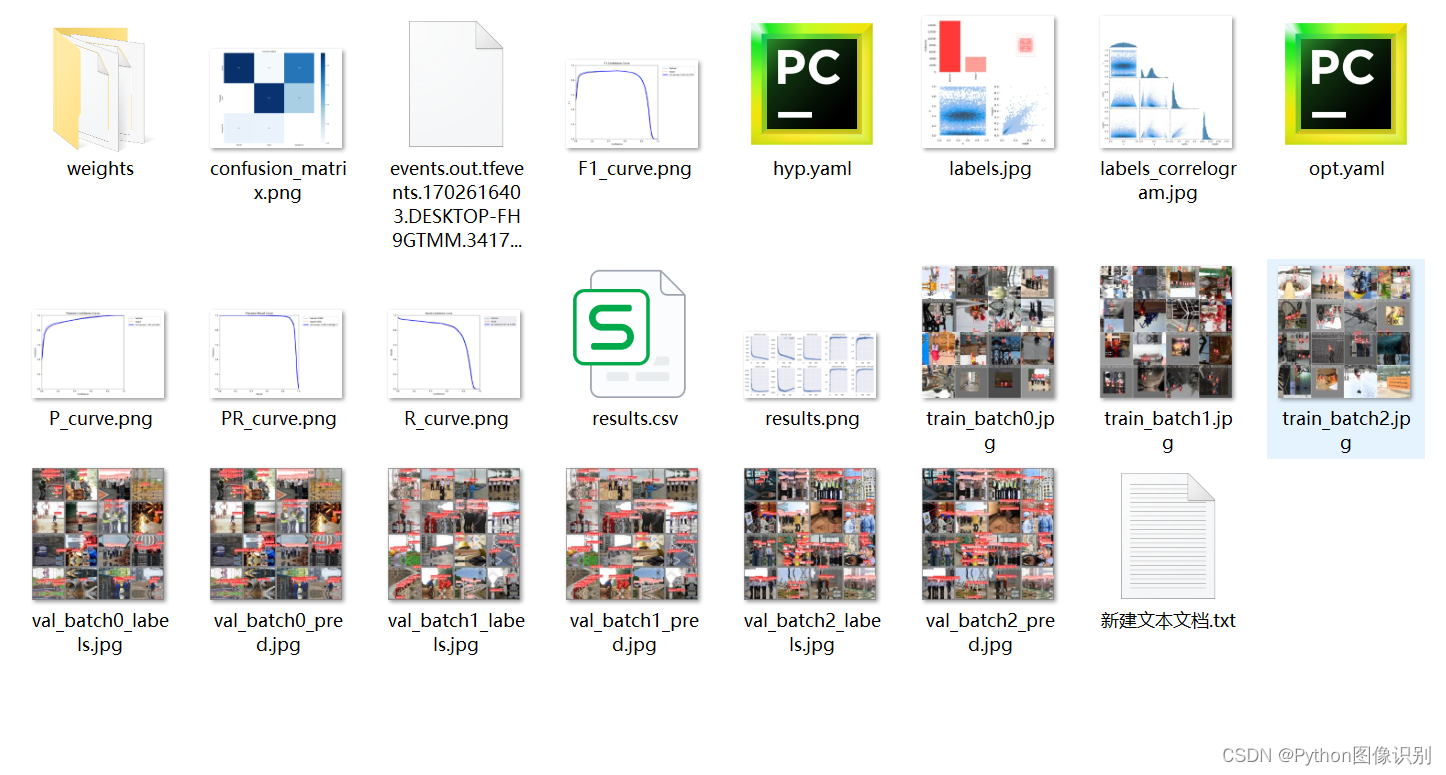
🌟下载链接
? ?该代码采用Pycharm+Python3.8开发,经过测试能成功运行,运行界面的主程序为main.py,提供用到的所有程序。为确保程序顺利运行,请按照requirements.txt配置Python依赖包的版本。Python版本:3.8,为避免出现运行报错,请勿使用其他版本,详见requirements.txt文件;
? ? 若您想获得博文中涉及的实现完整全部程序文件(包括训练代码、测试代码、训练数据、测试数据、视频,py、 UI文件等,如下图),这里已打包上传至博主的面包多平台,可通过下方项目讲解链接中的视频简介部分下载,完整文件截图如下:
 ![
![
项目讲解链接:B站
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 利用Jmeter做接口测试(功能测试)全流程分析!
- YOLOv8改进 | 检测头篇 | CLLAHead分布焦点检测头(全网独创首发)
- Hive入门+部署
- 阿里云服务器Alibaba Cloud Linux 3镜像版本大全说明
- Matplotlib_艺术画笔见乾坤
- 视频批量处理:随机分割方法,创新剪辑方式
- git 使用场景 本地分支 推送到 远程分支
- 执行计划EXPLAIN详解
- Apache Doris 入门 10 问
- 使用java消费贷计算