使用pandas按照商品和下单人统计下单数据
发布时间:2024年01月12日
目录
一:需求描述
最近运营那边给到一个excel表格,是一个小程序用户的下单数据,要以商品为维度,统计用户下单情况,主要是下单的商品总金额,单数和总单数。
给到的表格数据如下:
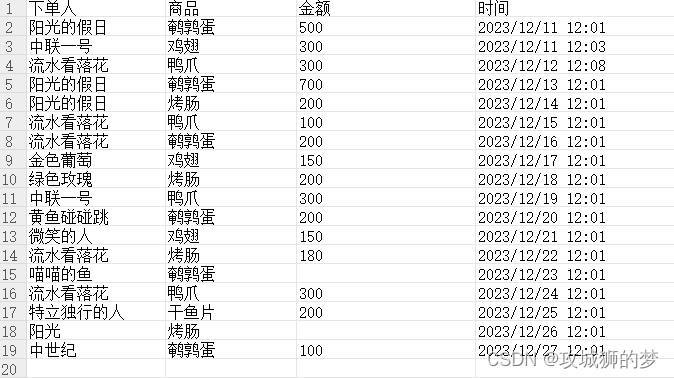
考虑用pandas实现,pandas提供了大量的数据处理函数,可以进行各种复杂的数据处理,包括数据清洗、数据转换、数据聚合等。使用pandas先对商品进行去重,然后循环商品,找出所有下单的人,再对下单人进行去重,按照商品-下单人作为关联条件进行统计金额,单数
最终实现的表格数据如下:
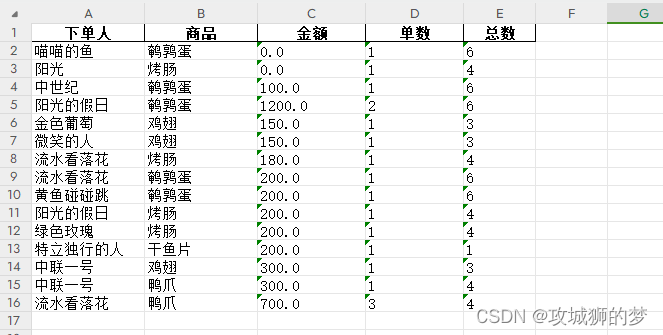
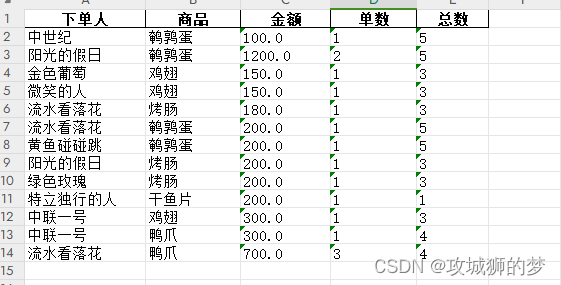
这里出现一个问题,由于给的表格存在金额数据为空的数据,在pandas中,可以使用fillna()方法对DataFrame中的空值进行处理。fillna()方法可以接受一个参数,用于指定如何填充空值。这样我金把额填充为0,这样出现的情况就是只要存在下单人就算一单,不管金额。还有其中情况是把金额为空的用户去除,在pandas中,可以使用dropna(inplace=True)删除含有空值的行,这样只会统计有下单金额的用户数据。
二:代码实现
首先要需要确保已经安装了pandas库。如果尚未安装,可以使用以下命令进行安装:
pip install pandas
代码编写:
import pandas as pd
dir = 'D://python/'
df=pd.read_excel(dir+'test.csv')#这个会直接默认读取到这个Excel的第一个表单
dic,label = [],('下单人','商品','金额','单数','总数')
#删除空值
df.dropna(inplace=True)
#把金额为空的填充0
#df.金额.fillna(0, inplace = True)
#print(df)
for 商品 in df.商品.unique():
下单人 = df[df.商品 == 商品].下单人
总数= 下单人.shape[0]
print(总数)
for 下单人 in 下单人.unique():
关联条件 = df[(df.商品 == 商品) & (df.下单人==下单人)].fillna('空值')
单数,金额 = 关联条件.shape[0],关联条件.金额.sum()
dic.append('~'.join(map(str,(eval(_) for _ in label))).split("~"))
print(dic)
#可以按照商品排序
data = pd.DataFrame(dic, columns=label).sort_values(by='商品')
data.to_excel(dir+'output1.xlsx', sheet_name='Sheet1',index=False)
#可以按照金额排序
data = pd.DataFrame(dic, columns=label).sort_values(by='金额')
data.to_excel(dir+'output1.xlsx', sheet_name='Sheet1',index=False)
三:注意事项
1:删除含有空值的行
df.dropna(inplace=True)
2:空值填充
df.fillna(0, inplace = True)
3: 某个列空值填充
df.金额.fillna(0, inplace = True)

文章来源:https://blog.csdn.net/qinshi501/article/details/135550797
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【java】16个扩展点 大力推荐
- 《Effective C++》条款42
- Redis:5种基本数据类型概述
- 走向云原生 破局数字化
- 【星海草稿】DPDK 后期会继续更新
- 漏刻有时数据可视化Echarts组件开发(46)散点图颜色判断
- 你竟然还不知道SQL性能分析?(你想象不到的详细)
- 新能源汽车智慧充电桩方案:智能高效的充电桩管理模式及应用场景
- root用户无法新增用户解决办法
- Docker容器(二)安装与初体验wordpress