【spark】spark内核调度(重点理解)
目录
spark内核调度
DAG
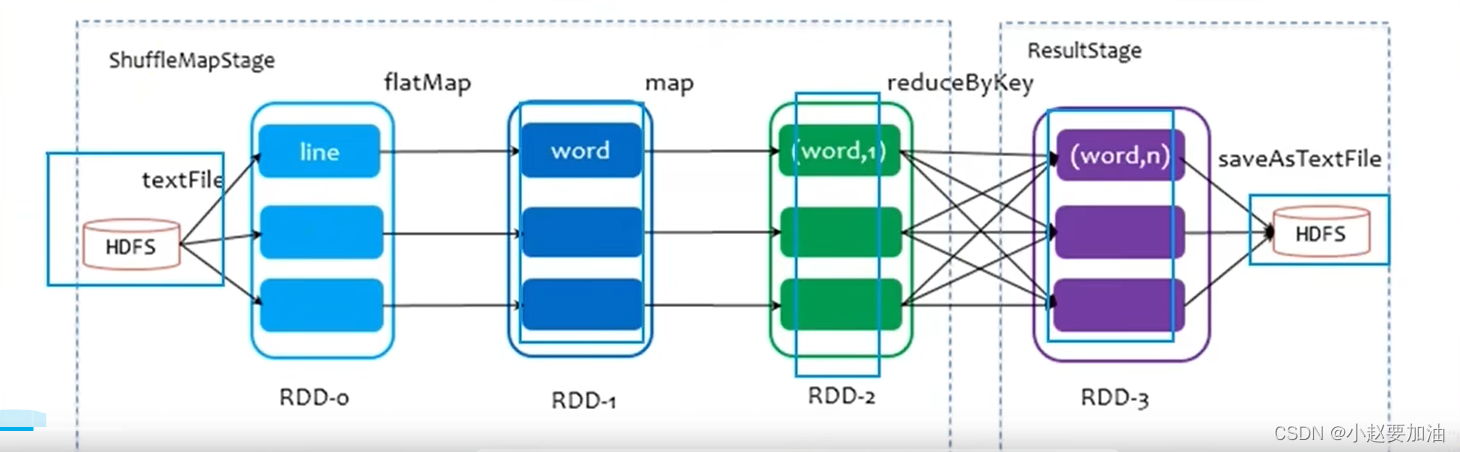
Spark的核心是根据RDD来实现的,Spark Scheduler则为Spark核心实现的重要一环,其作用就是任务调度。Spark的任务调度就是如何组织任务去处理RDD中每个分区的数据,根据RDD的依赖关系构建DAG,基于DAG划分Stage,将每个Stage中的任务发到指定节点运行。基于Spark的任务调度原理,可以合理规划资源利用,做到尽可能用最少的资源高效地完成任务计算
-
DAG:有向无环图(有方向但是没有形成闭环的一个执行流程图)
有向:有方向
无环:没有闭环 -
Job和Action的关系

Action:返回值不是RDD的算子
Job:一个应用程序内的子任务
一个Action会产生一个Job,每一个Job有自己对应的DAG图
1个ACTION = 1个DAG = 1个JOB
层级关系:
一个Application中,可以有多个JOB,每一个JOB内含有一个DAG,同时每一个JOB都是由一个Action产生的。
- DAG和分区:有关系
DAG的宽窄依赖和阶段划分
在SparkRDD前后之间的关系,分为
- 窄依赖:父RDD的一个分区,全部将数据发给子RDD的一个分区
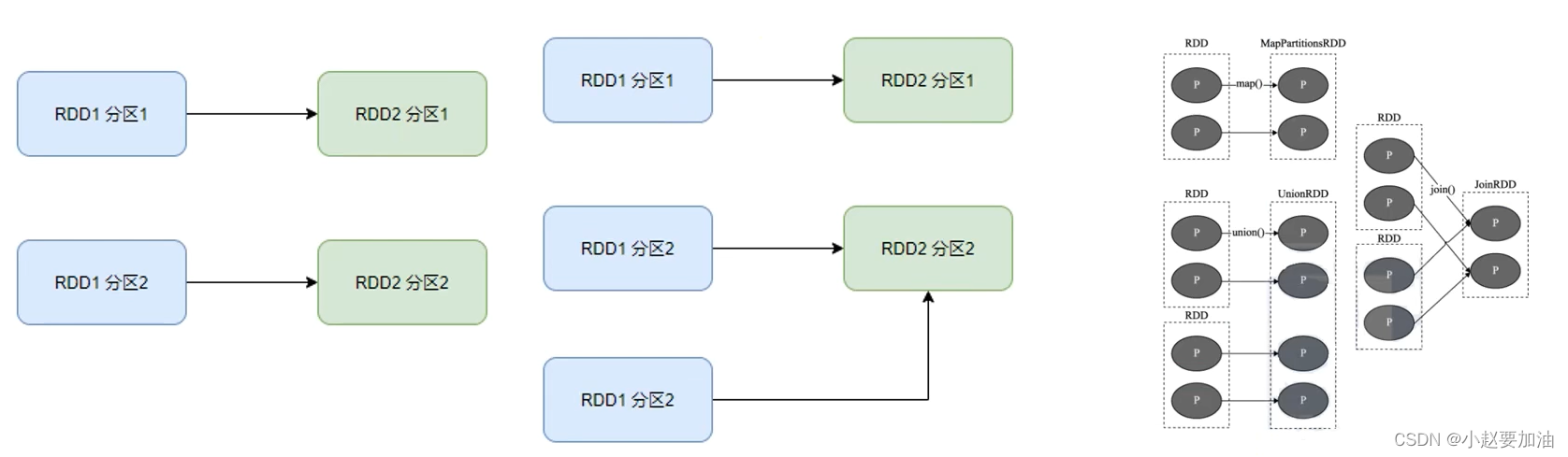
- 宽依赖:父RDD的一个分区,将数据发给子RDD的多个分区

- 阶段划分:对于Spark来说,会根据DAG按照宽依赖,划分不同的DAG阶段
划分依据:从后向前,遇到宽依赖,就划分出一个阶段。称之stage
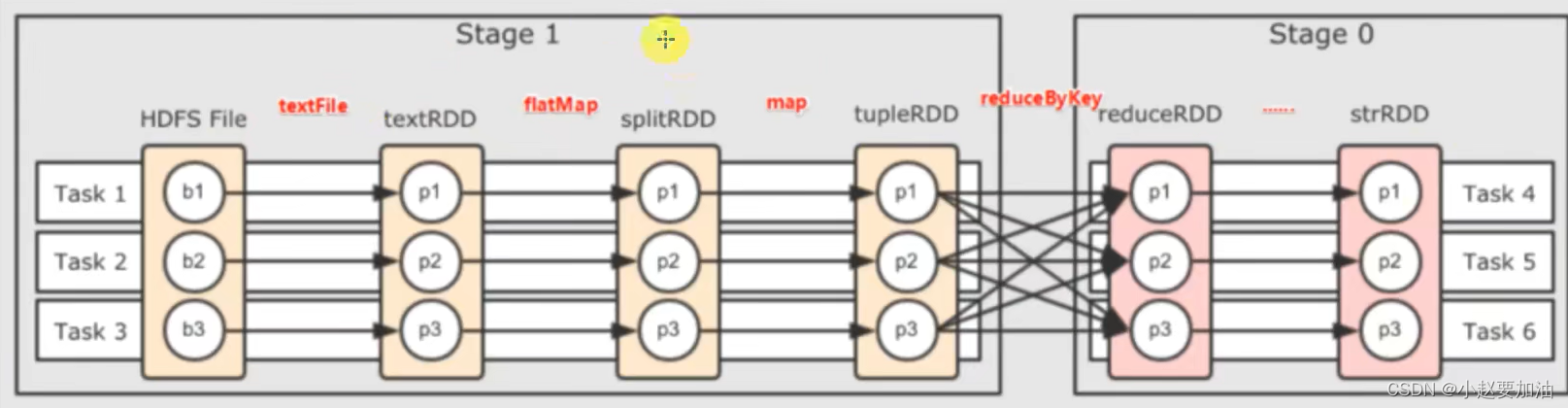
如图,可以看到,在DAG中,基于宽依赖,将DAG划分成2个stage
在stage内部一定是:窄依赖
内存迭代计算

基于带有内存的DAG,以及阶段划分。可以从图中可能出 逻辑上最优的task分配。一个task是一个线程来具体执行的。
task1中 rdd1、rdd2、rdd3的迭代计算,都是由一个task(线程完成),这一阶段的这一条线,是纯内存计算
task1 task2 task3,就形成了三个并行的 内存计算管道
面试题
Spark是怎样做内存计算的?DAG的作用是什么?Stage阶段划分的作用?
1、Spark任务会产生DAG图
2、DAG图会基于分区和宽窄依赖关系划分阶段
3、一个阶段的内部是窄依赖,窄依赖内,如果形成前后1:1分区对应关系,就可以产生许多内存迭代计算的管道
4、这些内存迭代计算的管道,就是一个个具体的执行Task
5、一个Task就是一个具体的线程,任务跑在一个线程内,就是走内存计算了
Spark为什么比MapReduce快

spark并行度
spark的并行:在同一时间内,有多少个task在同时运行
并行度:并行能力的设置
有6个task并行的前提下,rdd的分区就被规划成6个分区了
先有并行度,才会有的分区
如何设置并行度:spark.default.parallelism
可以在代码中和配置文件中以及提交程序的客户端参数中设置
优先级从高到低:
1、代码中
2、客户端提交参数中
3、配置文件中
4、默认
全局并行度是推荐设置,不要针对RDD改分区,可能会影响内存迭代管道的构建,或者会产生额外的shuffle
集群中如何规划并行度
结论:设置为CPU总核数的2~10倍
CPU的一个核心同一时间只能干一件事情
所以,在100个核心的情况下,设置100个并行度,就能让CPU 100%出力
这种设置下,如果task的压力不均衡,某个task先执行完了,就会导致CPU核心空闲
所以,我们将Task并行分配的数量变多,比如800个并行,同一时间只有100个在运行,700个在等待
但是可以确保,某个task运行完了,后续有task补上,不让cpu闲下来,最大程度利用集群资源
规划并行度,只看集群CPU核数
spark的任务调度
spark的任务调度由Drive进行调度,这个工作包含:
1、逻辑DAG产生
2、分区DAG产生
3、Task划分
4、将Task分配给Executor并监控其工作
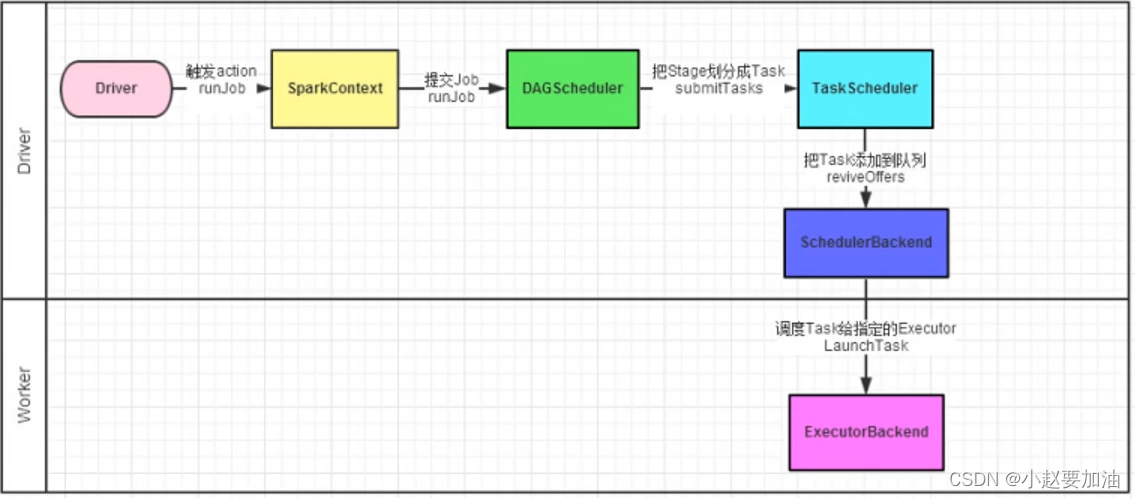
- Driver端被构建出来
- 构建SparkContext(执行环境入口对象)
- 基于DAG Scheduler(DAG调度器)构建逻辑Task分配
- 基于TaskScheduler(Task调度器)将逻辑Task分配到各个Executor上干活,并监控他们
- Worker(Executor),被TaskScheduler管理监控,听从他们的指令干活,并定期汇报进度。
Driver内两个组件:
DAGScheduler(DAG调度器):
工作内容:将逻辑的DAG图进行处理,最终得到逻辑上的Task划分
TaskScheduler(Task调度器):
工作内容:基于DAG Scheduler的产生,来规划这些逻辑的task,应该在哪些物理的Excutor上运行,以及监控管理他们的运行
Spark运行中的概念名词大全
1、一个spark环境可以运行多个Application
2、一个代码运行起来,会成为一个Application
3、Application内部可以有多个Job
4、每个Job由一个Action产生,并且每个Job有自己的DAG执行图
5、一个Job的DAG图 会基于宽窄依赖划分成不同的阶段
6、不同阶段内基于分区数量,形成多个并行的内存迭代管道
7、没一个内存迭代管道形成一个Task(DAG调度器划分将Job内划分出具体task任务,一个Job被划分出来的task在逻辑上称之为这个Job的taskset)
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!