中文词向量训练-案例分析
发布时间:2024年01月20日
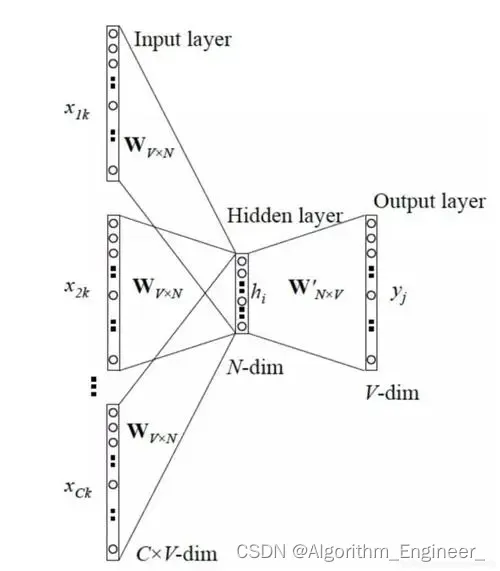
1 数据预处理,解析XML文件并分词
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# process_wiki_data.py 用于解析XML,将XML的wiki数据转换为text格式
import logging
import os.path
import sys
from gensim.corpora import WikiCorpus
import jieba
import jieba.analyse
import codecs
def process_wiki_text(origin_file, target_file):
with codecs.open(origin_file, 'r', 'utf-8') as inp, codecs.open(target_file,'w','utf-8') as outp:
line = inp.readline()
line_num = 1
while line:
# print('---- processing ', line_num, 'article----------------')
line_seg = " ".join(jieba.cut(line))
# print(len(line_seg))
outp.writelines(line_seg)
line_num = line_num + 1
line = inp.readline()
# if line_num == 101:
# break
inp.close()
outp.close()
if __name__ == '__main__':
# sys.argv[0]获取的是脚本文件的文件名称
program = os.path.basename(sys.argv[0])
# sys.argv[0]获取的是脚本文件的文件名称
logger = logging.getLogger(program)
# format: 指定输出的格式和内容,format可以输出很多有用信息,
# %(asctime)s: 打印日志的时间
# %(levelname)s: 打印日志级别名称
# %(message)s: 打印日志信息
logging.basicConfig(format='%(asctime)s: %(levelname)s: %(message)s')
logging.root.setLevel(level=logging.INFO)
# 打印这是一个通知日志
logger.info("running %s" % ' '.join(sys.argv))
# check and process input arguments
if len(sys.argv) < 3:
print(globals()['__doc__'] % locals())
sys.exit(1)
inp, outp = sys.argv[1:3]
# inp:输入的数据集
# outp:从压缩文件中获得的文本文件
space = " "
i = 0
output = open(outp, 'w', encoding='utf-8')
wiki = WikiCorpus(inp, lemmatize=False, dictionary={})
for text in wiki.get_texts():
output.write(space.join(text) + "\n")
i = i + 1
if i % 200000 == 0:
logger.info("Saved " + str(i) + " articles")
# break
output.close()
logger.info("Finished Saved " + str(i) + " articles")
process_wiki_text('wiki.zh.txt', 'wiki.zh.text.seg')
2 模型训练,使用gensim工具训练词向量
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# train_word2vec_model.py用于训练模型
import logging
import os.path
import sys
import multiprocessing
import gensim
from gensim.models import Word2Vec
from gensim.models.word2vec import LineSentence
if __name__ == '__main__':
if len(sys.argv) < 4:
print(globals()['__doc__'] % locals())
sys.exit(1)
# inp:分好词的文本 # outp1:训练好的模型 # outp2:得到的词向量
inp, outp1, outp2 = sys.argv[1:4]
"""
LineSentence(inp):格式简单:一句话=一行; 单词已经过预处理并被空格分隔。
size:是每个词的向量维度; window:是词向量训练时的上下文扫描窗口大小,窗口为5就是考虑前5个词和后5个词;
min-count:设置最低频率,默认是5,如果一个词语在文档中出现的次数小于5,那么就会丢弃;
workers:是训练的进程数(需要更精准的解释,请指正),默认是当前运行机器的处理器核数。这些参数先记住就可以了。
sg ({0, 1}, optional) – 模型的训练算法: 1: skip-gram; 0: CBOW
alpha (float, optional) – 初始学习率 iter (int, optional) – 迭代次数,默认为5
"""
lineSentence = LineSentence(inp, max_sentence_length=10000)
model = Word2Vec(lineSentence, size=100, window=5, min_count=5, workers=multiprocessing.cpu_count())
model.save(outp1)
model.wv.save_word2vec_format(outp2, binary=False)
4 使用模型,查看训练向量的结果
# coding:utf-8
import gensim
model = gensim.models.Word2Vec.load("wiki.zh.text.model")
count = 0
for word in model.wv.index2word:
count += 1
if count == 20:
print(word, model[word])
break
result = model.most_similar(u"分词")
for e in result:
print(e)
文章来源:https://blog.csdn.net/qq_37977007/article/details/135686257
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- C++中的max函数:实现与应用
- 机器人中的数值优化之牛顿共轭梯度法
- 【第十二课】KMP算法(acwing-831 / c++代码 / 思路 / 视频+博客讲解推荐)
- Python selenium模块的安装和配置教程
- 实时渲染 -- 几何(Geometry)
- MyBatis——MyBatis的ORM映射和MyBatis的配置文件升级
- 视频剪辑技巧:如何批量制作出让人印象深刻的画中画视频
- ROS OpenCV 图像预处理
- R语言中的函数28:Reduce(), Filter(), Find(), Map(), Negate(), Position()
- 常用正则表达式,复制粘贴即用