【语义分割】12个主流算法架构介绍、数据集推荐、总结、挑战和未来发展
背景
语义分割是将图像中的每个像素按其语义类别进行分类,从而实现像素级别的语义理解。其在自动驾驶、医学图像、结构损伤检测等领域有着广泛的应用。

1.主流算法架构
1.1 U-Net
论文地址:https://arxiv.org/abs/1505.04597
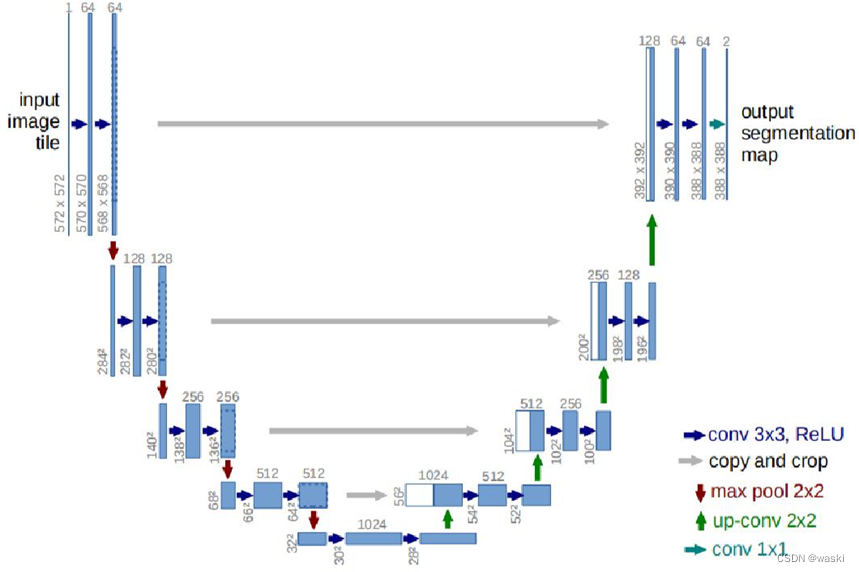
U-Net2015年由Ronneberger等人提出,是经典的编码-解码架构。其中编码器部分利用卷积层和池化层逐步提取输入图像的特征,获取输入图像特征的潜在表示。解码器部分使用转置卷积和卷积从编码器的各级分辨率级别还原目标的细节特征。U-Net因其结构简单、易于训练和有效性而受到青睐,同时也为图像分割任务提供了一个强大的基准模型。
1.2 SegNet
论文地址:https://arxiv.org/abs/1511.00561
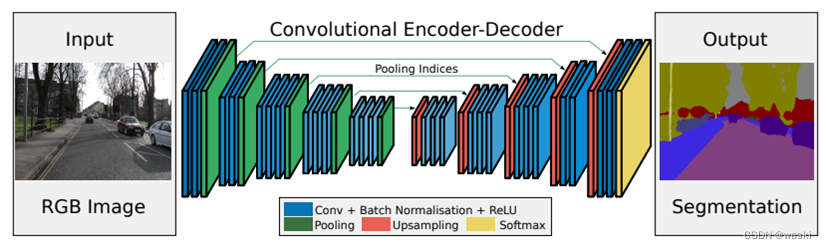
SegNet是2016年由Cambridge提出旨在解决自动驾驶的图像语义分割深度网络。SegNet与U-Net网络类似,主要的区别在于SegNet提出了记录池化的位置,反池化时恢复。SegNet在解码恢复信息时不再和编码器对应的分辨率级别进行拼接操作,而是直接进行转置卷积。
1.3 PSPNet
论文地址:https://arxiv.org/pdf/1612.01105.pdf

PSPNet是2017年提出的一种用于语义分割的深度卷积神经网络。其架构的主要特点是金字塔池化模块(Pyramid Pooling Module)。PSPNet最大的创新是引入金字塔池化模块,通过不同尺度的池化操作获得全局和局部信息。输入特征图被分割为不同大小的区域,并进行池化操作以提取每个区域的特征。不同池化尺度下的特征被级联在一起,形成了一个更加丰富和多样的特征表示。
1.4 UNet++
论文:https://arxiv.org/pdf/1807.10165.pdf

Unet++于2018年提出,Unet++继承了Unet的结构,同时又借鉴了DenseNet的稠密连接方式。其主要有四个结构特点:
(1)密集连接的多级UNet结构:UNet++采用了分层的、多级的UNet结构。每个UNet++模块都由一个编码器和多个解码器组成。每个解码器的特征图与上一级解码器的所有特征图相连接,形成了一种密集连接的结构,有助于更好地传递和利用不同层级的信息。
(2)嵌套连接与跳跃连接:UNet++结构通过嵌套连接将不同分辨率的特征图相互连接,以多层级方式传递信息。跳跃连接也被保留在不同层次,使得不同分辨率的信息可以更有效地在编码器和解码器之间传递。
(3)特征重组和特征融合:每个UNet++模块内部,通过特征重组和特征融合操作,将不同分辨率和不同层级的特征图结合起来,增强了特征表达的多样性和丰富性。
(4)多尺度特征提取:UNet++在编码器和解码器中都包含了多尺度特征提取模块,有助于捕获不同尺度下的语义信息。
1.5 DeepLabv3+
论文:https://arxiv.org/pdf/1802.02611v3.pdf

DeepLabv3+是由Google于2018年提出的图像语义分割模型,旨在解决语义分割任务中的精度和效率问题。它是DeepLab系列模型的最新版本,结合了深度卷积网络和空洞卷积网络的优势,并引入了空间金字塔池化模块(ASPP)和解码器模块,利用多尺度信息增强模型的性能,有助于解决对象尺度不一致的问题。
DeepLabv3+整体来说也是一个编码-解码架构,其中编码器中的DCNN是可以按照具体任务需求修改的backbone。举例来说,DCNN可以是高效轻便的MobileNet、EfficientNet,也可以是深度残差网络ResNet,也可以是经典的Xception、Inception等网络。具体的架构方案需要根据当前的任务做具体的设计和调整。
1.6 HRNet
论文:https://arxiv.org/pdf/1904.04514.pdf

HRNet于2019年提出,作者通过通过聚合来自所有并行卷积的(上采样的)表示来增强高分辨率表示,而不是仅聚合来自高分辨率卷积的表示。这种架构设计模式是模型有更强的表征能力。其架构的主要特点如下:
(1)多分辨率特征金字塔:HRNet在网络的不同分支中保持多个分辨率的特征图,同时通过高分辨率和低分辨率的交互,保留了更多的细节信息。通过多个分支,每个分支都以不同的分辨率来处理输入图像,然后进行特征融合,以综合不同分辨率的信息。
(2)多层级信息融合:HRNet内部进行多层级的信息融合,使得不同分辨率特征图之间可以相互交流和融合,充分利用不同分辨率的特征。
(3)高分辨率信息保留:通过保留高分辨率特征图,HRNet在姿态估计和图像分割任务中能够更好地捕获和利用细节信息,避免了传统网络中由于下采样导致的低分辨率特征损失问题。
(4)通道交流:HRNet在不同分辨率特征图之间引入了通道交流(channel fusion),使得不同分辨率的特征图可以相互交流和融合,提高了特征的丰富性和表达能力。
1.7 U2Net
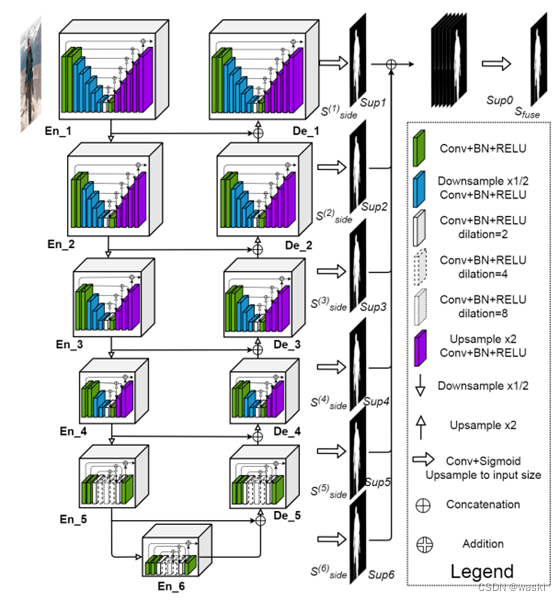
U2Net于2020年发表于CVPR。U2Net的主体是一个两层嵌套的U型结构,网络中的每个编码器和解码器模块也是类似UNet的结构,也就是在大的UNet中嵌入了一堆小UNet。其架构的主要特点如下:
(1)ReSidual U块(RSU)中混合了不同大小的感受野,它能够从不同的尺度捕获更多的上下文信息。
(2)RSU块中使用了池化操作,它增加了整个架构的深度,而不显著增加计算成本。这种架构使得使用者能够从头开始训练深度网络,而无需使用图像分类任务中的主干(backbone)。
1.8 HRNet-OCR
论文:https://arxiv.org/pdf/1909.11065.pdf


HRNet-OCR于2021年提出,它在HRNet的基础上,进一步引入了OCR Object-Contextual Representations)机制。这种OCR机制是一种简单而有效的对象上下文表示方法,帮助网络更好地理解图像中不同对象之间的关系和上下文信息。OCR模块在每个HRNet分支上引入了空间注意力机制(Spatial Attention)和对象级别的上下文信息建模。空间注意力机制有助于网络学习不同区域的重要性,对象级别的上下文信息帮助网络更好地理解对象之间的联系。
1.9 SETR
论文地址:https://arxiv.org/pdf/2012.15840.pdf
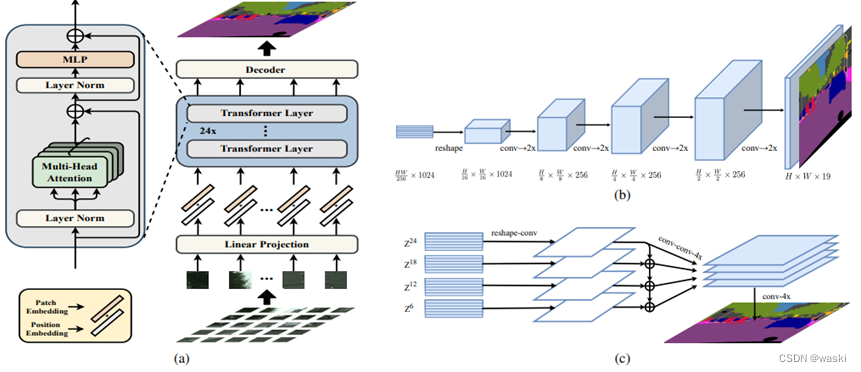
SETR于2021年提出,是基于ViT来进行语义分割的第一个代表模型。它提出以纯Transformer结构的编码器来代替CNN编码器,改变现有的语义分割模型架构。其架构的主要特点如下:(1)Image to sequence 图像序列化方法:作者参考了ViT的做法,即对输入图像进行切片处理,将每一个2D的图像切片(patch)视为一个“1D”的序列作为整体输入到网络当中。(2)Transformer: 通过将序列输入到Transformer架构可进行特征的提取,其主要包含两个部分Multi-head Self-Attention (MSA) and Multilayer Perceptron (MLP) blocks。(3)解码:作者给出了三种解码上采样方式,即朴素上采样、渐进上采样、多级特征融合(类似于特征金字塔)。
1.10 SegFormer
论文地址:https://arxiv.org/pdf/2105.15203.pdf

SegFormer于2021年提出,其架构的主要特点如下:
(1)patch的局部连续性:之前ViT做patch embedding时,每个patch都是独立的,而SegFormer对patch设计成有重叠的,保证局部连续性。
(2)多尺度融合:Encoder输出多尺度的特征,Decoder将多尺度的特征融合在一起,这使得模型能够同时捕捉高分辨率的粗略特征和低分辨率的细小特征,优化分割结果。
(3)轻量级decoder: 编码器中分层Transformer的设计使其相较于CNN有更大的感受野,这使得在设计decoder时可以仅由MLP层组成。所以decoder的计算量和参数量非常小,从而使得整个模型可以高效运行,简单直接。并且,通过聚合不同层的信息,结合了局部和全局注意力。
1.11 Swin-UNet
论文地址:https://arxiv.org/pdf/2105.05537.pdf

Swin-UNet于2021年提出,它是一个类Unet的纯Transformer。Token化的图像patch被输入到基于transformer的U型编码器-解码器架构中,并具有跳跃连接,用于局部全局语义特征学习。具体来说,Swin-UNet使用带有移位窗口(shifted windows)的分层Swin Transformer作为编码器来提取上下文特征,设计了一种基于对称Swin Transformer的patch expanding层解码器,对特征图进行上采样操作,恢复特征图的空间分辨率。
1.12 SegNeXt
论文地址:https://arxiv.org/abs/2209.08575

SegNeXt于2022提出,展示了卷积注意力在编码上下文信息上比transformer自注意力更有效。其架构特点主要如下:
(1)采用一种新的多尺度卷积注意力(Multi-Scale Convolutional Attention, MSCA)。MSCA包含三个部分,分别是,深度可分离卷积(获取局部信息),多分支深度可分离strip卷积(以捕获多尺度上下文),1×1卷积(建模不同通道之间的关系)
(2)在解码器中,轻量级的Hamburger 以进一步建模全局上下文。
2. 数据集推荐
在这里,小编针对道路交通领域,推荐一个易于上手的道路标记数据集CeyMo Dataset。所有图像均配备有像素级人工标注的道路标记真值图像(Ground-truth)。数据集的详细信息可见GitHub - oshadajay/CeyMo: CeyMo: See More on Roads - A Novel Benchmark Dataset for Road Marking Detection (IEEE/CVF WACV 2022)。针对语义分割任务,为了方便测试,小编将数据集进行了处理,将原来的11个标记类别变成了一个类别。如果想要处理后的数据集,可从百度网盘下载。
链接:https://pan.baidu.com/s/1p6mGDiCGEAvoyBMwD0twow?pwd=2twg
提取码:2twg
此外,小编用处理后的数据集测试了几个语义分割模型。所有语义分割架构均在Tensorflow2.0环境下测试。在测试集上参考测试结果如下:
| Model | F1-score(%) | IOU(%) |
| UNet | 91.00 | 82.81 |
| DeepLabv3+ | 89.96 | 81.12 |
| HRNetV2-W48 | 86.36 | 75.46 |
| HRNet-OCR | 88.20 | 78.30 |
| PSPNet | 88.10 | 78.15 |
| SegNet | 88.80 | 78.85 |
| SegFormer | 88.91 | 79.43 |
| SegNeXt | 90.29 | 82.98 |
总结
回顾近10年来经典的语义分割模型,无论是基于CNN的架构还是基于Transformer的架构,最核心的理念是“编码-解码”。直观上来讲,就是通过下采样获取特征的潜在表示,再通过上采样从抽象的底层特征表示中恢复目标的细节信息。
从交通、医学、遥感、自动驾驶、智能施工管控等领域近些年发表的关于语义分割的论文来看,采用的架构大多是以上所提到的模型的变体,包括但不限于添加各种注意力机制模块、更换主流的特征提取网络backbone、CNN与transformer混合设计、多尺度特征融合。其中一个主要原因是面对不同的分割任务和分割对象,已有的语义分割架构并不能保证表现得很出色。所以,在利用语义分割算法解决自己特定领域的问题时,往往需要结合实际需求(精度为第一要素、速度为第一要素、还是速度和精度要达到出色的平衡),对架构进行改造设计。
挑战与未来发展
目前来看,各种语义分割架构层出不穷,但本质上都是基于最小元素“卷积”或“Transformer”的各种组合变体。未来,针对特定的专业分割任务,仍需要结合具体场景和需求,选择或搭建适合自己的架构体系。
除此之外,以上所提到的语义分割架构全是基于监督学习的,也就是有标签的深度学习。但现实情况是,很多任务的标签获取很难或者非常珍贵。面对这一痛点,基于自监督学习、半监督学习以及无监督学习的深度学习范式是一个非常不错的研究思路。目前,已有很多学者开展了对自监督学习、半监督学习以及无监督学习的研究,并取得了一定的进展。关于这一块的内容,小编将在后续进行介绍。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 小程序商城 免 费 搭 建之java商城 电子商务Spring Cloud+Spring Boot+二次开发+mybatis+MQ+VR全景+b2b2c
- [Mac软件]ColorWell For Mac 7.4.0调色板生成器
- 游戏开发丨基于PyGlet的简易版Minecraft我的世界游戏
- 百望云成长型企业数电票升级解决方案,转型挑战迎刃而解!
- 【JS基础】对象的一些基本使用
- gradle各版本下载地址
- Linux内核架构和工作原理详解(二)
- 软件测试—回归测试用例选择方法
- 技术学习|CDA level I 数据库应用(数据定义语言DDL)
- 网络推理之深度学习推理框架